2026年1月20日,恰逢DeepSeek R1发布一周年之际,一个代号为“Model1”的模型意外出现在DeepSeek开源的FlashMLA代码更新中。这个突如其来的发现,迅速成为了技术社区讨论的焦点。
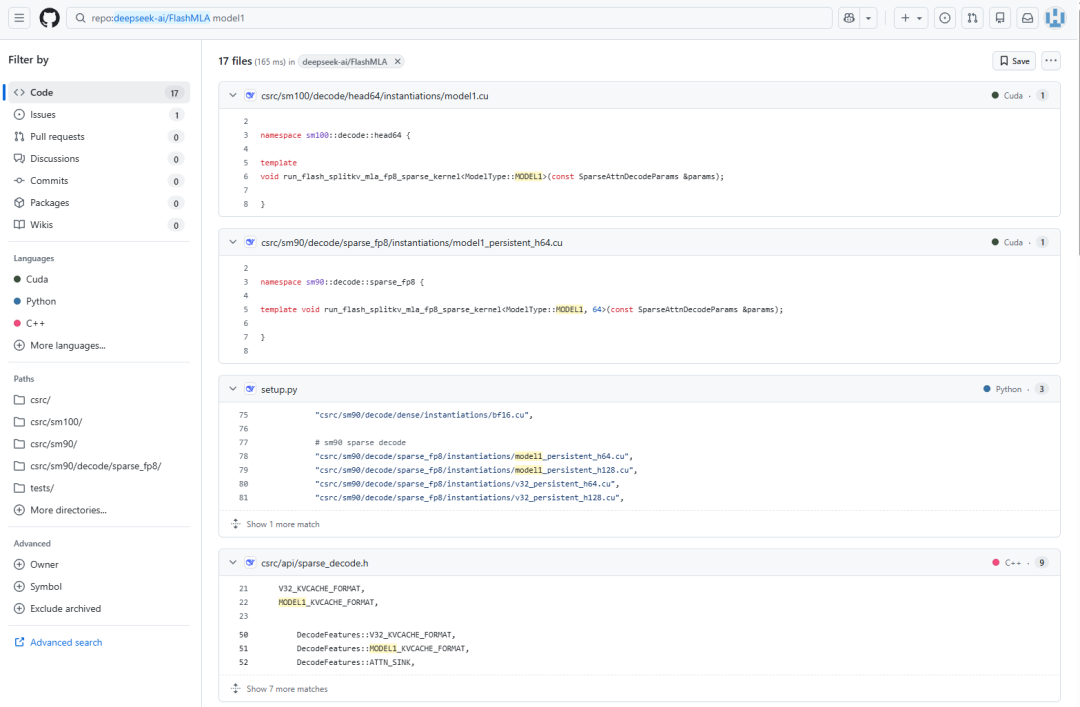
在对FlashMLA的代码更新进行梳理时,技术人员发现Model1的身影贯穿于28处记录中。一个关键细节是,在核心代码逻辑里,Model1与当前已知的V3.2模型是并列关系,两者拥有各自专属的架构配置参数。这表明Model1很可能并非V3系列的简单迭代版本,而是一条采用了全新框架的技术路线。
结合DeepSeek此前已公布的研究,例如用于解决大模型训练稳定性问题的mHC架构、优化MoE模型知识检索