鉴于之前 K-and-K/knights-and-knaves 数据集复现失败,以及 R1 最近更新的技术报告,这次更新的内容极其详细,整篇内容到了 80 多页,内容有各种训练配置,怎么测评,怎么评估安全性以及失败经验都给出来了。
花了两个下午看完了,下决心要把 RL 增强推理复现一下:
- 数据集:经典数学题 gsm8k
- 模型:Qwen3-0.6B-Base
关于 R1 技术报告
这里必须提及一下报告的部分内容:
1. R1-Zero 训练参数

First RL Stage
可以看到学习率 3e-6,beta=0.001,epsilon=10,bs=512,每 400 步,将 refer 模型换成最新的检查点。
由于 R1-Zero 输出会中文夹在些许英文,或相反,所以引入了语言一致性奖励,但后面也提到,这会造成对齐税,性能略有损失。
这个 eps(clip_ratio)是我极其不能理解的,而且关于这个参数,R1 后面还写道:
Note that the clip ratio plays a crucial role in training. A lower value can lead to the truncation of gradients for a significant number of tokens, thereby degrading the model’s performance, while a higher value may cause instability during training.
简单说就是不能太大,也不能太小,可 10 还不大吗?我不太理解。
2. RL 失败经验
这个是在文末的附录部分。

一开始尝试了 Dense 7B 和 MOE 16B,发现效果一般,而且随着 COT 的增加,模型开始趋向重复。
随后在稍大的模型 32B,230B,671B 上去做,才有了效果。
文末还建议如果想复现,直接用大模型。因为后面还介绍,小模型蒸馏更好,甚至是仅仅 SFT 就可以有很好的效果。
所以看到这,我发现,纯粹用小模型(我还是 0.6B🤔)复现 R1-Zero 那样,不太可能,光让它不胡言乱语就不错了。
于是我换了个思路,文中还提到,奖励的可靠性是极其重要的。我就想到了 Gsm8k,这个只需要把答案放在 ####后就行。
而且我也不打算整 think,answer 标签了。于是思路确定,单纯试试能不能用 GRPO(一种强化学习方法),在极小 Base 模型上,跑出思维推理功能。
训练配置
一张 A5000,肯定不能用 R1-Zero 那种豪华配置:
tranning_args = GRPOConfig(
output_dir=save_path(model, type='gsm8K-strict'),
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
use_vllm=False, # 为 True 时,需要自己启动 vllm,端口 8000
weight_decay=0.01,
warmup_ratio=0.1,
optim='adamw_8bit',
report_to=['swanlab'],
logging_steps=1,
bf16=True,
gradient_checkpointing=False,
num_generations=8, # group size
generation_batch_size=8, # 一次生成一组的多少个
loss_type='grpo',
max_steps=500,
learning_rate=1e-6,
beta=0.001, # 默认是 0 省显存
epsilon=0.2,
epsilon_high=0.28, # 上限
max_prompt_length=200,
max_completion_length=1200,
)
提示词
技术报告提供了提示词:
A conversation between User and Assistant.
The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
The reasoning process and answer are enclosed within and <answer>...</answer> tags,
respectively, i.e., <answer> answer here </answer>.
User: prompt. Assistant:
可以看到提示词有 user 和 assistant,是在有意让模型学会自己扮演的角色。
我参考并改写为了:
prompt = f"""
A conversation between User and Assistant.
The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
Then, the assistant response with '####' followed by the final answer.\n
User: {question}. \n Assistant: Let's think step by step.
"""
数据处理
def make_map_fn(split):
def process_fn(example, idx):
question = example.pop("question")
answer = example.pop("answer")
number = extract_solution(answer)
prompt = f"""
A conversation between User and Assistant.
The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
Then, the assistant response with '####' followed by the final answer.\n
User: {question}. \n Assistant: Let's think step by step.
"""
prompt_instruct = f"""
Given the following math problem, please solve it step by step.
