发表于 2026-1-25 07:59:37
|
查看: 116|
回复: 0
发表于 2026-1-25 07:59:37
|
查看: 116|
回复: 0
4.
|
| 命令 | 经典场景 | 注意事项 |
|---|---|---|
SETBIT |
布尔状态记录(签到/在线) | 偏移量从0开始计算 |
BITCOUNT |
活跃度统计(DAU/MAU) | 大数据量时可能阻塞,可考虑分片 |
BITOP |
多标签交叉分析(用户画像) | 运算结果需存储在新key中 |
GETBIT |
实时状态检查 | 适合高频读取场景 |
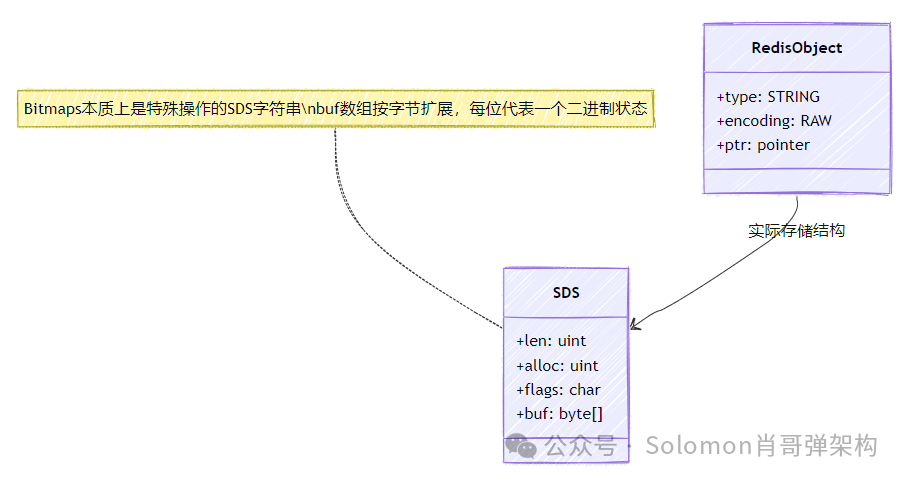
精确统计海量独立访客 (UV) 等去重计数需求时,使用 Set 存储可能导致内存爆炸。HyperLogLog 是一种概率算法,以固定的 12KB 内存空间,即可统计高达 2^64 个不重复元素,标准误差率仅为 0.81%。
与 Set 的直观对比:
| 方案 | 1亿独立用户内存占用 | 误差 |
|---|---|---|
| Set | ~5GB | 0% (精确) |
| HLL | 12KB | 0.81% (估算) |
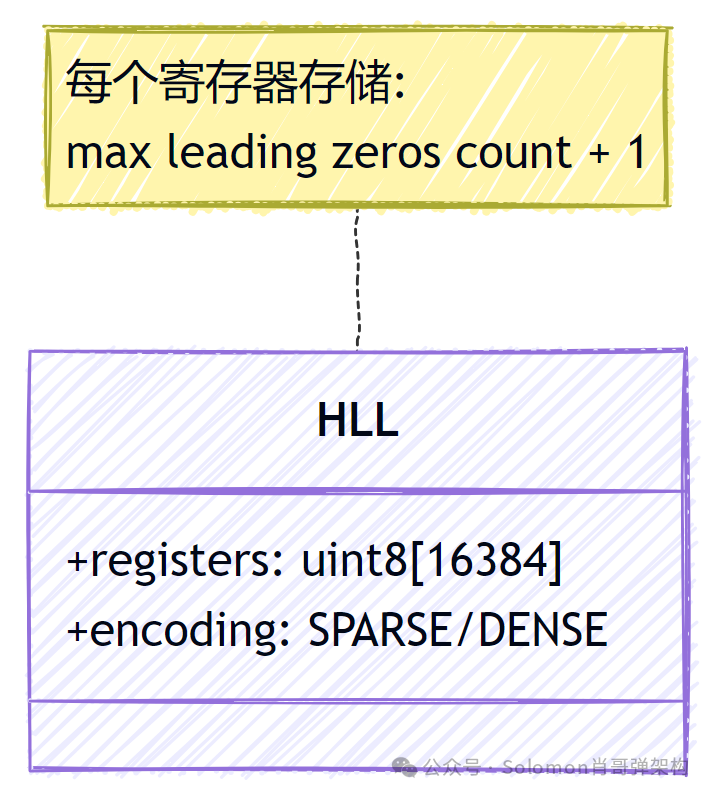
特征:基于概率的基数统计算法。
特点:固定 12KB 内存,可统计海量数据。
PFADD - 网站UV统计场景:记录每日独立访客。
# 记录用户访问(自动去重)
PFADD uv:20240320 “192.168.1.1” “10.0.0.2”特点:无论添加多少次相同元素,在统计时只计为 1 个。
PFCOUNT - 多维度UV计算场景:计算本周总 UV(合并多日数据)。
# 合并统计3天的独立访客数
PFCOUNT uv:20240320 uv:20240321 uv:20240322误差说明:标准误差 0.81%,实际误差随数据量增大趋于稳定。
PFMERGE - 跨渠道用户统计场景:合并 App 端和 Web 端的独立用户数。
# 合并两个平台的访问用户
PFMERGE uv:total uv:app uv:web
# 获取总UV
PFCOUNT uv:total内存效率:合并后仍只占用约 12KB 内存。
# 每小时滚动统计(Python示例)
def update_uv(user_ip):
# 记录到当前小时和总UV
redis.pfadd(f"uv:{datetime.now():%Y%m%d%H}", user_ip)
redis.pfadd("uv:total", user_ip)
# 大屏展示(每5分钟刷新,计算当日截至当前的总UV)
current_hour = datetime.now().strftime("%Y%m%d%H")
today_uv = redis.pfcount(*[f"uv:{current_hour[:-2]}{i:02d}" for i in range(24)])
total_uv = redis.pfcount("uv:total")# 统计参与A/B测试的总独立用户数(去重)
PFMERGE ab_test:users group_a:users group_b:users
PFCOUNT ab_test:users| 命令 | 经典场景 | 注意事项 |
