在现代Web应用中,将HTML页面导出为PDF是一个极为普遍且重要的需求。无论是客服系统需要存档聊天记录、电商平台生成订单与发票,还是报表系统制作可离线的数据报告,一个高质量的HTML转PDF功能都至关重要。
然而,实现它并非易事。开发者们常常面临样式还原度低、长内容分页困难、输出清晰度不足、性能瓶颈以及浏览器兼容性等诸多挑战。
传统的 html2canvas + jsPDF 组合虽然可行,但在样式还原度和截图质量上往往不尽如人意。本文将深入介绍一套新的解决方案:snapdom + jsPDF,并通过一个完整的客服消息列表导出案例,带你彻底掌握这套方案的核心技术细节与实现流程。
SnapDOM 与 jsPDF 核心理论
SnapDOM 是什么?
SnapDOM 是一个现代化的 DOM 截图库,其核心功能是将 DOM 元素高保真地转换为 Canvas、PNG 或 SVG 格式。
核心优势包括:
- 高保真截图:能够完美还原 CSS 样式,包括复杂的 flexbox、grid 布局、渐变、阴影等效果。
- 多种输出格式:支持 Canvas、PNG Data URL、SVG 字符串等多种格式,灵活适配不同场景。
- 高清缩放:通过
scale 参数轻松实现 2倍、3倍等高清晰度截图,确保打印质量。
- 体积小巧:压缩后体积仅约 20KB,对项目构建体积影响极小。
基础用法如下:
import { snapdom } from '@zumer/snapdom';
// 获取目标 DOM 元素
const element = document.querySelector('.my-element');
// 执行截图
const capture = await snapdom(element, {
scale: 2, // 2倍清晰度
quality: 0.95 // PNG 图片质量
});
// 多种输出方式
const canvas = await capture.toCanvas(); // 获取 Canvas 元素
const imgEl = await capture.toPng(); // 获取 <img> 元素,其 src 为 Data URL
const svgStr = await capture.toSvg(); // 获取 SVG 字符串
关键参数说明:
| 参数 |
类型 |
默认值 |
说明 |
scale |
number |
1 |
缩放倍数,设置为2可获得更清晰的截图,利于打印。 |
quality |
number |
0.92 |
输出图片的质量,范围在 0 到 1 之间。 |
更多详细配置请参阅 SnapDOM 官方文档。
jsPDF 是什么?
jsPDF 是目前最流行的纯前端 JavaScript PDF 生成库,支持在浏览器中直接创建、编辑并保存 PDF 文件。
核心特点:
- 纯前端方案:无需后端服务介入,减轻服务器压力。
- 功能丰富:支持添加文本、图片、表格、超链接等多种内容。
- 标准纸张:内置 A4、Letter 等多种标准纸张格式。
- 插件生态:拥有如 AutoTable(表格生成)等丰富的扩展插件。
基础用法:
import { jsPDF } from 'jspdf';
// 创建 PDF 实例
const pdf = new jsPDF({
orientation: 'portrait', // 页面方向:纵向
unit: 'mm', // 单位:毫米
format: 'a4', // 纸张规格:A4
compress: true // 启用压缩以减小文件体积
});
// 添加图片到 PDF
pdf.addImage(
imageDataUrl, // Base64 格式的图片数据
'PNG', // 图片格式
10, // X 坐标(距页面左边距,单位:mm)
10, // Y 坐标(距页面上边距,单位:mm)
190, // 图片宽度(mm)
100 // 图片高度(mm)
);
// 添加新页面
pdf.addPage();
// 保存并下载 PDF 文件
pdf.save('output.pdf');
常用 A4 尺寸常量定义(单位:毫米):
// A4 标准尺寸(单位:mm)
const A4_WIDTH_MM = 210;
const A4_HEIGHT_MM = 297;
// 页面边距
const MARGIN_MM = 10;
// 计算可用内容区域
const CONTENT_WIDTH_MM = A4_WIDTH_MM - MARGIN_MM * 2; // 190mm
const CONTENT_HEIGHT_MM = A4_HEIGHT_MM - MARGIN_MM * 2; // 277mm
SnapDOM + jsPDF 组合的优势
为什么选择这个组合?下面的对比图清晰地展示了它与传统方案的区别:
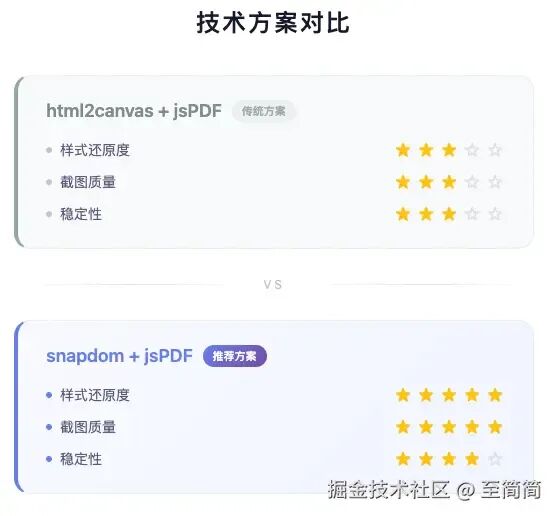
从上图可以看出,snapdom + jsPDF 方案在样式还原度、截图质量和稳定性三个核心维度上均表现优异,远超传统的 html2canvas 方案。
实战:消息列表导出为PDF完整案例
接下来,我们将通过一个模拟的 IM(即时通讯)产品中消息列表导出的完整 Demo,来拆解如何将上述理论落地。
项目结构与核心流程
典型的项目结构如下:
src/
├── components/
│ ├── MessageList.tsx # 消息列表组件
│ └── MessageList.css # 消息列表样式
├── services/
│ └── messageExportService.ts # PDF 导出服务(核心逻辑)
└── App.tsx
整个导出过程可以清晰地划分为 4 个步骤,如下图所示:
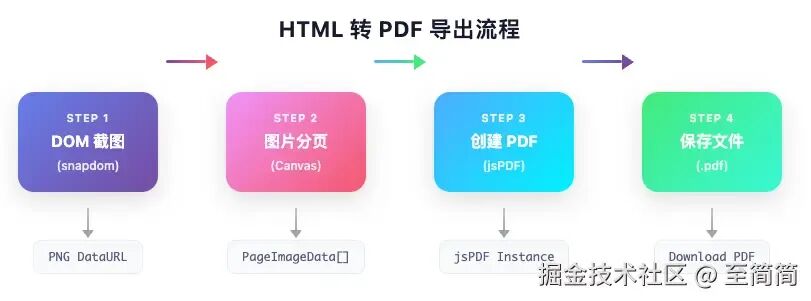
Step 1:DOM 截图(使用 SnapDOM)
第一步,将需要导出的消息列表 DOM 元素转换为一张高清的 PNG 图片。
