在日常开发中,你是否曾因数据重复问题而焦头烂额?
用户在提交表单时,不小心快速点击了两次保存按钮,数据库里竟意外插入了两条仅ID不同的记录。又或者,为了解决接口超时问题而引入的重试机制,也可能因第一次请求超时但实际已处理成功,后续重试导致数据重复。再比如,消息队列的消费者在处理消息时,如果遇到重复消息且未妥善处理,同样会引发数据一致性问题。
这些问题的根源,都指向了接口幂等性。
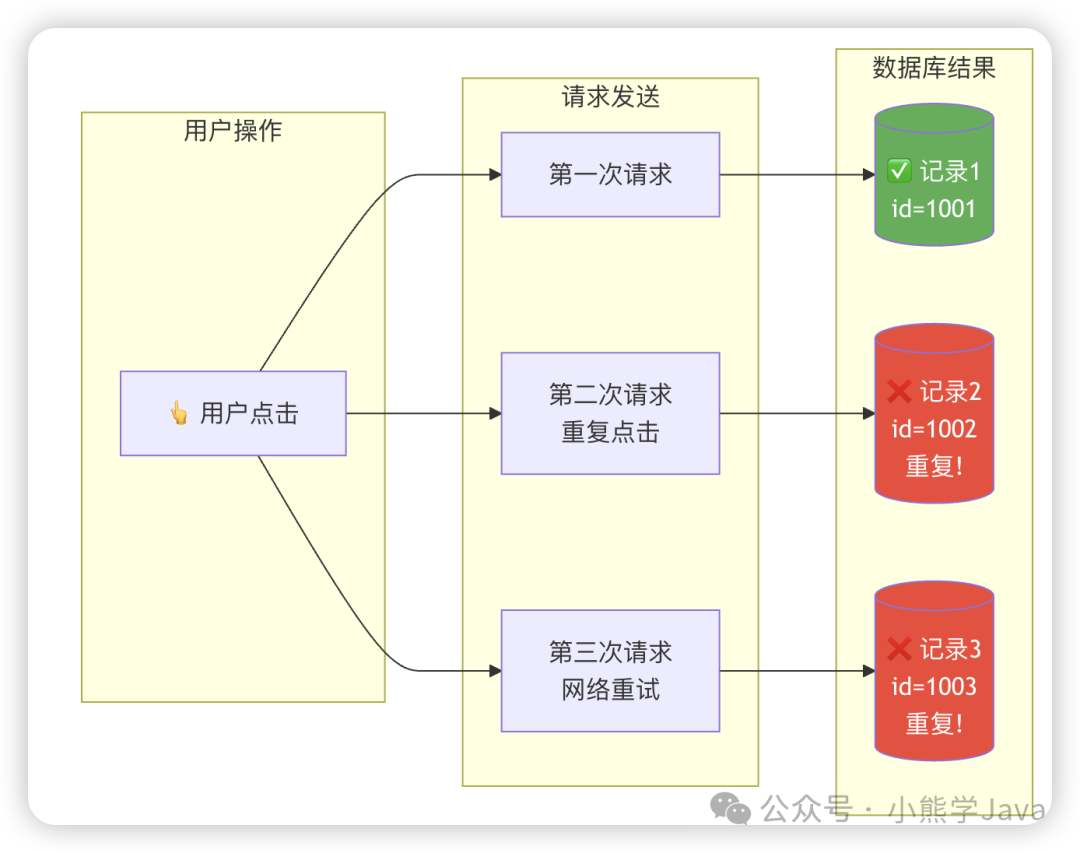
接口幂等性是指用户对于同一操作发起一次或多次请求,其最终结果是一致的,不会因多次执行而产生副作用。这类问题在INSERT操作和带有计算的UPDATE操作中尤为常见。
对于INSERT操作,多次请求可能导致数据重复:
-- 多次执行会产生多条重复记录
INSERT INTO `order` (user_id, product_id, amount) VALUES (1, 100, 1);
对于UPDATE操作,如果是简单更新(如 update user set status=1 where id=1)通常没问题。但若涉及计算,多次请求则可能导致逻辑错误:
-- 多次执行会导致status被错误累加
UPDATE user SET status = status + 1 WHERE id = 1;
那么,如何有效保证接口的幂等性呢?本文将深入剖析八种常用且实战性强的解决方案。
1. Insert前先Select(并发不适用)
这是一种直观的思路:在保存数据前,先根据业务字段(如订单号)查询数据是否存在。若存在则执行更新,反之则执行插入。
public void saveOrder(Order order) {
// 先查询是否存在
Order existOrder = orderMapper.selectByCode(order.getCode());
if (existOrder != null) {
// 已存在,执行更新
orderMapper.update(order);
} else {
// 不存在,执行插入
orderMapper.insert(order);
}
}
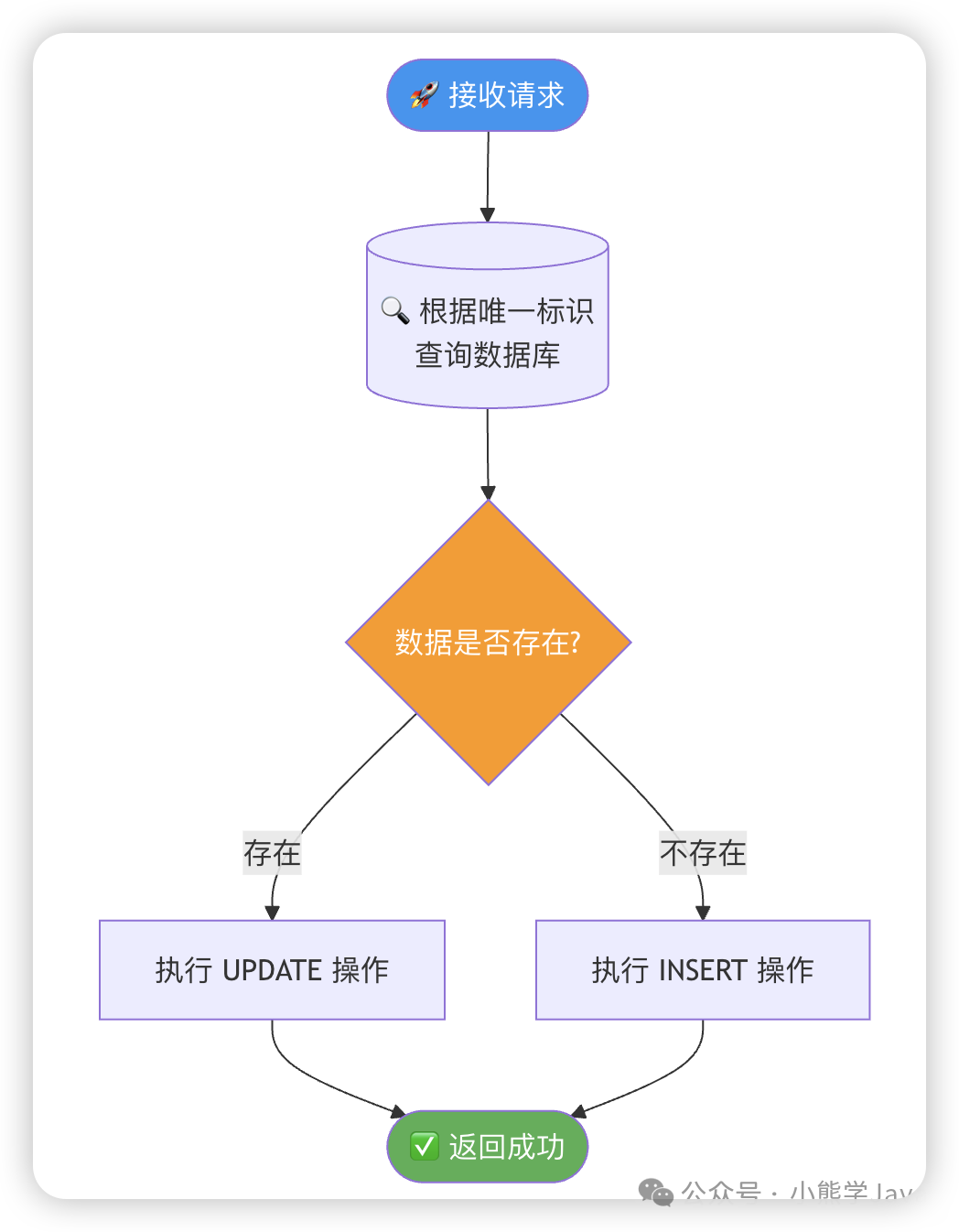
此方案简单易懂,是防止重复数据的常用方法。但其致命缺陷在于无法应对并发场景:两个并发请求可能同时通过SELECT检查,然后都执行INSERT,最终仍会产生重复数据。因此,它通常需要与其他方案配合使用。
2. 悲观锁(强一致场景)
在支付、库存扣减等对数据一致性要求极高的场景中,数据库/中间件的悲观锁是经典解决方案。
以支付场景为例,为避免余额被重复扣减为负数,可以使用SELECT ... FOR UPDATE锁定数据行。
-- FOR UPDATE 会锁住查询到的行
