作为普通用户,你可能从未意识到,你浏览的每一个网页,在传输过程中大都经过了一次“瘦身”。
没错,服务器发送给你的 HTML、CSS 等文件,往往不是原始大小。如果你像开发者一样,按下 F12 打开浏览器的开发者工具,查看网络请求,很可能会看到这样的响应头信息:
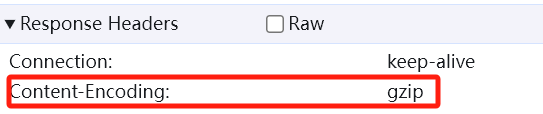
这张图的关键在于 Content-Encoding: gzip 这一行。它的潜台词是:“为了节省带宽、加快传输速度,我已经用 gzip 算法把内容压缩过了,你(浏览器)收到后需要先解压才能正常显示。”
在 HTTP 协议中,除了 gzip,常见的压缩算法还有 deflate、br(Brotli)等。这些算法看似五花八门,但追根溯源,很多都有一个共同的“祖先”:LZ 算法。
LZ 取自两位计算机科学家的姓氏:Abraham Lempel 和 Jacob Ziv。

这两位算法界的“老祖”在 2023 年相继离世,都属高寿。他们的智慧结晶,至今仍在全世界的每一比特数据流中默默工作。
起源:从最优编码到实时压缩
数据压缩主要分为两大类:有损压缩(如 MP3、JPEG)和无损压缩。前者通过舍弃一些人眼/人耳不敏感的信息来换取更大的压缩率;后者则要求解压后必须与原始数据完全一致,一个比特都不能错。
在 1948 年香农创立信息论后,研究者们便开始探索一个问题:如何为一段信息找到一种“最优”的编码方式,使其总长度最短?香农和他的学生法诺率先提出了香农-法诺编码。

这种方法通过将符号按概率分组,自顶向下构建一棵二叉树。
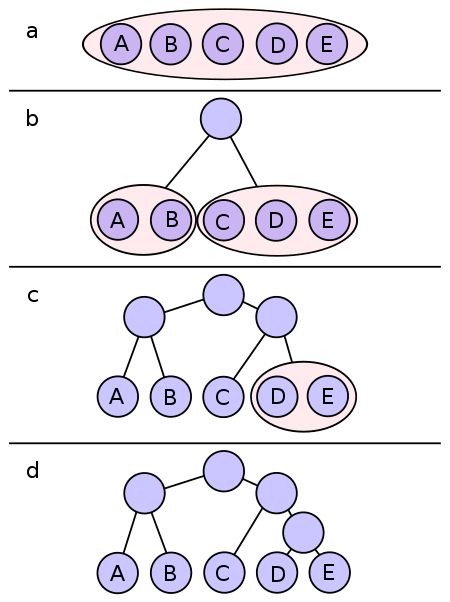
然而,香农-法诺编码并非总是最优解,且其生成的编码不一定是“前缀码”,可能导致解码歧义。后来,法诺在麻省理工学院教授信息论时,给学生们出了一道选择题:要么参加期末考试,要么尝试改进现有的数据压缩算法。
一位名叫霍夫曼的研究生选择了后者。他花了数月时间,一度想要放弃。就在他把笔记扔进垃圾桶的前一刻,一个优雅的想法闪过脑海:为什么不根据字符出现的频率,自底向上地构建二叉树呢? 这就是著名的霍夫曼编码算法。
霍夫曼算法实现了两个理想目标:
- 任何一个字符的编码,都不是其他字符编码的前缀(即前缀码)。
- 在满足前缀码的条件下,编码的总长度最小。
霍夫曼编码虽好,却有一个关键限制:它需要预先知道所有待编码符号出现的概率。在许多实际应用(尤其是实时通信)中,我们无法预知未来数据的统计特性。这个问题随着上世纪 70 年代互联网的萌芽而日益凸显。人们迫切需要一种能够边读取数据、边进行压缩的算法。
突破:LZ77与滑动窗口的诞生
以色列理工学院的 Ziv 和 Lempel 联手向这一挑战发起了进攻。他们是绝佳的搭档:Ziv 深谙统计学与信息论,而 Lempel 则在布尔代数和计算机科学领域造诣颇深。

1977年,两人同在贝尔实验室进行学术休假(一种带薪的长期研究假期)。就在这段宝贵的时间里,他们合作发表了里程碑式的论文《顺序数据压缩的通用算法》,提出了 LZ77 算法。
LZ77 的核心思想是“滑动窗口”和“动态字典”。它不再纠结于单个字符的频率,而是着眼于寻找重复出现的数据片段(如字符串、字节序列)。算法维护一个“历史缓冲区”(滑动窗口),对于当前待编码的数据,它会尝试在历史记录中找到最长的匹配字符串,然后用一个(距离偏移量,匹配长度)对来替代这段数据本身。
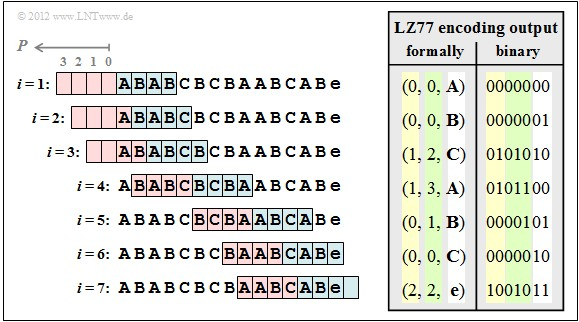
这张图清晰地展示了 LZ77 的编码过程。它最大的优点在于“通用性”和“在线性”:适用于任何类型的数据,无需预处理统计概率,只需一次遍历就能实现很高的压缩比。
次年,他们对算法进行了改进,提出了 LZ78。LZ78 能显式地构建并维护一个“字典”,压缩和解压效率更高,为后续许多变种算法奠定了基础。
乱战:从实验室走向千家万户
令人意外的是,如此强大的 LZ 算法在问世后的好几年里,主要停留在学术圈。直到 1984 年,DEC 公司的 Terry Welch 在 LZ78 的基础上创造了 LZW 算法,并被应用到 Unix 系统的 compress 程序中。随着 Unix 的流行,LZ 算法终于驶入了发展的快车道,但也开启了一个“群雄割据”的时代。
结语
从 LZ77 的开创性思想出发,到 LZW、Deflate、Gzip,再到我们每天右键点击文件就能创建的 ZIP 包,无损压缩技术经历了一场持续的演进与改进。但无论家族如何庞大,分支如何繁多,其核心原理依然深深烙印着 Lempel 和 Ziv 最初的智慧。
这些算法默默地工作着,压缩着网页、文档、程序,节省了海量的存储空间和网络带宽。可以说,LZ 算法及其庞大的“子孙后代”,早已以无形的方式,“统治”了我们数字世界的每一个角落,是信息时代当之无愧的基石技术之一。想了解更多有趣的计算机科学与技术发展史,欢迎来云栈社区交流探讨。
 发表于 2026-1-24 07:43:22
|
查看: 186|
回复: 0
发表于 2026-1-24 07:43:22
|
查看: 186|
回复: 0