今天分享一个磁盘扩容中遇到的典型陷阱:理论上 ext4 文件系统支持在线扩容,但在一个特殊场景下,却不得不卸载分区后才能完成操作。
事情源于一位用户,他的 CentOS 7.9 系统运行在天翼云主机上。/data 分区使用率高达99%,已经严重影响了业务。由于前任运维已经离职,问题迟迟未解决。用户曾尝试参考我之前的方案但未成功,于是再次联系到我。
在开始操作前,我首先建议用户在云平台为服务器创建快照以备份数据,这是进行任何磁盘操作前至关重要的安全步骤。
1 查看基本情况
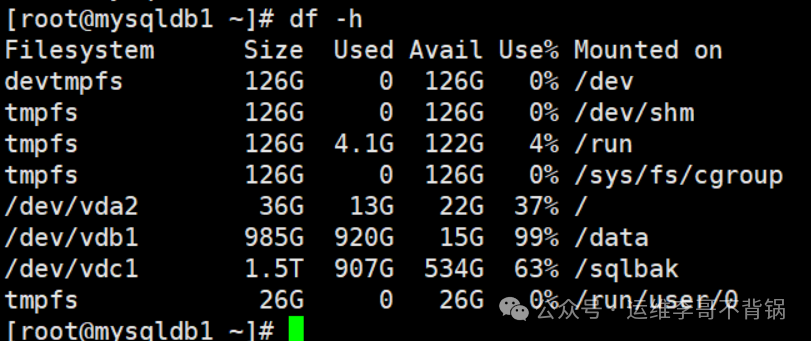
我使用 lsblk 命令查看了磁盘情况,确认云平台已将 /dev/vdb 磁盘扩容至 1.5T,但新增的空间尚未被系统分区识别。
接着,我使用 fdisk 命令查看磁盘的分区结构:
fdisk /dev/vdb
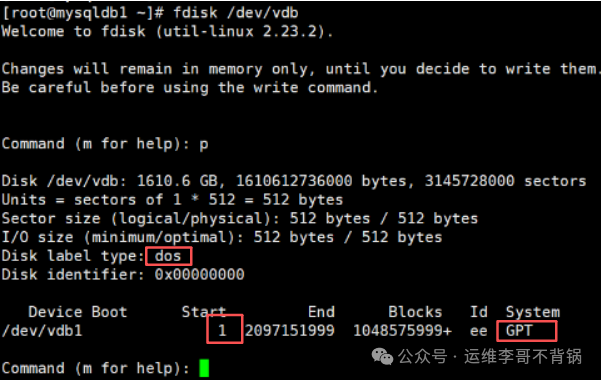
命令输出暴露了 3 个严重的异常点:
- 磁盘的标签类型显示为
dos(即传统的 MBR 分区表)。
- 但分区
/dev/vdb1 的系统类型却是 ee,这代表它是一个 GPT 保护分区(常用于在 MBR 磁盘上存放 GPT 数据)。
- 分区的起始扇区是
1,这非常不规范,通常应该从 2048 开始。
这明显是一个 “历史遗留的混合 GPT 磁盘”。前任运维同事的初始分区操作极不规范,为后续的扩容埋下了隐患。这类磁盘在扩容时极易出现问题。
2 尝试解决问题
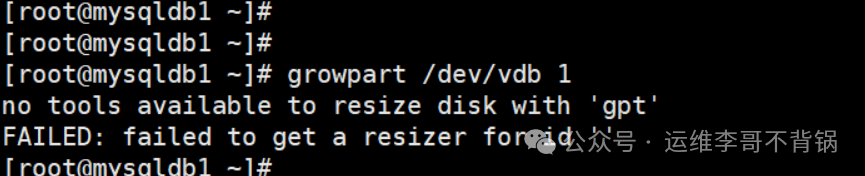
我首先尝试使用云环境中常用的 growpart 工具进行在线扩容,但如预期般失败了。
随后,我转向功能更强大的 parted 工具。首先查看磁盘的详细情况:
parted /dev/vdb print
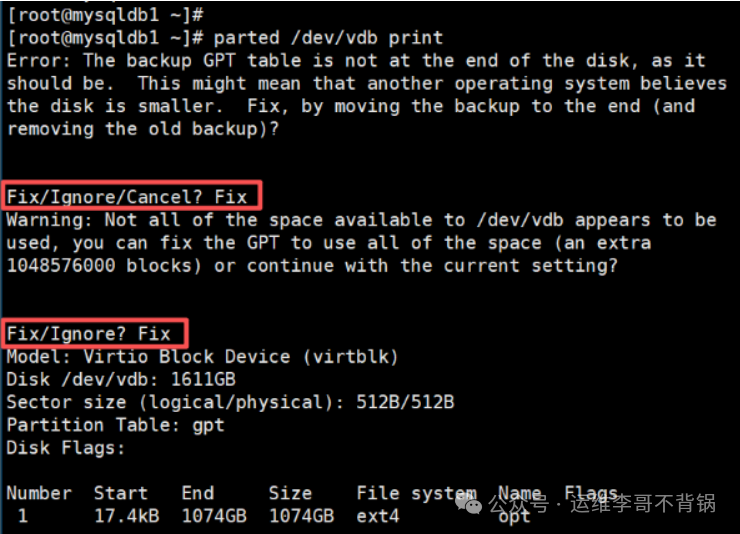
这里出现了两个交互式提示:
- 第一个错误提示表明:云平台扩容磁盘后,GPT 分区表的备份信息仍停留在旧的磁盘末尾,导致 GPT 结构不完整。我选择了
Fix 让其修复。
- 第二个警告提示询问:是否让 GPT 分区表正式识别并使用新扩容出来的磁盘空间?我同样选择了
Fix。
完成修复后,再次使用 parted 查看,磁盘信息已经显示正常。
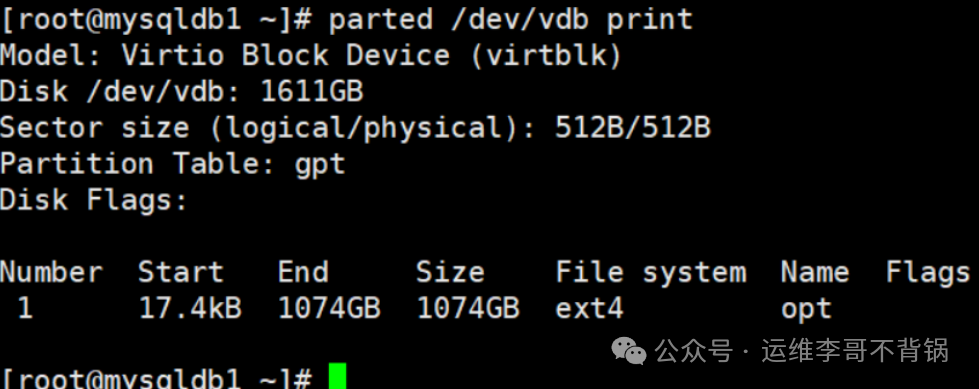
接下来,我尝试使用 parted 进行在线扩容分区:
parted /dev/vdb resizepart 1 100%

问题再次出现,提示分区 /dev/vdb1 正在被使用,要求先卸载(unmount)才能修改。这回到了我们开头提到的矛盾点。
3 最终解决方案
踩完前面的所有“坑”之后,最终的解决方案变得清晰。由于在线扩容分区表被阻止,必须卸载分区后操作:
# 卸载挂载点
umount /data
# 使用parted将分区1扩展到磁盘的100%
parted /dev/vdb resizepart 1 100%
# 在线扩展ext4文件系统以使用新的分区空间
resize2fs /dev/vdb1
# 验证扩容结果
df -h
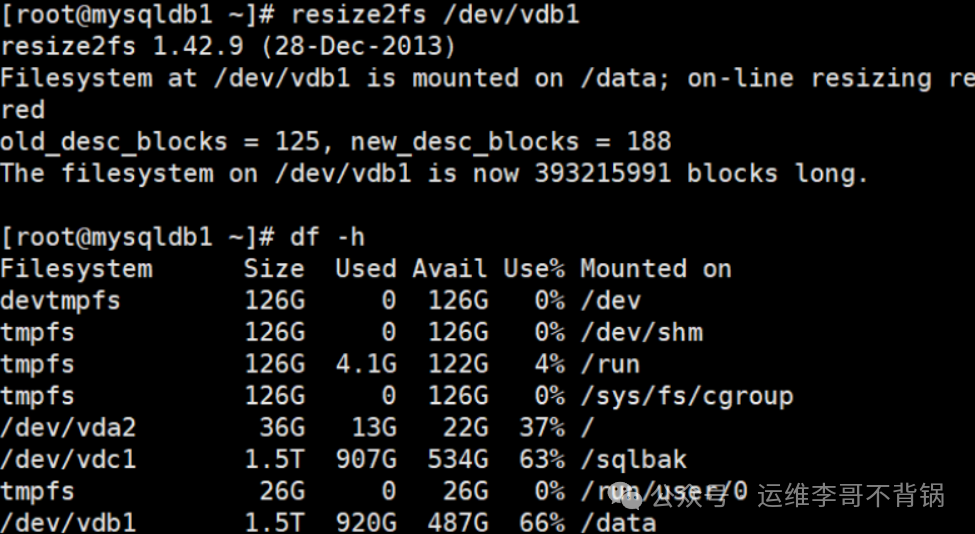
从输出可以看到,/data 分区已成功从约 985G 扩容至 1.5T。
细心的读者可能会问:我们执行了 umount,但并没有执行 mount 命令重新挂载,为什么 df -h 能显示挂载信息?这是因为该系统使用了 systemd 管理挂载点。当我们卸载时,对应的 mount unit 被停用;在文件系统操作完成后,systemd 自动重新激活了该 unit,实现了自动挂载。
systemctl list-units --type=mount |grep data

4 真正的原因
问题的根源并非 ext4 文件系统不支持在线扩容,而是出在分区表与内核交互的层面。
一句话总结:
内核无法在“分区正在使用”的情况下,重新加载一个被修改(修复)过的 GPT 分区表。
这块磁盘同时命中了多个“高风险条件”,构成了一个复杂的系统运维场景:
| 风险点 |
说明 |
| GPT 备份表异常 |
扩容后备份GPT信息未更新,需要修复。 |
| GPT 扩展空间 |
修复过程修改了分区表的核心元数据。 |
| 分区正在挂载 |
内核出于安全考虑,拒绝为重写过的分区表重读分区信息。 |
| 非标准起始扇区 |
可能是陈旧系统镜像或不当初始化留下的历史问题。 |
因此,对于这种特定状态的磁盘,理论支持在线扩容,但实际操作中内核行为不允许。
这次经历再次证明,磁盘最初的格式化与分区方式,将深远影响未来数年的运维体验。一个规范、清晰的初始设置,能避免后续大量的棘手问题。希望这个案例能为大家在Linux系统运维中处理类似磁盘问题提供参考。更多技术讨论与资源分享,欢迎访问云栈社区。
 发表于 2026-1-13 03:05:11
|
查看: 198|
回复: 0
发表于 2026-1-13 03:05:11
|
查看: 198|
回复: 0
