API设计是B端产品的技术基石。一套设计优良的API,不仅能大幅提升内部开发与对接效率,更能为企业客户提供稳定、强大的集成能力,成为产品竞争力的重要组成部分。
本文是上篇,将深入探讨前4个关键的最佳实践:RESTful规范、接口鉴权、分页排序筛选以及错误码体系。每个实践都包含设计规范、代码示例与避坑指南,旨在提供一份可直接落地的实战参考。
8个最佳实践全景图
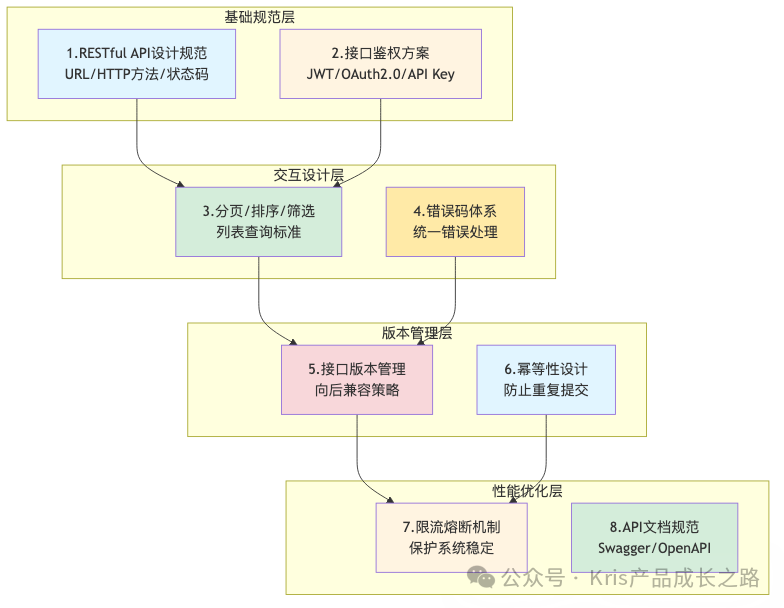
| 实践 |
重要性 |
复杂度 |
必要性 |
PM参与度 |
| RESTful规范 |
⭐⭐⭐⭐⭐ |
⭐⭐ |
必须 |
高(定义接口) |
| 接口鉴权 |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
必须 |
中(理解原理) |
| 分页排序筛选 |
⭐⭐⭐⭐⭐ |
⭐⭐ |
必须 |
高(定义规则) |
| 错误码体系 |
⭐⭐⭐⭐⭐ |
⭐⭐⭐ |
必须 |
高(定义错误) |
| 版本管理 |
⭐⭐⭐⭐ |
⭐⭐⭐ |
重要 |
中(理解策略) |
| 幂等性设计 |
⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
重要 |
中(理解原理) |
| 限流熔断 |
⭐⭐⭐ |
⭐⭐⭐⭐ |
可选 |
低(技术实现) |
| API文档 |
⭐⭐⭐⭐⭐ |
⭐⭐ |
必须 |
高(Review文档) |
实践1:RESTful API设计规范 - 接口设计的语法
📌 是什么与作用
RESTful是一种广泛采用的API架构风格,其核心在于通过统一的URL设计和标准的HTTP方法(GET、POST等)来表达操作,使API变得直观、易于理解与维护。
核心价值:
- 统一规范:团队遵循同一套设计语言。
- 语义清晰:URL本身具有描述性,降低了理解成本。
- 易于维护:标准化的结构降低了长期维护的复杂度。
- 行业标准:符合主流技术实践,便于第三方集成。
| RESTful vs 非RESTful |
维度 |
RESTful风格 |
非RESTful风格 |
| URL设计 |
/api/v1/users/123 |
/api/getUserById?id=123 |
| 操作方式 |
HTTP方法(GET/POST/PUT/DELETE) |
全部用POST |
| 资源表示 |
名词复数 |
动词+名词 |
| 状态码 |
200/404/500等标准状态码 |
全部返回200 |
🔧 RESTful设计的6大原则
原则1:URL使用名词复数,表示资源
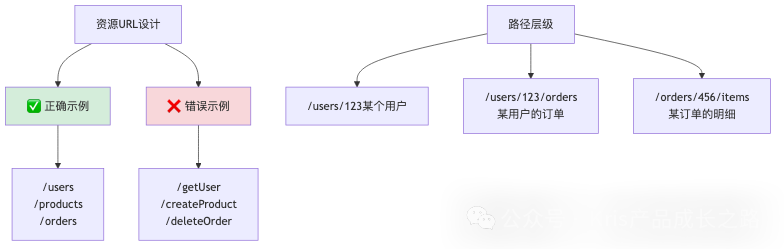
| 资源 |
URL |
说明 |
| 用户列表 |
GET /api/v1/users |
获取所有用户 |
| 单个用户 |
GET /api/v1/users/123 |
获取ID为123的用户 |
| 用户的订单 |
GET /api/v1/users/123/orders |
获取用户123的所有订单 |
| 规范 |
说明 |
正确示例 |
错误示例 |
| 小写字母 |
避免大小写混淆 |
/users |
/Users |
| 复数名词 |
资源用复数 |
/products |
/product |
| 连字符 |
多单词用-连接 |
/order-items |
/orderItems |
| 避免动词 |
URL表示资源,不是操作 |
/users(配合POST) |
/createUser |
| 层级清晰 |
避免过深,通常不超过3层 |
/users/123/orders |
/api/v1/company/dept/team/user/orders |
原则2:用HTTP方法表示操作
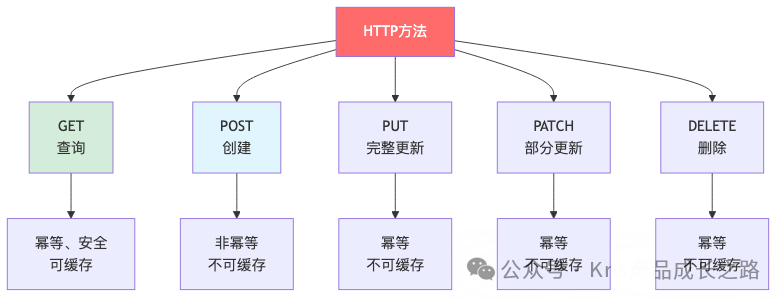
| 操作 |
HTTP方法 |
URL |
请求体 |
响应 |
| 查询用户列表 |
GET |
/api/v1/users |
无 |
用户列表 |
| 查询单个用户 |
GET |
/api/v1/users/123 |
