Langfuse 是一款开源的 LLM 应用可观测性与分析平台,专为管理和调试由大语言模型驱动的应用程序而设计。它可以帮助开发者追踪每一次LLM调用,分析成本和延迟,从而更好地理解应用行为。今天,我们就来一步步实现如何在本地安装Langfuse,并将其与 LangChain 框架集成,实现对LLM应用的有效监控。
本地化安装
最便捷的本地安装方式是使用 Docker Compose。
# 下载源码
git clone https://github.com/langfuse/langfuse.git
cd langfuse
# 启动服务
docker compose up -d
配置服务
服务启动后,通过浏览器访问 http://localhost:3000,你将看到登录界面。
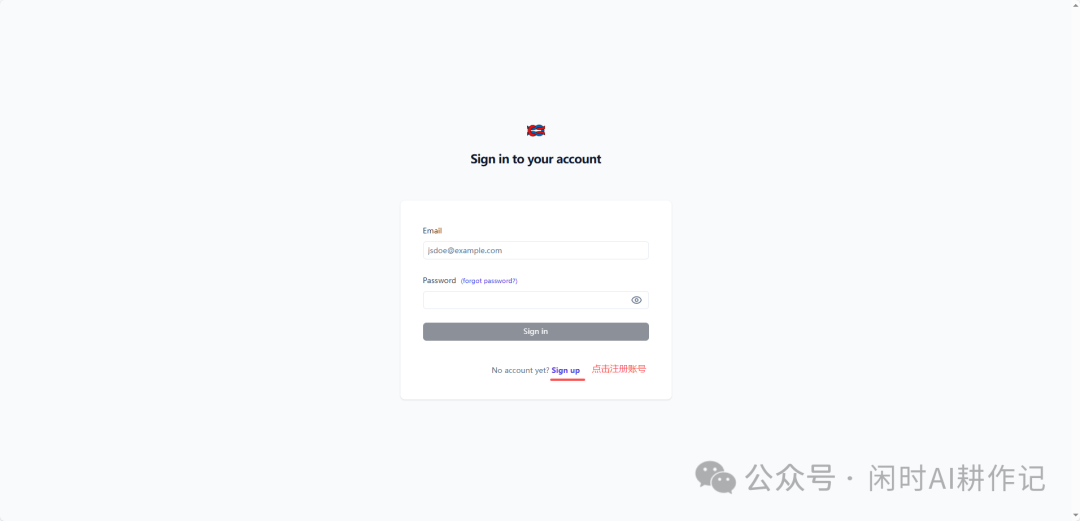
点击 “Sign up” 链接,进入账号注册页面。
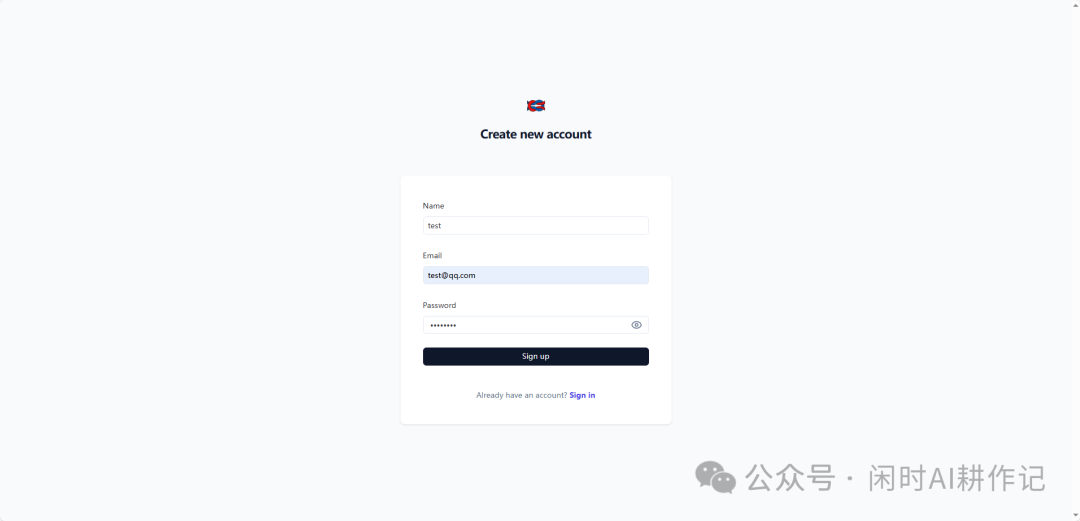
成功登录后,系统会引导你创建一个新的组织(Organization)。点击 “+ New Organization” 按钮。