SELECT * FROM user WHERE id = 123 FOR UPDATE;
使用时需确保两点:数据库引擎为InnoDB,且操作位于事务中。
@Transactional
public Result deductAmount(Long userId, BigDecimal amount) {
// 1. 第一次查询,快速判断余额是否充足(不加锁)
User user = userMapper.selectById(userId);
if (user.getAmount().compareTo(amount) < 0) {
return Result.fail("余额不足");
}
// 2. 加悲观锁再次查询,确保数据一致性
User lockedUser = userMapper.selectByIdForUpdate(userId);
// 3. 再次判断余额(防止并发情况下余额已被扣减)
if (lockedUser.getAmount().compareTo(amount) < 0) {
// 余额不足,说明是重复请求或并发请求,直接返回成功
return Result.success("操作已完成");
}
// 4. 执行扣款
userMapper.deductAmount(userId, amount);
return Result.success();
}
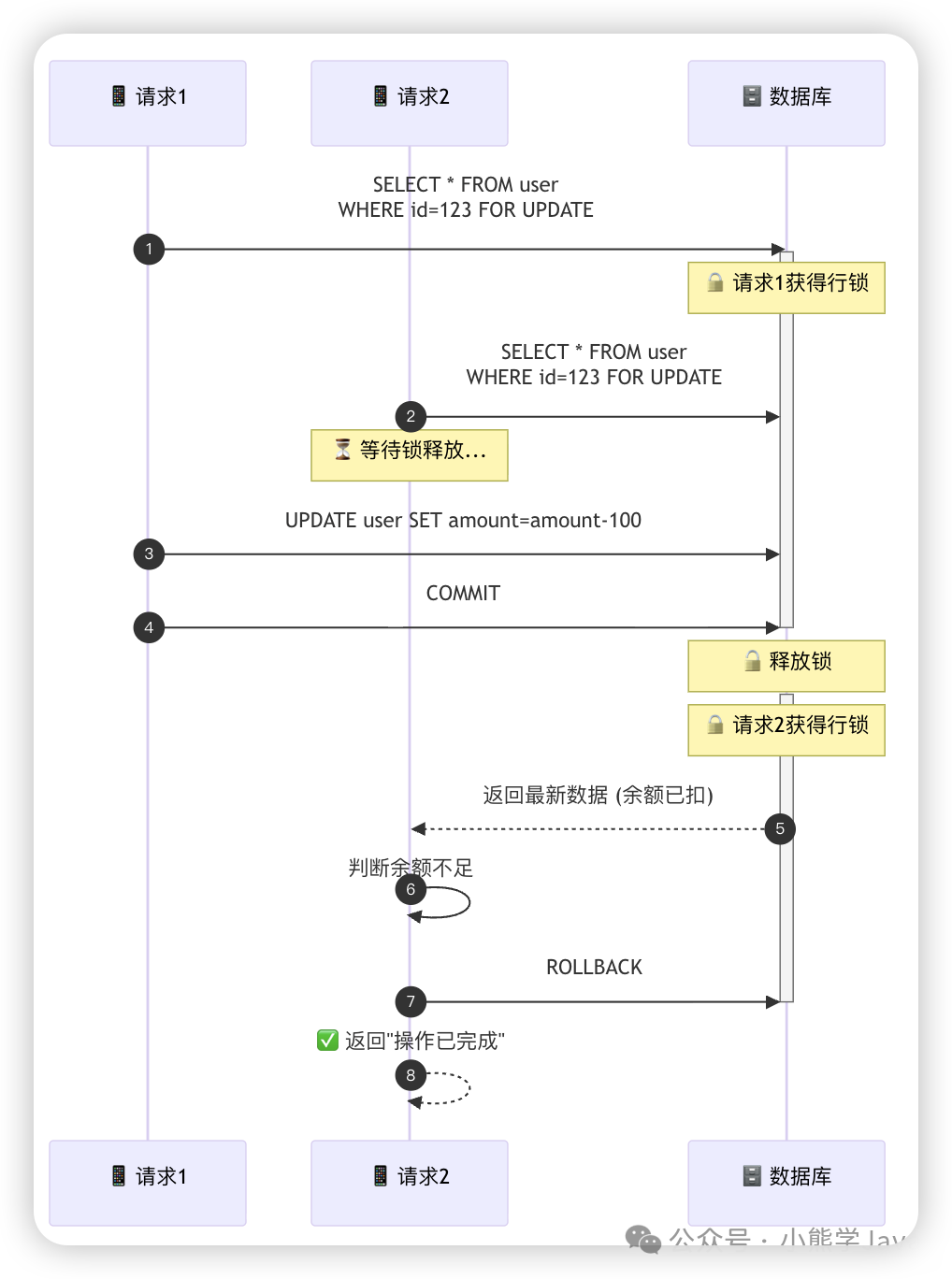
注意:WHERE条件中的字段必须是主键或唯一索引,否则会锁表,严重影响性能。悲观锁会造成请求排队等待,影响接口性能,且难以保证多次请求返回值一致,故更适合防重设计,而非严格的幂等设计。
| 防重设计与幂等设计的区别: |
设计类型 |
目标 |
返回值要求 |
| 防重设计 |
避免产生重复数据 |
可以不同 |
| 幂等设计 |
避免产生重复数据 + 返回一致结果 |
必须相同 |
3. 乐观锁(更新场景推荐)
为提升性能,可采用乐观锁。通过在表中增加version版本字段实现。
-- 表结构增加版本字段
ALTER TABLE user ADD COLUMN version INT DEFAULT 0;
更新时,将当前版本号作为条件。
public Result updateWithOptimisticLock(Long userId, BigDecimal amount) {
// 1. 查询当前数据,获取version
User user = userMapper.selectById(userId);
if (user == null) {
return Result.fail("用户不存在");
}
// 2. 带版本号更新