无 |
用户详情 |
| 创建用户 |
POST |
/api/v1/users |
用户信息 |
创建的用户 |
| 完整更新用户 |
PUT |
/api/v1/users/123 |
完整用户信息 |
更新后的用户 |
| 部分更新用户 |
PATCH |
/api/v1/users/123 |
部分字段 |
更新后的用户 |
| 删除用户 |
DELETE |
/api/v1/users/123 |
无 |
删除结果 |
完整接口示例
# 1. 查询用户列表
GET /api/v1/users?page=1&page_size=20&status=active
Response: 200 OK
{
"code": 0,
"message": "success",
"data": {
"total": 156,
"list": [...]
}
}
# 2. 创建用户
POST /api/v1/users
Content-Type: application/json
{
"username": "zhangsan",
"email": "zhangsan@example.com",
"role": "admin"
}
Response: 201 Created
{
"code": 0,
"message": "用户创建成功",
"data": {
"user_id": "123",
"username": "zhangsan",
"created_at": "2024-11-01T10:30:00Z"
}
}
# 3. 更新用户(完整)
PUT /api/v1/users/123
Content-Type: application/json
{
"username": "zhangsan",
"email": "zhangsan@example.com",
"role": "user",
"status": "active"
}
# 4. 更新用户(部分)
PATCH /api/v1/users/123
Content-Type: application/json
{
"status": "inactive"
}
# 5. 删除用户
DELETE /api/v1/users/123
Response: 200 OK
{
"code": 0,
"message": "用户删除成功"
}
原则3:使用标准HTTP状态码
合理地使用HTTP状态码是良好API设计的重要标志,它能清晰地向调用方传达请求结果的性质。关于HTTP协议的深入理解有助于设计出更规范的API。
| 常用状态码 |
状态码 |
含义 |
使用场景 |
示例 |
| 2xx 成功 |
|
|
|
| 200 |
OK |
请求成功 |
查询、更新、删除成功 |
| 201 |
Created |
创建成功 |
创建用户成功 |
| 204 |
No Content |
成功但无返回内容 |
删除成功 |
| 4xx 客户端错误 |
|
|
|
| 400 |
Bad Request |
请求参数错误 |
缺少必填字段 |
| 401 |
Unauthorized |
未认证 |
Token过期/无效 |
| 403 |
Forbidden |
无权限 |
没有访问权限 |
| 404 |
Not Found |
资源不存在 |
用户ID不存在 |
| 409 |
Conflict |
资源冲突 |
用户名已存在 |
| 429 |
Too Many Requests |
请求过多 |
超过限流阈值 |
| 5xx 服务器错误 |
|
|
|
| 500 |
Internal Server Error |
服务器错误 |
代码异常 |
| 503 |
Service Unavailable |
服务不可用 |
服务器维护 |
状态码使用示例
# 成功场景
GET /api/v1/users/123
Response: 200 OK
POST /api/v1/users
Response: 201 Created
# 客户端错误
GET /api/v1/users/999999
Response: 404 Not Found
