在 Linux 图形栈的探索旅程中,我们将视线从内核态的 DRM/KMS 上移至用户态。在这里,坐落着 Linux 图形世界中最庞大、最核心的组件——Mesa 3D。
用户态驱动的核心职责是翻译:将应用程序发出的图形 API 调用(如 glDrawArrays 或 vkCmdDraw),编译成 GPU 硬件能理解的寄存器指令和二进制代码。在 Linux 生态中,承担这一重任的集合体,绝大多数情况下就是 Mesa。
Mesa 不仅仅是一个 OpenGL 的开源实现,它是一套庞大的图形驱动基础设施。它向下通过 ioctl 对接 DRM 内核子系统,向上为应用程序提供 OpenGL、Vulkan、OpenCL、VA-API 等标准化接口。
Mesa 内部主要由四部分逻辑组成,构成了三条关键驱动路径:
- Gallium3D 路径:主要服务于 OpenGL 和 OpenCL。它通过统一的状态追踪器(State Tracker)将复杂的 API 调用转换为通用的 Gallium 中间表达,极大降低了不同硬件适配 OpenGL 的难度。
- Vulkan 直接路径:为了极致性能,现代 Vulkan 驱动(如 Intel ANV, AMD RADV)通常不经过 Gallium 的上下文抽象层,而是直接对接硬件指令发射。但它们依然与 Gallium 驱动共享核心基础设施,如 NIR 编译器、Winsys 代码和工具库。
- 软件与虚拟化路径:Mesa 还包含了强大的 CPU 软件渲染器(llvmpipe for GL, Lavapipe for VK)以及服务于虚拟机的 Virgl/Venus 驱动,这使得 Linux 能够在无 GPU 或虚拟化环境下依然提供完整的图形加速能力。
- 共享编译中端(NIR):这是两条路径的“公约数”。无论是 OpenGL 还是 Vulkan,它们的 Shader 最终都会汇聚到 NIR 编译器进行硬件无关的优化。这种共享中端的设计确保了 Mesa 只需要维护一套优化算法,所有硬件驱动即可同时获益。
Linux 图形栈全景图
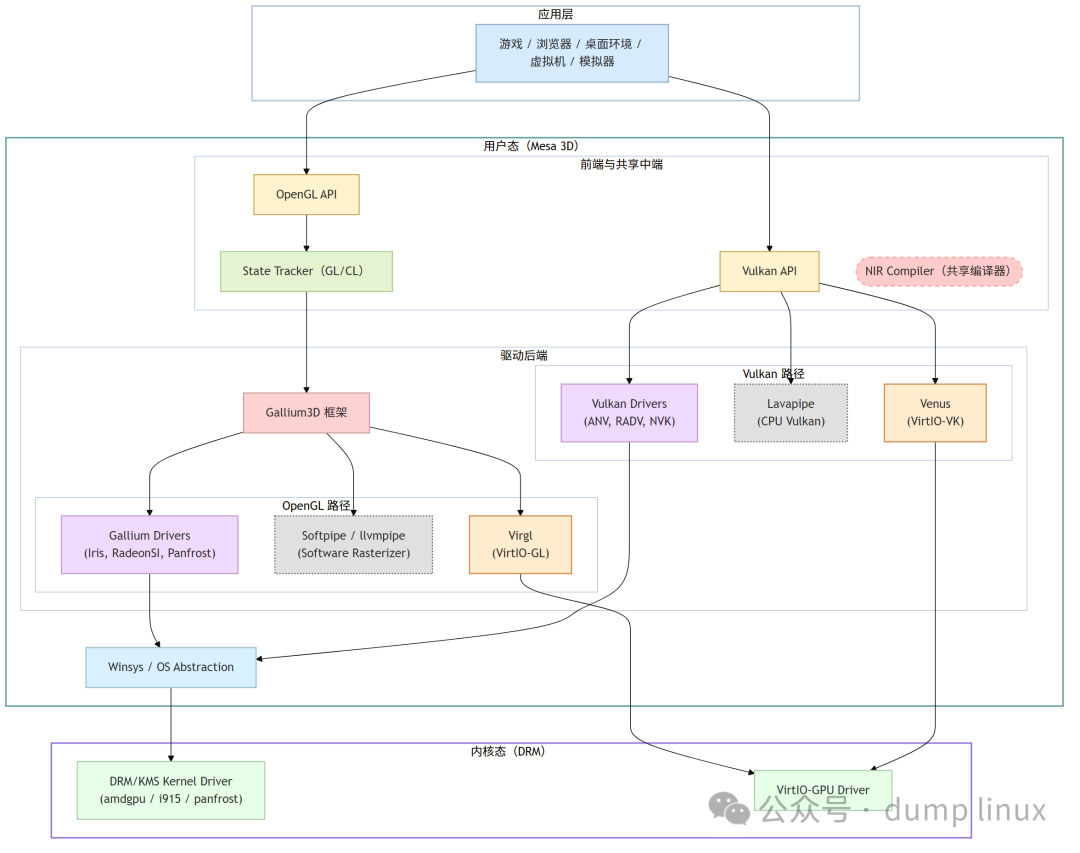
值得注意的是,在应用层与具体的 Mesa 驱动之间,还存在着一个关键的 Loader 层(如 Vulkan Loader、GLVND)。它是图形栈的入口,充当了“调度员”的角色:负责在系统中多个可用的驱动实现(ICD 或 Vendor Library)中,为应用匹配并加载对应的驱动,并将 API 调用实时分发到该后端。例如,Vulkan Loader 会通过扫描 /usr/share/vulkan/icd.d 列表来识别硬件驱动,而 GLVND 则负责在多厂商环境下实现 OpenGL 的透明调度。
对于驱动工程师、图形库维护者以及需要性能调优的应用开发者而言,理解 Mesa 能帮助你定位性能瓶颈、理解驱动与内核交互、并在必要时修复或规避驱动层面的兼容性问题。如果你想深入了解图形栈背后的计算机科学原理,可以访问云栈社区的相关板块。
2. 渲染管线
在深入 Mesa 的软件架构之前,我们需要先了解一下 GPU 到底在做什么。
图形渲染管线(Graphics Pipeline)是将用户提供的几何数据(顶点、纹理)转换为屏幕上最终像素的一系列处理步骤。Mesa 的核心任务,就是将 OpenGL/Vulkan API 对这条管线的描述,翻译成 GPU 硬件的配置。
虽然现代 GPU 架构高度并行且复杂,但逻辑上它们通常遵循以下标准流程:
逻辑渲染管线图
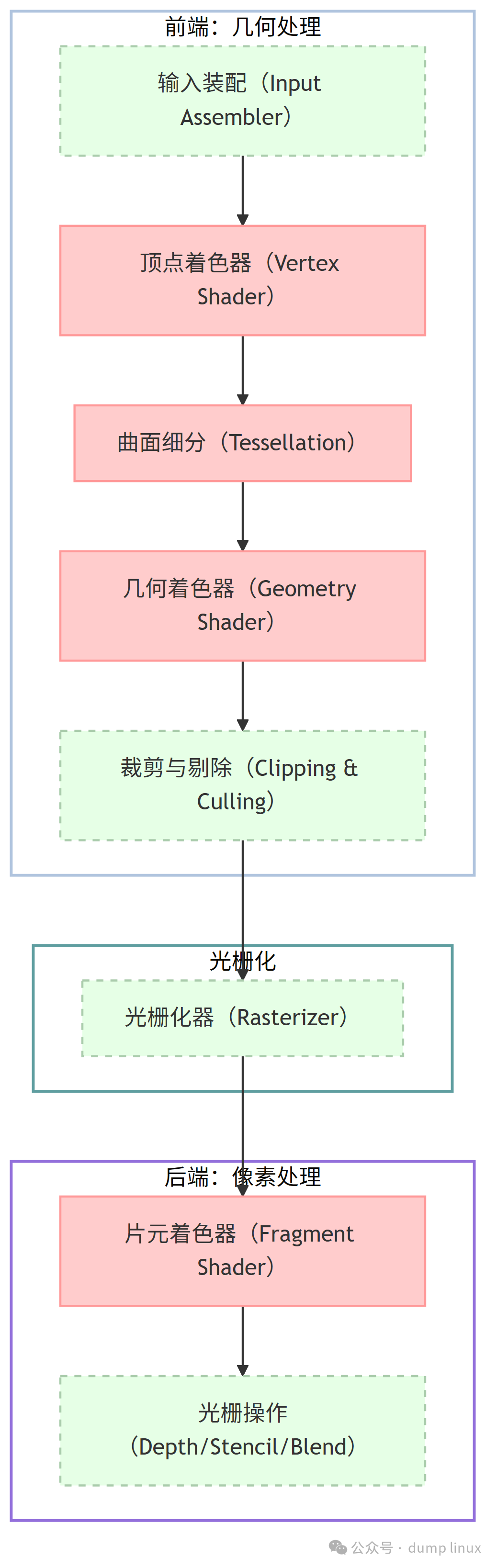
图例说明:
- 实线框(红色):可编程阶段(Programmable)。这是 Shader(着色器) 运行的地方,也是 Mesa 编译器(Compiler)发挥作用的主战场。
- 虚线框(绿色):固定功能阶段(Fixed Function)。这些通过寄存器配置状态,Mesa 驱动需要设置这些状态。