|---|---|---|
PFADD |
实时流量统计(点击/访问) | 需客户端保证元素序列化一致性 |
PFCOUNT |
多维度聚合计算(周/月UV) | 误差随数据量增大而相对减小 |
PFMERGE |
跨数据集去重(渠道合并) | 合并后误差可能略微增大 |
随着 LBS(基于位置服务)需求爆发,Redis Geospatial 提供了原生的地理位置存储与查询能力。它巧妙复用了 Sorted Set 数据结构,通过 Geohash 算法将二维的经纬度编码为一维的分数 (score),从而支持高效的范围查询。
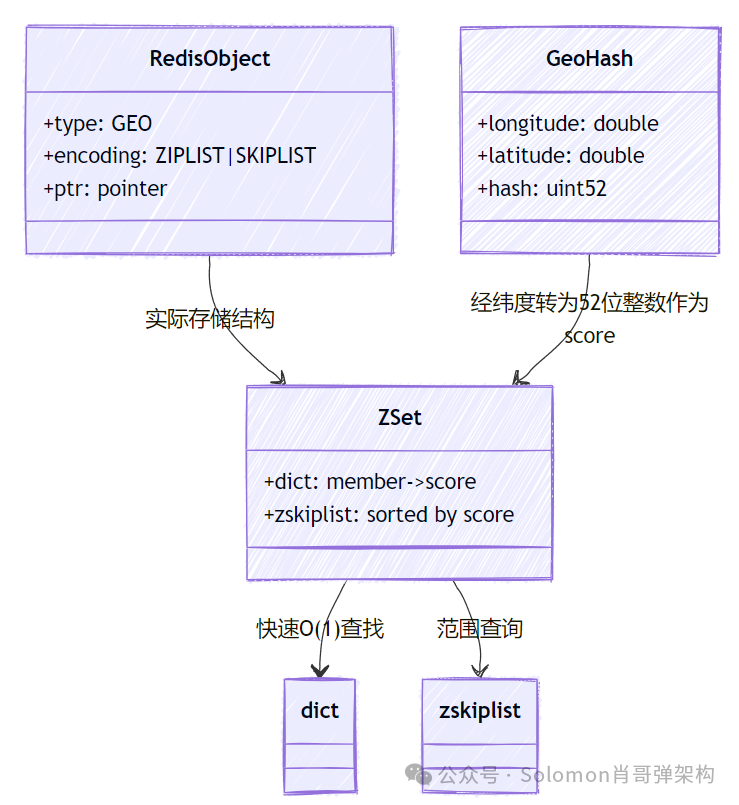
特征:基于 Sorted Set 实现的经纬度存储。
特点:支持半径查询、距离计算和坐标获取。
GEOADD + GEORADIUS。GEOADD - 门店/车辆位置更新场景:共享单车或外卖骑手实时位置上报。
# 添加/更新单车位置(经度116.404, 纬度39.915)
GEOADD bikes:locations 116.404 39.915 “bike_1001”特点:位置变更时,新坐标直接覆盖旧坐标。
GEOPOS - 导航定位查询场景:获取外卖员或车辆的当前位置。
# 查询骑手当前位置
GEOPOS delivery:riders “rider_205”输出:[“116.404”, “39.915”] (经度,纬度),精度约为0.1米。
GEODIST - 配送距离计算场景:估算商家到顾客的直线距离。
# 计算两个位置的距离(单位:公里)
GEODIST stores:locations “starbucks_001” “customer_888” km算法:使用 Haversine 公式计算球面距离。输出示例:“1.234” 表示1.234公里。
GEORADIUS - 附近服务推荐场景:查找用户5公里内的所有加油站。
# 以用户当前位置为中心搜索,返回带距离和坐标
GEORADIUS gas:stations 116.404 39.915 5 km WITHDIST WITHCOORD输出:包含地点ID、距离和坐标的列表。
-- Lua脚本检查车辆是否驶出电子围栏
local key = KEYS[1]
local vehicle = ARGV[1]
local fence_lon, fence_lat, radius = tonumber(ARGV[2]), tonumber(ARGV[3]), tonumber(ARGV[4])
local pos = redis.call('GEOPOS‘, key, vehicle)
if not pos then return 0 end
-- 构建一个临时成员用于距离计算(这里是一种思路,实际需调整)
local dist = redis.call('GEODIST', key, vehicle, table.concat({fence_lon, fence_lat}, ":"), ‘m’)
if tonumber(dist) > radius then
send_alert(vehicle) -- 触发告警
return 1
end
return 0# 找出用户当前位置10公里内最近的3个充电桩(Python示例)
results = redis.georadius(
