在上一篇《告别数据库“膨胀”:Dify x SLS 构建高可用生产级 AI 架构》中,我们深度剖析了Dify在大规模生产场景下数据库因日志写入而面临的性能瓶颈,并介绍了通过SLS插件实现“存算分离”的硬核改造方案。
然而,解决“数据存储”只是跨过了生产落地的第一道坎。面对复杂的微服务运维、波动的AI潮汐流量,如何构建一个弹性、免运维的“计算底座”同样关键。本文将视野从单一的数据架构扩展至全栈基础设施,为您介绍基于阿里云 SAE(Serverless应用引擎)与 SLS(日志服务)的终极生产级解决方案。
随着LLM应用的爆发式增长,Dify以其强大的工作流编排与友好的可视化界面,正成为企业构建AI应用的首选。然而,当应用从本地Demo迈向大规模生产时,开发者常会遭遇两大“隐形”挑战:运维复杂度的剧增与数据架构的性能瓶颈。
现状与挑战:Dify规模化落地的架构瓶颈
在单机Demo阶段,使用Docker Compose部署配合默认的PostgreSQL存储方案完全够用。但一旦进入生产环境,这两项基础设施往往最先成为性能与扩展性的瓶颈。
运维管理复杂
Dify是一个由API服务、Worker、Web前端、KV缓存、关系型数据库、向量数据库等多个组件构成的微服务架构。在生产环境中,这种架构给运维带来了很大挑战:
- 资源缺乏弹性: AI应用通常具有明显的流量波峰波谷特征。若采用自建Kubernetes或ECS集群,扩容响应滞后,高峰期用户排队等待,低谷期又造成大量资源闲置,推高成本。
- 维护成本高昂: 保障高可用、配置负载均衡、处理节点故障、执行蓝绿/灰度发布等基础设施工作,不仅技术门槛高,还会大量挤占开发团队本应用于业务创新的精力。
- 性能瓶颈明显: 默认部署方式下的QPS能力有限,难以支撑高并发场景,尤其在推理密集型任务下容易成为系统瓶颈。
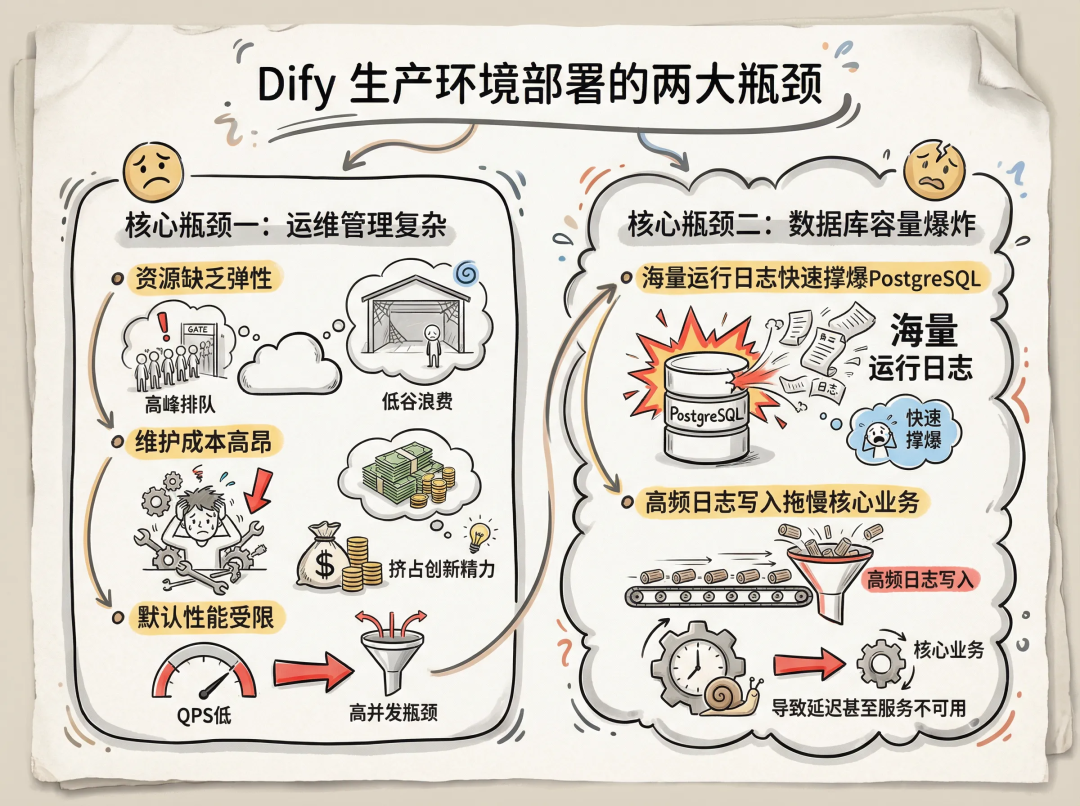
数据库容量爆炸
Dify默认将所有数据(包括业务元数据和运行日志)存储在 PostgreSQL 中。随着业务量增长,“数据特征”与“存储引擎”的错配问题日益凸显:
- 日志“撑爆”数据库: Workflow的每一次节点执行,都会完整记录输入输出、Prompt、推理过程及Token统计等详细信息。在生产级高并发场景下,这些数据占据了数据库绝大部分资源,导致表空间迅速膨胀。