2.1 几何处理
几何处理(Geometry Processing)这一阶段主要处理“点、线、面”的数学变换。
- 输入装配(Input Assembler):从显存(VBO)中读取顶点数据,并按照指定的拓扑结构(如三角形、线段等),将离散的顶点初步分组,确定哪些顶点属于同一个图元(例如标记出组成一个三角形的三个顶点),为后续处理奠定基础。
- 顶点着色器(Vertex Shader) [可编程]:对经过输入装配的每个顶点进行单独处理,核心是坐标变换(如将 3D 世界坐标转换为屏幕裁剪坐标),还可完成顶点级别的光照、动画等计算。此阶段仅处理单个顶点,不涉及图元的组装逻辑。
- 图元装配与裁剪(Primitive Assembly & Clipping):基于输入装配阶段确定的拓扑结构,将经过顶点着色器处理后的顶点正式组装成完整的图元(如具体的三角形、线段);同时,切除图元中位于屏幕视锥体之外的部分,确保仅保留可见内容进入后续阶段。
2.2 光栅化
光栅化(Rasterization)是 3D 几何数据变为 2D 像素数据的关键转折点。
- 光栅化器(Rasterizer):确定一个三角形覆盖了屏幕上的哪些像素网格。生成的每个潜在像素点被称为片元(Fragment),包含位置、深度等信息。
- 在此阶段,驱动程序需要配置视口大小(Viewport)、面剔除模式(Cull Face)、多重采样(MSAA)等状态,这些配置直接影响光栅化的精度和效率。
2.3 像素处理
像素处理(Pixel Processing)阶段主要处理颜色与深度,最终决定屏幕上每个像素的呈现效果。
- 片元着色器(Fragment Shader) [可编程]:计算每个像素的最终颜色。通常涉及复杂的纹理采样、光照计算、后期处理(如阴影、反射)等。
- 逐采样操作(Per-Sample Operations / ROP):
- 深度/模板测试(Depth/Stencil Test):判断像素是否被前面的物体遮挡(Z-Buffer 测试),或通过模板缓冲实现遮罩效果。
- 混合(Blending):处理半透明物体,将当前计算出的颜色与 Framebuffer 中已有的颜色进行 alpha 混合,生成最终像素色。
延迟状态更新(Lazy State Update):当应用程序调用 glBlendFunc 或 glEnable(GL_DEPTH_TEST) 时,Mesa 并不会立即操作硬件,而是将其记录在 pipe_context 的软件状态中。只有在 glDraw* 调用发生时,Mesa 才会将这些状态刷入硬件寄存器,这种延迟更新机制可减少不必要的硬件交互,提升性能。
3. Gallium3D 的诞生
在深入 Mesa 内部之前,必须理解其发展史上最重要的转折点:Gallium3D 架构。
在 Gallium3D 出现之前的 Classic Mesa 时代,驱动采用“直接转换”模式。每个驱动都需要独立实现完整的 OpenGL 状态机、纹理管理、上下文切换等通用逻辑(如旧版的 Intel i965,现代 Intel 驱动 Iris 已采用 Gallium3D)。这意味着如果你要支持一个新的 GPU,不仅要适配硬件特性,还要重写大量与 API 相关的重复代码,导致了 M × N 的复杂度问题(M 个图形 API 乘以 N 个硬件架构)。
Gallium3D 的引入从根本上解决了这个问题。它设计了一套统一的、基于现代 GPU 硬件能力的抽象接口层,将“API 处理”与“硬件操作”解耦:
- 前端(State Trackers):负责处理 API(OpenGL、OpenCL、VA-API 等)的复杂语义,将其转换为 Gallium 的通用中间表达(如 CSO, Constant State Objects),它不关心硬件细节。例如 OpenGL 状态追踪器会解析
glBindTexture 等调用,转换为 Gallium 纹理绑定接口。