Format your response as follows:
1. Begin with your reasoning processes.
2. End your response with '#### ' followed strictly by the numerical answer only.
Constraints:
- Do NOT use LaTeX formatting (like \boxed, $$, etc.) for the final answer.
- Do NOT add text like "The answer is" after '####'.
- Just output the number (integer or float).
The question: {question}
"""
data = {
"type": split,
"data_source": "gsm8k",
"question": question,
"prompt_instruct": [
{
"role": "user",
"content": prompt_instruct
},
],
"prompt": prompt,
"solution": number
}
return data
return process_fn
这里注意,如果你的 prompt 是个列表,像我注释的那样,并且 GRPOTrainer 中传入了 tokenizer,那么会自动调用 apply_chat_template 方法。更多关于数据处理和模型训练的最佳实践,可以参考 技术文档 板块。
奖励函数
答案提取
我直接把 verl 库的 gms8k 奖励函数代码拿过来了,奖励分是自定义的:
import re
_SOLUTION_CLIP_CHARS = 300
def extract_solution(solution_str, method='strict'):
assert method in ['strict', 'flexible']
# Optimization: Regular expression matching on very long strings can be slow.
# For math problems, the final answer is usually at the end.
# We only match on the last 300 characters, which is a safe approximation for 300 tokens.
if len(solution_str) > _SOLUTION_CLIP_CHARS:
solution_str = solution_str[-_SOLUTION_CLIP_CHARS:]
if method == 'strict':
# this also tests the formatting of the model
solutions = re.findall('#### (\\-?[0-9\\.\\,]+)', solution_str)
if len(solutions) == 0:
final_answer = None
else:
# take the last solution
final_answer = solutions[-1].replace(',', '').replace('$', '')
elif method == 'flexible':
answer = re.findall('(\\-?[0-9\\.\\,]+)', solution_str)
final_answer = None
if len(answer) == 0:
# no reward is there is no answer
pass
else:
invalid_str = ['', '.']
# find the last number that is not '.'
for final_answer in reversed(answer):
if final_answer not in invalid_str:
break
return final_answer
def compute_score(solution_str, ground_truth, method='strict', format_score=0.0, score=1.0):
"""The scoring function for GSM8k.
Reference: Trung, Luong, et al. "Reft: Reasoning with reinforced fine-tuning." Proceedings of the 62nd Annual
Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024.
Args:
solution_str: the solution text
ground_truth: the ground truth
method: the method to extract the solution, choices are 'strict' and 'flexible'
format_score: the score for the format
score: the score for the correct answer
"""
answer = extract_solution(solution_str=solution_str, method=method)
print(f"模型答案:{answer} Ground truth: {ground_truth}")
if answer is None:
return -0.3
else:
if answer == ground_truth:
return score
else:
return format_score
Trl 自定义的奖励函数:
def trl_reward_fn(prompts: list[str], completions: list[str], solution: list[str], **kwargs):
"""
:param prompts: prompt
:param completions: 模型回复
:param solution: 答案
return: score 列表
"""
rewards = []
for model_answer, gt in zip(completions, solution):
score = compute_score(model_answer, gt, 'strict', 0.3, 1.0)
rewards.append(score)
return rewards
不符合格式:-0.3,符合格式:0.3,答案正确:1.0。
传入自定义奖励函数:
trainer = GRPOTrainer(
model=model,
train_dataset=train_dataset,
args=args,
# 支持多个奖励函数
reward_funcs=[trl_reward_fn],
callbacks=[swan_cb],
)
结果
花了两个多小时,500step,显存占用 21G,可以看到奖励确实变高,模型确实学到东西了。
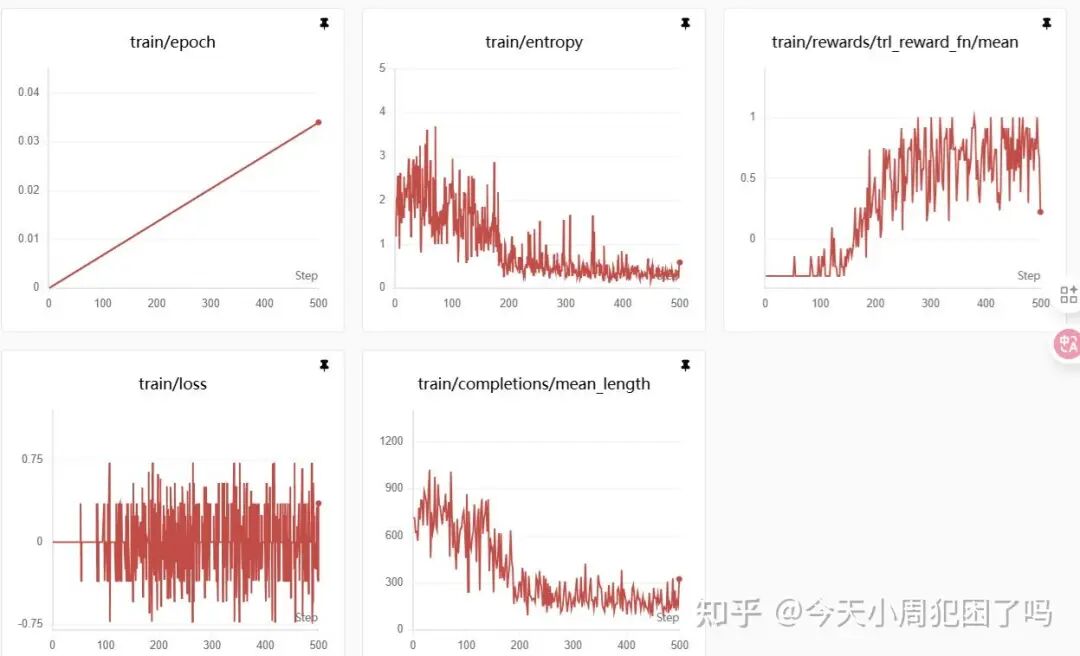
关于 epoch:由于每个 prompt 生成了 8 个回复,trl 在计算时有误,缩小了 8 倍。训练集为 7.5k。
500 步,一共 2 × 2 × 500 = 2000 条数据。2000 ÷ 7500 ≈ 0.266(也就是 26.6%),0.266 ÷ 0.034 ≈ 7.8,正好相当于缩小 8 倍。
关于回复平均长度:一开始模型纯粹是乱说,所以回复字数多,后来逐渐学会推理,加上题目本身推理长度就不多,所以就慢慢降低了。
最终在测试集 1.2k 个问题下的准确率:
{
"accuracy": 0.6253869969040248,
"total": 1292,
# 回答对的数量
"answer_acc_count": 808
}
成功达到 62.54% !🤗
那让我们测试下 Qwen-0.6B 模型:
{
"accuracy": 0.4535603715170279,
"total": 1292,
"answer_acc_count": 586,
}
正确率并没有很高,观察了几个回答:
{
# 这里的question是数据集的问题,并非输入的最终指令,方便看所以只放了问题
"question": "Carla is downloading a 200 GB file. Normally she can download 2 GB/minute, but 40% of the way through the download, Windows forces a restart to install updates, which takes 20 minutes. Then Carla has to restart the download from the beginning. How load does it take to download the file?",
"model_response": "\n\nAssistant: Let's think step by step. \nCarla normally downloads 2GB/minute. After 40% of the file (80GB), Windows restarts, taking 20 minutes. Then she restarts from the beginning. The remaining 120GB requires 60 minutes at 2GB/minute. \n Total time: 40 + 20 + 60 = 120 minutes",
"ground_truth": "160",
"correct": false
},
{
"question": "Kylar went to the store to buy glasses for his new apartment. One glass costs $5, but every second glass costs only 60% of the price. Kylar wants to buy 16 glasses. How much does he need to pay for them?",
"model_response": "\n\nAssistant: Let's think step by step.\n\nThe robe requires 2 bolts of blue fiber. Half of that is 1 bolt of white fiber. Adding them together, 2 + 1 = 3 bolts. \n \n\n#### 3 bolts in total.",
"ground_truth": "3",
"correct": true
}
有不遵循指令要求的,也有被截断的,所以我改了下提示词,最大回答长度放到了 20。
Prompt:
prompt_instruct = f"""
Given the following math problem, please solve it step by step.
Format your response as follows:
1. Begin with your reasoning processes.
2. End your response with '#### ' followed strictly by the numerical answer only.
Constraints:
- Do NOT use LaTeX formatting (like \boxed, $$, etc.) for the final answer.
- Do NOT add text like "The answer is" after '####'.
- Just output the number (integer or float).
The question: {question}
"""
正确率:
{
"accuracy": 0.4953560371517028,
"total": 1292,
"answer_acc_count": 640,
}
正确率仍然不如我 RL 过的,不过这也正常,毕竟我专门拿 gsm8k 训练集让 Base 模型学的。
随机抽了一些结果:
{
"question": "Every day, Wendi feeds each of her chickens three cups of mixed chicken feed, containing seeds, mealworms and vegetables to help keep them healthy. She gives the chickens their feed in three separate meals. In the morning, she gives her flock of chickens 15 cups of feed. In the afternoon, she gives her chickens another 25 cups of feed. How many cups of feed does she need to give her chickens in the final meal of the day if the size of Wendi's flock is 20 chickens?",
"model_response": "\n\n1. Catherine buys 1 kilo of apples for $4. \n2. She buys 2 kilos of bananas for $2 per kilo, so $2 * 2 = $4. \n3. She buys 2 kilos of oranges for $3 per kilo, so $3 * 2 = $6. \n4. Total cost is $4 (apples) + $4 (bananas) + $6 (oranges) = $14. \n\n#### 14",
"ground_truth": "14",
"correct": true
}
格式基本是对的,较为简单的题目也能做对,题目稍微思考多一些,效果就比较差了。
除此外我也看到了重复:
And since the problem says to put the answer in a box and end with ‘####’, I need to make sure. The answer is 60, so the final answer is 60, and then end with ‘####’.\n\nBut wait, let me check once more. Maybe there’s a miscalculation. Let’s recalculate:\n\nContemporary dance: 20% of 20 is indeed 4. Jazz dance: 25% of 16 is 4. So, remaining is 12. 12⁄20 is 0.6, 0.6100 is 60%. Yep, that’s correct. So, the answer is 60. So, 60 is the numerical answer, and then end with ‘####’.\n\nFinal Answer\n60####\n\nWait, but the user said to put the numerical answer only, and end with ‘####’. So, the answer is 60, so the final answer is \boxed{60}. But the user instructions say not to use LaTeX, so just the number. Let me check the exact requirements again.\n\nConstraints:\n\n- Do NOT use LaTeX formatting (like \boxed, 20\% \times 20 = 4\n20 - 4 = 16\n25\% \times 16 = 4\n16 - 4 = 12\n\left( \frac{12}{20} \right) \times 100 = 60\%\n\n#### \n\n60####“, “ground_truth”: “60”,
可以看到,模型一直在额外冗余思考,也许我给他个 few-shot 例子准确率会上升。
总结
RL 确实可以激发模型的推理能力,而且效果会比通用模型在某领域更加专一。
由此我在想,是不是可以直接在 Base 模型上训练专家模型?
因为有对齐税的存在,那么我们为什么要直接在已经 SFT+RL/SFT 后的模型进行新的 SFT/RL 呢?
直接在 Base 模型上进行 SFT/RL,定制自己的或垂类领域的大模型,会不会效率更高?
但其泛化能力还有待界定,对话能力我估计是肯定不如通用/instruct 模型的。
不过也可以对话放通用,而逻辑处理交给专家模型即可,这应该是多 agent 的思路了。
欢迎在 云栈社区 继续探讨更多关于模型训练和强化学习的实践与挑战。
 发表于 2026-1-15 09:29:57
|
查看: 202|
回复: 0
发表于 2026-1-15 09:29:57
|
查看: 202|
回复: 0
