多年前基于 PVE(Proxmox VE)搭建的私有云环境,使用了其内置的 Ceph 存储。最近,集群的健康状态开始频繁报警。
查看集群状态,发现了慢操作和对象降级的告警:
# ceph health
HEALTH_WARN 8 OSD(s) experiencing slow operations in BlueStore; Degraded data redundancy: 318313/5100831 objects degraded (6.240%), 106 pgs degraded, 106 pgs undersized
root@node03:~# ceph health detail
HEALTH_WARN 8 OSD(s) experiencing slow operations in BlueStore; Degraded data redundancy: 318263/5100831 objects degraded (6.239%), 106 pgs degraded, 106 pgs undersized
[WRN] BLUESTORE_SLOW_OP_ALERT: 8 OSD(s) experiencing slow operations in BlueStore
osd.1 observed slow operation indications in BlueStore
osd.2 observed slow operation indications in BlueStore
osd.3 observed slow operation indications in BlueStore
osd.5 observed slow operation indications in BlueStore
osd.9 observed slow operation indications in BlueStore
osd.10 observed slow operation indications in BlueStore
osd.11 observed slow operation indications in BlueStore
osd.12 observed slow operation indications in BlueStore
虽然通过PVE节点的Web界面查看磁盘的SMART检测结果都显示为“PASSED”,但心里总觉得不踏实。
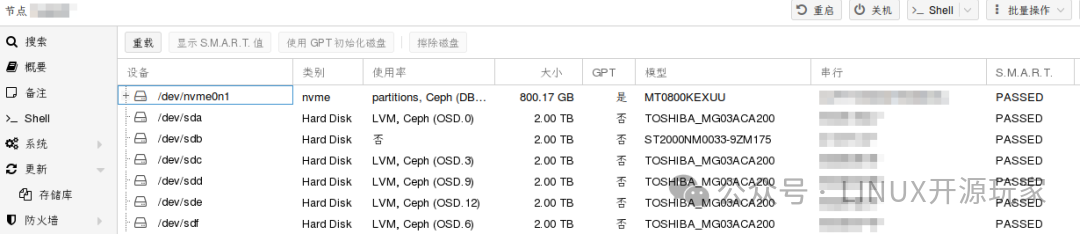
为了更放心,我决定手动检查所有磁盘的关键SMART属性,尤其是重定位扇区数。检查后发现 sdb 硬盘的“重定位事件计数”非常高,于是决定用另一块硬盘 sdf 来替换它(上方的截图是替换完成后的状态)。
# DISKs=$(ls /dev/sd[a-z])
# for DISK in ${DISKs[@]}; do ls $DISK; smartctl -a $DISK | grep -E 'Reallocated|Pending|Uncorrectable'; done
/dev/sda
5 Reallocated_Sector_Ct 0x0033 100 100 050 Pre-fail Always - 0
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 100 000 Old_age Offline - 0
/dev/sdb
5 Reallocated_Sector_Ct 0x0133 100 100 010 Pre-fail Always - 40
196 Reallocated_Event_Count 0x0032 000 000 000 Old_age Always - 32808
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
/dev/sdc
5 Reallocated_Sector_Ct 0x0033 100 100 050 Pre-fail Always - 0
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 100 000 Old_age Offline - 0
...
由于当初部署时使用了固态硬盘(/dev/nvme0n1)作为缓存,并且是先分区,再将不同的分区(例如 /dev/nvme0n1p1、/dev/nvme0n1p2 等)分别分配给各个OSD作为WAL和DB设备。因此,在更换数据盘时,我必须找出目标OSD所关联的WAL和DB分区。
这只能通过对比块设备的UUID来实现。首先,查看Ceph OSD目录下的符号链接记录:
# file /var/lib/ceph/osd/ceph-6/*
/var/lib/ceph/osd/ceph-6/block: symbolic link to /dev/ceph-2f7e3d8f-e29c-40db-949a-102e9f2c90d3/osd-block-4d238e4d-c2f0-4005-9433-5a76334e9f95
/var/lib/ceph/osd/ceph-6/block.db: symbolic link to /dev/ceph-86d4cba4-b0db-440f-b5cc-5dd9e25b81b9/osd-db-c890bf20-b9a6-4714-8c10-cd550ecc52b5
/var/lib/ceph/osd/ceph-6/block.wal: symbolic link to /dev/ceph-12e8969a-414b-4bdd-a45c-89b718faf6cd/osd-wal-172d5eda-2167-41c3-b09f-f7edece3937d
/var/lib/ceph/osd/ceph-6/ceph_fsid: ASCII text
...
然后,通过 lsblk 命令查看系统中对应的设备映射关系:
# lsblk
...
sdb 8:16 0 1.8T 0 disk
└─ceph--2f7e3d8f--e29c--40db--949a--102e9f2c90d3-osd--block--4d238e4d--c2f0--4005--9433--5a76334e9f95 252:0 0 1.8T 0 lvm
...
├─nvme0n1p3 259:3 0 9.3G 0 part
│ └─ceph--12e8969a--414b--4bdd--a45c--89b718faf6cd-osd--wal--172d5eda--2167--41c3--b09f--f7edece3937d 252:11 0 9.3G 0 lvm
...
├─nvme0n1p9 259:9 0 37.3G 0 part
│ └─ceph--86d4cba4--b0db--440f--b5cc--5dd9e25b81b9-osd--db--c890bf20--b9a6--4714--8c10--cd550ecc52b5 252:9 0 37.3G 0 lvm
...
通过对比可以确定:OSD.6(即 ceph-6)的数据块(block)位于 sdb 上的LVM中,其WAL设备对应 nvme0n1p3 分区,DB设备对应 nvme0n1p9 分区。
理清对应关系后,操作就明确了。我先在PVE的Web管理界面中删除这个OSD,然后准备重新添加。新加入的SATA硬盘被系统识别为 sdf。
目标是保持OSD.6的ID不变,且继续使用原来的WAL和DB分区,仅更换数据盘(从sdb换到sdf)。执行以下命令即可完成:
# ceph-volume lvm create --bluestore --data /dev/sdf --block.wal /dev/nvme0n1p3 --block.db /dev/nvme0n1p9 --osd-id 6
整个过程在古董机器上运行得非常缓慢。所以,如果你的预算允许,还是建议直接全闪存阵列吧。

 发表于 2026-1-27 03:16:07
|
查看: 211|
回复: 0
发表于 2026-1-27 03:16:07
|
查看: 211|
回复: 0