- 拖慢核心业务: 高频、高吞吐的日志写入会大量占用数据库连接池和I/O资源,严重干扰核心业务操作(如创建应用、知识库检索、对话上下文管理等),导致响应延迟、超时甚至服务不可用。
协同赋能:SAE与SLS的核心优势
为解决上述瓶颈,SAE与SLS协同发力——SAE聚焦弹性算力调度,SLS专攻海量日志存储,共同构建高性能、高可用的Dify运行底座。
SAE:极致弹性的Dify全托管运行环境
SAE不仅负责Dify核心微服务(API、Worker、Sandbox)的编排,更通过一键化模板集成了Dify运行所需的完整云生态。
- 一键全栈交付: 开发者无需手动搭建复杂环境。通过预置模板,可一键部署完整的微服务集群,并自动创建和集成连通日志服务SLS(工作流日志存储)、表格存储Tablestore(向量存储)、云数据库Redis版(缓存)及RDS for PostgreSQL(元数据存储)等阿里云服务,无需逐个购买和配置,实现“开箱即是生产级”的交付体验。
- 企业级高可用保障: 实例自动分布于多可用区,配合健康检查与自愈机制规避单点故障。支持金丝雀发布,确保在工作流频繁迭代时,流量切换平滑无感。
- 秒级算力弹性: 完美适配AI业务的“潮汐特征”。SAE支持按CPU/内存利用率或QPS指标进行自动扩缩容。在推理高峰期,秒级拉起Worker实例抗压;在业务低谷期,自动释放闲置资源,将算力成本严格控制在“有效使用”范围内。
- 深度性能调优: SAE对Dify实施了穿透代码与架构的“立体调优”,不仅在底层修补了Redis集群适配与慢SQL短板,更精准调优了运行参数并对齐了资源规格。这一全链路改造驱动吞吐量实现从10 QPS到500 QPS的50倍跃迁,确保AI响应如丝般顺滑。
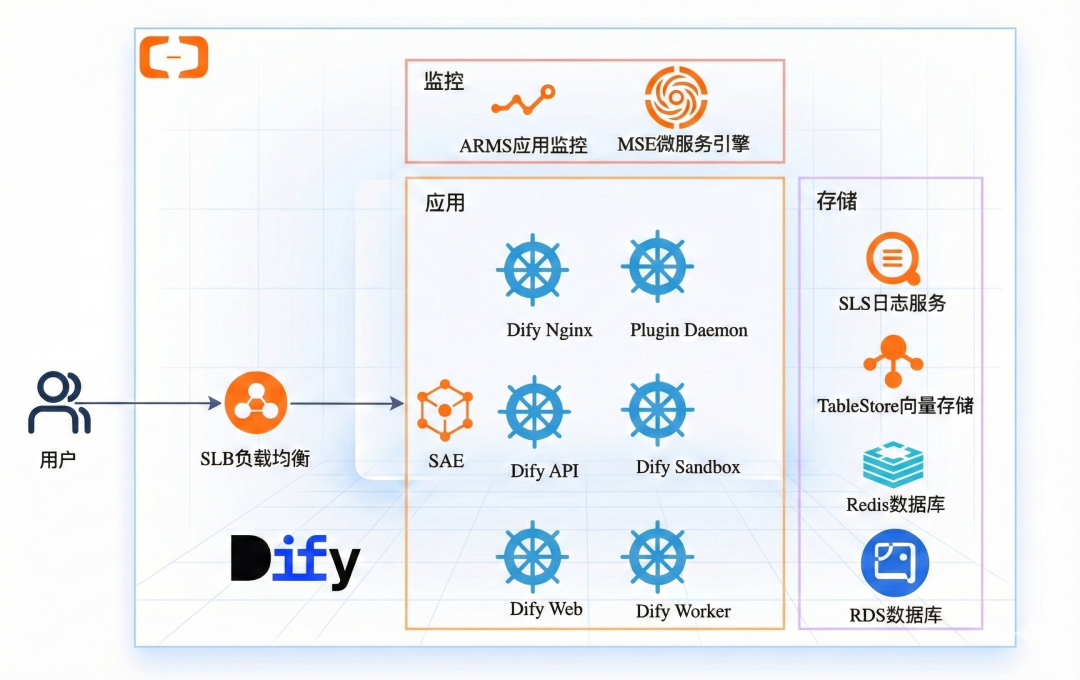
SLS:支撑海量数据的“存算分离”方案
SLS并非简单的数据库替代品,而是专为日志场景设计的云原生基础设施。相比于PostgreSQL,SLS在Dify场景下实现了四个维度的架构升级:
- 极致存储弹性: 不同于数据库需按“峰值”预置资源,SLS作为Saas化服务,天然支持秒级弹性伸缩。无论是深夜的低谷还是突发的推理洪峰,都能自适应承载,无需关心分片或容量上限。
- 架构解耦负载隔离: 利用追加写入特性,避免了数据库常见的随机I/O与锁竞争,轻松支撑万级TPS吞吐。同时通过将日志负载彻底剥离至云端,确保海量日志写入不影响Dify核心业务的响应速度。
- 分层存储低成本留存: 依托高压缩比技术,热数据实时分析,冷数据自动沉降至归档存储,可以远低于数据库SSD的成本满足长周期的审计与回溯需求。
- 开箱即用的业务洞察: 内置的OLAP分析引擎支持SQL实时查询、可视化报表与告警监控,帮助开发者将沉睡的日志数据转化为直观的业务洞察。
极简部署:1分钟定义生产级底座
SAE应用中心内置了深度优化的Dify生产级模板,通过简单的参数配置,即可一键交付一套高可用就绪的运行环境,告别繁琐的YAML编写与环境调试。
Step 1:选择部署模板
登录SAE控制台,进入应用中心,选择 “Dify 社区版 - Serverless 部署” 。
Step 2:配置参数与规格选型
目前提供了Dify高性能版、Dify高可用版、Dify测试版三种模板。
如果是应对高并发生产场景,建议优先选择 Dify高性能版 ,该版本专门针对 api 镜像以及 plugin-daemon 镜像做了深度优化,运行效率更高。配置过程极为精简,只需手动填写各云服务的密码并选定所属的VPC与子网(VSW),系统便会针对选定的云资源给出一份总预估价格,确保成本清晰透明。
Step 3:提交并访问服务
点击提交后,系统会自动完成核心服务的部署与云资源关联。
部署完成后,直接在浏览器输入控制台提供的服务地址 ${EXTERNAL-IP}:${PORT} ,即可开始您的Dify应用编排之旅。
注: 当Dify启动并运行之后,SLS插件会自动创建相关的logstore和索引配置。无须手动干预,直接从SLS控制台进入对应的project,即可对工作流日志进行实时的查询和分析。
50倍性能跃迁:SAE从10 QPS到500 QPS的突破之路
Dify社区版的默认配置仅能支撑10 QPS,但这仅仅是起步。从“尝鲜”到500 QPS的生产级扩容,并非简单的堆砌服务器资源,而是一场步步惊心的“闯关游戏”。SAE团队通过全链路压测,为您提前探明并攻克了这条晋级之路上的两大核心关卡。
瓶颈一:突破10 QPS限制——组件并发与数据库连接的协同调优
1. 为什么默认配置只有10 QPS?
Dify社区版默认配置更多是为了方便开发者快速试用,而非为大规模生产环境设计。其核心组件dify-api的默认参数极为保守:
SERVER_WORKER_AMOUNT(工作进程数):1
SERVER_WORKER_CONNECTIONS(单进程最大连接数):10
这两个参数直接锁死了单节点的吞吐上限。但在生产环境中,我们不能简单地将这些参数“调大十倍”,因为应用层的并发能力提升,立即会引发下游数据库的连锁反应。
2. 牵一发而动全身的“连接池”难题
随着QPS的增长,dify-api和dify-plugin-daemon等组件会向PostgreSQL发起海量连接。如果缺乏全链路的参数协同,系统极易陷入瘫痪:
- 连接数被打满: PostgreSQL的总连接数是有限的,盲目增加组件并发,会导致数据库连接迅速耗尽,后续请求直接报错。
- 组件间的连接争抢: SQLAlchemy连接池有“懒加载”机制,且空闲连接在过期前不会释放。如果配置不当,会出现非核心组件占用大量空闲连接,而核心组件因拿不到连接而“饥饿”的情况。
解决方案:经过实战验证的“生产级配置矩阵”
为了避免用户陷入繁琐的参数试错循环,SAE团队在真实生产环境下进行了多轮全链路压测。摸索出了不同流量档位下API并发度、数据库连接池大小与各组件资源规格之间的 生产级配置清单 。用户无需关心具体的参数计算,只需根据预估流量选择对应的规格档位,确保每一份算力都能转化为实际的业务吞吐量。
注: 压测场景并不包含代码执行(Code Sandbox)链路。dify-sandbox组件的规格与数量请根据实际业务中代码运行的复杂度自行评估调整。
配置清单:https://help.aliyun.com/zh/sae/dify-performance-optimization
瓶颈二:从200 QPS到500 QPS —— Redis单点瓶颈与读写分离
1. 集成ARMS链路追踪定位性能瓶颈
在将数据库连接优化、QPS稳定提升至200后,系统吞吐量难以进一步提高。为定位瓶颈,SAE团队通过SAE平台深度集成的ARMS应用监控,对dify-plugin-daemon组件进行链路分析——在SAE控制台的应用详情页点击“应用监控”,即可查看耗时最长的调用链路。
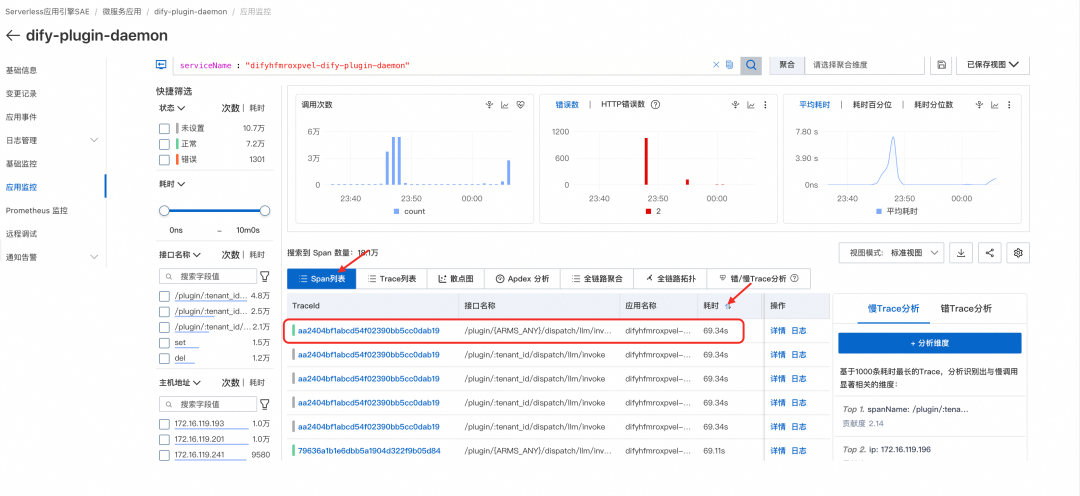
Trace数据显示,下游Redis的SET/DEL操作频繁失败。SAE团队尝试将Redis实例垂直扩容至最大规格(64核),但效果甚微:QPS仅小幅提升,SET/DEL操作延迟却急剧升高,CPU利用率迅速打满。
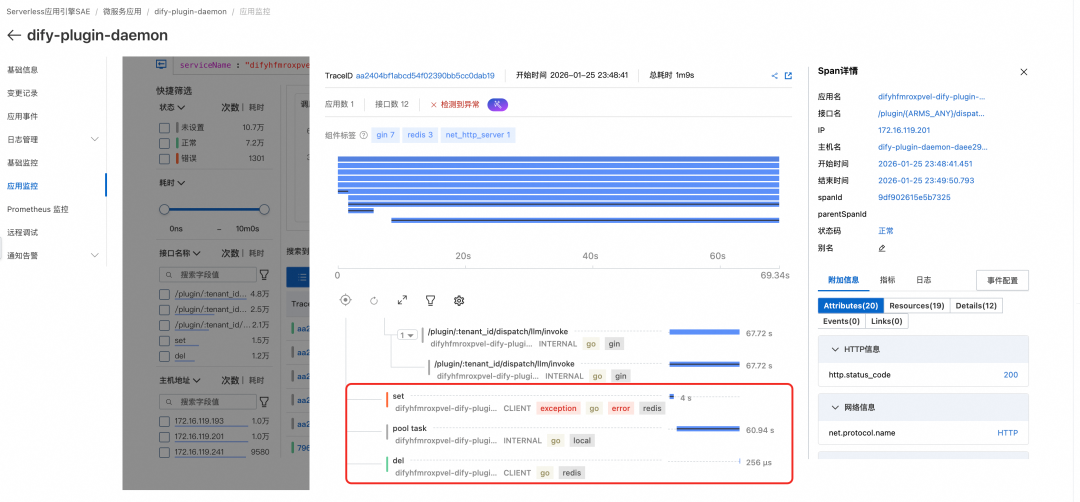
2. Dify-plugin-daemon高频读写Redis引发单点拥堵
通过代码分析发现,这是Dify业务逻辑与Redis单点架构冲突的结果:
- dify-plugin-daemon在处理每次数据链路请求时,都会生成一个新的Session ID并写入Redis。这种高频的写入逻辑导致Redis请求量居高不下。
- 原生架构中,所有的Session读写请求都全部集中在同一个Redis节点上。在200+ QPS的高并发冲击下,Redis单线程处理能力达到极限,导致set和del等基础操作的耗时急剧增大,从而阻塞了整个请求链路。
解决方案:集群化改造实现读写分离
为了突破单机架构限制,SAE团队深入组件底层,对dify-plugin-daemon进行了集群化适配:
- 补全集群协议: 针对原生组件不支持Redis Cluster的问题,SAE团队修改了底层代码,使其完整支持Redis Cluster协议。
- 实现读写分离: 通过架构升级,将原本集中在单机上的海量请求分发到集群。利用集群的多节点特性,实现了流量的负载分担与读写分离。
这一改造彻底解决了单点瓶颈,成功支撑业务吞吐量从200 QPS平滑提升至500 QPS。
激活全链路数据价值:SLS从“黑盒运行”到“深度洞察”
Dify上线后,如何评估模型的成本和性能?如何分析业务的走势?依托SLS强大的OLAP分析引擎,我们无需预先定义表结构,即可对Dify的工作流日志进行深度挖掘,构建覆盖“技术指标”与“业务指标”的全景仪表盘。
基础设施视角:透视LLM成本与性能
对于Dify的LLM节点,workflow_node_execution日志中的process_data字段中详细记录了模型的调用情况,可以用来对模型调用情况进行秒级多维分析。
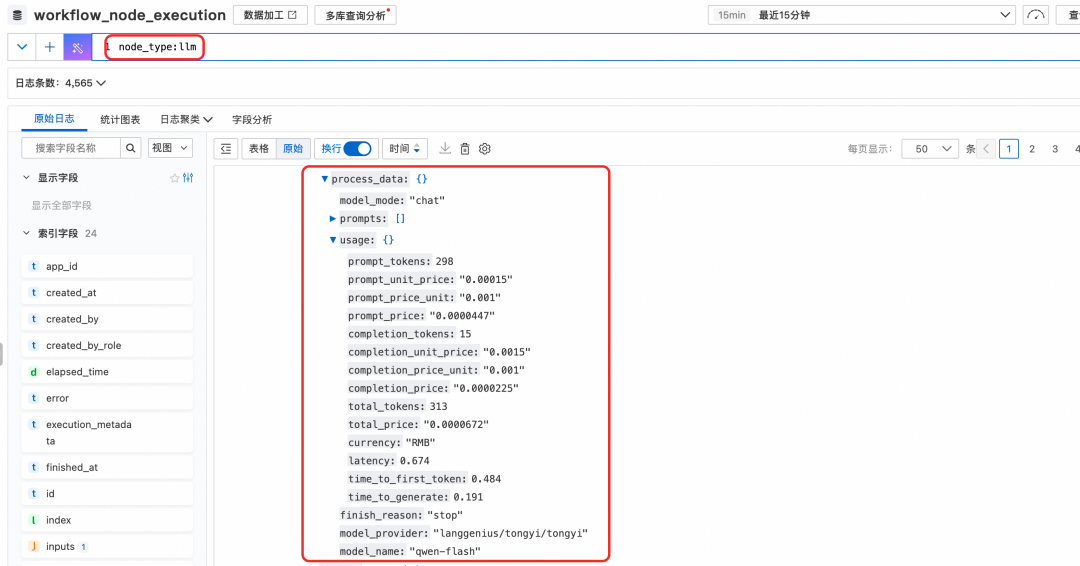
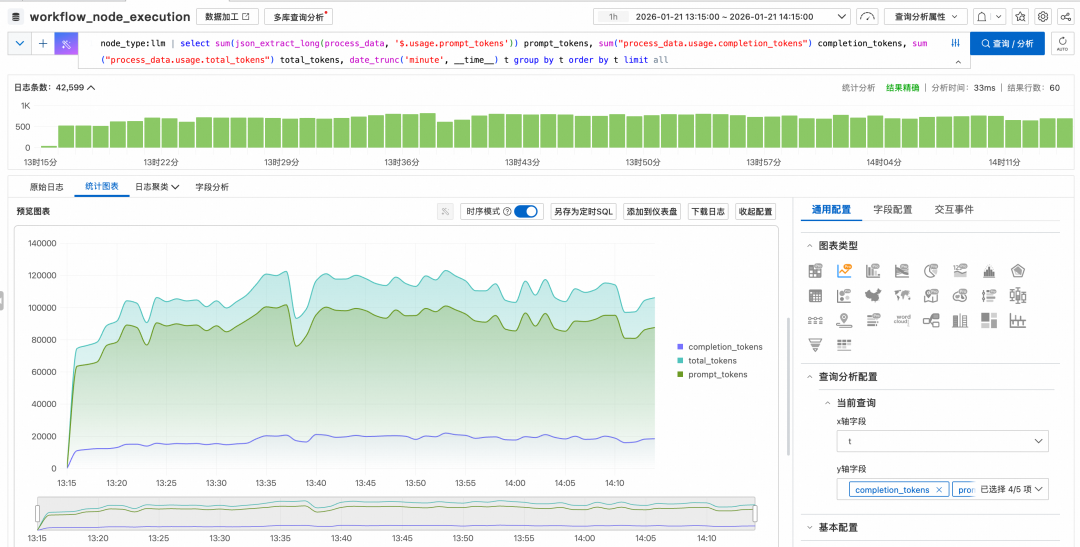
场景 A:Token消耗与成本审计
实时监控Token的消耗趋势,是控制AI成本的关键。我们可以统计输入(prompt_tokens)、输出(completion_tokens)及总Token数随时间的变化曲线,精准识别异常流量。
分析SQL示例:
node_type:llm | select
sum(
json_extract_long(process_data, '$.usage.prompt_tokens')
) prompt_tokens,
sum("process_data.usage.completion_tokens") completion_tokens,
sum("process_data.usage.total_tokens") total_tokens,
date_trunc('minute', __time__) t
group by
t
order by
t
limit
all
注: json中的字段可以在SQL中直接用json_extract_xxx函数进行提取分析,如 json_extract_long(process_data, '$.usage.prompt_tokens') 。对于常用的字段建议额外建立json子索引,然后在SQL中就可以引用对应的列名,如 "process_data.usage.completion_tokens" , 便于进行更高效的统计分析。
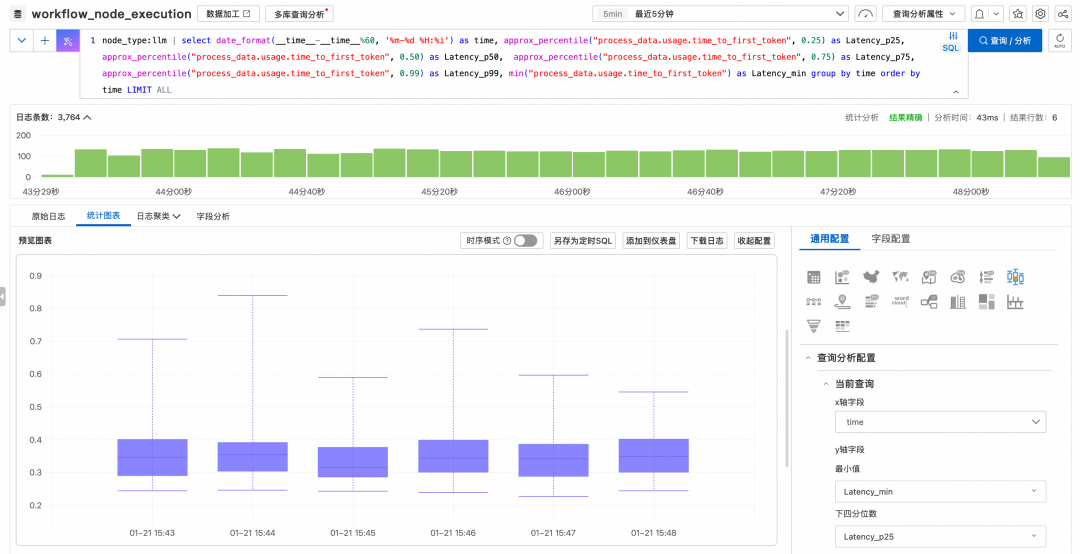
场景 B:首字延迟(TTFT)性能分位分析
LLM的响应速度直接影响用户体验。通过分析 time_to_first_token 的P50、P90、P99分位值,可以客观评估模型在不同负载下的响应稳定性,为模型路由或推理加速提供数据支撑。
分析SQL示例:
node_type:llm | select
date_format(__time__-__time__ % 60, '%m-%d %H:%i') as time,
approx_percentile("process_data.usage.time_to_first_token", 0.25) as Latency_p25,
approx_percentile("process_data.usage.time_to_first_token", 0.50) as Latency_p50,
approx_percentile("process_data.usage.time_to_first_token", 0.75) as Latency_p75,
approx_percentile("process_data.usage.time_to_first_token", 0.99) as Latency_p99,
min("process_data.usage.time_to_first_token") as Latency_min
group by
time
order by
time
limit
all
业务运营视角:洞察用户意图与转化
除了底层的模型指标,SLS还能帮助我们深入理解业务逻辑。以一个“电商智能客服助手”的Dify应用为例,我们可以利用SQL拆解工作流节点的输入输出,辅助运营决策。
场景 A:用户意图分布趋势
通过分析工作流中“意图识别”节点的输出结果,我们可以量化统计用户咨询的高频类目(如:退换货、物流查询、优惠券),并观察这些需求随时间的变化趋势,从而指导知识库的优化方向。
分析SQL示例:
* and title: 用户意图识别 | select
json_extract_scalar(outputs, '$.text') intent,
count(1) pv
group by
intent
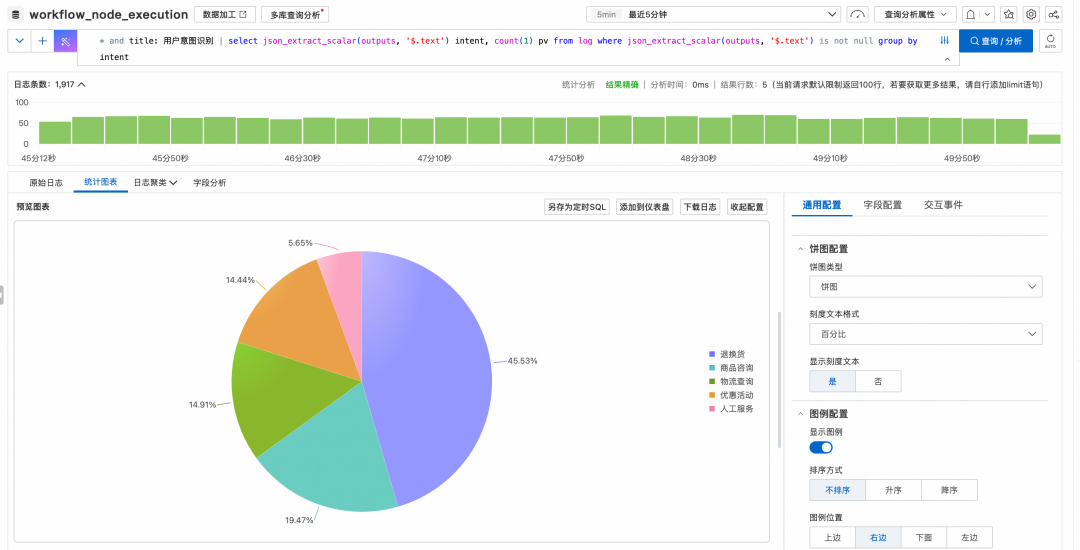
场景 B:异常诊断与漏斗分析
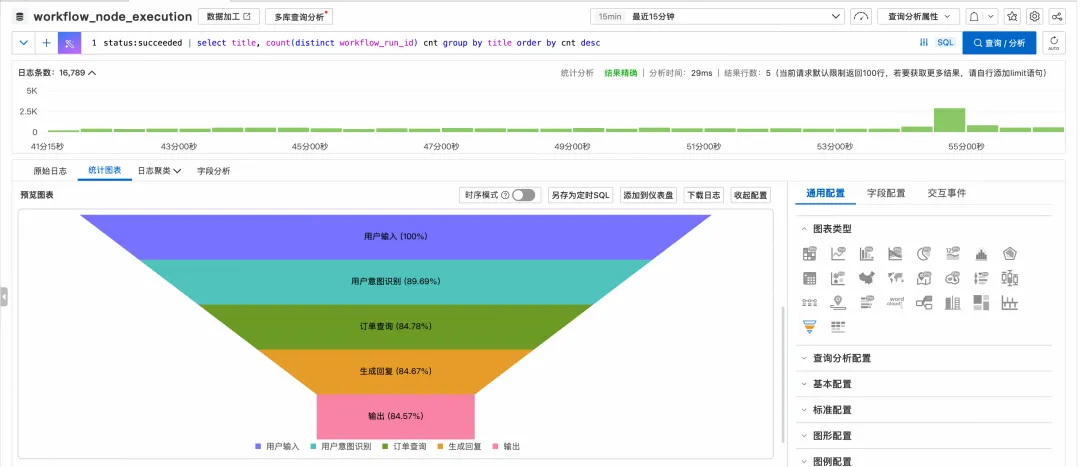
通过统计特定节点的错误率或特定意图的后续流转情况,构建漏斗图,快速定位导致用户流失的节点。例如,分析“商品检索”节点的空结果率,以判断是否需要扩充商品知识库。可以通过漏斗图,分析观察工作流哪些中间节点出现异常失败的比率较高。
分析SQL示例:
status:succeeded | select
title,
count(distinct workflow_run_id) cnt
group by
title
order by
cnt desc
结语:让AI应用回归业务本质
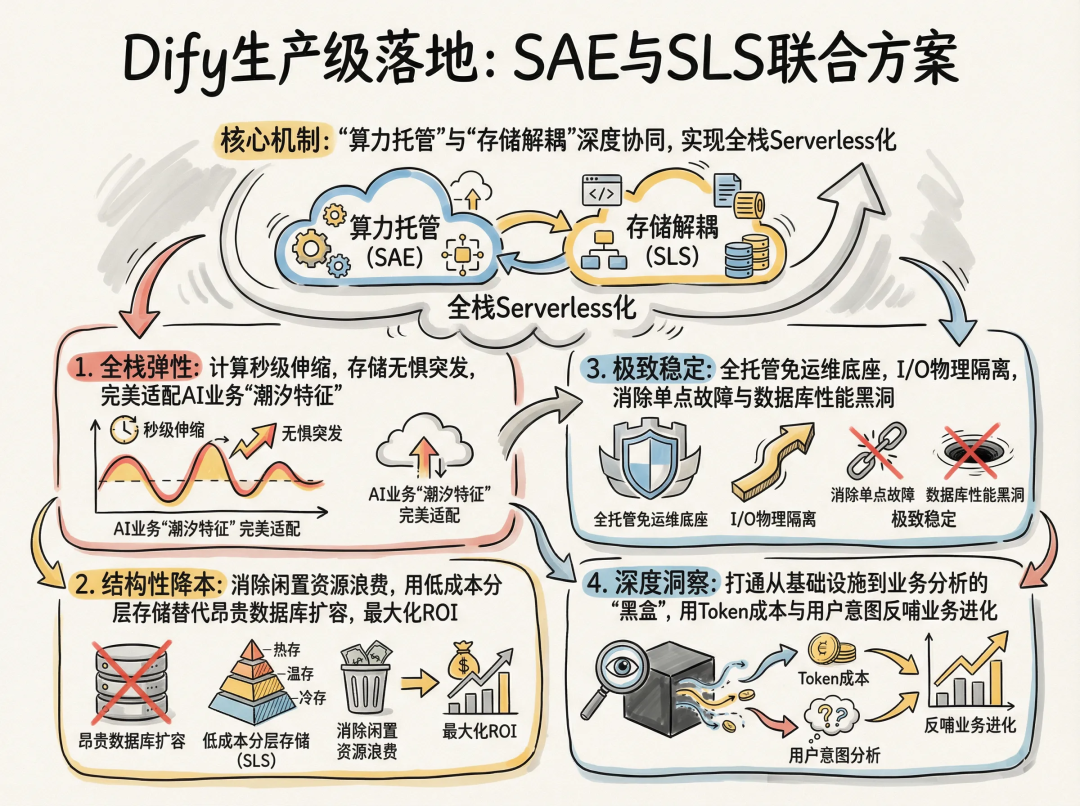
从“能用”到“好用”,Dify的生产级落地需要坚实的基础设施支撑。SAE与SLS的联合方案,不仅仅是两个云产品的简单叠加,而是通过“算力托管”与“存储解耦”的深度协同,为Dify带来了全栈Serverless化的架构质变:
- 全栈弹性: 计算层随流量秒级伸缩,存储层无惧突发吞吐,完美适配AI业务的“潮汐特征”。
- 结构性降本: 彻底消除闲置资源浪费,用低成本的分层存储替代昂贵的数据库扩容,最大化ROI。
- 极致稳定: 全托管免运维底座配合I/O物理隔离,彻底消除单点故障风险与数据库性能黑洞。
- 深度洞察: 打通从基础设施监控到业务数据分析的“黑盒”,用Token成本与用户意图数据反哺业务进化。
通过SAE联合SLS发布的这一解决方案,Dify开发者无需再为底层的资源和架构操心,只需一次简单的配置,即可拥有一个高可用、高性能、低成本的AI应用环境,从而真正专注于业务创新与Prompt调优。
立即体验: 欢迎登录阿里云SAE控制台,进入应用中心,搜索Dify模板,勾选Dify高性能版,开启您的一键托管之旅。
了解Serverless应用引擎SAE
阿里云Serverless应用引擎SAE是面向AI时代的一站式容器化应用托管平台,以“托底传统应用、加速AI创新”为核心理念。它简化运维、保障稳定、闲置特性降低75%成本,并通过AI智能助手提升运维效率。

面向AI,SAE集成Dify等主流框架,支持一键部署与弹性伸缩,在Dify场景中实现性能 提升50倍、成本优化30%以上。
产品优势
凭借八年技术沉淀,SAE入选2025年Gartner云原生魔力象限全球领导者,亚洲第一,助力企业零节点管理、专注业务创新。SAE既是传统应用现代化的“托举平台”,也是AI应用规模化落地的“加速引擎”。
1. 传统应用运维的“简、稳、省”优化之道
- 简:零运维心智,专注业务创新
- 稳:企业级高可用,内置全方位保障
- 省:极致弹性,将成本降至可度量
2. 加速AI创新:从快速探索到高效落地
- 快探索:内置Dify、RAGFlow、OpenManus等热门AI应用模板,开箱即用,分钟级启动POC;
- 稳落地:提供生产级AI运行时,性能优化(如Dify性能提升50倍)、无感升级、多版本管理,确保企业级可靠交付;
- 易集成:深度打通网关、ARMS、计量、审计等能力,助力传统应用智能化升级。
适合谁?
✅ 创业团队:没有专职运维,需要快速上线
✅ 中小企业:想降本增效,拥抱云原生
✅ 大型企业:需要企业级稳定性和合规性
✅ 出海企业:需要中国区 + 全球部署
✅ AI创新团队:想快速落地AI应用
了解更多
产品详情页地址:https://www.aliyun.com/product/sae
相关链接:
[1] 阿里云SAE控制台
https://saenext.console.aliyun.com/overview
通过结合 Serverless 应用引擎、高性能 PostgreSQL 数据库以及可扩展的缓存方案,开发者可以轻松构建出像Dify这样复杂的 AI应用 生产底座。如果您想了解更多关于云原生架构实践与AI应用落地的深度讨论,欢迎访问 云栈社区。
 发表于 2026-1-31 06:08:26
|
查看: 239|
回复: 0
发表于 2026-1-31 06:08:26
|
查看: 239|
回复: 0