- 后端(Pipe Drivers):只负责实现 Gallium 接口定义的具体硬件操作,它不关心是哪个 API 在调用它。例如 AMD 的
radeonsi 驱动只需实现纹理绑定的硬件指令发射,无需理解 OpenGL 规范。
这种架构将复杂度从 M × N 降低到了 M + N。现代的 Mesa 驱动(如 AMD 的 radeonsi,ARM 的 panfrost)几乎全部基于 Gallium3D,大幅降低了新硬件和新 API 的适配成本。
4. Gallium3D 核心抽象
要读懂 Mesa 驱动代码,必须理解 Gallium 定义的四个核心对象。这四个对象构成了驱动开发的通用语言,也是 Gallium3D 抽象能力的核心载体。
4.1 Pipe Screen
Pipe Screen 对应于物理 GPU 设备。它是一个只读的、全局的单例对象,用于查询硬件的能力(capabilities)。
- 职责:告诉上层“我支持多大的纹理”、“我是否支持几何着色器”、“我的显存对齐要求是什么”、“支持哪些像素格式”等基础能力。
- 生命周期:通常在驱动加载时创建,直到进程结束。例如程序启动时,
radeonsi 驱动会初始化 radeonsi_screen 结构体(继承自 pipe_screen),记录 Radeon GPU 的硬件特性。
4.2 Pipe Context
Pipe Context 对应于渲染上下文(Rendering Context)。它是状态的核心容器,存储了当前的绘制状态。
- 职责:持有当前绑定的着色器、纹理、混合模式、深度测试状态等。所有的
draw_vbo(绘制调用)都是在这个对象上发起的,它相当于画家的“调色盘和画笔”,每次绘制都依赖于上下文当前的状态配置。
- 生命周期:对应 OpenGL Context。当应用程序调用
glCreateContext 时,Mesa 会创建一个 pipe_context 实例,直到 glDeleteContext 时销毁。
4.3 Pipe Resource
Pipe Resource 对应于显存中的数据,即 Buffer Objects(BOs)。
- 类型:Texture(纹理,如 2D 纹理、立方体贴图)、Buffer(顶点/索引缓冲、Uniform 缓冲等)。
- 职责:抽象了显存分配。它不知道数据的内容,只知道格式(Format,如 RGBA8)、大小(Size)和用途(Usage,如是否可作为渲染目标)。例如一个顶点缓冲资源会记录顶点数据的显存地址、长度和对齐方式。
4.4 Pipe Surface / Sampler View
Pipe Surface / Sampler View 是 Resource 的视图。显存只是一堆二进制数据,视图决定了 GPU 如何解释这些数据。
- Pipe Surface:用于写入(作为 Render Target 或 Depth Stencil)。例如将一个 RGBA8 纹理的某一层作为渲染目标时,会创建一个
pipe_surface 描述其格式和层级。
- Sampler View:用于读取(作为纹理采样)。例如采样纹理时,
sampler_view 会指定采样的 Mipmap 范围、格式转换方式等。
- 意义:同一个显存对象(Resource),可以被解释为不同的格式(如将 RGBA8 纹理视为 BGRA8 读取),或者只渲染其中的某一层(Mipmap Level),提升资源复用性。
从设计角度看,Gallium 用 Screen 描述“硬件能力”,用 Context 承载“渲染状态”,用 Resource 管理“显存对象”,再用 View/Surface 决定“如何解释显存”,从而把复杂的 GPU 使用模型拆解为可组合的四类对象,为跨硬件、跨 API 适配奠定了基础。
Gallium 对象关系图
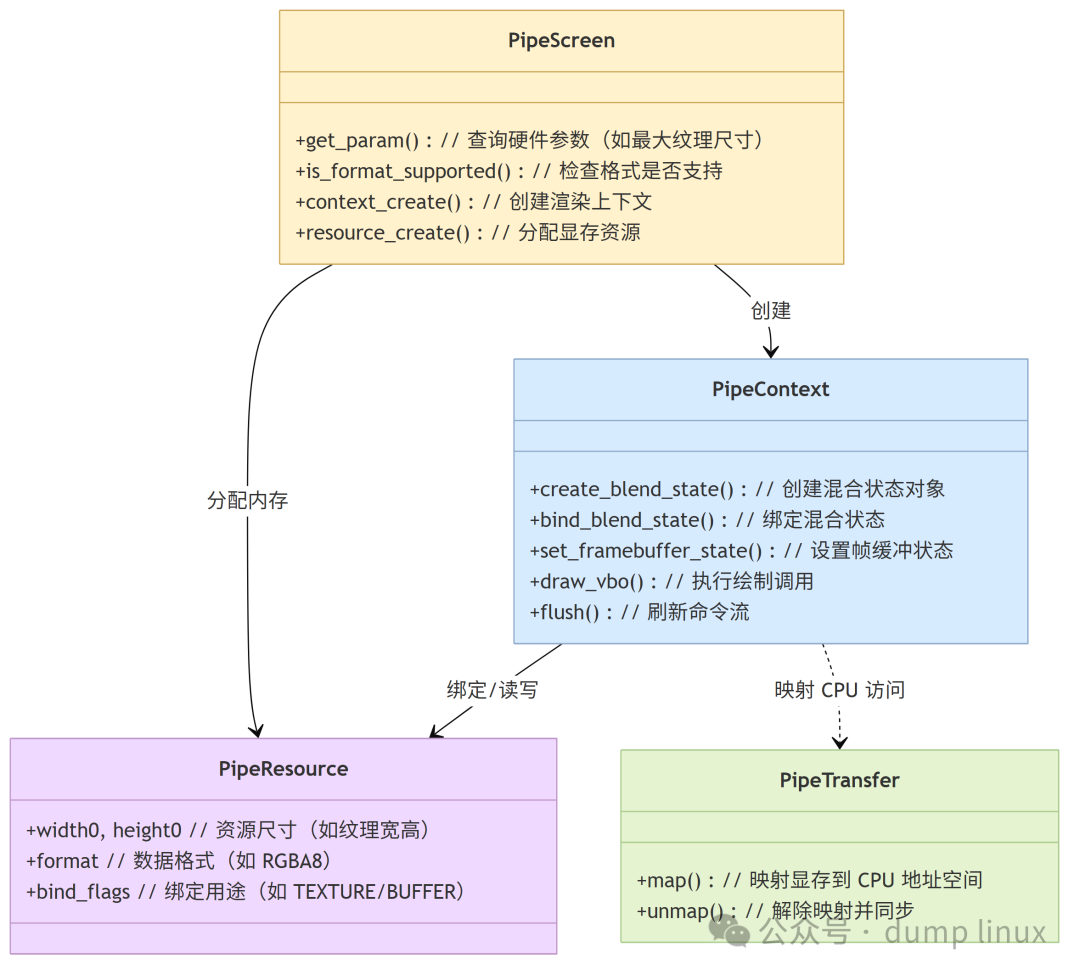
注:Pipe Transfer 是用于在 CPU 和 GPU 之间传输数据(Map/Unmap)的接口,处理了 CPU 对显存的读写访问。
5. Shader 编译
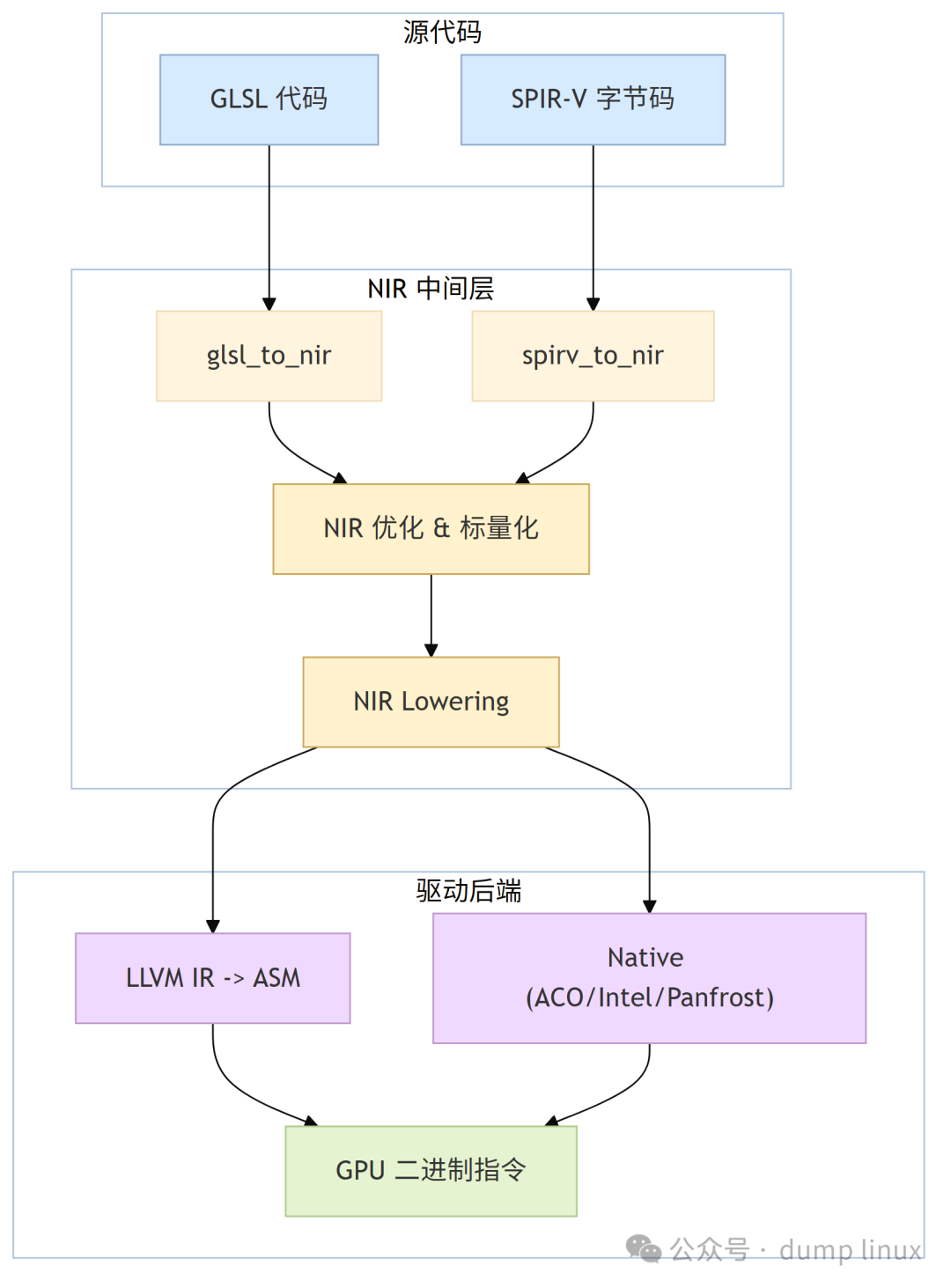
Mesa 最复杂的部分在于如何将人类可读的 Shader 代码(GLSL / SPIR-V)转换为 GPU 硬件指令。在这个过程中,NIR(New Intermediate Representation) 是现代 Mesa 的绝对核心。
NIR 是一种基于 SSA(Static Single Assignment,静态单赋值) 形式的中间表示。SSA 的特性(每个变量只被赋值一次)使得数据流分析极其简单,从而允许编译器做激进的优化。这也是 Mesa 在 shader 编译链上的核心抽象层,无论输入是 GLSL 还是 SPIR-V,最终都会转换为 NIR 进行统一处理。
相比早期的 TGSI(Texture/Graphics Shader Interface),NIR 以 SSA 为核心,更利于全局优化和后端统一(避免为不同输入格式开发多套优化逻辑),这也是 Mesa 在近几年全面迁移到 NIR 的根本原因。
5.1 前端解析
- GLSL:通过
glsl_to_nir 模块解析。Mesa 通常使用其内置 GLSL 前端完成语法与语义分析并直接生成 NIR;在某些工具链或特定场景下,也可能借助 glslang 等外部前端。
- Vulkan(SPIR-V):通过
spirv_to_nir 模块解析。直接将 SPIR-V 字节码(二进制中间码)转换为 NIR,跳过源码解析步骤。
5.2 NIR 优化
NIR 优化不仅仅是精简代码,更重要的是对齐硬件架构特性。
- 通用优化:包括死代码消除(DCE)、常量折叠(Constant Folding)、循环展开(Loop Unrolling)等标准编译器优化。
- 标量化(Scalarization):这是 NIR 对现代 GPU 最关键的贡献。
- 背景:早期的 GPU(如 TeraScale)是 VLIW(超长指令字)架构,一次处理
vec4 数据。现代 GPU(如 AMD RDNA, NVIDIA, Intel Xe)普遍转向 Scalar(标量)SIMD 架构。
- 作用:NIR 能够自动将代码中的向量操作拆解为标量操作,以填充现代 GPU 的 ALU 流水线。例如,一个
vec4 的加法在 NIR 优化后会被拆解为 4 个独立的标量加法,允许编译器更灵活地进行指令调度和寄存器分配。
- 向量化(Vectorization):在某些特定场景(如内存 Load/Store),硬件依然偏好向量操作。NIR 能够智能识别连续的标量访问,将其合并为向量指令以提升显存带宽效率。
5.3 降级
降级(Lowering)将通用的操作转换为特定硬件支持的操作。例如:
- 有些 GPU 不支持 64 位整数,NIR 可以在这一步将其拆分为两个 32 位操作;
- 将通用的纹理采样操作映射到硬件特定的采样指令格式;
- 把复杂的控制流(如嵌套分支)拆分为硬件可高效执行的结构。
5.4 后端代码生成
当 NIR 完成优化和降级后,需要翻译为最终的 GPU 机器码(ISA)。不同的驱动选择了不同的后端策略:
- LLVM 后端:
- 典型应用:AMD
radeonsi (OpenGL), clover (OpenCL), llvmpipe (CPU 渲染)。
- 特点:LLVM 提供极其强大的通用优化能力,生成的代码质量高,但编译速度较慢(可能导致游戏加载时的卡顿)。AMD 的 OpenGL 驱动在历史上长期依赖 LLVM 将 IR 转换为 ISA。
- Native Compiler (专用后端):
- ACO (AMD Compiler):由 Valve 开发,专用于 AMD 的 Vulkan 驱动 (
RADV)。它的设计目标是极快的编译速度(比 LLVM 快数倍)和针对游戏场景的优异运行性能。目前 ACO 已成为 Linux 游戏体验的核心组件。
- NAK (NVIDIA Compiler):专为 NVK(NVIDIA Vulkan)驱动设计,使用 Rust 编写,代表了 Mesa 后端的新技术方向。
- Intel / Adreno / Panfrost:Intel (
brw/elk) 和移动端驱动(如 freedreno, panfrost)通常拥有自己手写的轻量级后端编译器,直接从 NIR 生成指令,以避免 LLVM 的庞大依赖和开销。
Shader 编译流程图
5.5 着色器缓存
Shader 的编译(尤其是优化和后端代码生成)是计算密集型任务。如果在游戏运行过程中实时编译,会导致明显的画面卡顿(Stutter)。
为了解决这个问题,Mesa 引入了磁盘着色器缓存(On-disk Shader Cache):
- 机制:Mesa 会对输入的 Shader 源码、编译选项、GPU 硬件型号等计算一个唯一的 SHA-1 哈希值。
- 命中:在触发编译前,驱动先去磁盘(在常见桌面 Linux 环境中通常位于
~/.cache/mesa_shader_cache)查找是否存在该哈希对应的二进制文件。如果命中,直接加载,耗时接近于零。
- 未命中:执行完整的 NIR 编译流程,并将最终结果写入磁盘缓存,供下次使用。
这也是为什么许多 Steam 游戏在首次启动或驱动更新后需要“预编译着色器”的原因——它们在预热这个缓存。
6. Draw Call 生命周期
当应用程序调用 glDrawArrays 时,Mesa 内部发生了什么?这是理解驱动工作流的关键,因为从 API 调用到 GPU 执行的全链路流程直接影响渲染性能。
6.1 State Tracker 阶段
- 验证:检查纹理是否完整(如 Mipmap 是否生成)、Shader 是否链接成功、顶点属性格式是否匹配等,确保绘制操作合法。
- 延迟编译:如果 Shader 尚未编译(或因状态变化需要重新编译变体,如不同的纹理格式导致采样逻辑变化),触发编译流程。
- 转换:将 GL 的绘制命令(如顶点数量、图元类型)转换为
pipe_context->draw_vbo() 调用,传递标准化的参数(如顶点缓冲、索引缓冲的 pipe_resource 句柄)。
6.2 Gallium 驱动阶段
- 状态发射(State Emit):驱动检查自上次绘制以来哪些状态(Blend、Rasterizer、Depth)发生了变化(通过“脏标记”跟踪),并将对应的硬件命令包(如寄存器配置)写入命令流。未变化的状态不会重复发射,减少冗余指令。
- 描述符生成:将绑定的 Resource(纹理、Buffer)转换为硬件能理解的描述符(Descriptor),包含显存地址、格式、采样方式等信息,并加入到当前命令流中,供 Shader 访问资源时使用。
- 内存驻留与地址管理:
- Legacy 模式(Relocation / 重定位):在旧硬件上,驱动不知道显存块的最终物理地址,因此在命令流中写入占位符,由内核在提交时进行“修补(Patching)”,这会带来巨大的 CPU 开销。
- Modern 模式(Softpin / 无重定位):现代 GPU 驱动(如 AMDGPU, Intel Gen8+, NVIDIA)采用 Softpin 技术。用户态驱动直接管理 GPU 的虚拟地址空间(Virtual Address Space),直接将确定的 64 位地址写入命令流。提交时,驱动只需将 BO 句柄列表传递给内核,告诉内核“确保这些内存驻留在显存中,不要移动它”,完全消除了内核修补指令的开销。
注意:驱动通常会做命令重用与批次合并(command buffer reuse / batch coalescing)以减少提交次数。例如将多个连续的、状态相同的 draw 调用合并为一个批次提交,这对性能有显著影响(减少 CPU 到 GPU 的命令交互开销)。