int rows = userMapper.updateAmountWithVersion(
userId,
amount,
user.getVersion() // 当前版本号
);
// 3. 判断影响行数
if (rows > 0) {
// 更新成功,首次请求
return Result.success("操作成功");
} else {
// 更新失败,说明version已变化,是重复请求
return Result.success("操作已完成"); // 保证幂等性,返回成功
}
}
<!-- MyBatis Mapper -->
<update id="updateAmountWithVersion">
UPDATE user
SET amount = amount + #{amount}, version = version + 1
WHERE id = #{userId} AND version = #{version}
</update>
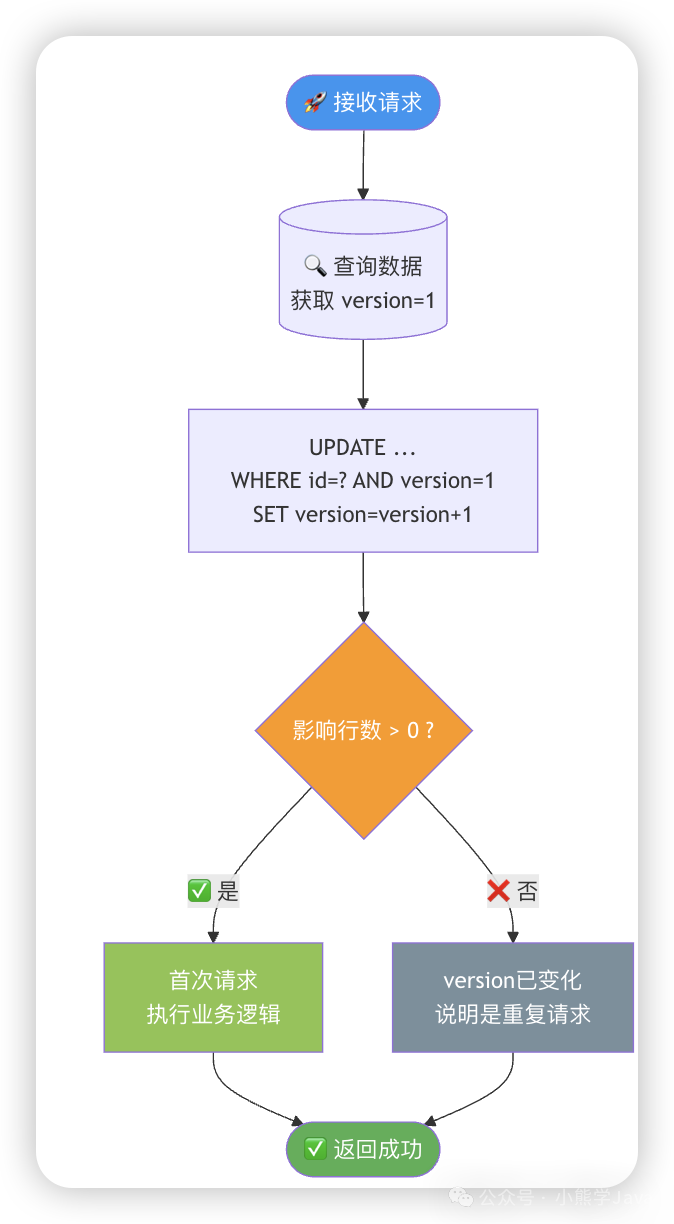 首次请求成功后,
首次请求成功后,version值改变。后续重复请求因WHERE条件不满足,影响行数为0,接口为保持幂等性直接返回成功。
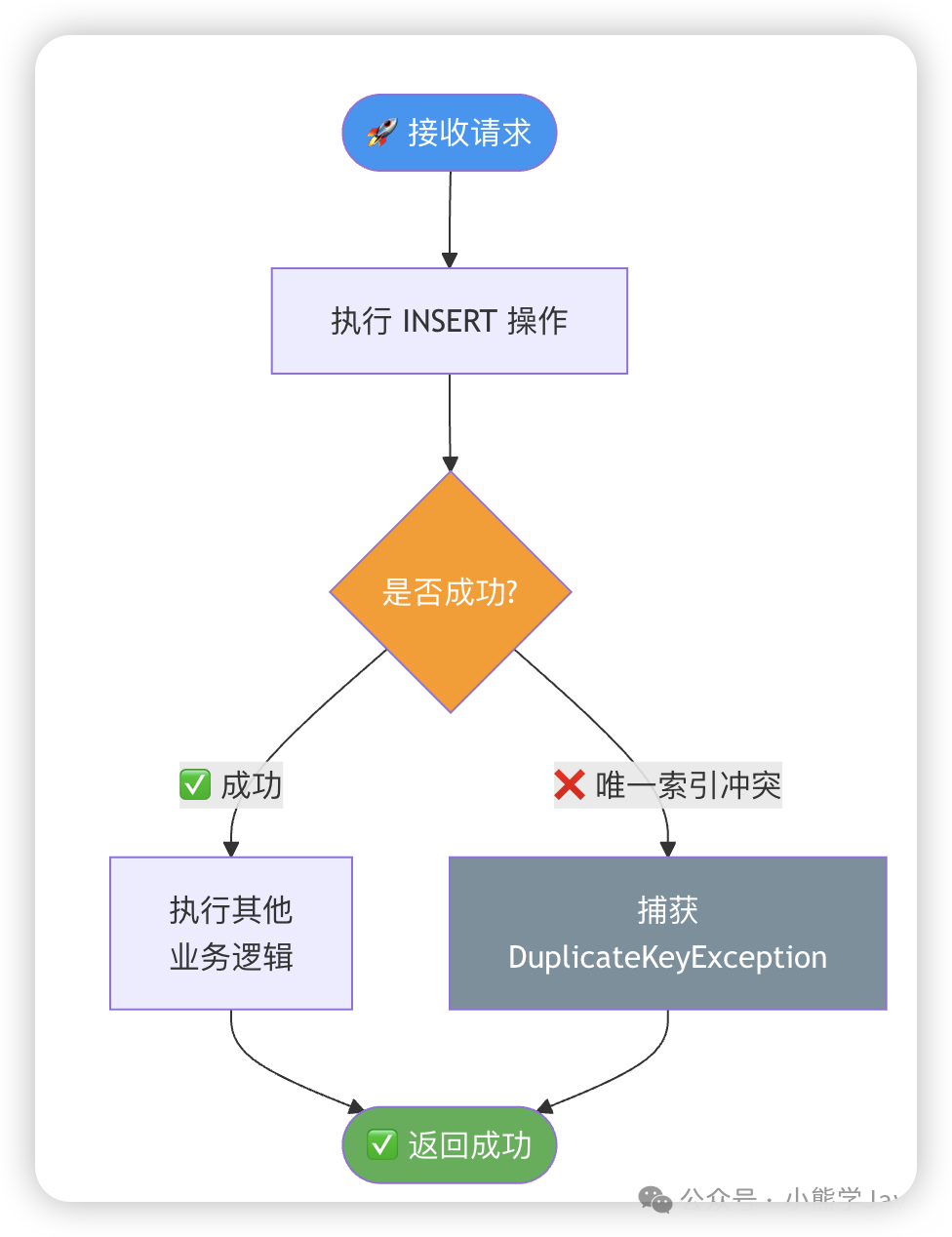
4. 唯一索引(最简单有效)
为防重复字段添加唯一索引,是最直接有效的方案之一。
-- 给order表的code字段添加唯一索引
ALTER TABLE `order` ADD UNIQUE KEY `un_code` (`code`);
代码中捕获唯一索引冲突异常,并返回成功。
public Result saveOrder(Order order) {
try {
orderMapper.insert(order);
return Result.success("创建成功");
} catch (DuplicateKeyException e) {
// 唯一索引冲突,说明是重复请求
log.info("订单已存在,code={}", order.getCode());
return Result.success("订单已存在"); // 保证幂等性
}
}
软删除场景的特殊处理
在采用“软删除”(使用is_deleted标志位)的业务中,由于历史记录存在,无法直接建立唯一索引。可通过以下方式解决:
方式一:扩展is_delete列的含义,删除时将其值设为记录主键ID。
UPDATE tb_order_worker SET is_delete = id WHERE order_id = 'xxx';
ALTER TABLE tb_order_worker ADD UNIQUE KEY `un_order_delete` (`order_id`, `is_delete`);
