在C++ STL中,set和unordered_set作为关联式容器能够实现快速键查找,但仅存储键本身。本文将继续探讨map和unordered_map,这两种容器同样属于关联式容器,但完整存储键值对,使其在需要处理键值映射的场景中极为实用。下面我们将详细分析它们的特性和用法。
总体差异
map是有序键值对容器,键是唯一的,底层与set一样,是用红黑树实现的。而unordered_map不保证元素的排序,底层采用哈希表实现,能够提供更快的查找速度。它们之间的差异与set和unordered_set的差异基本一致,底层实现也完全相同。具体这里不展开,有兴趣可以去参考相关文章。
map有以下几个特点:
- 存储的是键值对,其中每个键都是唯一的。
- 元素按照键的顺序自动排序,通常是升序。
- 每个键在map中只能出现一次。
- 提供了双向迭代器,可以向前和向后遍历元素。
相比之下,unordered_map则不保证元素排序,且只支持单向迭代器,但提供了平均O(1)的查询性能。
map/unordered_map 通用基础用法
不管是map还是unordered_map,核心操作都是“增删改查”,语法几乎一致。
(1)插入元素
// map的头文件
#include <map>
// unordered_map的头文件
#include <unordered_map>
using namespace std;
int main() {
map<int, string> m;
unordered_map<int, string> um;
// 方式1:[]运算符(如果键不存在则插入,存在则修改值)
m[1] = "苹果";
um[1] = "苹果";
// 键1已存在,修改值
m[1] = "红苹果";
um[1] = "红苹果";
// 方式2:insert()函数(不覆盖已存在的键)
// 插入成功返回pair<迭代器, true>,失败返回pair<迭代器, false>
auto ret1 = m.insert({2, "香蕉"});
auto ret2 = um.insert({2, "香蕉"});
// 键2已存在,插入失败,不会修改值
auto ret3 = m.insert({2, "黄香蕉"});
cout << "map插入键2是否成功:" << boolalpha << ret3.second << endl; // 输出false
// 方式3:emplace()函数(原地构造,效率更高,不覆盖已存在的键)
m.emplace(3, "橙子");
um.emplace(3, "橙子");
return 0;
}
emplace()比insert()更高效,因为insert()需要先构造键值对再拷贝/移动,而emplace()直接在容器内构造,减少内存拷贝。这一点在其他很多容器中都存在。
C++17引入了try_emplace(),当值不存在时才会插入:
#include <map>
#include <iostream>
#include <string>
using namespace std;
int main() {
map<int, string> m;
auto ret1 = m.insert({1, "香蕉"});
// 键1已存在,插入失败,不会修改值
auto ret2 = m.try_emplace(1, "黄香蕉");
cout << "map插入键1是否成功:" << boolalpha << ret2.second << endl; // 输出false
// 键2不存在,可以插入
auto ret3 = m.try_emplace(2, "水蜜桃");
cout << "map插入键2是否成功:" << boolalpha << ret3.second << endl;
return 0;
}
输出结果:

(2)查找元素
#include <map>
#include <unordered_map>
#include <iostream>
#include <string>
using namespace std;
int main() {
map<int, string> m{{1, "苹果"}, {2, "香蕉"}};
unordered_map<int, string> um{{1, "苹果"}, {2, "香蕉"}};
// 方式1:find()函数(返回迭代器,找不到返回end())
auto it1 = m.find(1);
if (it1 != m.end()) {
cout << "map找到键1:" << it1->second << endl; // 输出红苹果
}
auto it2 = um.find(3);
if (it2 == um.end()) {
cout << "unordered_map未找到键3" << endl;
}
// 方式2:[]运算符(不推荐用于查找!找不到会自动插入该键,值为默认值)
// 比如下面这行代码会给m插入键3,值为空字符串
// cout << m[3] << endl;
// 方式3:count()函数(返回键的个数,map/unordered_map键唯一,所以返回0或1)
if (m.count(2)) {
cout << "map存在键2" << endl;
}
return 0;
}
(3)遍历元素
#include <map>
#include <unordered_map>
#include <iostream>
#include <string>
using namespace std;
int main() {
map<int, string> m{{1, "苹果"}, {2, "香蕉"}, {3, "橙子"}};
unordered_map<int, string> um{{1, "苹果"}, {2, "香蕉"}, {3, "橙子"}};
// 方式1:范围for循环(C++11起支持)
cout << "map遍历(有序):" << endl;
for (auto& p : m) {
cout << p.first << ":" << p.second << endl;
}
// 输出:1:苹果 2:香蕉 3:橙子
cout << "unordered_map遍历(无序):" << endl;
for (auto& p : um) {
cout << p.first << ":" << p.second << endl;
}
// 输出顺序不确定,比如可能是2:香蕉 1:苹果 3:橙子
// 方式2:迭代器遍历
cout << "map迭代器遍历:" << endl;
for (auto it = m.begin(); it != m.end(); ++it) {
cout << it->first << ":" << it->second << endl;
}
return 0;
}
(4)范围查询
map支持lower_bound/upper_bound进行范围查找:
#include <iostream>
#include <map>
#include <iomanip> // 用于格式化输出金额
using namespace std;
int main() {
// 初始化订单数据:键(订单编号)有序排列
map<int, double> order_map = {
{50, 99.9},
{100, 199.9},
{120, 299.9},
{150, 399.9},
{180, 499.9},
{200, 599.9},
{250, 699.9},
{300, 799.9}
};
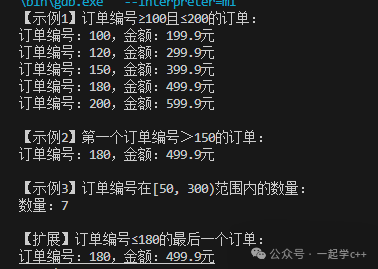
// ========== 示例1:查找[100, 200]区间的订单 ==========
cout << "【示例1】订单编号≥100且≤200的订单:" << endl;
// lower_bound(100):第一个≥100的元素(键100)
auto left = order_map.lower_bound(100);
// upper_bound(200):第一个>200的元素(键250),左闭右开区间
auto right = order_map.upper_bound(200);
// 遍历[left, right)区间,即100≤订单编号≤200
for (auto it = left; it != right; ++it) {
cout << "订单编号:" << it->first
<< ",金额:" << fixed << setprecision(1) << it->second << "元" << endl;
}
// ========== 示例2:查找第一个订单编号>150的订单 ==========
cout << "\n【示例2】第一个订单编号>150的订单:" << endl;
auto first_gt_150 = order_map.upper_bound(150);
if (first_gt_150 != order_map.end()) {
cout << "订单编号:" << first_gt_150->first
<< ",金额:" << fixed << setprecision(1) << first_gt_150->second << "元" << endl;
}
// ========== 示例3:统计[50, 300)区间的订单数量 ==========
cout << "\n【示例3】订单编号在[50, 300)范围内的数量:" << endl;
auto start = order_map.lower_bound(50);
auto end = order_map.lower_bound(300); // lower_bound(300) = 第一个≥300的元素(键300)
int count = 0;
for (auto it = start; it != end; ++it) {
count++;
}
cout << "数量:" << count << endl;
// ========== 扩展:查找订单编号≤180的最后一个订单 ==========
cout << "\n【扩展】订单编号≤180的最后一个订单:" << endl;
auto upper_180 = order_map.upper_bound(180); // 第一个>180的元素(键200)
if (upper_180 != order_map.begin()) {
auto last_lte_180 = prev(upper_180); // 迭代器前移一位,指向180
cout << "订单编号:" << last_lte_180->first
<< ",金额:" << fixed << setprecision(1) << last_lte_180->second << "元" << endl;
}
return 0;
}
输出结果:
lower_bound(key)返回指向第一个≥key的元素的迭代器,若所有元素都<key,返回end();
upper_bound(key)返回指向第一个>key的元素的迭代器,若所有元素都≤key,返回end();
map的范围查询遵循“左闭右开”原则,即[lower_bound(a), upper_bound(b)],对应a ≤ 键 < b。若要包含b,需用lower_bound(b)作为右边界。
核心差异总结
| 特性 |
map |
unordered_map |
| 底层实现 |
红黑树 |
哈希表(链地址法) |
| 有序性 |
按键升序排列(可自定义比较) |
无序(按哈希值存储) |
| 查找时间复杂度 |
O(log n)(红黑树查找) |
平均O(1),最坏O(n)(哈希冲突) |
| 插入/删除时间复杂度 |
O(log n)(红黑树调整) |
平均O(1),最坏O(n)(重哈希) |
| 内存占用 |
较高(红黑树节点含额外指针) |
较低(哈希表结构更紧凑) |
| 键的要求 |
支持比较运算符(<) |
支持哈希函数和==运算符 |
| 迭代器稳定性 |
插入/删除不失效(除被删元素) |
重哈希时所有迭代器失效 |
| 支持的操作 |
有序遍历、lower_bound/upper_bound |
快速查找、桶操作(如bucket_count) |
易错点和注意事项
map和unordered_map在使用中有一些常见错误,需要特别注意。
不要用[]运算符做查找
与set不同,map和unordered_map支持[]进行随机访问,但访问不存在的元素会自动创建一个默认值:
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main() {
map<int, string> m{{1, "苹果"}};
// 想查找键2,结果不小心插入了键2,值为空字符串
if (m[2] == "香蕉") { // 这里m已经多了一个键2!
cout << "找到香蕉" << endl;
}
cout << "map的大小:" << m.size() << endl; // 输出2,而不是1!
return 0;
}
正确做法:查找用find()或count(),只有要修改值时才用[]。
迭代器失效问题
map和unordered_map在迭代器失效方面有显著差异:
map的迭代器失效:
- 插入元素时,所有现有迭代器仍然有效。
- 删除元素时,只有指向被删除元素的迭代器失效。
// map迭代器失效示例
std::map<int, int> m;
// 插入一些元素...
auto it = m.find(5);
m.erase(it); // it现在失效,不能再使用
// 但其他迭代器不受影响
unordered_map的迭代器失效:
- 插入元素时,如果触发了rehash,则所有迭代器失效。
- 删除元素时,只有指向被删除元素的迭代器失效。
// unordered_map迭代器失效示例
std::unordered_map<int, int> um;
// 插入一些元素...
auto it = um.find(5);
um.insert({10, 20}); // 如果触发rehash,it可能失效
可以通过reserve()提前预留桶的数量,降低触发重哈希概率:
int main() {
unordered_map<int, string> um;
um.reserve(1000); // 提前预留1000个桶,避免后续重哈希
// 后续插入不会触发重哈希,迭代器更稳定
return 0;
}
自定义类型作为键/值时的错误
要自定义map类型,必须先重载<运算符:
#include <map>
#include <string>
#include <iostream>
using namespace std;
struct Point {
int x;
int y;
// 必须重载<,否则编译报错
bool operator<(const Point& other) const {
// 先比x,x相同比y
return x < other.x || (x == other.x && y < other.y);
}
};
int main() {
map<Point, int> m{{{1,2}, 10}, {{1,3}, 20}};
return 0;
}
要自定义unordered_map类型,必须提供哈希函数和重载==:
#include <unordered_map>
#include <map>
#include <string>
#include <iostream>
using namespace std;
struct Student {
int id;
string name;
// 重载了==
bool operator==(const Student& other) const {
return id == other.id;
}
};
// 自定义哈希函数
namespace std {
template<>
struct hash<Student> {
size_t operator()(const Student& s) const {
return hash<int>()(s.id); // 用id作为哈希依据
}
};
}
int main() {
unordered_map<Student, int> um{{{1, "张三"}, 90}};
return 0;
}
总结
map和unordered_map作为C++中常用的关联容器,各有其独特优势和适用场景。在数据结构的设计中,理解它们的底层实现至关重要。
map的核心优势:
- 元素按键有序排列。
- 稳定的O(log n)时间复杂度。
- 迭代器在插入时不会失效。
- 适合范围查询和有序遍历。
unordered_map的核心优势:
- 平均O(1)的插入和查找性能。
- 更高的缓存效率(连续存储桶)。
- 适合大量随机访问的场景。
选择map还是unordered_map,本质上是在有序性和原始性能之间做出权衡。掌握它们的特性和底层机制,有助于在实际开发中优化算法性能并做出合适的选择。
 发表于 2025-11-29 02:07:42
|
查看: 175|
回复: 0
发表于 2025-11-29 02:07:42
|
查看: 175|
回复: 0