在实际应用中,一个帧内可能包含成百上千次 draw 调用,因此这条路径上的任何一次多余状态检查或命令提交,都会被成倍放大为性能瓶颈。对于进行底层图形开发的朋友,可以参考云栈社区中关于高效内存管理和优化的讨论。
6.3 Winsys / Kernel 接口阶段
- 批处理(Batching):生成的命令流首先写入用户态的 Command Buffer(Batch Buffer)。这是一块连续的内存区域,用于临时存储待提交的 GPU 指令。
- 提交(Submission):如果 Batch Buffer 满了,或者用户调用了
glFlush/glSwapBuffers,驱动调用 DRM 接口(如 DRM_IOCTL_AMDGPU_CS 或 DRM_IOCTL_I915_GEM_EXECBUFFER2)将命令提交给内核。
- 同步(Implicit vs Explicit Sync):
- 隐式同步(Legacy):传统 Linux 图形栈依赖内核的
dma_resv 对象。内核通过跟踪 Buffer Object (BO) 的使用情况,自动推断任务依赖。这对应用简单,但导致内核逻辑极度复杂,且容易造成不必要的 CPU 等待。
- 显式同步(Modern):Vulkan 和现代 Wayland 协议引入了显式同步。应用程序和驱动显式地通过 Timeline Semaphores 或
drm_syncobj 传递依赖关系。优势:内核不再通过猜测来管理依赖,极大降低了提交路径的开销,并解决了复杂的跨引擎(如 3D 引擎与 Video 编解码引擎)同步卡顿问题。
OpenGL 命令执行路径图
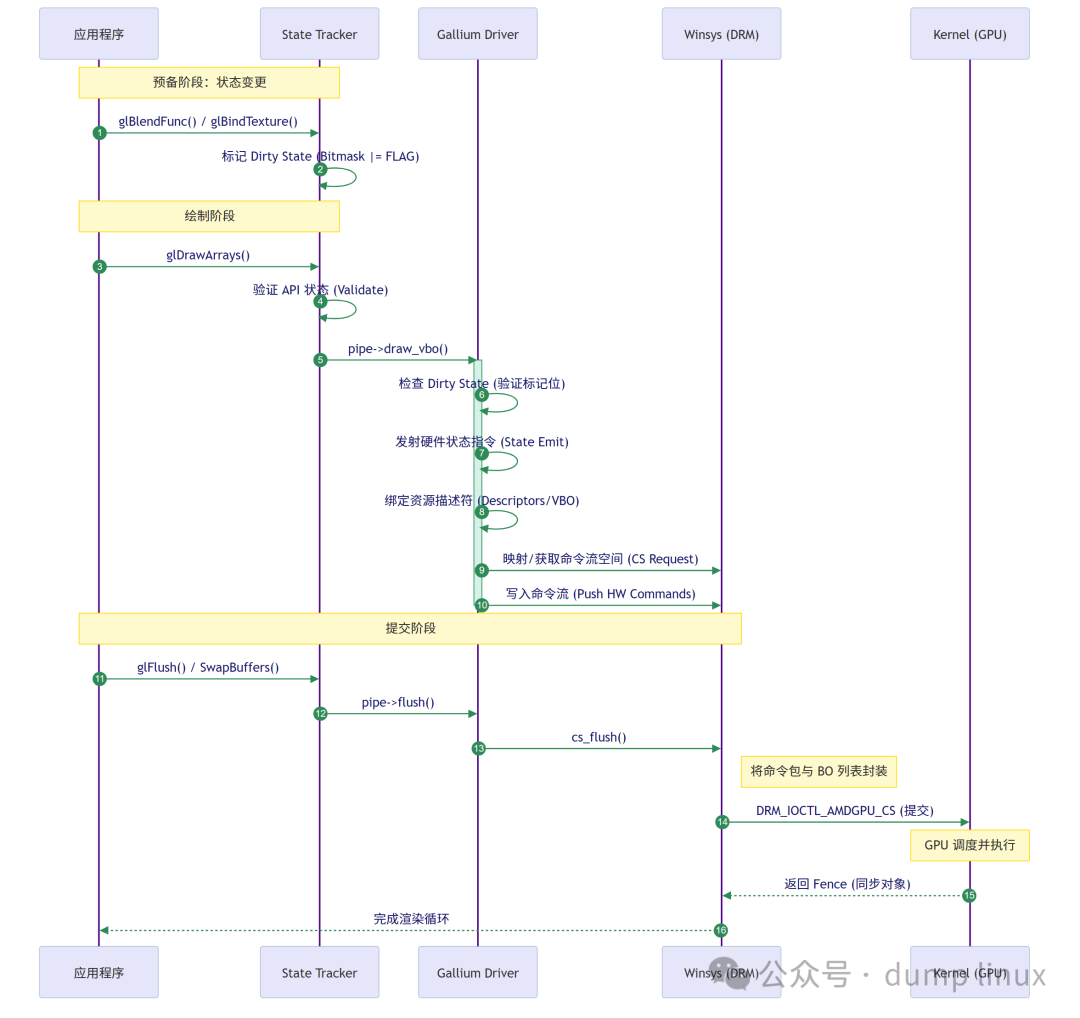
7. WSI 与 Winsys
Mesa 负责画图,但画在哪里?这涉及到 WSI(Window System Integration,窗口系统集成)——Mesa 与操作系统窗口系统(如 X11、Wayland)的交互层。
- OpenGL / OpenGL ES:主要通过 EGL(或传统的 GLX)实现 WSI。EGL 作为跨平台的接口,负责初始化显示连接、创建渲染表面(Surface)以及将渲染好的缓冲区(Buffer)提交给窗口管理器。在现代 Linux 系统(如 Wayland 或 Android)上,EGL 是连接 OpenGL 与屏幕的唯一桥梁。
- Vulkan:直接使用内置的 Vulkan WSI 扩展。 Vulkan 并不依赖 EGL,而是通过一系列以
VK_KHR_ 开头的扩展(如 VK_KHR_surface 和 VK_KHR_wayland_surface)来处理窗口集成。它引入了交换链(Swapchain)的概念,允许开发者显式控制图像在渲染引擎与显示服务器之间的流转。
在 Gallium 架构中,有一个特殊的组件叫 Winsys。它充当了图形驱动与操作系统环境之间的胶水,主要负责向内核提交命令、显存管理以及与窗口系统相关的底层资源对接,确保渲染结果能正确显示在屏幕上。
- GBM(Generic Buffer Management):这是现代 Linux 图形栈的内存分配标准。EGL 使用 GBM 分配
dma-buf(跨设备共享内存对象)。这个 dma-buf 是一个跨进程的内存句柄,它既可以被 GPU 渲染(作为 Framebuffer),也可以被显示控制器(KMS)直接读取并扫描到屏幕上,实现了零拷贝显示(避免从 GPU 到显示的冗余拷贝)。注意:使用 dma-buf 时需要关注缓存一致性与同步(如通过 sync_file),以避免显示撕裂或未定义数据读取。
- DRI(Direct Rendering Infrastructure):定义了 Mesa 如何与 X Server 或 Wayland Compositor 握手。例如 DRI3 协议允许 Mesa 直接访问窗口系统管理的缓冲区,减少 X Server 作为中间层的性能开销。
- Modifiers(格式修饰符):这是 Winsys 处理的一个关键细节。为了性能,GPU 通常以平铺(Tiling,如 AMD 的 TILED、Intel 的 X-tiling)或压缩格式(如 AMD FBC、NVIDIA PS)写入纹理——这些格式能提升显存带宽利用率,但与线性内存布局不兼容。当 Mesa 渲染完一帧后,它通过 Modifier 告诉显示服务器(Compositor):“这块 Buffer 是用 AMD_FBC 格式压缩的”,以便 Compositor 能正确解析数据。
8. 生态扩展
Mesa 并非一成不变,随着硬件架构的演进和新编程语言的兴起,Mesa 正在经历两场静悄悄的革命:Zink 和 Rusticl。
8.1 Zink
长期以来,为新 GPU 编写 OpenGL 驱动是一项极其繁重的工作。Zink 的出现打破了这一局面。
- 原理:Zink 本质上是一个 Gallium 驱动,但它并不直接操作硬件。它将 Gallium 的中间指令翻译成 Vulkan 命令。
- 意义:
- 驱动开发解耦:硬件厂商只需专注于开发高质量的 Vulkan 驱动。只要 Vulkan 驱动符合规范,通过 Zink 就能直接获得完整的 OpenGL 4.6 支持。
- 统一生态:对于新兴硬件(如 RISC-V GPU 或国产 GPU),无需再重复造 OpenGL 的轮子。
- 性能:经过数年的优化,Zink 在许多场景下的性能已经接近甚至超越了原生 OpenGL 驱动(因为其后端 Vulkan 驱动往往有更好的多线程优化)。
8.2 Rusticl
Mesa 早期名为 Clover 的 OpenCL 实现长期处于维护停滞状态,导致 Linux 下的 OpenCL 支持一直落后。Rusticl 是这一领域的破局者。
- 技术栈:Rusticl 是第一个合入 Mesa 主线的大规模 Rust 组件。它利用 Rust 的内存安全性重写了 OpenCL 前端。
- 现状:它同样对接 Gallium 接口,这意味着所有支持 Gallium 的驱动(Iris, RadeonSI, Panfrost)都能立即获得现代化的 OpenCL 3.0 支持。Rusticl 的成功标志着 Rust 语言正式进入了 Linux 核心图形栈。
8.3 虚拟化、API 翻译与 Apple Silicon
除了语言层面的革新,Mesa 在硬件与环境形态的支持上也在飞速扩展:
- VirtIO-GPU (Virgl & Venus,跨虚拟机边界的图形加速方案):
- Virgl:允许虚拟机(Guest)内的 OpenGL 命令序列化后,通过
virtio 总线透传到宿主机(Host)执行。
- Venus:专为 Vulkan 设计的虚拟化协议。相比 Virgl,Venus 利用了 Vulkan 的显式对象模型,实现了更低的序列化开销和接近原生的性能。这对于 ChromeOS、云渲染及 Android 模拟器 环境至关重要。
- Dozen (dzn,Vulkan-on-D3D12 翻译层):它是 Mesa 内部实现的将 Vulkan 指令流映射为 Direct3D 12 调用。这对于 WSL2(Windows Subsystem for Linux)至关重要,它允许 Linux 端的 Vulkan 应用无缝运行在仅提供 D3D12 驱动的 Windows 宿主机上。
- Asahi (Apple Silicon):
- 逆向工程 Apple M1/M2/M3 GPU 是近年来最受关注的开源图形项目之一。基于 Mesa 的 AGX 驱动展示了其架构的强大弹性,使得 Linux 能够在非传统 PC 架构的 Apple Silicon 硬件上实现完整、高性能的 OpenGL 和 Vulkan 支持。
9. 调试工具
Mesa 拥有一套极其强大的调试生态,这对驱动开发者和图形程序开发者都至关重要。无论是定位渲染错误、性能瓶颈还是兼容性问题,这些工具都能提供关键线索。
核心环境变量(用于临时改变 Mesa 行为,便于定位问题):
MESA_GL_VERSION_OVERRIDE=4.6:强制伪装 OpenGL 版本(用于运行声称需要更高版本但实际未使用高版本特性的应用)。MESA_DEBUG=1:开启详细的错误检查和日志输出(如未初始化的纹理、无效的状态组合)。LIBGL_ALWAYS_SOFTWARE=1:强制使用软件渲染(通常由 llvmpipe 提供,基于 CPU 模拟 GPU)。如果你的程序在硬件驱动上崩溃,但在软件渲染下正常,那么问题很可能出在驱动层或驱动与硬件的交互上。NIR_PRINT=1:打印 Shader 编译过程中的 NIR 中间代码(优化前/后),用于调试编译器优化问题(如优化导致的逻辑错误)。GALLIUM_HUD=fps,cpu,draw-calls:在屏幕上通过 Head-Up Display 显示实时性能数据,快速定位帧率波动、CPU 占用过高等问题。LIBGL_DEBUG=verbose:打印 OpenGL Loader 加载驱动的具体过程,用于排查“驱动找不到”或“加载了错误的驱动版本”等问题。
专业调试工具:
- RenderDoc:图形调试的工业标准。它可以截取一帧完整的渲染过程,让你逐个 Draw Call 查看 GPU 状态(纹理、缓冲数据)、Shader 输出和管线配置,是分析渲染错误(如黑块、颜色异常)的“显微镜”。
- apitrace:用于追踪 OpenGL/EGL/Vulkan 调用并进行回放。适合分析 API 调用序列(如状态泄漏、不必要的纹理切换),也可用于跨设备复现问题(无需原始应用环境)。
- Piglit:Mesa 的回归测试套件,包含数万个测试用例,覆盖了各种 API 边缘情况和硬件特性。驱动开发者可通过 Piglit 快速发现代码修改引入的 regression。
- Khronos CTS(Conformance Test Suite):官方合规性测试,通过 CTS 是驱动支持特定 API 版本(如 OpenGL 4.6、Vulkan 1.3)的必要条件,确保驱动行为符合规范。
典型调试流程:先在软件渲染(如 llvmpipe)下运行程序,确认问题是否与硬件/驱动相关;再使用 apitrace 记录并回放调用序列,定位异常 API 调用;最后用 RenderDoc 截取问题帧,检查 Shader 输出和状态配置,或结合 MESA_DEBUG 日志分析驱动层错误。
10. 总结
Mesa 3D 是连接上层应用程序与下层 Linux 内核图形子系统的核心桥梁,也是开源图形生态的基石。
- 架构上,它利用 Gallium3D 将 M × N 的适配问题简化为状态追踪器(State Tracker)与管道驱动(Pipe Driver)的模块化组合,大幅降低了新硬件和新 API 的支持成本;同时通过 Vulkan 直通路径保证了高性能场景的需求。
- 编译上,它利用 NIR 构建了统一、高效、SSA 形式的 Shader 优化与降级管线,通过通用优化 Pass 和硬件特定降级,兼顾了编译器的复用性和硬件针对性。NIR 结合 Native/LLVM 后端,实现了针对现代标量 GPU 架构的高效代码生成。
- 生态上,Zink 和 Rusticl 的加入,标志着 Mesa 正在向更通用、更安全的方向演进。
- 运行上,它通过
pipe_context 管理复杂的渲染状态,通过延迟更新和命令批处理减少硬件交互开销;通过 Winsys 与 DRM 内核交互,完成命令流提交与窗口系统集成,最终实现渲染结果从 GPU 到屏幕的高效呈现。
理解 Mesa 的工作原理,不仅能帮助开发者更好地利用图形 API 进行开发,更能为驱动调试、性能优化和跨平台适配提供深度指导。Mesa 作为开源项目的价值,正是向开发者敞开了图形栈黑箱。
 发表于 2026-1-31 00:39:16
|
查看: 311|
回复: 0
发表于 2026-1-31 00:39:16
|
查看: 311|
回复: 0