的Engram条件记忆模块,再加之此次Model1的现身,一系列技术信号共同指向一个结论:DeepSeek的新一代模型发布可能已经进入倒计时。
外界对于这款神秘模型的讨论异常热烈,各种基于代码细节的解读与预测层出不穷。
R2还是V4?关于Model1的多元猜想
网络上的技术人员对DeepSeek Model1进行了深入分析,给出了许多技术见解,主要围绕其架构、能力与参数量展开。
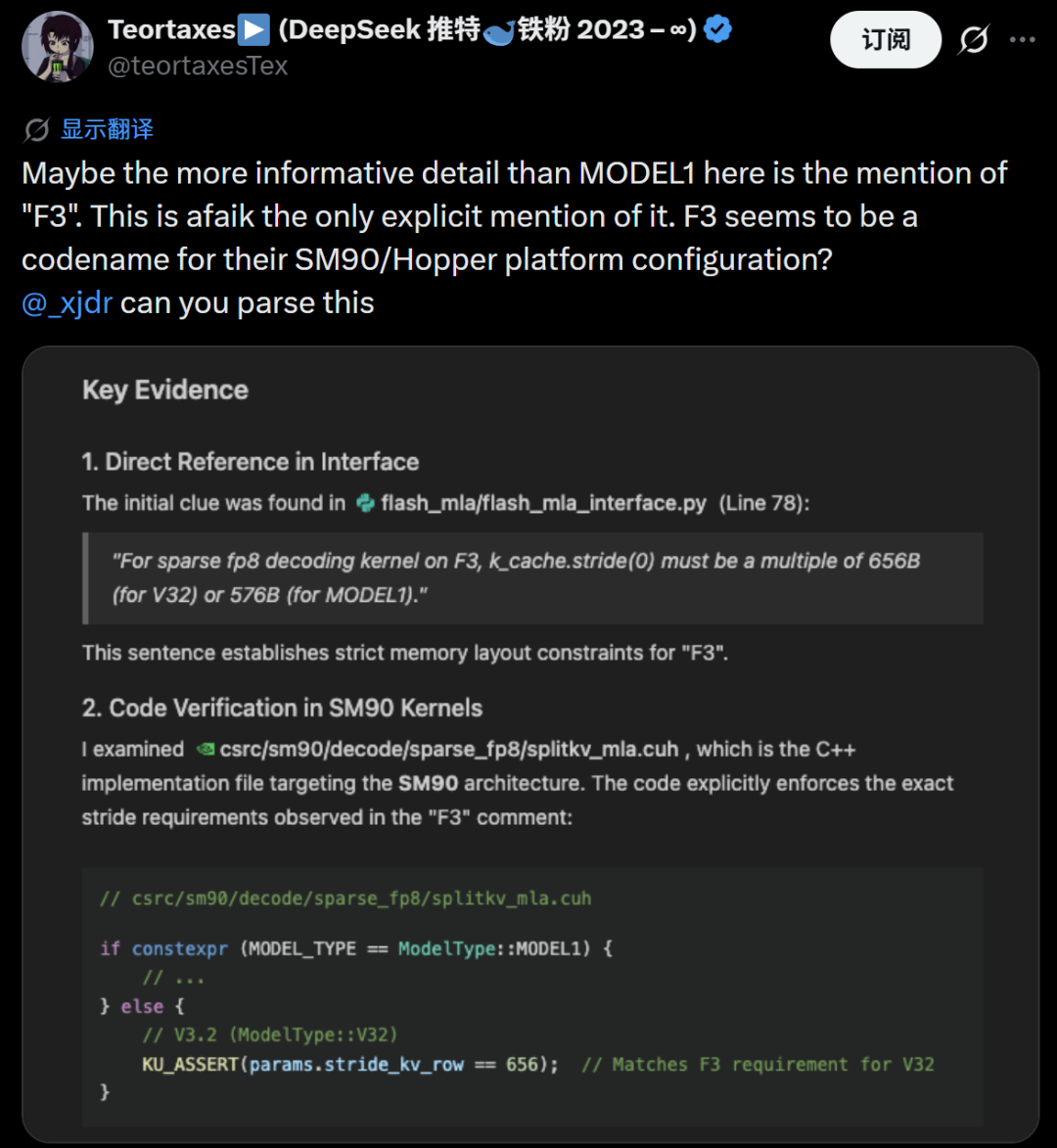
在检索Model1相关信息时,一个标注了“F3”的细节引起了注意。F3据信是DeepSeek内部的一个平台代号,这比单纯的“Model1”包含了更多信息。有分析认为,F3可能是针对NVIDIA SM90(即Hopper架构)计算平台的特定配置。
同时,有网友分析指出,这个神秘的Model1采用了512维的架构设计,并专门为NVIDIA的Blackwell B200 GPU进行了优化,同时整合了用于处理长上下文的token级稀疏MLA(Multi-Head Latent Attention)技术。

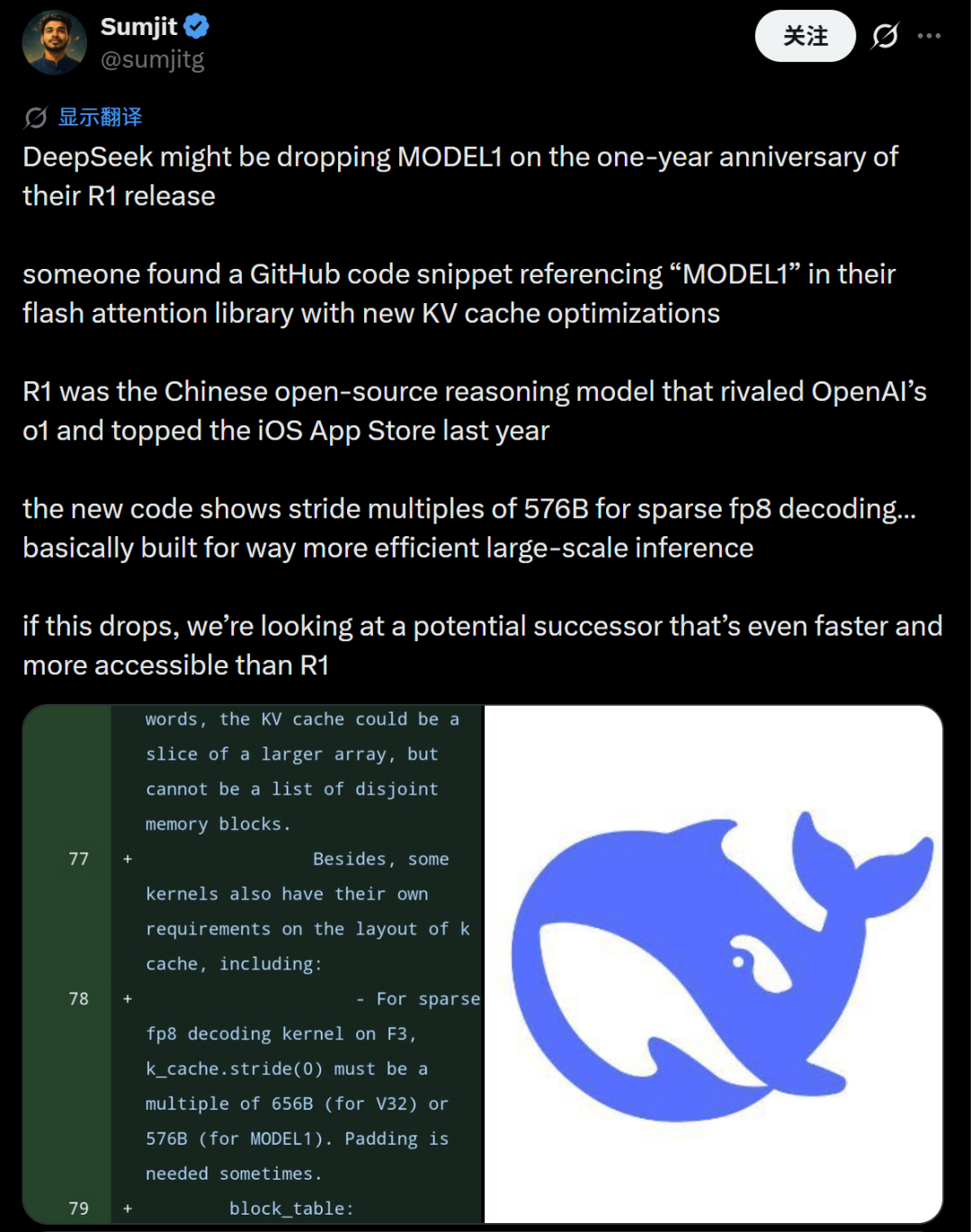
一个最直接的代码证据是,新的代码注释明确提到了Model1的k_cache(键缓存)在内存中的排列要求。注释显示,对于Model1,k_cache.stride(0)必须是576字节的倍数,而V3.2模型对应的要求是656字节。这一差异强烈暗示Model1采用了不同的内存布局,可能对应着全新的V4或R2模型。