{
"code": 40001,
"message": "用户不存在",
"data": null
}
POST /api/v1/users
{
"email": "invalid-email"
}
Response: 400 Bad Request
{
"code": 40002,
"message": "邮箱格式错误",
"errors": {
"email": "邮箱格式不正确"
}
}
# 服务器错误
GET /api/v1/users
Response: 500 Internal Server Error
{
"code": 50001,
"message": "服务器内部错误",
"trace_id": "abc123xyz"
}
原则4:统一的响应格式
统一的响应结构能极大简化客户端对响应的处理逻辑。
标准响应结构
{
"code": 0, // 业务状态码(0表示成功)
"message": "success", // 提示信息
"data": {}, // 业务数据
"trace_id": "abc123", // 追踪ID(可选)
"timestamp": 1698825600 // 时间戳(可选)
}
不同场景的响应示例
- 成功响应(单条数据)
{
"code": 0,
"message": "查询成功",
"data": {
"user_id": "123",
"username": "zhangsan",
"email": "zhangsan@example.com",
"role": "admin",
"status": "active",
"created_at": "2024-01-01T00:00:00Z"
}
}
- 成功响应(列表数据)
{
"code": 0,
"message": "查询成功",
"data": {
"total": 156, // 总数
"page": 1, // 当前页
"page_size": 20, // 每页数量
"total_pages": 63, // 总页数
"has_next": true, // 是否有下一页
"has_prev": true, // 是否有上一页
"list": [ // 数据列表
{
"user_id": "123",
"username": "zhangsan"
}
]
}
}
- 错误响应
{
"code": 40002,
"message": "参数校验失败",
"data": null,
"errors": { // 详细错误信息
"email": "邮箱格式不正确",
"phone": "手机号不能为空"
},
"trace_id": "abc123xyz"
}
原则5:合理的URL层级
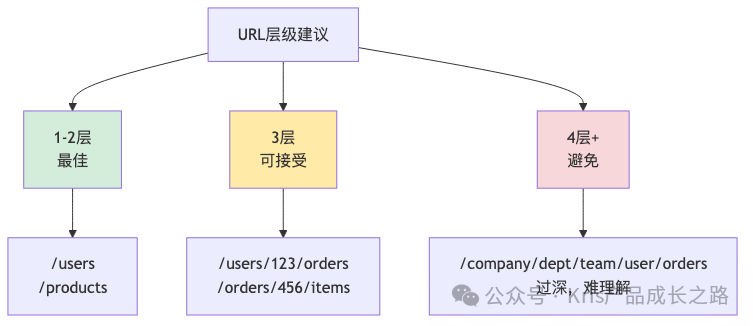
对于复杂查询,应优先使用查询参数而非过度嵌套的URL路径。
| 场景 |
❌ 错误设计 |
✅ 正确设计 |
| 查询用户的订单 |
/getUserOrders?userId=123 |
/users/123/orders |
| 查询订单的商品 |
/getOrderItems?orderId=456 |
/orders/456/items |
| 复杂查询 |
/orders/user/123/product/789 |
/orders?user_id=123&product_id=789 |
💡 实战案例:电商API设计
商品管理API
# 基础CRUD
GET /api/v1/products # 商品列表
GET /api/v1/products/123 # 商品详情
POST /api/v1/products # 创建商品
PUT /api/v1/products/123 # 更新商品(完整)
PATCH /api/v1/products/123 # 更新商品(部分)
DELETE /api/v1/products/123 # 删除商品
# 关联资源
GET /api/v1/products/123/reviews # 商品评价
GET /api/v1/products/123/inventory # 商品库存