方式二:新增辅助列order_rid,删除时将其设为主键值。
ALTER TABLE tb_order_worker ADD COLUMN order_rid BIGINT DEFAULT 0;
ALTER TABLE tb_order_worker ADD UNIQUE KEY `un_order` (`order_id`, `is_delete`, `order_rid`);
UPDATE tb_order_worker SET is_delete = 1, order_rid = id WHERE order_id = 'xxx';
5. 防重表(灵活方案)
当仅部分业务场景需要防重时,可单独创建一张防重表。
CREATE TABLE `repeat_check` (
`id` BIGINT PRIMARY KEY AUTO_INCREMENT,
`unique_key` VARCHAR(255) NOT NULL COMMENT '唯一标识,如:paipai_0001',
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP,
UNIQUE KEY `un_key` (`unique_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
业务操作前,先尝试向防重表插入唯一标识。
@Transactional
public Result saveOrder(Order order) {
// 1. 生成唯一标识
String uniqueKey = order.getSource() + "_" + order.getCode();
try {
// 2. 插入防重表
RepeatCheck check = new RepeatCheck();
check.setUniqueKey(uniqueKey);
repeatCheckMapper.insert(check);
// 3. 插入成功,执行业务操作
orderMapper.insert(order);
return Result.success("创建成功");
} catch (DuplicateKeyException e) {
// 4. 唯一索引冲突,说明是重复请求
return Result.success("订单已存在");
}
}
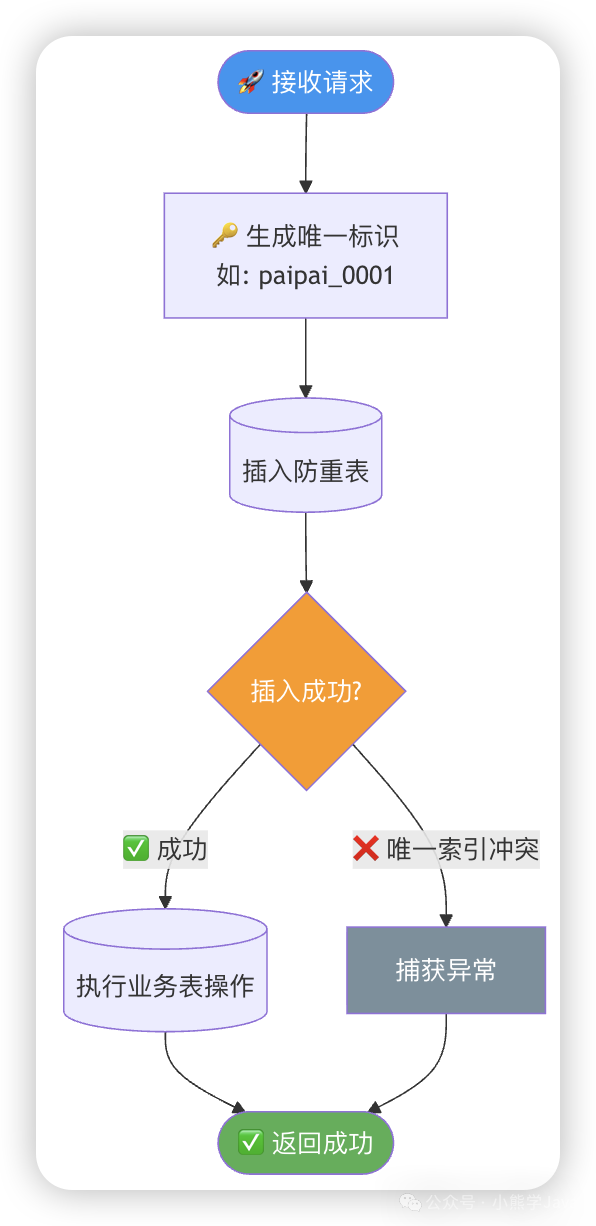 关键:防重表与业务表需在同一数据库/中间件实例,且操作要在同一事务中,以保证原子性。
关键:防重表与业务表需在同一数据库/中间件实例,且操作要在同一事务中,以保证原子性。
6. 状态机(状态流转业务)
对于订单等有状态流转的业务,可利用状态的前置条件来保证幂等性。
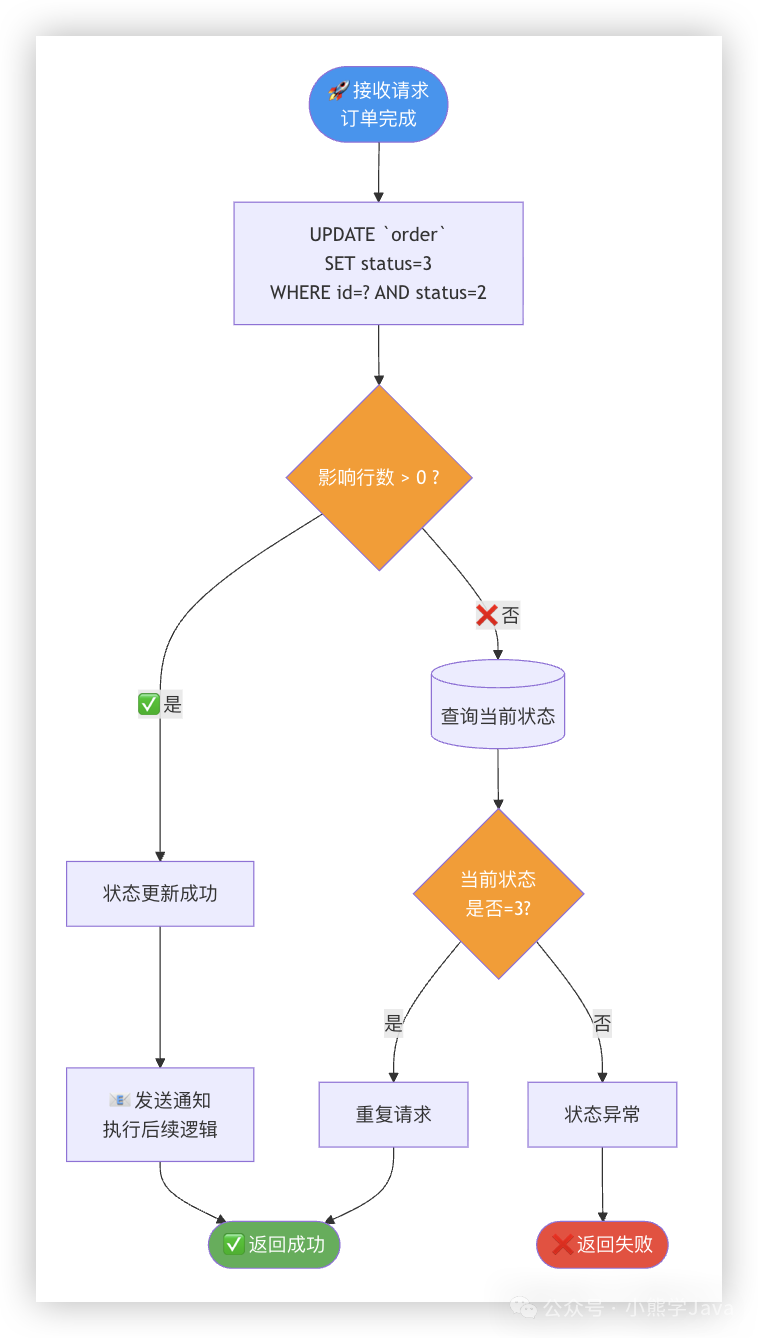
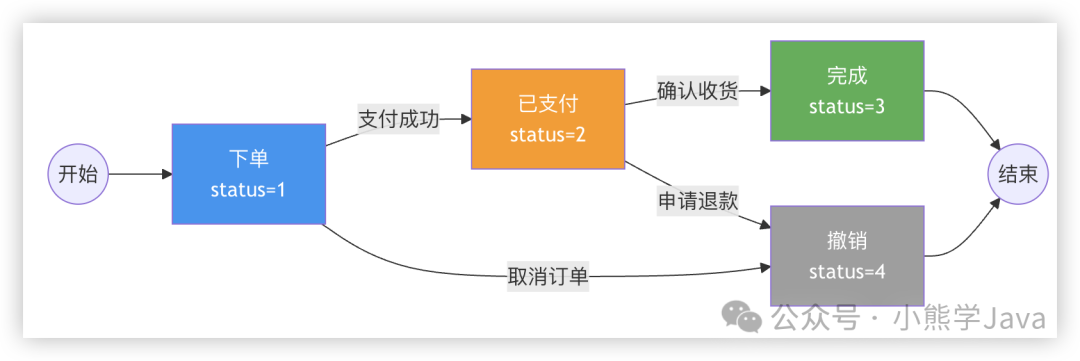 假设订单状态需从“已支付”(2)变为“完成”(3)。
假设订单状态需从“已支付”(2)变为“完成”(3)。
UPDATE `order` SET status = 3 WHERE id = 123 AND status = 2;
public Result completeOrder(Long orderId) {
// 使用状态机更新:当前状态必须是"已支付"才能变成"完成"
int rows = orderMapper.updateStatus(orderId,
OrderStatus.COMPLETED.getCode(), // 新状态:完成
OrderStatus.PAID.getCode() // 当前状态:已支付
);
if (rows > 0) {
// 状态更新成功,执行后续业务逻辑
sendNotification(orderId);
return Result.success("订单已完成");
} else {
// 状态未更新,可能是重复请求或状态已变更
Order order = orderMapper.selectById(orderId);
if (order.getStatus() == OrderStatus.COMPLETED.getCode()) {
// 状态已经是完成,说明是重复请求
return Result.success("订单已完成");
} else {
// 状态不对,业务异常
return Result.fail("订单状态异常");
}
}
}
 此方案天然适合状态流转业务,无需额外字段,但仅限于更新状态字段的场景。
此方案天然适合状态流转业务,无需额外字段,但仅限于更新状态字段的场景。
7. 分布式锁(通用方案)
在云原生/IaaS架构的分布式系统中,利用Redis等实现的分布式锁是通用选择。
方式一:使用SET命令
public Result saveOrder(Order order) {
String lockKey = "order:lock:" + order.getCode();
String lockValue = UUID.randomUUID().toString();
try {
// 尝试获取锁,设置30秒过期
Boolean success = redisTemplate.opsForValue()
.setIfAbsent(lockKey, lockValue, 30, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(success)) {
// 获取锁成功,说明是首次请求
orderMapper.insert(order);
return Result.success("创建成功");
} else {
// 获取锁失败,说明是重复请求
return Result.success("订单已存在");
}
} finally {
// 释放锁(需判断是否是自己的锁)
String value = redisTemplate.opsForValue().get(lockKey);
if (lockValue.equals(value)) {
redisTemplate.delete(lockKey);
}
}
}
方式二:使用Redisson框架(推荐)
@Autowired
private RedissonClient redissonClient;
public Result saveOrder(Order order) {
String lockKey = "order:lock:" + order.getCode();
RLock lock = redissonClient.getLock(lockKey);
try {
// 尝试获取锁,等待0秒,锁定30秒
boolean acquired = lock.tryLock(0, 30, TimeUnit.SECONDS);
if (acquired) {
// 获取锁成功,执行业务操作
orderMapper.insert(order);
return Result.success("创建成功");
} else {
// 获取锁失败,说明是重复请求
return Result.success("订单已存在");
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return Result.fail("系统异常");
} finally {
// 只有持有锁的线程才能释放锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
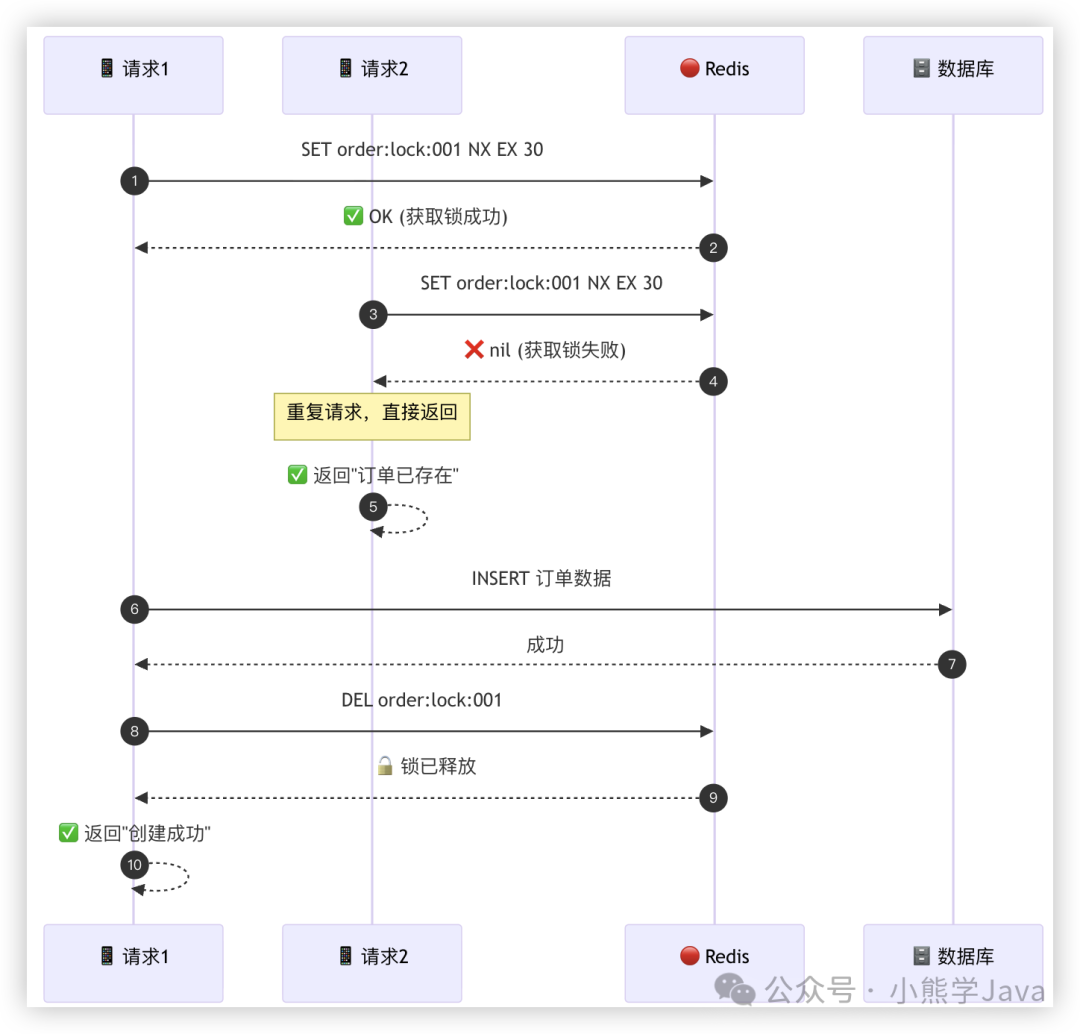 注意:务必设置合理的锁过期时间,避免死锁或锁过早释放。对于需要永久防重的场景(如订单号),建议“分布式锁+唯一索引”组合使用。
注意:务必设置合理的锁过期时间,避免死锁或锁过早释放。对于需要永久防重的场景(如订单号),建议“分布式锁+唯一索引”组合使用。
8. Token机制(前后端配合)
该方案需要两次请求:第一次获取Token,第二次携带Token执行业务。
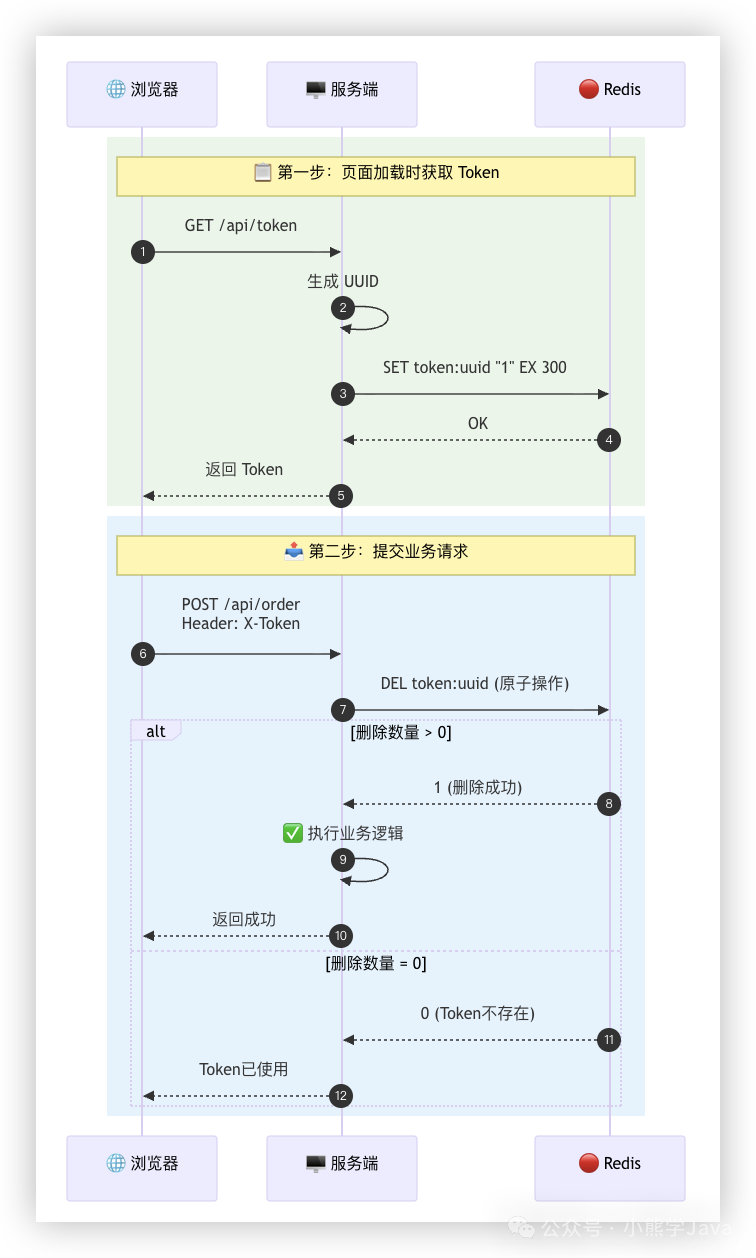 第一步:服务端生成Token
第一步:服务端生成Token
@RestController
