在2026年CES国际消费电子展的主题演讲中,NVIDIA CEO黄仁勋正式发布了新一代NVIDIA Rubin计算平台。
Rubin架构以美国天文学家Vera Florence Cooper Rubin的名字命名,是NVIDIA首款全公开的AI计算平台,采用芯片、互联、网络及机柜系统深度协同的设计方案。
通过多芯片协同工作,Rubin构建起一套在性能、成本效益与系统级安全性上全面优化的AI超算系统。其核心目标直指推理主导时代的关键挑战——系统性降低单位算力成本与单位Token成本。不同于Blackwell平台的渐进式升级,Rubin是一款围绕智能体AI(Agentic AI)、长上下文推理与大规模混合专家模型(MoE)重构的下一代计算架构,为AI应用的下一阶段发展奠定基础。
一、 NVIDIA Rubin平台核心架构
提升AI能力的技术路径正在发生转变。过去十年,性能提升主要依赖更大规模的模型与更长的训练时长;然而如今,随着模型架构向混合专家模型与智能体AI演进,推理阶段的算力消耗、通信压力与上下文管理成本,已逐渐超过训练阶段本身。
Rubin架构正是为应对这一变革而生。NVIDIA将其定义为具备“极致协同设计”特性的AI超算,由六大核心芯片类型构成,形成从计算、互联到存储的全链路优化体系:
- Rubin GPU:计算核心,配备8个HBM4内存堆栈。
- Vera CPU:专为智能体推理设计,搭载88颗自研Olympus架构Arm核心。
- NVLink 6交换机:实现GPU间海量数据的瞬时互联。
- ConnectX-9超级网卡:负责系统的高速网络连接,保障Rubin系统与其他机柜、数据中心及云平台的高效通信,是大规模训练与推理任务的网络基石。
- BlueField-4数据处理器(DPU):处理复杂的数据流转,驱动原生AI存储架构。
- Spectrum-6以太网交换机:支持大规模AI工厂扩展的下一代以太网设备。
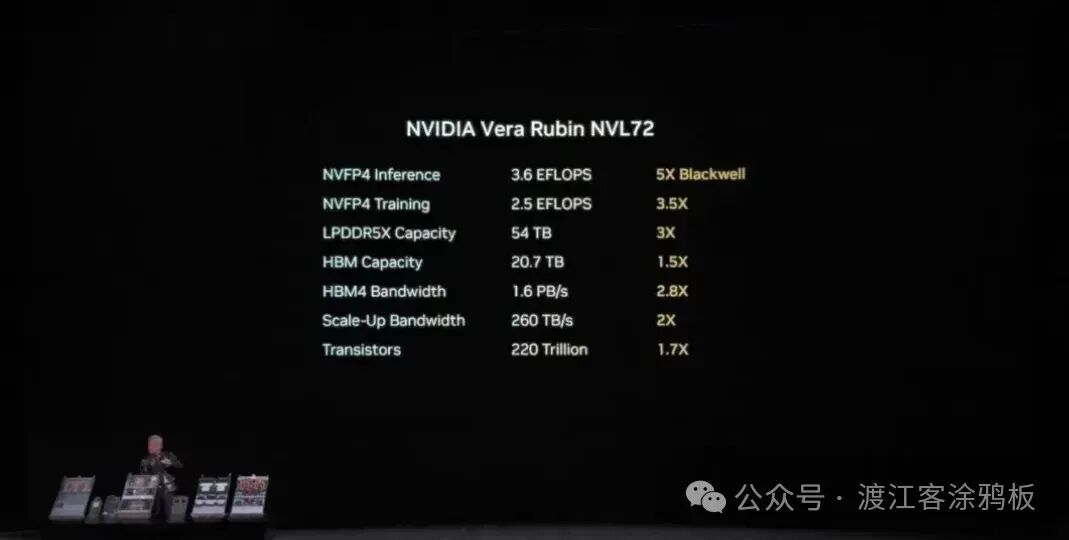
上述组件并非简单堆叠,而是围绕机柜级系统进行协同优化,最终构成Vera Rubin NVL72的核心。相较于上一代Blackwell平台,Rubin平台实现了跨越式的性能提升:
- 推理性能:NVFP4数据类型下推理性能高达50PFLOPS,提升幅度达5倍。
- 训练性能:NVFP4数据类型下训练性能高达35PFLOPS,提升幅度达3.5倍。
- 能效优化:采用100%液冷散热方案,能效水平显著提升。
二、 NVIDIA Rubin平台核心组件与技术创新
NVIDIA Rubin计算平台围绕推理驱动型AI负载完成系统性重构,从CPU、GPU到互联技术,再到系统级可靠性与安全性,形成一套高度协同的核心技术组合。
1、Vera CPU
与传统通用CPU不同,Vera CPU专为AI推理阶段的数据调度与多步骤推理逻辑设计,其核心特性如下:
- 88颗自研Olympus架构Arm核心
- 支持176线程空间多线程技术
- 最大可寻址1.5TB容量的LPDDR5X内存
- 内存带宽高达1.2TB/s
- 通过NVLink-C2C互联技术与GPU通信,带宽可达1.8TB/s

Vera CPU的定位并非“替代GPU”,而是承担数据流转、上下文调度与推理控制逻辑,让GPU专注于高密度计算任务,从系统层面提升推理效率。
2、Rubin GPU
Rubin GPU是整个架构中负责AI计算的核心组件,设计目标是让单颗GPU承载更多推理工作,降低对GPU数量的依赖。在核心指标上,Rubin GPU相较Blackwell实现代际跃升:
- NVFP4推理性能:50PFLOPS(提升约5倍)
- NVFP4训练性能:35PFLOPS(提升约3.5倍)
- HBM4内存:8个堆栈,总容量288GB
- 内存带宽:22TB/s
- 单GPU NVLink带宽:6TB/s(提升1倍)

NVIDIA Rubin GPU配备8个HBM4内存堆栈,单卡提供288GB内存容量与22TB/s内存带宽。第三代Transformer引擎引入硬件级自适应压缩能力,针对长上下文、多模态及大规模混合专家模型做专项优化,大幅降低单位Token的计算成本,为AI推理提供最高50 PFLOPS的NVFP4算力支持。
3、NVLink 6
在Rubin架构中,GPU间通信被提升至与计算同等重要的系统级资源地位。为满足推理驱动型与大规模混合专家模型的需求,NVIDIA第六代NVLink(NVLink 6)成为Rubin纵向扩展的核心基础设施,旨在实现机柜内多GPU间超低延迟、高一致性的协同工作。NVLink 6的核心技术特性包括:
- 单GPU互联带宽:6TB/s(双向)
- 单台NVLink 6交换机带宽:28TB/s
- 每台NVL72机柜最多可配置9台NVLink 6交换机
- 机柜级纵向总带宽:260TB/s

在技术实现层面,NVLink 6采用400G SerDes技术,将单GPU双向互联带宽提升至3.6TB/s。在Vera Rubin NVL72机柜中,9台NVLink 6交换机可构建出260TB/s的纵向扩展总带宽,让机柜内72颗GPU如同“超级GPU”般协同运作。这一带宽与拓扑规模,为超大规模混合专家模型提供了低延迟、高吞吐的GPU间通信保障,是Rubin实现推理成本大幅下降的关键基础。
此外,NVLink 6交换机集成了全网络计算能力,可加速各类集合通信操作,并在可维护性与系统弹性方面实现多项增强,为大规模训练与推理任务提供更高效、稳定的系统支撑。NVLink 6还具备更强的容错能力,支持零停机维护与机柜级可靠性、可用性和可维护性(RAS)功能。
4、Spectrum-X 以太网
当系统从单机柜扩展至多机柜乃至数据中心规模时,横向组网成为新的性能瓶颈。Rubin平台基于Spectrum-6芯片推出Spectrum-X以太网解决方案,核心特性如下:
- 单芯片带宽:102.4Tb/s
- 支持800G/200G端口配置
- 全液冷设计
- 集成共封装光学器件(CPO)与硅光技术