GET /api/v1/categories/5/products # 分类下的商品
# 特殊操作
GET /api/v1/products/search?q=iPhone # 搜索
POST /api/v1/products/batch # 批量操作
GET /api/v1/products/export?format=excel # 导出
订单管理API
# 基础CRUD
GET /api/v1/orders # 订单列表
GET /api/v1/orders/456 # 订单详情
POST /api/v1/orders # 创建订单
PUT /api/v1/orders/456 # 更新订单
# 订单子资源
GET /api/v1/orders/456/items # 订单商品
GET /api/v1/orders/456/logistics # 物流信息
# 订单操作
POST /api/v1/orders/456/pay # 支付订单
POST /api/v1/orders/456/ship # 订单发货
POST /api/v1/orders/456/cancel # 取消订单
POST /api/v1/orders/456/refund # 申请退款
⚠️ RESTful设计的常见坑点
坑点1:滥用POST

| 坑点2:URL包含动词 |
❌ 错误 |
✅ 正确 |
说明 |
POST /api/createUser |
POST /api/users |
创建操作用HTTP方法表示 |
GET /api/getUserList |
GET /api/users |
URL只表示资源 |
坑点3:返回格式不统一
// ❌ 错误:不同接口返回格式不一致
// 接口1
{ "success": true, "result": {...} }
// 接口2
{ "code": 0, "data": {...} }
// ✅ 正确:统一格式
{ "code": 0, "message": "success", "data": {...} }
| 坑点4:状态码滥用 |
场景 |
❌ 错误 |
✅ 正确 |
| 业务错误 |
HTTP 200 + code: 1001 |
HTTP 400 + code: 1001 |
| 资源不存在 |
HTTP 200 + “未找到” |
HTTP 404 |
| 服务器错误 |
HTTP 200 + “系统错误” |
HTTP 500 |
正确做法:
- HTTP状态码表示HTTP协议层面的请求状态(成功、失败、重定向等)。
code字段表示业务逻辑层面的状态(参数错误、库存不足等)。- 两者应配合使用,共同清晰地传达结果。
实践2:接口鉴权方案 - 守护API安全的防线
📌 是什么与作用
接口鉴权用于确保只有经过认证和授权的客户端才能访问相应的API资源,是保障系统安全的第一道,也是最重要的一道屏障。
核心价值:
- 身份认证:确认“你是谁”。
- 权限授权:确认“你能做什么”。
- 行为追踪:关联操作与具体用户,便于审计。
- 防护攻击:防止未授权访问和恶意调用。
🔧 三种主流鉴权方案

方案1:API Key(最简单)
工作原理
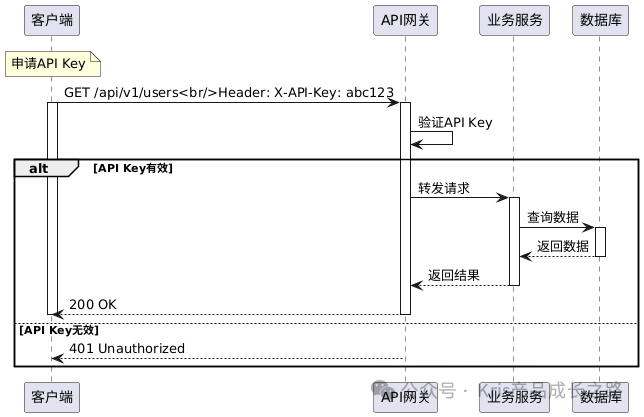
API Key使用示例
# 方式1:放在Header(推荐)
GET /api/v1/users
X-API-Key: sk_live_51H3j2KLxPyQ9m8vN...
# 方式2:放在Query参数(不推荐,会记录在日志)
GET /api/v1/users?api_key=sk_live_51H3j2KLxPyQ9m8vN...
优缺点
- 优点:实现简单,性能好,适合机器对机器的服务间调用。
- 缺点:无法区分具体用户,密钥泄露后危害大,不适合多用户系统。
方案2:JWT Token(最常用)
JWT结构
JWT(JSON Web Token)是一种开放标准,由Header、Payload、Signature三部分组成。
Header.Payload.Signature
- Header:声明令牌类型和签名算法。
- