就在 DeepSeek-R1 发布一周年的节点上,国产大模型领域掀起波澜。1 月 21 日凌晨,有开发者在 DeepSeek 官方 GitHub 仓库的代码更新中,意外发现了一个名为「MODEL1」的全新模型分支。
这个神秘模型在 114 个文件中被提及近 30 次,并且与当前的主力模型 V3.2 并列成为独立分支,种种迹象表明这并非一次简单的版本迭代,而可能代表着一次重大的架构更新。
从泄露的代码细节来看,MODEL1 似乎整合了多项前沿优化技术。例如,其优化了 KV 缓存布局,支持 FP8 稀疏解码,并且专门适配了最新的英伟达 Blackwell 架构,预计将在推理效率和显存占用上带来显著提升。更为关键的是,代码暗示其可能整合了长上下文优化机制,旨在解决大模型在处理超长文本时“记忆力”不足的痛点。
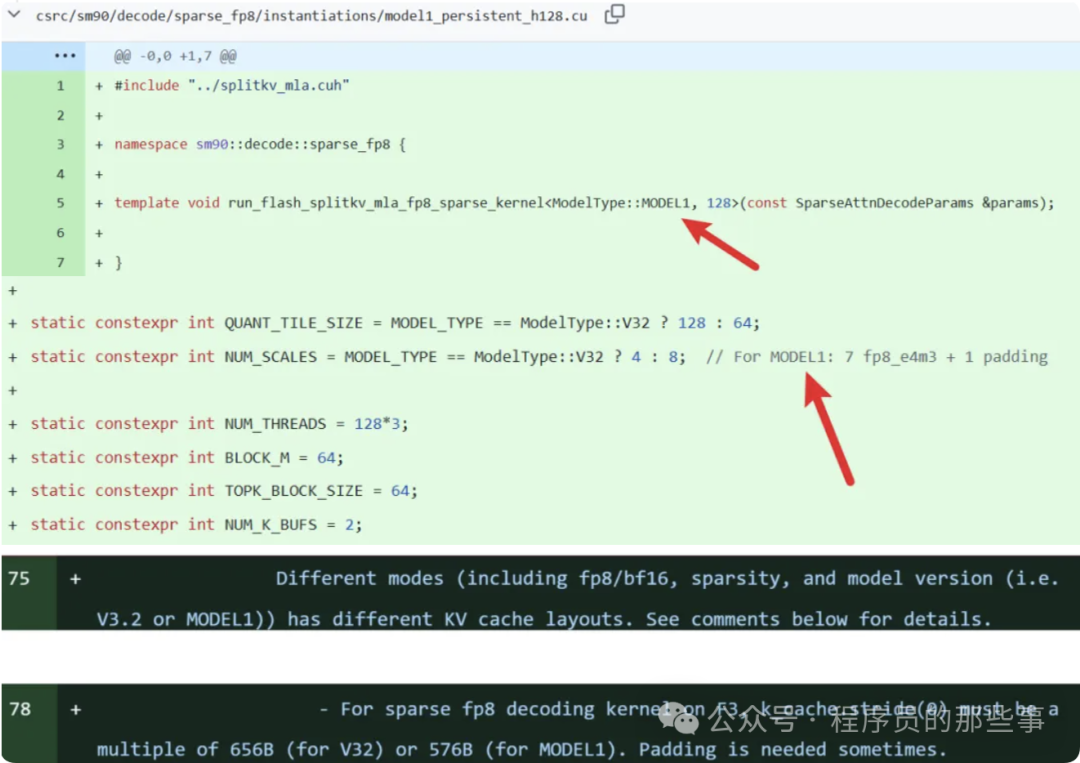
代码片段显示 MODEL1 在稀疏 FP8 解码内核上与 V3.2 的差异,包括量化块大小、缩放因子数量等参数的不同设置。
这一发现迅速在开发者社区和人工智能爱好者中引发了热烈讨论与猜测。主要观点分为两派:一派认为这极有可能是传闻已久但迟迟未发布的 R2 模型。毕竟 R2 早在 2025 年就有研发消息传出,后因芯片供应等问题延迟,其预期的技术方向与 MODEL1 泄露的特性高度吻合。
另一派则坚信这就是按命名惯例即将到来的 V4 模型。他们认为,V3.2 之后的全新架构,逻辑上就应该是 V4。无论是 R2 还是 V4,这次泄露都预示着一款性能更强、效率更高的国产大模型即将面世。
目前 DeepSeek 官方尚未对此事作出正式回应。不过,有行业消息称,这款新模型有可能在春节前后正式发布。无论最终命名为 R2 还是 V4,国产大模型的这次迭代都值得所有技术从业者保持关注。关于此事的最新动态和技术解析,你也可以在云栈社区与更多开发者一同交流探讨。
|  发表于 2026-1-24 08:23:14
|
查看: 137|
回复: 0
发表于 2026-1-24 08:23:14
|
查看: 137|
回复: 0