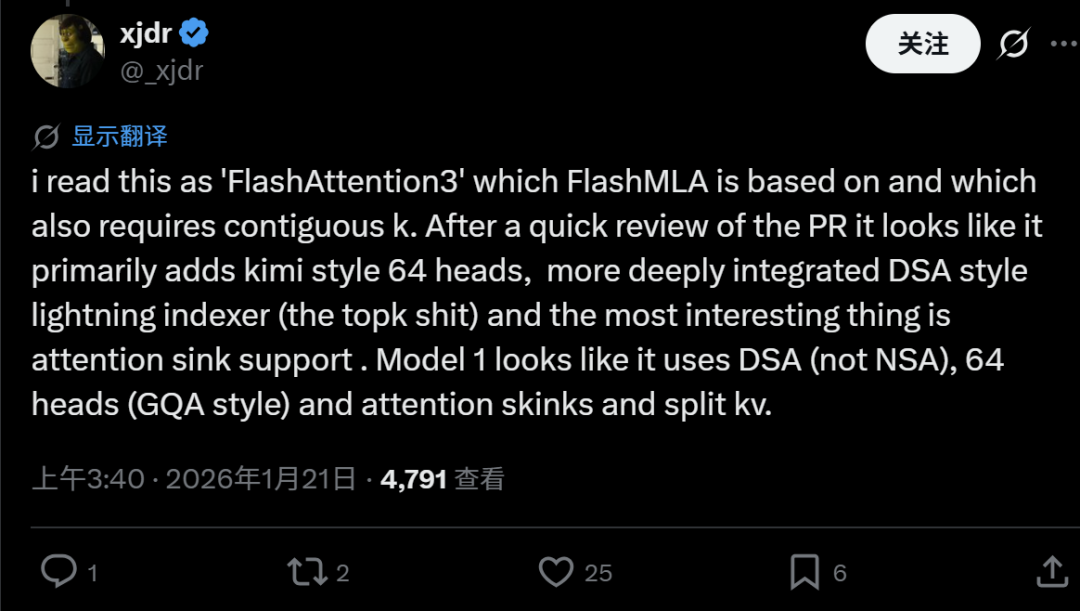
有网友在深入分析FlashMLA仓库后提出,Model1可能使用了DSA(可能是某种动态稀疏注意力机制)、64个注意力头(采用GQA分组查询注意力风格),并支持注意力汇聚(attention sinks)和分键值(split KV)技术。它可能集成了类似kimi风格的64头注意力以及更深层次集成的闪电索引器(lightning indexer),整体上可能是FlashAttention3的一个变体。
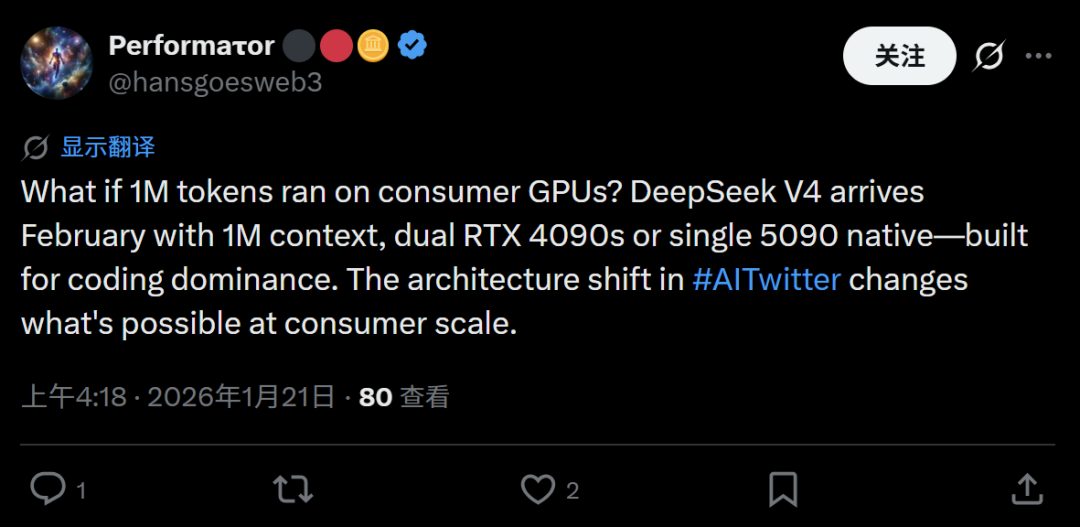
此外,也有预测指向了可能在2月发布的DeepSeek V4模型。有观点认为,新模型的能力或许能够“下放”到消费级硬件,从而改变人工智能应用的消费级格局。