
生成式AI可以说是人类创造的最复杂的应用程序之一。虽然其输出的结果可能简单易懂,但其背后的数学原理却异常复杂。与此同时,GenAI在内存带宽和容量方面也面临着严峻的瓶颈。这正是过去几年里,多家公司竞相推出各种“内存巨兽”(Memory Godbox)解决方案的核心驱动力。
通常,业界会采用CXL协议来扩展系统内存,将大容量的DDR内存作为相对高速的缓存,服务于高带宽但容量相对较低的HBM堆叠内存。这些HBM内存通常被封装在GPU或其他类型的XPU加速器上,专门用于处理AI工作负载。
近日,Enfabrica公司凭借其新推出的Emfasys内存集群,成为了这一领域的最新入局者。其目标直指一个潜在的“杀手级应用”——利用KV缓存来加速AI对复杂查询的推理性能。这或许正是Enfabrica及其同行们一直等待的市场突破口。
AI推理为何需要更多内存?
要理解Emfasys这类解决方案的价值,我们首先需要探讨AI推理在GPU/XPU上如何使用HBM内存,以及面临的性能瓶颈。
LLM(大语言模型)将信息分割成令牌(Token),并通过软件模拟的神经网络进行处理以生成参数。神经网络中的这些参数就像是虚拟神经元之间连接的权重。我们首先通过使用标注的数据集来训练AI,但当规模足够大时,如果给模型提供数万亿的信息片段(令牌),我们可以教会神经网络分解任何数据(如图片或文本块),并将其重新组合。
参数的数量决定了神经网络“思考”的丰富程度。在训练或推理时,被激活的参数必须存储在运行神经网络的计算引擎的HBM内存中。
在进行AI推理时,模型采用一种注意力(Attention)机制——需要记住查询中重要的内容(Key)和上下文中重要的内容(Value)来生成回答。问题在于,对于处理的每个新令牌,都必须为所有已处理的先前令牌重新计算Key和Value向量,以更新注意力权重。
因此,LLM引入了KV缓存机制。它通过将先前计算好的Attention KV向量存储在内存中,来加速后续令牌的处理和生成,从而避免每次都需要重新计算。
这些KV缓存可以保存在GPU和XPU的本地内存中。但由于每个计算引擎的HBM容量通常只有几百GB,如果遇到上下文窗口很大的任务,缓存很快就会被填满。此外,在推理运行时,模型权重和激活内存也必须存储在HBM中。KV缓存需要存储输入和输出的所有KV向量,这对内存容量构成了巨大挑战。
缓存嵌入和参数的需求,也是Nvidia致力于创建基于ARM的服务器CPU(如Grace),并使用NVLink将其与搭载HBM的GPU加速器紧密连接的原因之一。虽然单个Grace CPU的LPDDR5内存容量不到0.5TB,但这也远高于早期H100 GPU的80GB或96GB。随着KV缓存和嵌入需求的不断增长,GPU需要能够直接、高效地访问更庞大的主机服务器内存池。
内存已成为关键瓶颈。 拥有一个巨大的、以主机内存速度运行的共享内存池来存储KV向量和嵌入,是让推理运行得更快、更经济的一种有效方法。
CXL内存扩展方案迎来突破
早在2023年3月,Enfabrica就公布了其加速计算结构(ACF)架构。ACF-S设备,现在也被称为超级网卡(代号“Millennium”),本质上是融合了以太网和PCIe/CXL协议的交换芯片。通过将这三层网络融合,旨在消除对机架顶部以太网交换机、大量网卡/主机总线适配器以及机架内PCIe交换机的需求。
以下是ACF-S超级网卡的内部框图:
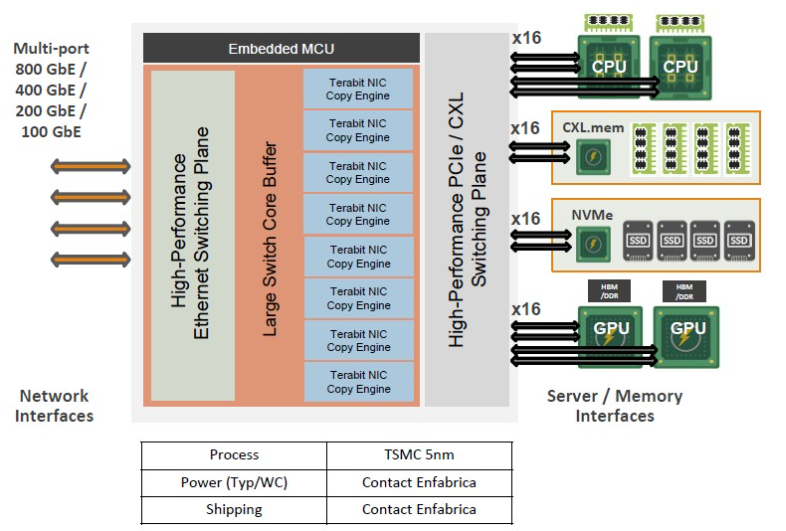
如图所示,该芯片可以连接多路CPU和GPU,并创建一个机架级的互联系统。而Emfasys内存“巨兽”正是该芯片针对AI推理工作负载的一种特定应用形态——作为独立的内存加速器和扩展器。
Emfasys内存系统详解
Emfasys系统的设计目标非常明确:大幅增加系统中GPU和XPU可用的内存容量。其系统架构如下:
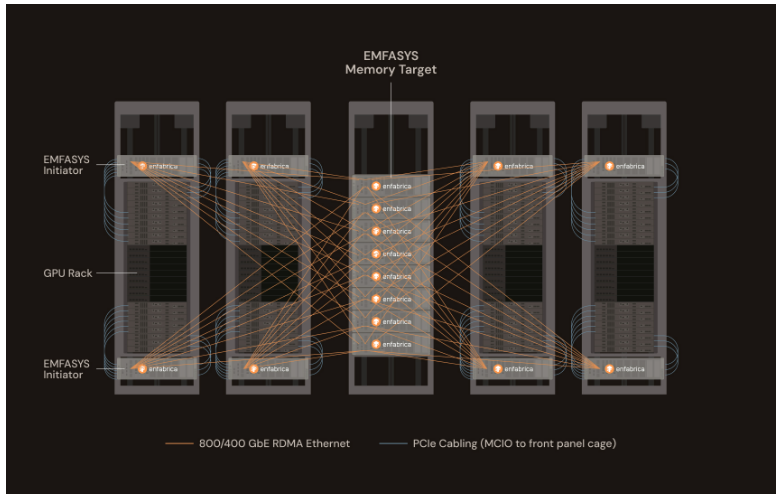
这是一个专门用于扩展内存容量的配置用例:
- 内存服务器:位于中央机架,共有8台。每台服务器安装了9个ACF-S超级网卡,每个网卡通道连接2个CXL内存DIMM。使用单条1TB的DDR5 DIMM时,每台服务器可提供18TB的内存容量。因此,8台服务器总共可提供高达144TB的共享内存池。
- GPU服务器:四个GPU服务器机架环绕中央内存机架。每个GPU机架内配有一对Emfasys启动器(Initiator)。
- 连接方式:启动器通过PCIe MCIO线缆直接连接到GPU服务器,然后通过800 Gb/s的以太网端口,使用RoCE RDMA技术低延迟地连接到排列在中央的内存服务器。
当然,1TB的DDR5内存条目前非常昂贵。为了控制成本,也可以选择容量更小的DIMM。例如,使用256 GB的DDR5内存条,则每个内存服务器可提供4.5 TB容量,整个内存机架总容量为36 TB。
对比来看,如果每个GPU的内存容量是192GB,那么需要192个GPU才能提供36TB的内存总量。而Nvidia的“Blackwell” B200 GPU单价可能高达4万美元。在GB200 NVL72系统中,每个B200 GPU只能访问共享在两个Blackwell GPU之间的Grace处理器上的LPDDR5内存。需要144个Grace CPU才能累加到36TB的KV缓存,并且这些缓存还是分散的。
Enfabrica的CEO Rochan Sankar在接受采访时解释了其优势:“我们本质上构建了一个具有海量内存的类云存储目标,芯片上有数十个端口,并在所有内存条上对事务进行条带化处理。为什么有人说CXL对AI没用?因为他们只关注单个CXL端口的带宽。但如果我们有一个非常庞大、宽广的内存控制器,可以跨所有内存条进行写入。现在,你可以利用多个链接的聚合带宽进行写入,从而获得尽可能高的内存带宽或吞吐量。”
Sankar还透露,目前的Emfasys机箱支持18个并行内存通道,而明年将升级到28个通道。
下图更详细地展示了KV缓存设置是如何连接在一起的:
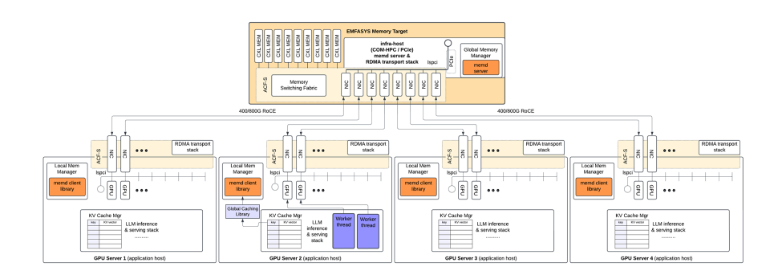
上图展示了四个GPU服务器连接到一个内存“巨兽”的情况,但该架构显然可以扩展到更大规模。
性价比与前景
Sankar没有提供Emfasys内存系统的具体价格,但他指出,与标准的DDR5内存相比,CXL内存本身并没有显著的溢价。最关键的是,Emfasys内存系统可以通过PCIe MCIO链路连接到任何GPU或XPU主机,然后这些加速器就能像访问本地扩展内存一样使用这个巨大的内存池,其体验类似于Grace CPU在Grace-Hopper或Grace-Blackwell复合体中为GPU提供内存的方式。
当被问及价格/性能优势时,Sankar表示,在四组Nvidia GB200 NVL72机架级系统上增加一组Emfasys机器,可以将AI推理中每个令牌(Token)的成本降低一半。考虑到内存服务器本身并不便宜,这个数据恰恰说明了由于内存容量限制,GPU的利用率有多低。为了将价值百万美元的内存服务器添加到价值数千万美元的Nvidia机架级机器中,从而实现令牌成本减半,意味着GPU通过添加内存将其吞吐量提高了一倍以上。
毫无疑问,这种能够显著提升现有昂贵AI计算资产利用率、降低推理成本的解决方案,将引起超大规模云计算厂商和大型企业的强烈关注。随着AI模型参数和上下文窗口的不断增长,对高效、大容量内存解决方案的需求只会越来越迫切。想了解更多关于人工智能和云计算领域的前沿技术动态,欢迎持续关注云栈社区的技术分享。
原文链接:
https://www.nextplatform.com/2025/07/29/skimpy-hbm-memory-opens-up-the-way-ai-inference-memory-godbox/
 发表于 2026-1-24 06:00:48
|
查看: 177|
回复: 0
发表于 2026-1-24 06:00:48
|
查看: 177|
回复: 0