"charging:piles",
current_lon,
current_lat,
10, # 最大搜索半径10km
unit="km",
withdist=True,
sort="ASC", # 按距离升序排序
count=3 # 只返回距离最近的3个
)| 命令 | 经典场景 | 注意事项 |
|---|---|---|
GEOADD |
实时位置更新(车辆/人员) | 坐标需验证有效性(经度-180~180,纬度-85~85) |
GEORADIUS |
附近地点推荐/搜索 | 数据量极大时可考虑按地理区域分片存储 |
GEODIST |
运费/配送时间估算 | 计算的是直线距离,而非实际导航路径 |
GEOPOS |
位置追踪 | 需处理成员不存在的情况,返回nil |
当需要消息队列功能时,Redis List 存在消息消费即删除、无法回溯、缺乏消费组支持等痛点。Redis Stream 作为持久化的、支持消费者组的消息队列数据结构,提供了轻量级的 Kafka 替代方案,尤其适合高并发场景下的异步任务、事件溯源等。
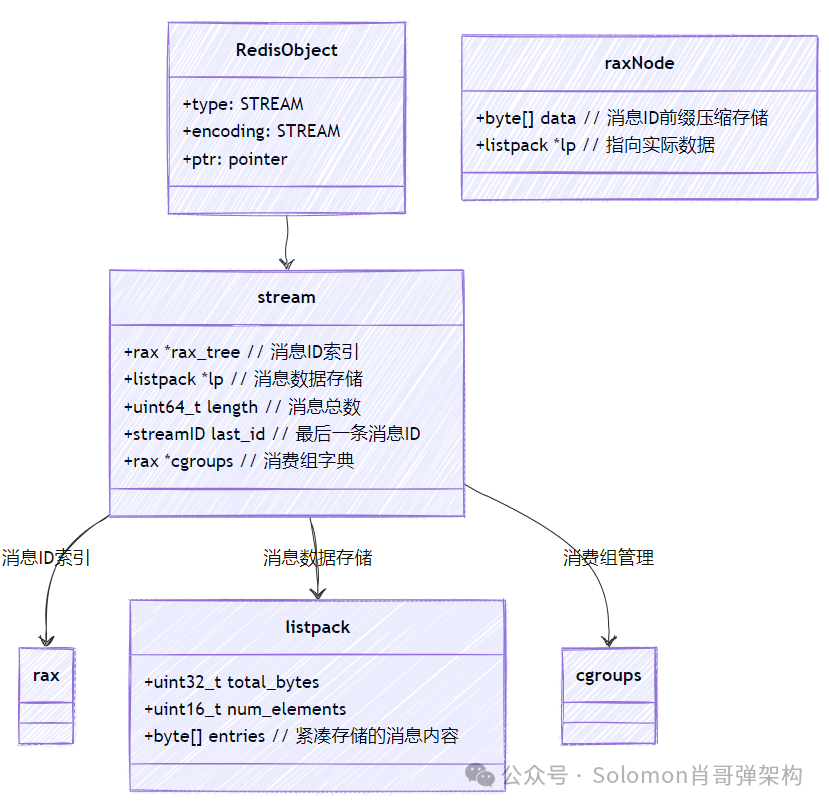
特征:持久化的、可追加的消息日志。
特点:支持多消费者组、消息回溯、阻塞读取。
消息ID结构:<毫秒时间戳>-<序列号>,例如 1639872992000-42,保证严格递增。
XADD - 订单事件流场景:记录电商订单的状态变更事件。
# 记录订单支付事件(* 表示由Redis自动生成消息ID)
XADD orders:events * order_id 1001 action “payment” amount 299.00特点:每个消息可包含多个键值对 (field-value)。
XREAD - 实时监控报警场景:单消费者阻塞读取服务器错误日志。
# 阻塞读取最新错误日志,最多等待5秒
XREAD BLOCK 5000 STREAMS logs:error $注意:$ 表示只接收调用此命令后到达的新消息。
XGROUP - 多团队协作场景:为订单处理流程创建消费者组。
# 创建一个名为‘order_processors’的消费者组,从最新消息开始消费
XGROUP CREATE orders:events order_processors $ID策略:$ 从最新消息开始;0 从第一条历史消息开始;也可指定具体 ID。
XREADGROUP - 分布式任务处理场景:多个客服 worker 从同一个咨询工单流中竞争获取任务。
# 客服Worker代码示例(Python伪代码)
while True:
# 从‘customer_service’消费者组,以‘worker1’身份获取新消息
messages = redis.xreadgroup(
‘customer_service’,
‘worker1’,
{‘tickets’: ‘>’}, # ‘>‘ 表示获取尚未分派给其他消费者的新消息
count=1,
block=30000
)
if messages:
process_ticket(messages[0][‘tickets’][0])XACK - 任务完成确认场景:确认支付消息已被成功处理。
# 确认ID为‘1639872992000-0’的消息已处理完成
XACK payments:events payment_workers 1639872992000-0必须调用:否则该消息会一直停留在消费者的 Pending Entries List (PEL) 中,导致重复消费。
-- Lua脚本实现带重试次数限制的消息消费
local msg = redis.call(‘XREADGROUP’, ‘GROUP’, ‘mygroup‘, ‘myconsumer’, ‘COUNT’, ‘1’, ‘STREAMS’, ‘mystream‘, ‘>’)
if not msg then return end
local id = msg[1][2][1][1]
local delivery_count = redis.call(‘HGET’, ‘msg:‘..id, ‘count’) or 0
if tonumber(delivery_count) > 3 then
-- 重试超过3次,确认并移入死信队列
redis.call(‘XACK’, ‘mystream‘, ‘mygroup‘, id)
redis.call(‘XADD’, ‘dead_letters’, ‘*’, ‘failed_id‘, id)
else
-- 增加重试计数
redis.call(‘HINCRBY’, ‘msg:‘..id, ‘count’, 1)
end
return msg# 记录用户1001的关键行为事件
XADD user:1001:history * event_type registration ip “192.168.1.1”
XADD user:1001:history * event_type profile_update name “Alice”
XADD user:1001:history * event_type payment amount 100
# 通过重放所有事件,重建用户当前状态
XRANGE user:1001:history - + # ‘-‘ 和 ‘+‘ 分别表示最小和最大ID,即获取全部| 命令 | 经典场景 | 注意事项 |
|---|---|---|
XADD |
事件溯源、审计日志、实时数据流 | 消息ID保持时间有序有利于回溯和分析 |
XREADGROUP |
分布式任务队列、微服务间通信 | 需监控消息堆积,处理消费者离线 |
XACK |
确保消息至少被处理一次 (at-least-once) | 必须实现,否则是典型的生产问题 |
XGROUP |
多团队/多服务协同处理同一数据流 | 生产环境建议对消费者组设置监控 |
无论使用哪种高级数据结构,以下通用禁忌都值得警惕:
EXPIRE),防止无用数据常驻内存,引发内存耗尽。KEYS 命令:生产环境严禁使用 KEYS * 这类命令,它会阻塞 Redis 服务。使用 SCAN 命令进行迭代式扫描。MULTI/EXEC) 的局限性:它并非原子性的回滚事务,而是将命令打包顺序执行。在涉及多个键且需要强一致性的场景下慎用。通过深入理解 Bitmaps、HyperLogLog、Geospatial 和 Stream 的原理与适用场景,你可以在设计系统时做出更优的技术选型,以极低的资源成本应对海量数据挑战。这些高级功能正是 Redis 在众多数据库/中间件中脱颖而出的关键之一。希望本文的深度解析能成为你实战中的得力参考。更多技术干货与实践讨论,欢迎访问 云栈社区。