基于该架构打造的NVIDIA SN688(带宽409.6Tb/s,支持512个800G端口)与SN6810(带宽102.4Tb/s,支持128个800G端口)两款产品,均采用液冷设计,能效与可靠性大幅提升。相较传统方案,其在能效、可靠性与运行时长上优势显著,为多机柜AI工厂提供可持续扩展能力。
5、BlueField-4 数据处理器(DPU)
随着上下文窗口扩展至百万级Token规模,键值缓存(KV cache)的存储与访问逐渐成为推理性能的关键制约因素。Rubin平台推出基于BlueField-4 DPU构建的推理上下文内存存储平台,在GPU内存与传统存储之间搭建起“第三内存层”,其技术优势体现在三个层面:
- 硬件层面:BlueField-4加速上下文数据管理与访问,降低数据迁移开销。
- 网络层面:Spectrum-X以太网支持基于远程直接数据存取(RDMA)的高速数据共享。
- 软件层面:DOCA、NIXL、Dynamo等软件栈负责调度与优化,实现键值缓存的高效共享与复用。

在特定场景下可将Token吞吐量提升5倍,同时优化能效表现,为多轮智能体推理与多智能体协同提供稳定支撑。
6、第三代机密计算与RAS引擎
Rubin平台首次在机柜级实现英伟达第三代机密计算技术,将可信执行环境扩展至CPU、GPU与NVLink全领域,从芯片、架构到网络层面系统性保障模型与数据安全。
与此同时,第二代RAS引擎覆盖CPU、GPU与互联系统,提供实时健康监控、容错及主动维护能力。结合模块化、无电缆托盘式机柜设计,Rubin系统的部署与维护效率相较Blackwell提升高达18倍。
总体而言,这些核心组件与技术共同构成Rubin在性能密度、成本效益、安全性与扩展性方面的创新基石。
三、 NVIDIA Rubin平台系统形态
Vera Rubin NVL72机柜:集成72颗Rubin GPU、36颗Vera CPU及全套互联、存储组件。单机柜即可支持以往需要一整个数据中心才能承载的大模型训练与推理任务,实现计算密度与成本效益的革命性突破。
HGX Rubin NVL8系统:专为x86架构生成式AI平台设计的服务器主板。通过NVLink互联8颗Rubin GPU,可高效加速AI与高性能计算的训练、推理及科学计算任务。
DGX SuperPOD大规模部署方案:作为Rubin系统的大规模扩展参考架构,由8台Vera Rubin NVL72机柜(总计576颗GPU)组成,集成NVLink 6扩展网络、Spectrum-X以太网、推理上下文内存存储平台及Mission Control管理软件。该方案提供开箱即用的大规模AI基础设施,支持超大规模模型训练与海量智能体协同任务。
四、 NVIDIA Rubin平台生态
Rubin平台的核心价值在于大幅降低AI部署成本:训练MoE模型所需的GPU数量仅为Blackwell平台的1/4,推理阶段的单位Token成本降幅最高可达10倍。这一突破性进展将推动AI从小众前沿领域走向规模化普及,让长上下文、多模态、智能体等复杂人工智能技术在更多场景落地应用。
目前,Rubin平台已全面投入运行,基于该架构的相关产品将于2026年下半年通过合作伙伴正式面市:
- 云服务提供商:AWS、Google Cloud、Microsoft、OCI、CoreWeave等将率先部署Rubin实例。其中微软计划在Fairwater的AI超级工厂部署数十万颗Vera Rubin芯片。
- 硬件厂商:思科、戴尔、慧与(HPE)、联想、超微(Supermicro)等将推出基于Rubin架构的服务器产品。
- 人工智能实验室:Anthropic、Meta、OpenAI、xAI等机构已计划采用Rubin平台训练更大规模、更强性能的AI模型。
五、结束语
NVIDIA Rubin计算平台标志着AI超算迈入全新时代。从芯片到机柜的端到端协同设计,将推理性能、能效水平与系统级安全性提升至前所未有的高度。通过Rubin GPU、Vera CPU、NVLink 6、Spectrum-X网络与BlueField-4 DPU的深度协同,Rubin平台不仅大幅降低单位算力成本与单位Token成本,更能为长上下文、多模态及智能体AI模型提供高效支撑。依托NVL72、HGX Rubin NVL8及DGX SuperPOD等系统形态,Rubin实现从单机柜到大规模数据中心的灵活部署,为下一代计算架构技术的落地筑牢根基。更多关于前沿计算技术的深度讨论,欢迎访问云栈社区进行交流。
 发表于 2026-1-13 00:21:06
|
查看: 259|
回复: 0
发表于 2026-1-13 00:21:06
|
查看: 259|
回复: 0