例如,实现100万(1M)的上下文长度,并仅通过双RTX 4090或单张RTX 5090显卡就能原生运行,尤其擅长编程任务。
在DeepSeek的FlashMLA库中,引用Model1的代码片段展示了新的KV缓存优化,其步长(stride)要求为576B(用于稀疏fp8解码),相比V3.2的656B更为高效。这种设计显然是针对大规模推理场景优化的,它很可能就是传奇模型R1的正式继任者。
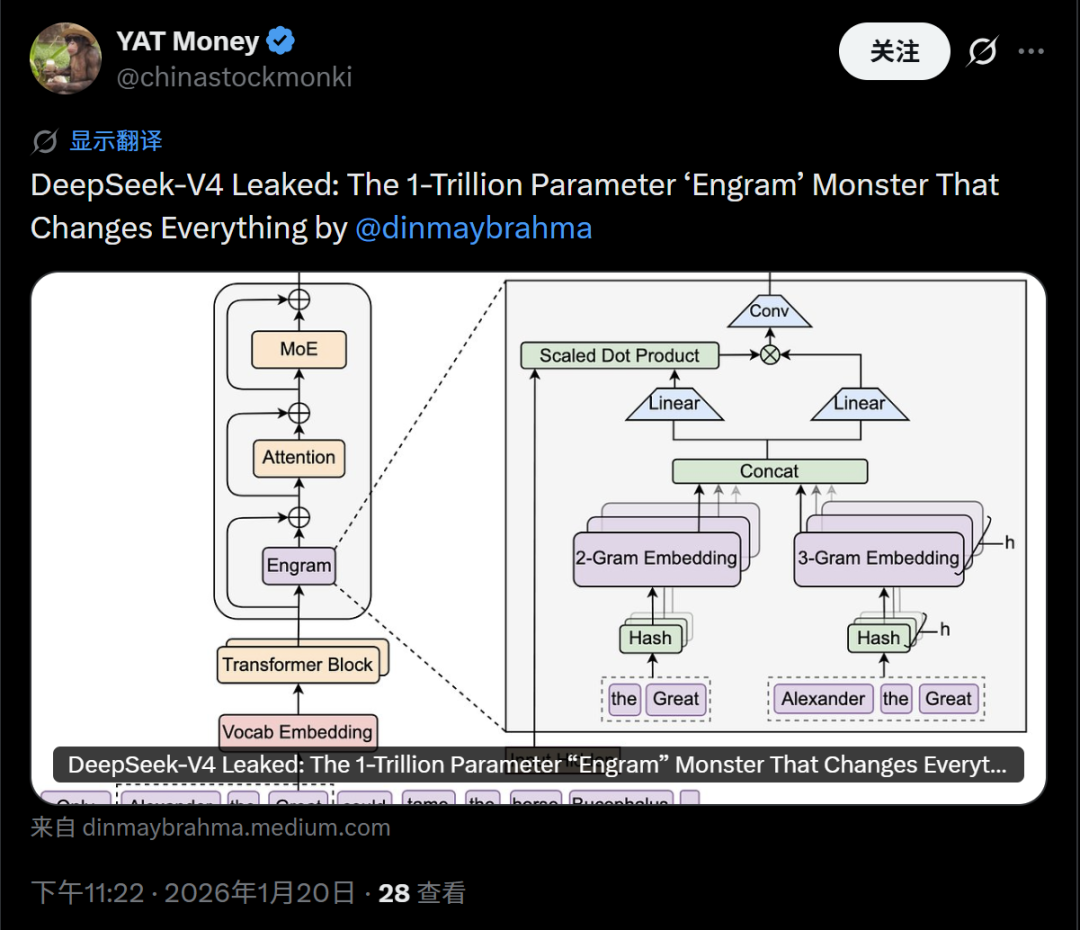
更夸张的猜想来自一份所谓的“泄露”,声称DeepSeek-V4将是一个拥有1万亿参数的“Engram怪物”,并可能彻底改变现状,而这个怪物可能就是Model1。
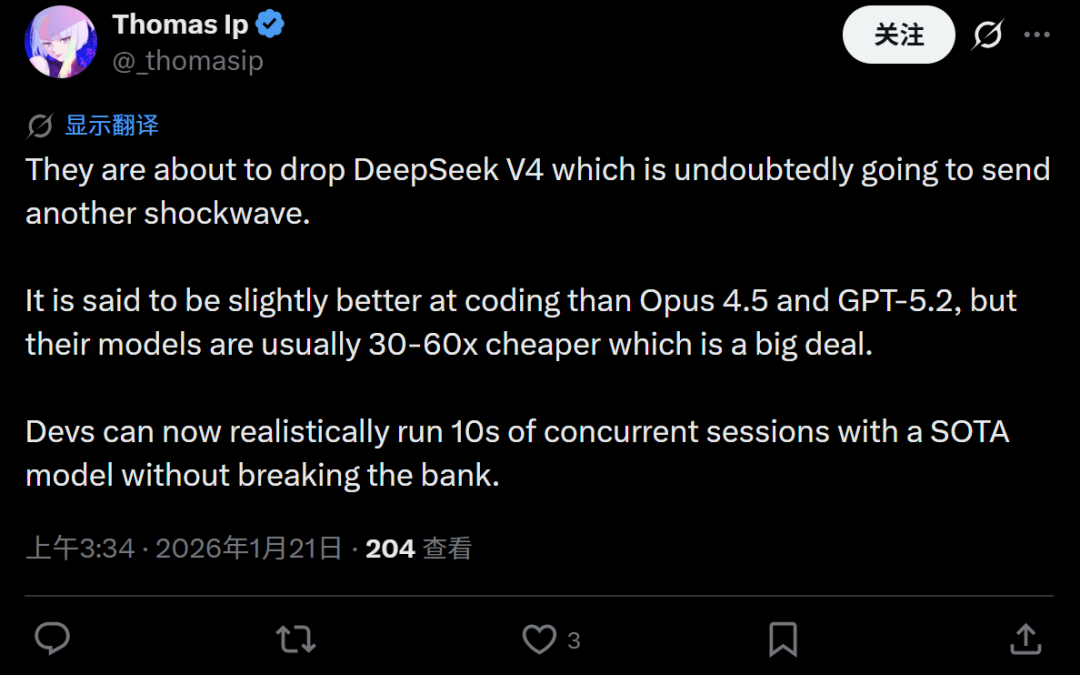
有网友评论称,“DeepSeek V4无疑将会引发另一场震撼”。据称,其代码能力可与Opus 4.5和GPT-5.2媲美,但价格却便宜30到60倍,这对于开发者生态而言是一个巨大的吸引力。
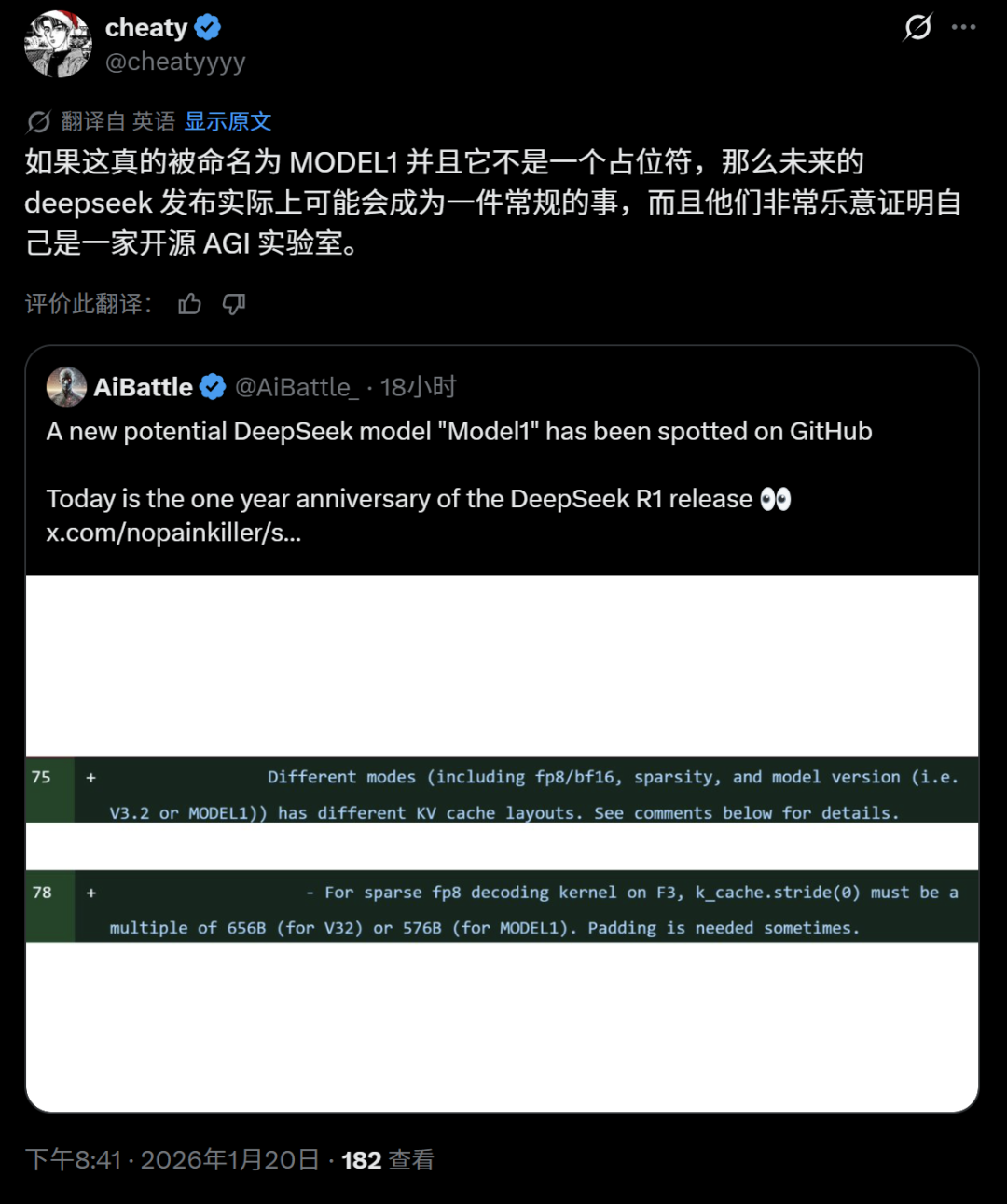
除了R系列(推理)和V系列(全能)的猜测,还有一种有趣的观点认为:如果“Model1”不是一个占位符,而就是新模型的实际名称,那可能意味着DeepSeek未来的模型发布将变得更加常规化和频繁,进一步彰显其作为开源AGI实验室的定位。
下一个“DeepSeek时刻”将至?
回顾DeepSeek的技术路线,其打造的追求极致综合性能的V系列与专注复杂推理的R系列,已经构筑了强大的竞争力。如今,Model1在代码库中密集出现,绝非偶然。从与V3.2并列的独立配置、专属的KV缓存与fp8精度支持,到可能整合的mHC、Engram等前沿技术,一切迹象都表明,一款神秘的新模型已完成核心储备,正蓄势待发。
DeepSeek在去年震撼硅谷后,其任何动向都备受全球同行关注。

网友们也在热议,今年即将发布的Model1,是否会像去年的R1一样,为全球科技圈带来一个新的“DeepSeek时刻”。
在全球大模型竞争白热化的环境下,Model1的来袭无疑让战局更加激烈。
甚至有美国网友直言:“总有一天,美国人会真正审视中国,并感到震惊!人们怎么还没意识到,DeepSeek的性价比惊人,其成本可能仅为其他模型的四分之一。他们2月的新模型V4将给美国模型带来巨大的麻烦。”
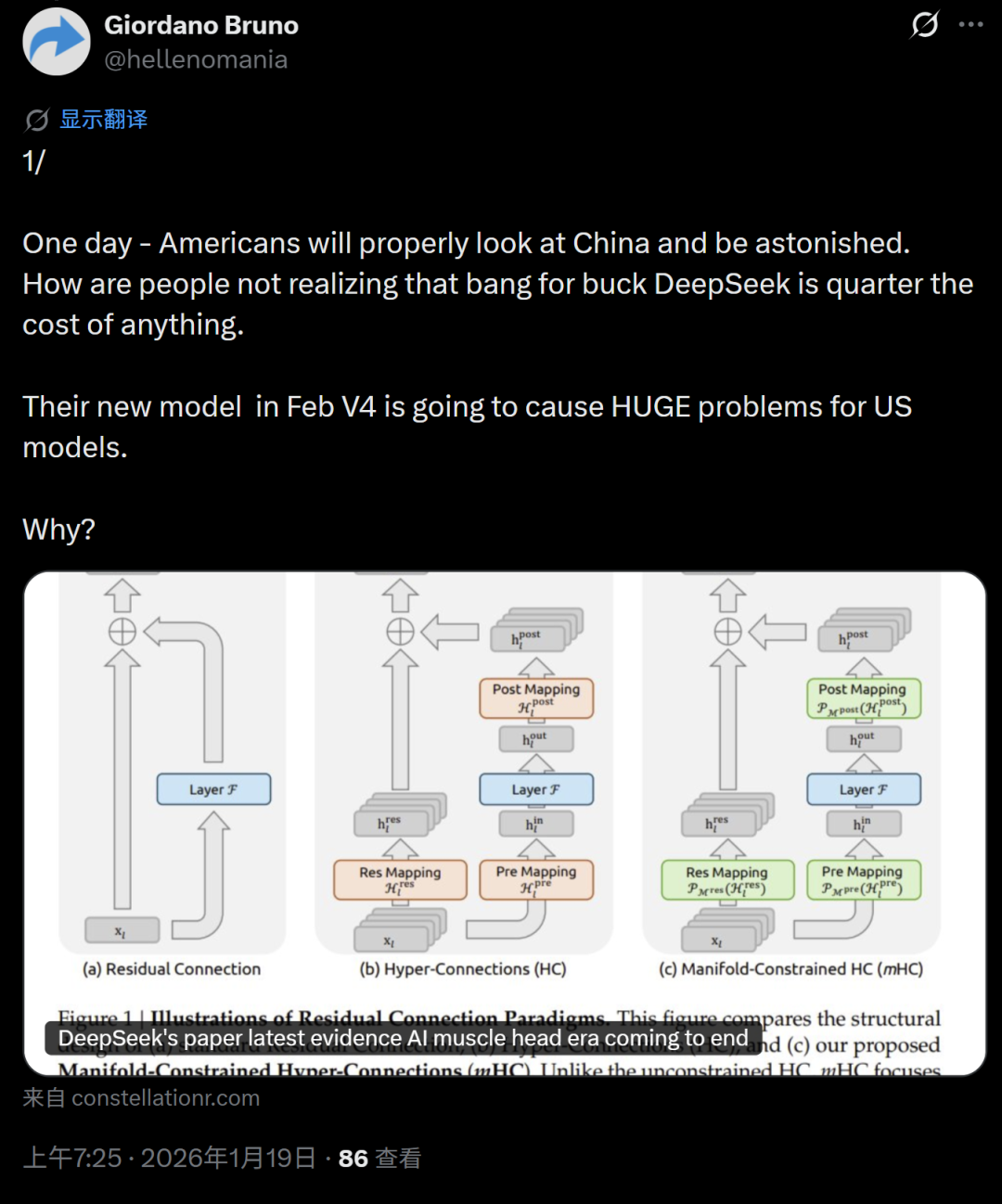
无论Model1最终是业界期待已久的R1继任者“R2”,还是多次传闻将在农历新年附近发布、主打超强代码能力的“V4”,它都极有可能成为承载DeepSeek下一代核心突破的旗舰模型。从社区的热烈讨论可以看出,市场早已翘首以盼。人们既期待新模型能降低使用门槛,让消费级显卡也能驾驭强大的长上下文能力;也期待它能延续R1的推理传奇,并在全球范围内再次掀起技术风暴。关于DeepSeek的更多技术动态和开源项目进展,也欢迎在云栈社区的开发者板块持续关注和交流。
 发表于 2026-1-24 04:00:58
|
查看: 303|
回复: 0
发表于 2026-1-24 04:00:58
|
查看: 303|
回复: 0