// messageExportService.ts
import { snapdom } from '@zumer/snapdom';
// 图片质量配置
const IMAGE_QUALITY = 0.95;
const IMAGE_FORMAT = 'image/png' as const;
/**
* 将 DOM 元素转换为图片 Data URL
*/
export async function captureElementToImage(
element: HTMLElement,
quality: number = IMAGE_QUALITY
): Promise<string> {
console.log('开始截图...');
// 保存原始样式,便于后续恢复
const originalOverflow = element.style.overflow;
const originalHeight = element.style.height;
const originalMaxHeight = element.style.maxHeight;
// 临时修改样式,确保能截取到完整内容(尤其是滚动区域)
element.style.overflow = 'visible';
element.style.height = 'auto';
element.style.maxHeight = 'none';
try {
// 核心:使用 snapdom 进行高保真截图
const capture = await snapdom(element, {
scale: 2, // 2倍清晰度,保证打印质量
quality: quality
});
// 优先使用 toPng() 获取 Data URL
const imgElement = await capture.toPng();
const dataUrl = imgElement.src;
// 降级处理:如果 toPng 返回的数据异常,则回退到 toCanvas
if (!dataUrl || dataUrl.length < 100) {
console.log('toPng 返回无效,尝试 toCanvas...');
const canvas = await capture.toCanvas();
return canvas.toDataURL(IMAGE_FORMAT, quality);
}
console.log('截图成功,大小:', (dataUrl.length / 1024).toFixed(2), 'KB');
return dataUrl;
} finally {
// 无论成功与否,都必须恢复元素的原始样式
element.style.overflow = originalOverflow;
element.style.height = originalHeight;
element.style.maxHeight = originalMaxHeight;
}
}
关键点解析:
- 临时修改样式:清除
overflow、height 和 maxHeight 限制,确保能捕获滚动区域内的全部内容。
scale: 2:设置为 2 倍缩放,这是生成高清打印 PDF 的关键。- 降级处理:对
snapdom 的 toPng() 方法做了兼容性处理,失败时自动回退到 toCanvas()。
- 样式恢复:使用
try...finally 确保元素样式总能被恢复,避免影响页面正常显示。
Step 2:图片分页处理(Canvas 分割)
获取到的是一张“长图”,我们需要根据 A4 纸的高度(减去页边距)将其智能地分割成多页。
// 尺寸常量定义(单位:毫米)
const A4_WIDTH_MM = 210;
const A4_HEIGHT_MM = 297;
const PDF_MARGIN_MM = 10;
const PDF_CONTENT_WIDTH_MM = A4_WIDTH_MM - PDF_MARGIN_MM * 2; // 190mm
const PDF_CONTENT_HEIGHT_MM = A4_HEIGHT_MM - PDF_MARGIN_MM * 2; // 277mm
// 单位换算:1毫米约等于 3.78 像素 (基于 96 DPI)
const MM_TO_PX = 3.7795275590551;
// 分页后每张图片的数据结构
interface PageImageData {
dataUrl: string;
width: number;
height: number;
}
/**
* 将一张长图片按 A4 页面高度分割成多张图片
*/
export async function splitImageIntoPages(
imageDataUrl: string
): Promise<PageImageData[]> {
return new Promise((resolve, reject) => {
const img = new Image();
img.crossOrigin = 'anonymous';
img.onload = () => {
const pages: PageImageData[] = [];
const originalWidth = img.width;
const originalHeight = img.height;
// 计算每页内容区域在 Canvas 中的像素高度(需考虑 scale=2)
const pageContentHeightPx = Math.floor(
PDF_CONTENT_HEIGHT_MM * MM_TO_PX * 2 // scale=2
);
const pageContentWidthPx = Math.floor(
PDF_CONTENT_WIDTH_MM * MM_TO_PX * 2
);
// 计算缩放比例,使图片宽度刚好适配页面内容宽度
const widthScale = pageContentWidthPx / originalWidth;
const scaledHeight = originalHeight * widthScale; // 缩放后的总高度
// 根据缩放后的高度计算总页数
const totalPages = Math.ceil(scaledHeight / pageContentHeightPx);
console.log(`原始尺寸: ${originalWidth}x${originalHeight}px`);
console.log(`缩放后高度: ${scaledHeight}px, 总页数: ${totalPages}`);
// 循环,逐页裁剪
for (let pageIndex = 0; pageIndex < totalPages; pageIndex++) {
const startY = pageIndex * pageContentHeightPx; // 当前页在“缩放后图片”上的起始Y坐标
const endY = Math.min(startY + pageContentHeightPx, scaledHeight);
const currentPageHeight = Math.floor(endY - startY);
// 计算当前页内容对应到“原始图片”上的区域
const sourceStartY = startY / widthScale;
const sourceHeight = currentPageHeight / widthScale;
// 创建 Canvas 来绘制当前页
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d')!;
canvas.width = pageContentWidthPx;
canvas.height = currentPageHeight;
// 开启高质量图像渲染
ctx.imageSmoothingEnabled = true;
ctx.imageSmoothingQuality = 'high';
// 将原始图片的对应区域绘制到当前页 Canvas 上
ctx.drawImage(
img,
0, sourceStartY, // 源图片起始位置 (x, y)
originalWidth, sourceHeight, // 源图片裁剪区域宽高
0, 0, // 目标 Canvas 起始位置
pageContentWidthPx, currentPageHeight // 目标 Canvas 绘制宽高
);
// 将 Canvas 转换为 Data URL
const pageDataUrl = canvas.toDataURL(IMAGE_FORMAT, IMAGE_QUALITY);
pages.push({
dataUrl: pageDataUrl,
width: pageContentWidthPx,
height: currentPageHeight
});
console.log(`第 ${pageIndex + 1}/${totalPages} 页处理完成`);
}
resolve(pages);
};
img.onerror = () => reject(new Error('图片加载失败'));
img.src = imageDataUrl;
});
}
分页算法逻辑图解:
假设我们有一张高 5000 像素(缩放后)的长图,每页内容区域高 1046 像素。
原始长图 (假设 5000px 高)
┌───────────────────┐
│ │ ─┐
│ Page 1 │ │ 1046px (277mm × 3.78 × 2)
│ │ ─┘
├───────────────────┤
│ │ ─┐
│ Page 2 │ │ 1046px
│ │ ─┘
├───────────────────┤
│ │ ─┐
│ Page 3 │ │ 1046px
│ │ ─┘
├───────────────────┤
│ │ ─┐
│ Page 4 │ │ 1046px
│ │ ─┘
├───────────────────┤
│ Page 5 │ ── 剩余 816px
│ │
└───────────────────┘
这个分页逻辑是方案的核心,它确保了无论内容多长,都能被正确地分割到多个 A4 页面上,且内容不会被截断。
Step 3:创建 PDF(使用 jsPDF)
将分割好的多张图片,按顺序添加到 jsPDF 实例中,形成最终的多页 PDF 文档。
import { jsPDF } from 'jspdf';
/**
* 将分页后的图片数据创建成一个完整的 PDF 文档
*/
export function createPdfFromPages(pages: PageImageData[]): jsPDF {
const pdf = new jsPDF({
orientation: 'portrait',
unit: 'mm',
format: 'a4',
compress: true // 启用压缩,减小最终文件体积
});
if (pages.length === 0) {
throw new Error('没有可添加的页面');
}
pages.forEach((page, index) => {
// 第一页 pdf 已自动创建,后续页面需要手动添加
if (index > 0) {
pdf.addPage();
}
// 将 Canvas 像素高度转换回毫米(需考虑 scale=2)
const scaleFactor = 2;
const pageHeightMm = page.height / MM_TO_PX / scaleFactor;
// 图片宽度固定为页面内容宽度,高度按比例计算
const finalWidth = PDF_CONTENT_WIDTH_MM; // 190mm
const finalHeight = pageHeightMm;
