前言
在现代微服务架构中,服务的透明度和可控性变得至关重要,可观测性则是实现这一目标的核心支柱。作为一款高性能的边缘和服务代理,Envoy 原生提供了强大的可观测性支持。本节我们将深入探讨如何在 Envoy 中实践完整的可观测性方案,涵盖日志、指标和链路追踪三大支柱。
日志配置
日志是我们诊断问题的第一手资料,Envoy 的访问日志配置非常灵活。配置方式也很直观,下面是一个将访问日志输出到标准输出的基础配置示例:
static_resources:
listeners:
- name: ingress_listener
address:
socket_address:
address: 0.0.0.0
port_value: 10000
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
...
access_log:
- name: envoy.access_loggers.stdout
typed_config:
"@type": type.googleapis.com/envoy.extensions.access_loggers.stream.v3.StdoutAccessLog
log_format:
text_format: "[%START_TIME%] \"%REQ(:METHOD)% %REQ(X-ENVOY-ORIGINAL-PATH?:PATH)% %PROTOCOL%\" %RESPONSE_CODE% %BYTES_SENT% %DURATION% %REQ(X-REQUEST-ID)% \"%REQ(USER-AGENT)%\" \"%REQ(X-FORWARDED-FOR)%\" %UPSTREAM_HOST% %UPSTREAM_CLUSTER% %RESPONSE_FLAGS%\n"
- 上述配置将日志输出到控制台,便于开发和调试。在生产环境中,更常见的做法是输出到文件,然后由
filebeat 或 logstash 等日志采集工具收集,这也是 运维 监控体系中的标准环节。只需将上述配置中的 stdout 替换为 file 并指定路径即可,例如:path: /var/log/envoy/access.log。
- 此外,Envoy 支持将日志直接输出到 Kafka 等消息中间件,并可以根据响应状态码(如仅采集 4xx、5xx 错误)或按采样比例进行采集,这些高级配置在此不赘述。
Admin 管理页面
Envoy 内置了一个强大的 Admin 管理页面,默认端口为 9901。通过该页面,我们可以方便地查看实时统计信息、动态调整日志级别、甚至启用性能剖析器。配置如下:
admin:
address:
socket_address:
address: 0.0.0.0
port_value: 9901
配置后,访问 http://<your-envoy-ip>:9901 即可打开管理界面。
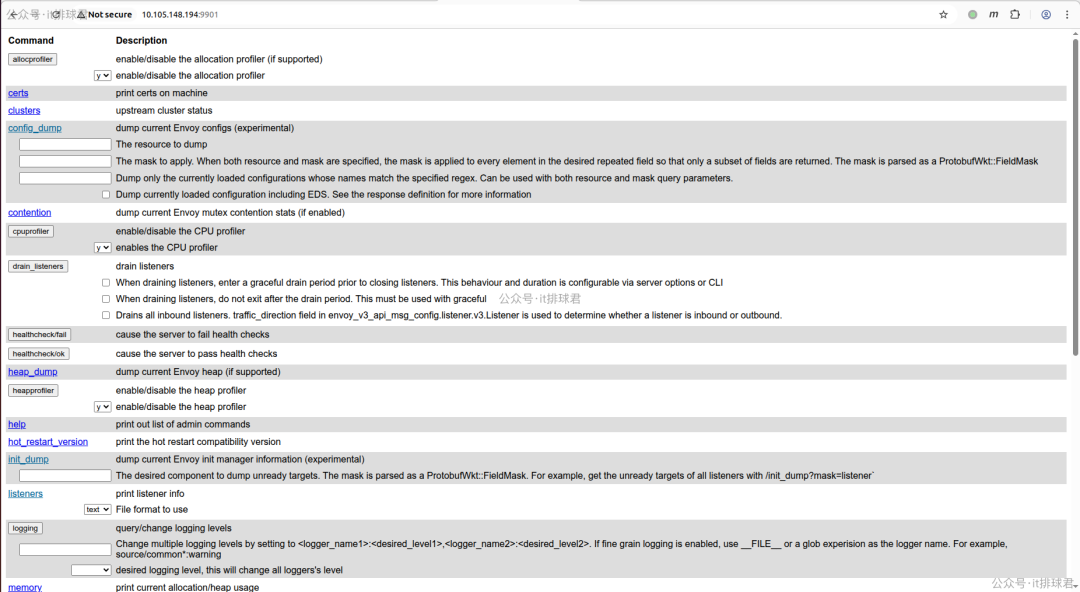
如图所示,界面功能非常丰富,可以查看集群状态、监听器信息、进行配置热重载等。这为日常的 运维 与排障工作提供了极大的便利。
Metrics 接入 Prometheus
启用 Admin 接口后,Envoy 自动在 /stats/prometheus 路径下暴露了格式化的 Prometheus 指标数据。我们可以通过 http://10.105.148.194:9901/stats/prometheus 直接访问。
接下来,只需在 Kubernetes (K8s) 集群内部或外部部署一个 Prometheus 服务,并将其配置为抓取 Envoy 的指标端点。以下是一个简单的 prometheus.yml 配置示例:
global:
scrape_interval: 5s
evaluation_interval: 5s
rule_files:
- /etc/prometheus/*.rules
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: "envoy"
metrics_path: /stats/prometheus
static_configs:
- targets: ["10.105.148.194:9901"]
使用 Docker 快速启动一个 Prometheus 实例来测试采集:
docker run -d --name prometheus \
-p 9090:9090 \
-v ./prometheus.yml:/etc/prometheus/prometheus.yml \
-v /usr/share/zoneinfo/Asia/Shanghai:/etc/localtime \
registry.cn-beijing.aliyuncs.com/wilsonchai/prometheus:v3.5.0
启动后,访问 Prometheus 的 Web UI (http://localhost:9090) 并在 Graph 页面输入 envoy_,即可看到所有来自 Envoy 的丰富指标,为服务监控和告警提供了数据基础。
Traces 接入 Jaeger
链路追踪是洞察请求在分布式系统中流转路径的关键。Envoy 支持将追踪数据发送到如 Jaeger 这样的后端。首先,你需要一个已运行的 Jaeger 收集器(Collector)。
假设 Jaeger 已部署完毕,我们需要修改 Envoy 的配置以启用 OpenTelemetry 追踪。这里要特别注意,不同 Envoy 版本的配置可能不同,本文基于 v1.32 版本。
主要配置改动在监听器的 tracing 部分,并需要定义一个指向 Jaeger 收集器的集群:
static_resources:
listeners:
- name: ingress_listener
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
...
tracing:
provider:
name: envoy.tracers.opentelemetry
typed_config:
"@type": type.googleapis.com/envoy.config.trace.v3.OpenTelemetryConfig
service_name: envoy-proxy
grpc_service:
envoy_grpc:
cluster_name: jaeger_otlp_collector
...
clusters:
...
- name: jaeger_otlp_collector
type: LOGICAL_DNS
connect_timeout: 5s
lb_policy: ROUND_ROBIN
http2_protocol_options: {}
load_assignment:
cluster_name: jaeger_otlp_collector
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 10.22.12.178 # 替换为你的 Jaeger Collector OTLP gRPC 地址
port_value: 4317
...
配置修改完成后,重启 Envoy 实例。此时,发送经过该 Envoy 的请求,即可在 Jaeger UI 中查看到对应的追踪数据。
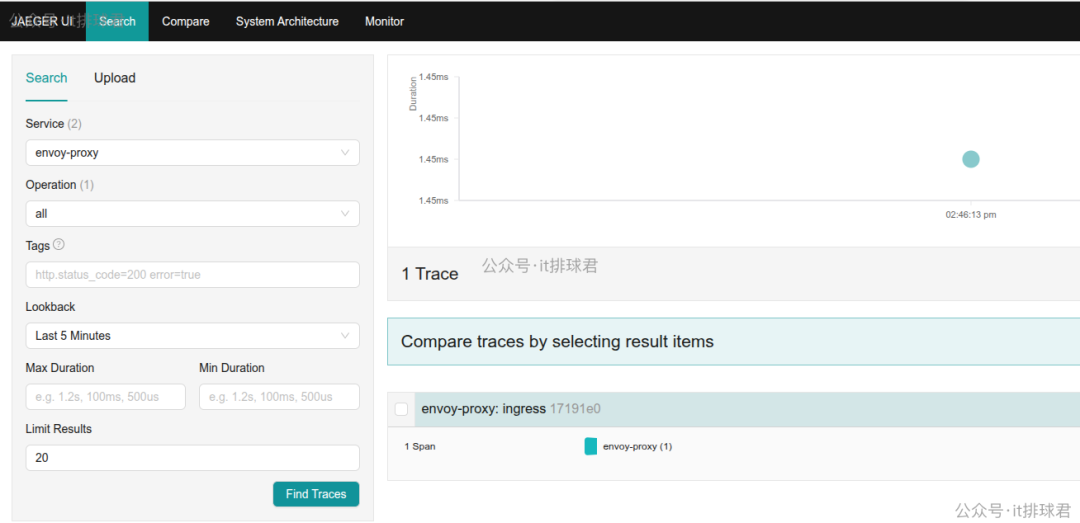
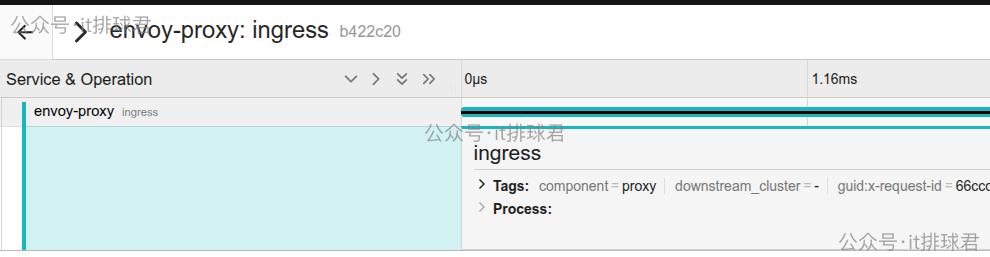
由于当前仅在 Envoy 侧配置了追踪,尚未与后端服务联动,因此追踪链中只显示了“envoy-proxy”这一个跨度(Span)。要实现从网关到后端服务的完整全链路追踪,需要在后端服务中也集成相应的追踪 SDK(如 OpenTelemetry),并在云栈社区的 云原生/IaaS 相关讨论中可以找到更多关于服务网格与微服务追踪的深度实践。
小结
至此,我们完成了基于 Envoy 的可观测性三大支柱建设:通过访问日志记录请求明细,通过 Prometheus 暴露并采集系统与业务指标,通过 Jaeger 实现请求的链路追踪。这套组合为基于 Envoy 构建的 Service Mesh 或 API 网关提供了坚实的运维洞察力基础,是保障系统稳定性和快速排查故障不可或缺的一环。在实际生产中,可以在此基础上,结合告警规则(Alerting Rules)、日志聚合分析(如 ELK Stack)和更复杂的追踪采样策略,构建起企业级的可观测性平台。
 发表于 2026-1-27 08:34:42
|
查看: 201|
回复: 0
发表于 2026-1-27 08:34:42
|
查看: 201|
回复: 0