@RequestMapping("/api")
public class TokenController {
@GetMapping("/token")
public Result getToken() {
// 生成全局唯一Token
String token = UUID.randomUUID().toString().replace("-", "");
// 存入Redis,设置5分钟过期
String key = "idempotent:token:" + token;
redisTemplate.opsForValue().set(key, "1", 5, TimeUnit.MINUTES);
return Result.success(token);
}
}
第二步:提交请求时验证并删除Token
@PostMapping("/order")
public Result createOrder(@RequestHeader("X-Token") String token,
@RequestBody Order order) {
String key = "idempotent:token:" + token;
// 使用Redis的原子删除操作判断Token是否首次使用
Boolean deleted = redisTemplate.delete(key);
if (Boolean.TRUE.equals(deleted)) {
// Token验证通过,执行业务逻辑
orderMapper.insert(order);
return Result.success("创建成功");
} else {
// Token不存在或已被使用,按幂等性返回成功
return Result.success("请勿重复提交");
}
}
也可使用Lua脚本保证“验证-删除”的原子性。
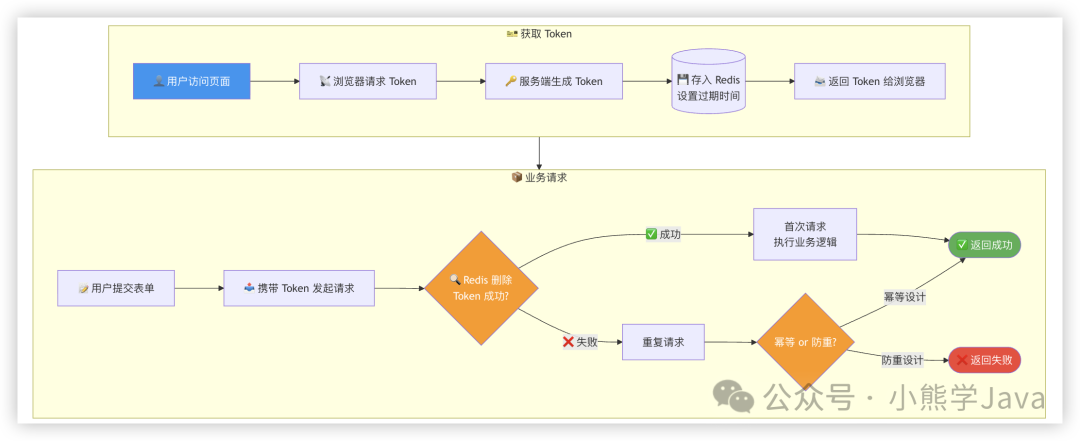 关键:Token需全局唯一,推荐使用UUID或雪花算法生成。若是防重设计,Token无效时应返回失败提示。
关键:Token需全局唯一,推荐使用UUID或雪花算法生成。若是防重设计,Token无效时应返回失败提示。
方案对比与选型建议
| 各方案对比如下: |
方案 |
适用场景 |
优点 |
缺点 |
推荐度 |
| Insert前先Select |
低并发简单场景 |
简单易懂 |
并发下会失效 |
⭐⭐ |
| 悲观锁 |
金融、库存等强一致场景 |
数据一致性高 |
性能差,可能死锁 |
⭐⭐⭐ |
| 乐观锁 |
更新操作、冲突较少的场景 |
性能较好 |
需要额外version字段 |
⭐⭐⭐⭐ |
| 唯一索引 |
插入操作 |
简单有效,数据库兜底 |
需要有唯一业务字段 |
⭐⭐⭐⭐⭐ |
| 防重表 |
部分场景需要防重 |
灵活,不影响业务表 |
需要额外维护表 |
⭐⭐⭐⭐ |
| 状态机 |
状态流转类业务 |
天然适合,无额外开销 |
仅适用特定场景 |
⭐⭐⭐⭐ |
| 分布式锁 |
分布式系统通用场景 |
性能好,通用性强 |
需要Redis等中间件 |
⭐⭐⭐⭐⭐ |
| Token机制 |
前后端配合的表单提交 |
可控性强 |
需要两次请求 |
⭐⭐⭐⭐ |
选型建议:
- 简单插入:优先考虑唯一索引,数据库层面兜底,简单可靠。
- 更新场景:推荐乐观锁(通用)或状态机(特定业务)。
- 分布式系统:推荐 分布式锁 + 唯一索引 组合,兼顾性能与安全。
- 前端可控场景:可采用Token机制,有效防止用户重复点击。
- 强一致性场景:考虑悲观锁,牺牲部分性能保障数据绝对正确。
实际项目中常采用多层次防护,例如:
@Transactional
public Result createOrder(String token, Order order) {
// 第一层:Token验证(防重复点击)
if (!tokenService.validateToken(token)) {
return Result.success("请勿重复提交");
}
// 第二层:分布式锁(并发控制)
String lockKey = "order:lock:" + order.getCode();
RLock lock = redissonClient.getLock(lockKey);
try {
if (!lock.tryLock(0, 30, TimeUnit.SECONDS)) {
return Result.success("订单处理中");
}
// 第三层:唯一索引(最终保障)
try {
orderMapper.insert(order);
return Result.success("创建成功");
} catch (DuplicateKeyException e) {
return Result.success("订单已存在");
}
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
总结
接口幂等性是保障网络/系统数据一致性与业务可靠性的基石。面对重复提交、消息重试等复杂场景,单一方案往往难以覆盖所有情况。理解每种方案的原理、优缺点及适用场景,并根据实际业务特点进行组合式设计,是构建健壮系统的关键。从简单的唯一索引到复杂的分布式锁与Token机制,合理选型与搭配,方能从容应对高并发下的各类幂等性挑战。
 发表于 2025-12-3 00:23:59
|
查看: 179|
回复: 0
发表于 2025-12-3 00:23:59
|
查看: 179|
回复: 0