// 设置图片在 PDF 页面中的位置(保留页边距)
const x = PDF_MARGIN_MM; // 10mm 左边距
const y = PDF_MARGIN_MM; // 10mm 上边距
console.log(`添加第 ${index + 1} 页: ${finalWidth}x${finalHeight.toFixed(2)}mm`);
// 将当前页图片添加到 PDF
pdf.addImage(page.dataUrl, 'PNG', x, y, finalWidth, finalHeight);
});
return pdf;
}
Step 4:主导出函数(串联所有步骤)
最后,我们将以上三个步骤封装成一个统一的、易于调用的函数。
interface ExportConfig {
targetSelector: string; // 目标 DOM 元素的 CSS 选择器
filename?: string; // 输出的 PDF 文件名
quality?: number; // 图片质量
}
/**
* 主导出函数:对外暴露的统一接口
*/
export async function exportMessagesToPdf(config: ExportConfig): Promise<void> {
const {
targetSelector,
filename = 'messages.pdf',
quality = IMAGE_QUALITY
} = config;
console.log('=== 开始导出 PDF ===');
// 1. 获取目标 DOM 元素
const element = document.querySelector(targetSelector) as HTMLElement;
if (!element) {
throw new Error(`元素未找到: ${targetSelector}`);
}
console.log('元素尺寸:', {
width: element.offsetWidth,
height: element.scrollHeight
});
// 2. DOM 截图
const imageDataUrl = await captureElementToImage(element, quality);
console.log('截图完成,大小:', (imageDataUrl.length / 1024).toFixed(2), 'KB');
// 3. 图片分页
const pages = await splitImageIntoPages(imageDataUrl);
console.log(`分页完成,共 ${pages.length} 页`);
// 4. 创建 PDF
const pdf = createPdfFromPages(pages);
// 5. 保存文件
pdf.save(filename);
console.log('=== 导出完成 ===');
}
在 React 组件中使用
在组件中,调用我们封装好的导出服务就非常简单了。
// MessageList.tsx
import { exportMessagesToPdf } from '../services/messageExportService';
import { useRef, useState, useCallback } from 'react';
const MessageList: React.FC = () => {
const messageListRef = useRef<HTMLDivElement>(null);
const [isExporting, setIsExporting] = useState(false);
const handleExportToPdf = useCallback(async () => {
setIsExporting(true);
try {
// 生成一个带时间戳的唯一文件名
const timestamp = new Date().toISOString().replace(/[:.]/g, '-');
const filename = `messages-${timestamp}.pdf`;
await exportMessagesToPdf({
targetSelector: '.message-list-container',
filename,
quality: 0.95
});
} catch (error) {
console.error('导出失败:', error);
alert('导出失败,请重试');
} finally {
setIsExporting(false);
}
}, []);
return (
<div className="message-list-container" ref={messageListRef}>
<div className="message-list-header">
<h2>消息记录</h2>
<button
className="export-button"
onClick={handleExportToPdf}
disabled={isExporting}
>
{isExporting ? '导出中...' : '导出 PDF'}
</button>
</div>
<div className="message-list">
{messages.map(message => (
<MessageItem key={message.id} message={message} />
))}
</div>
</div>
);
};
运行效果
点击导出按钮后,你将在控制台看到清晰的日志,并自动下载生成的高清 PDF 文件。
=== 开始导出 PDF ===
目标选择器: .message-list-container
元素尺寸: { width: 600, height: 8500 }
开始截图...
截图完成,大小: 2847.65 KB
分页完成,共 8 页
添加第 1 页: 190x277.00mm
添加第 2 页: 190x277.00mm
...
添加第 8 页: 190x156.32mm
=== 导出完成 ===
SnapDOM 与 html2canvas 深度对比
为什么我们强烈推荐 SnapDOM 而不是更广为人知的 html2canvas?下表详细对比了两者的差异:
| 对比维度 |
SnapDOM |
html2canvas |
| 样式还原 |
★★★★★ 接近完美 |
★★★☆☆ 部分样式丢失 |
| Flexbox/Grid |
✅ 完美支持 |
⚠️ 部分场景有问题 |
| 渐变背景 |
✅ 完美支持 |
⚠️ 可能失真 |
| 阴影效果 |
✅ 完美支持 |
⚠️ 部分丢失 |
| 自定义字体 |
✅ 支持良好 |
⚠️ 需要额外处理 |
| SVG 支持 |
✅ 原生支持 |
⚠️ 支持有限 |
| 输出格式 |
PNG/Canvas/SVG |
Canvas/PNG |
| 包大小 |
~20KB (gzipped) |
~60KB (gzipped) |
| 维护状态 |
活跃更新 |
近期更新较少 |
| API 设计 |
现代 Promise API |
回调 + Promise 混合 |
代码简洁性对比:
html2canvas 方式:
import html2canvas from 'html2canvas';
// 通常需要配置大量参数来处理兼容性问题
const canvas = await html2canvas(element, {
scale: 2,
useCORS: true,
logging: false,
allowTaint: true,
foreignObjectRendering: true, // 对SVG等内容可能仍不生效
// ... 更多字体、背景处理配置
});
const dataUrl = canvas.toDataURL('image/png');
snapdom 方式:
import { snapdom } from '@zumer/snapdom';
// API 简洁直观,核心配置即可
const capture = await snapdom(element, {
scale: 2,
quality: 0.95
});
const dataUrl = (await capture.toPng()).src;
当然,如果您的项目已经深度集成 html2canvas,或者导出的内容样式极其简单,迁移成本较高,那么继续使用 html2canvas 也无可厚非。
总结与优化方向
核心要点回顾:
- SnapDOM 凭借其高保真的渲染能力,是替代 html2canvas 实现高质量 DOM 截图的优秀选择。
- jsPDF 提供了稳定、功能丰富的纯前端 PDF 生成能力。
- “截图-分页-合成” 的三段式流程是处理长内容 HTML 转 PDF 的通用有效模式。
- 分页算法 涉及像素与物理尺寸(毫米)的精确换算,是保证 PDF 排版正确的关键。
方案还可以进一步优化:
| 优化方向 |
说明 |
| Web Worker |
将耗时的图片分页计算放入 Web Worker,避免阻塞主线程导致页面卡顿。 |
| 分段截图 |
对于超长内容(如数万条消息),可分批截图再合并,避免单次操作内存溢出。 |
| 进度反馈 |
在分页和导出过程中提供进度条或提示,提升用户体验。 |
| PDF 元数据 |
使用 pdf-lib 等库对生成的 PDF 进行进一步压缩,或添加页码、页眉页脚、文档属性等信息。 |
| 错误重试与监控 |
增加网络不稳定或渲染失败时的重试机制,并上报关键指标以监控方案稳定性。 |
这套 snapdom + jsPDF 的方案,在样式还原度、输出质量和开发者体验上取得了很好的平衡,能够满足绝大多数中高保真度的 HTML 转 PDF 需求。希望这篇结合实战的详细解析,能帮助你下次遇到类似需求时,能够从容应对。
技术探索永无止境,欢迎在云栈社区与更多开发者交流前端、Node.js 以及工程化实践中的心得与挑战。
 发表于 2026-1-28 03:14:34
|
查看: 140|
回复: 0
发表于 2026-1-28 03:14:34
|
查看: 140|
回复: 0