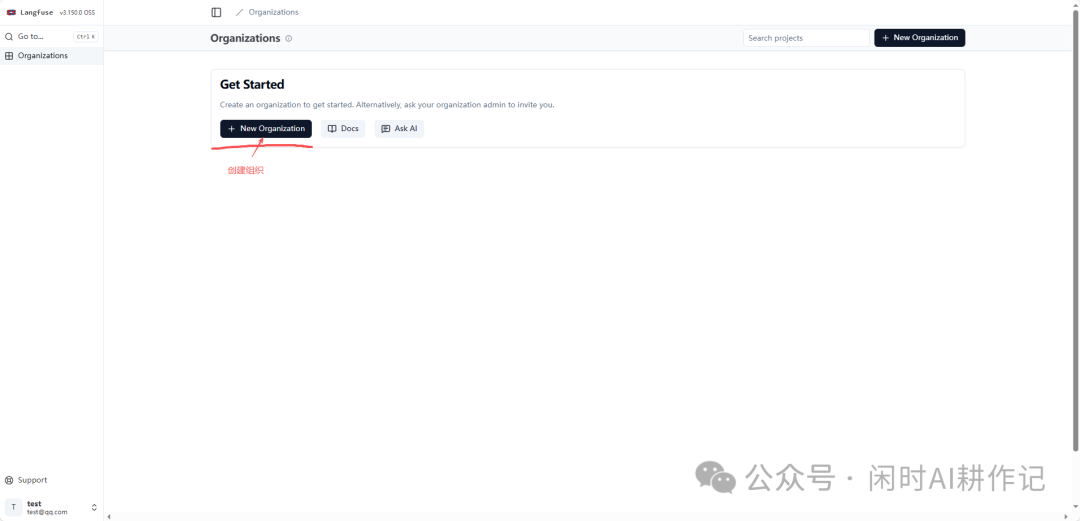
在创建组织页面,填写组织名称后点击 “Create” 按钮。
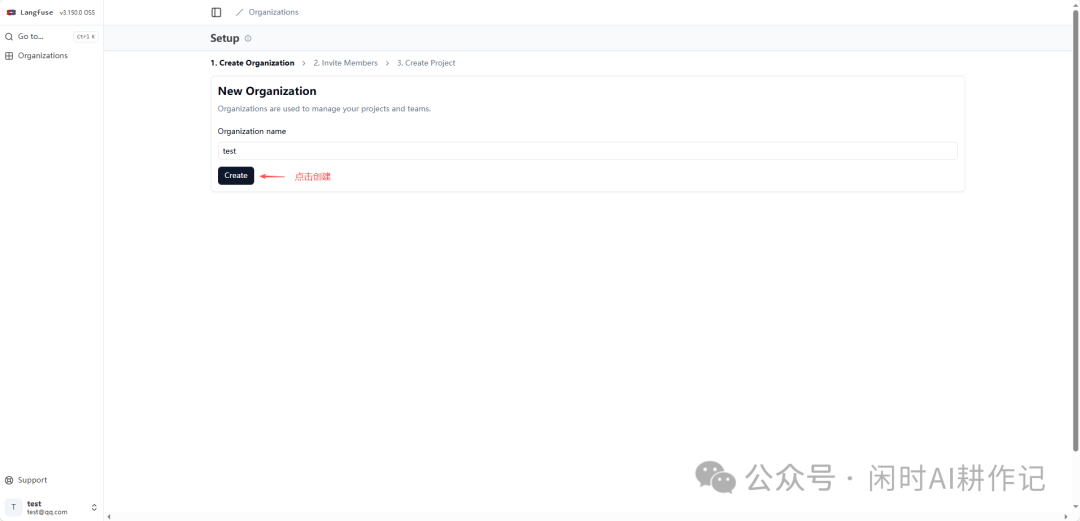
组织创建完成后,可以跳过 “Invite Members” 步骤,直接点击 “Next” 按钮进入第三步 “Create Project”。
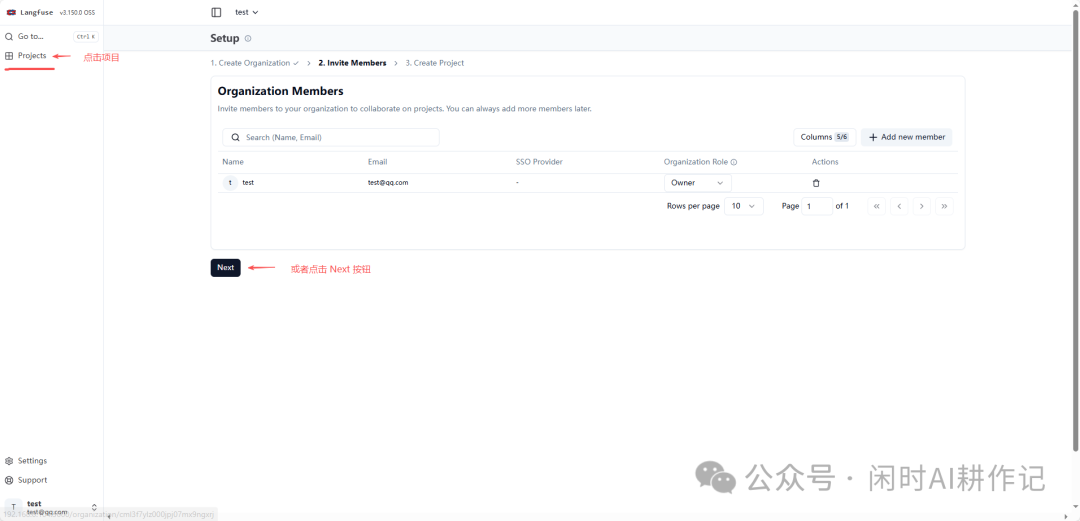
在创建项目页面,输入你的项目名称,然后点击 “Create” 按钮。项目是用于分组追踪记录、数据集等的基本单元。
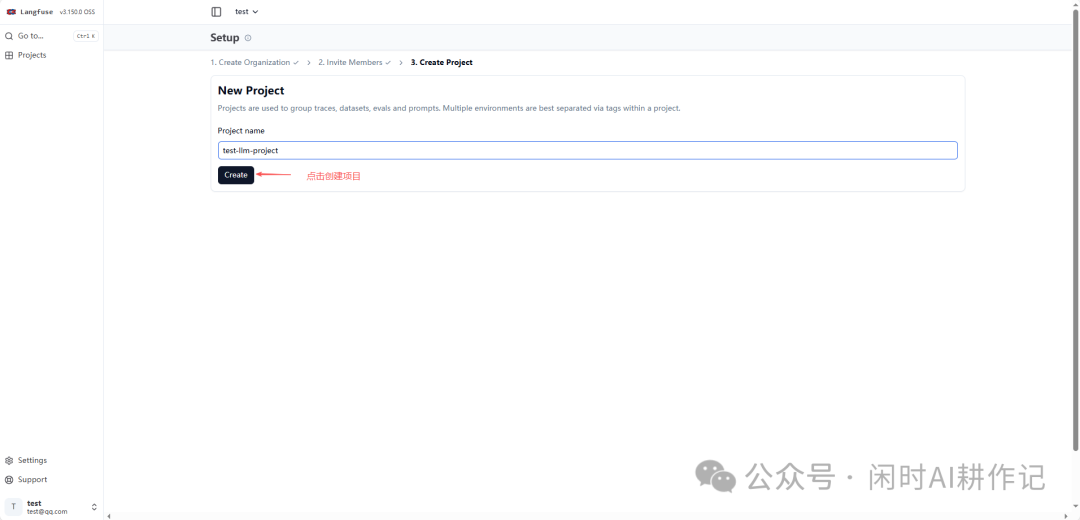
项目创建成功后,进入项目主页。点击左侧导航栏的 “Tracing”,页面会引导你进行追踪配置。点击 “Configure Tracing”。
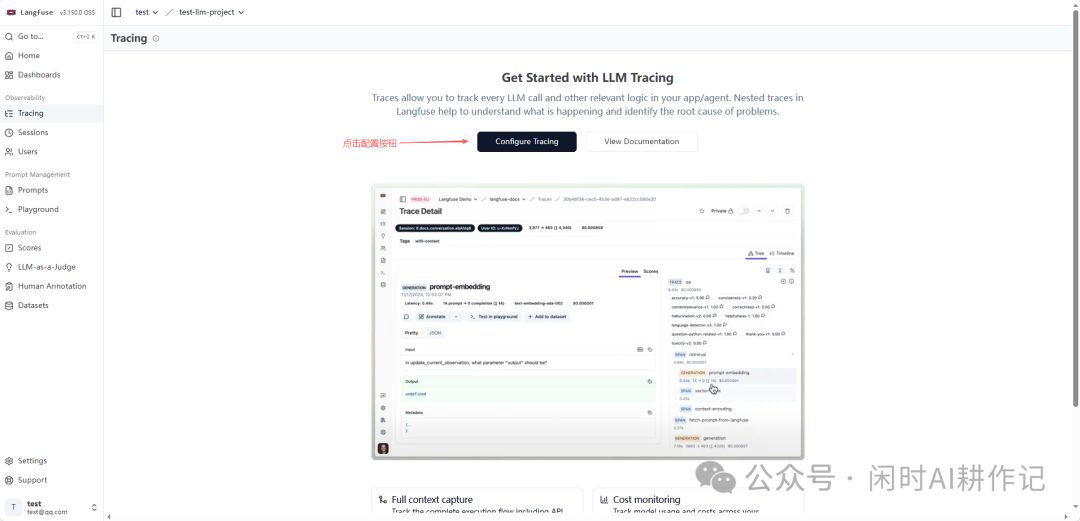
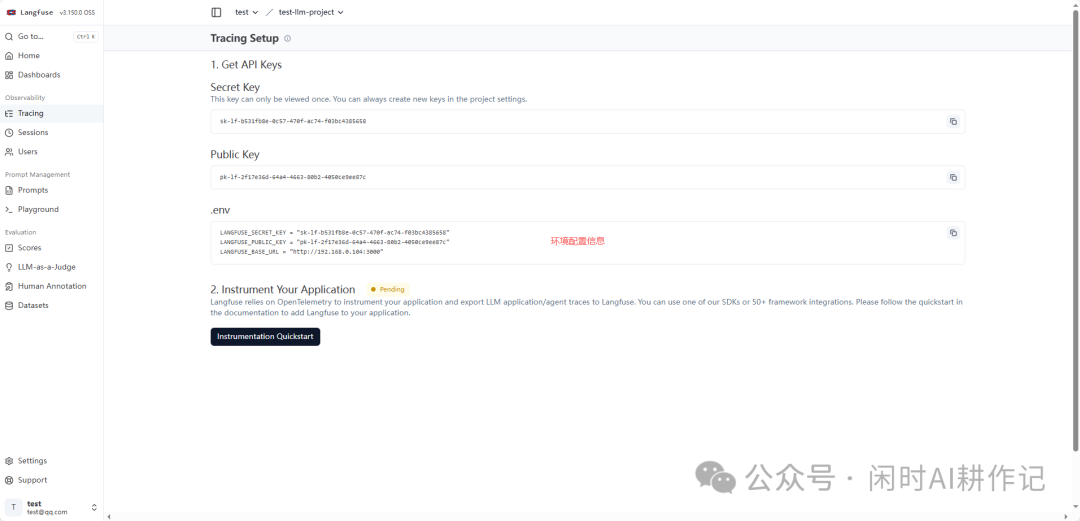
在追踪设置页面,第一步是获取API密钥。点击 “Create new API key” 按钮。
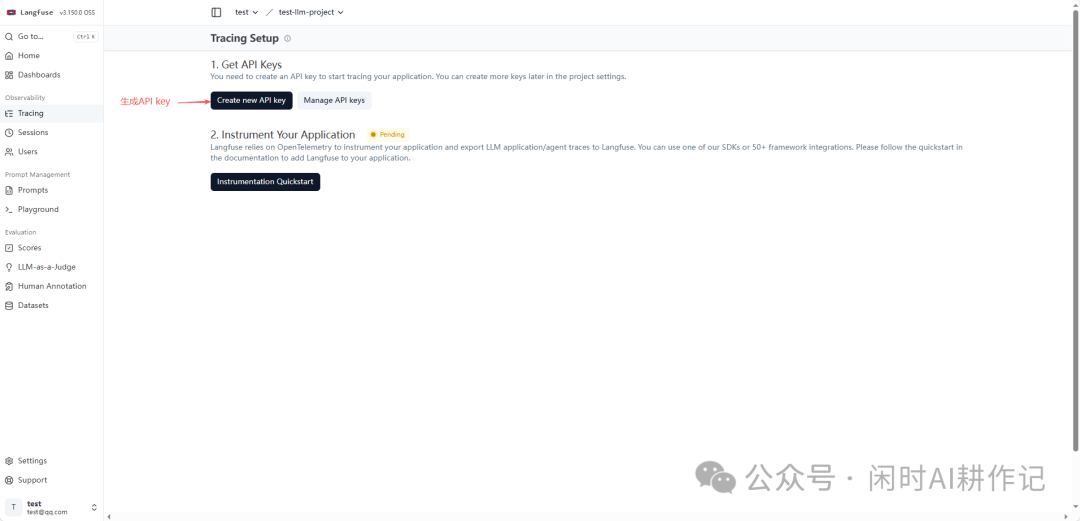
创建成功后,页面会显示你的 Secret Key 和 Public Key,请务必妥善保存。同时,页面也会给出将其配置到环境变量(.env文件)中的示例。
LangChain 集成 Langfuse
安装依赖
在你的 Python 环境中安装 langfuse 包。
pip install langfuse
配置环境变量
创建一个 .env 文件,将上一步在 WebUI 中生成的配置信息复制进去,例如:
LANGFUSE_SECRET_KEY="sk-1F-9532Fbde-dC57-478F-ac74-F6B0c4385658"
LANGFUSE_PUBLIC_KEY="pk-1F-2f17636d-64a4-46e3-3802-4050c406ee7c"
LANGFUSE_BASE_URL="http://127.0.0.1:3000"
基本使用:追踪LLM调用
集成 Langfuse 到 LangChain 应用中的核心是使用 CallbackHandler。步骤如下:
- 导入包:
from langfuse.langchain import CallbackHandler
- 创建回调处理器对象:
langfuse_handler = CallbackHandler()
- 将该处理器加入到
RunnableConfig 的 callbacks 属性中
- 在调用 LLM 时传入该 config
下面是一个完整的示例代码,使用了智谱AI的GLM模型:
from langchain_core.runnables import RunnableConfig
from langchain_openai import ChatOpenAI
from langfuse.langchain import CallbackHandler
from utils.env_util import ZAI_API_KEY, ZAI_BASE_URL
langfuse_handler = CallbackHandler()
model = ChatOpenAI(
temperature=0.8,
model="glm-4.7-flash",
api_key=ZAI_API_KEY,
base_url=ZAI_BASE_URL,
max_tokens=2048,
stream_usage=True,
streaming=True
)
config = RunnableConfig(
configurable={
"thread_id": "12345t"
},
callbacks=[langfuse_handler]
)
result = model.invoke("你是谁?", config=config)
print(result)
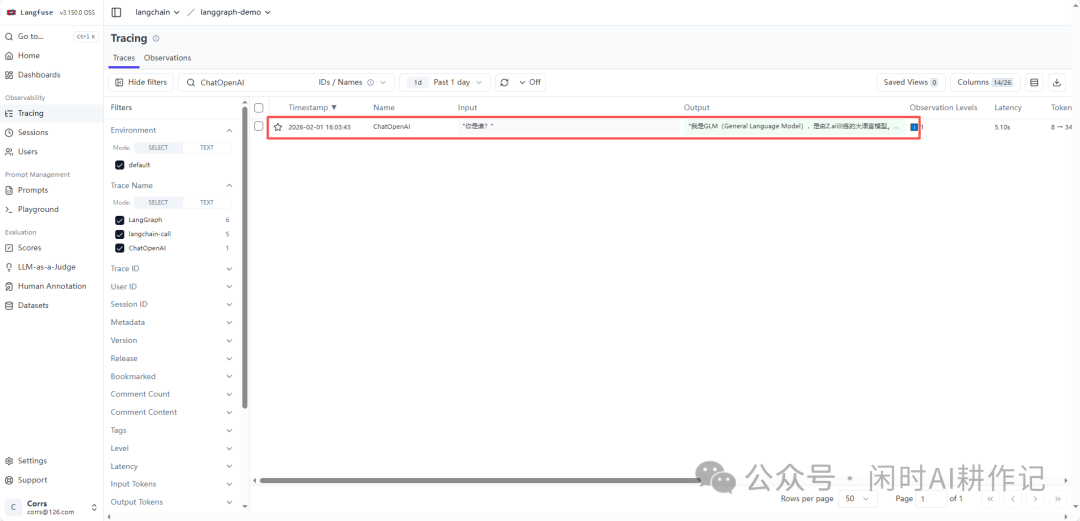
运行这段代码后,回到 Langfuse 的 Tracing 页面,你就能看到这次 LLM 调用的详细追踪记录,包括输入、输出、延迟、使用的Token数等。
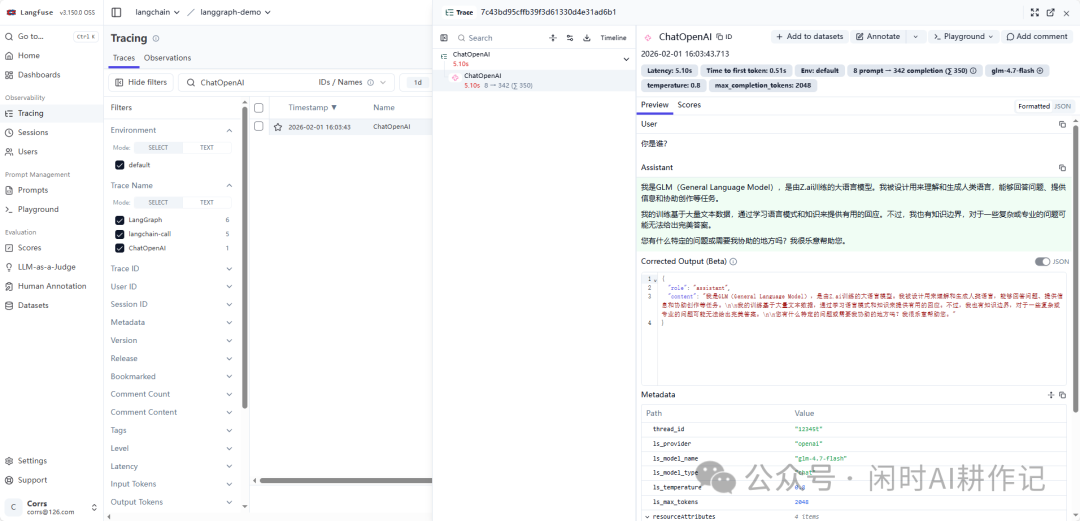
点击单条记录,可以查看更详尽的调试信息,例如模型参数、元数据等。
进阶使用:按用户和会话追踪
对于更复杂的应用,你可能需要按用户(User)或会话(Session)来聚合和查看追踪数据。Langfuse 提供了相应的 API 来实现这一点。
from langchain_core.runnables import RunnableConfig
from langchain_openai import ChatOpenAI
from langfuse.langchain import CallbackHandler
from langfuse import get_client, propagate_attributes
from utils.env_util import ZAI_API_KEY, ZAI_BASE_URL
# 创建Langfuse客户端对象
langfuse = get_client()
langfuse_handler = CallbackHandler()
model = ChatOpenAI(
temperature=0.8,
model="glm-4.7-flash",
api_key=ZAI_API_KEY,
base_url=ZAI_BASE_URL,
max_tokens=2048,
stream_usage=True,
streaming=True
)
config = RunnableConfig(
configurable={
"thread_id": "12345t"
},
callbacks=[langfuse_handler]
)
# 定义 session_id 和 user_id
session_id = "s:11111"
user_id = "u:11111"
with langfuse.start_as_current_observation(as_type="span", name="chat-agent"):
with propagate_attributes(session_id=session_id, user_id=user_id):
result = model.invoke("你是谁?", config=config)
print(result)
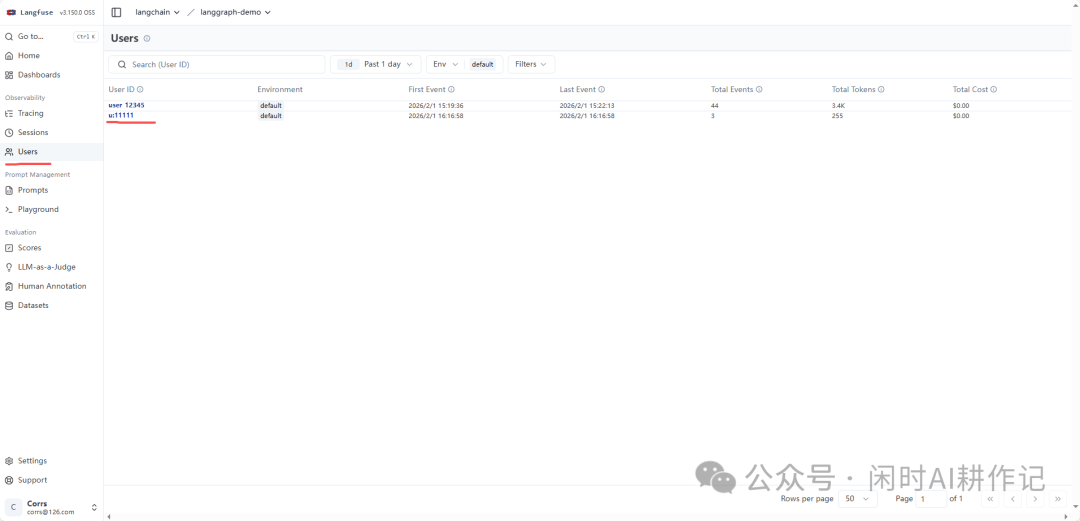
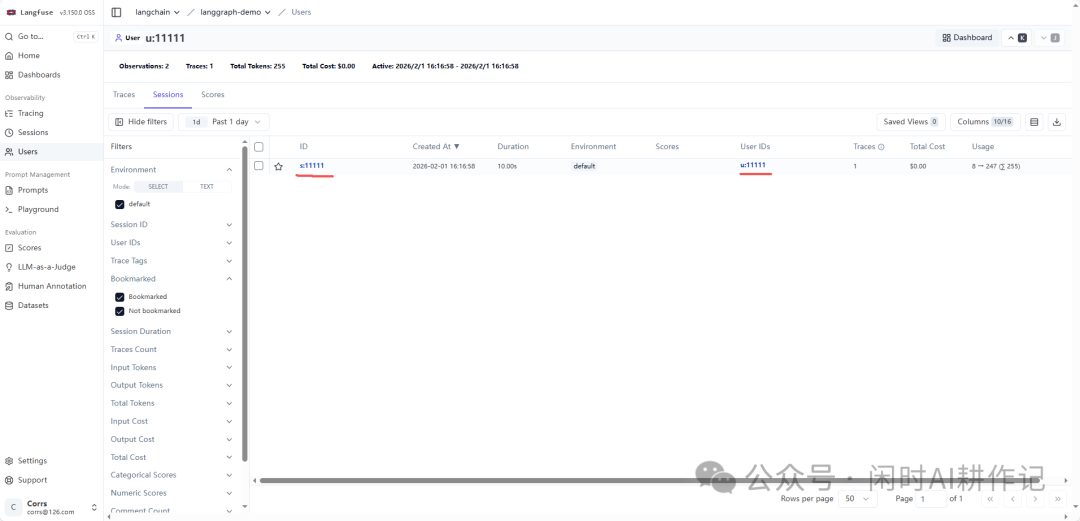
通过这种方式,你可以在 Langfuse 的 “Users” 页面,通过指定的 user_id 查看到该用户的所有相关调用记录、总成本、总Token消耗等聚合信息,这对于分析用户行为和应用 RAG 系统的性能至关重要。
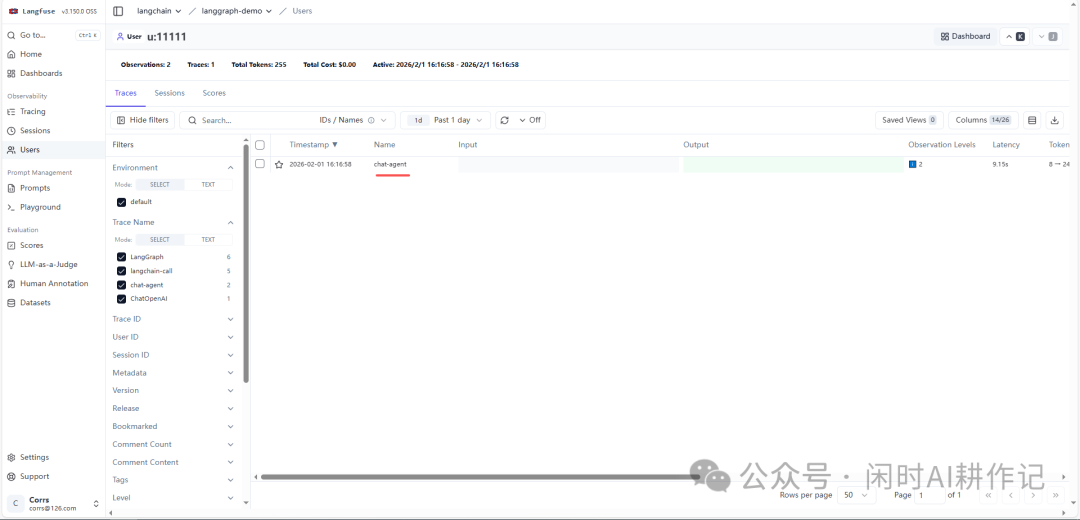
你还可以进入用户的仪表盘,获得更直观的数据概览。
总结
通过以上步骤,我们成功在本地部署了 Langfuse,并将其与 LangChain 应用集成。现在,你可以清晰地 监控 每一次LLM调用的细节,从延迟、成本到具体的输入输出。这对于调试复杂的Agent工作流、优化提示词、控制预算具有巨大的价值。希望这篇指南能帮助你在开发LLM应用时,更好地利用可观测性工具提升开发效率和应用质量。如果你想与更多开发者交流此类技术的实践心得,欢迎访问 云栈社区 参与讨论。
 发表于 2026-2-2 05:39:29
|
查看: 272|
回复: 0
发表于 2026-2-2 05:39:29
|
查看: 272|
回复: 0
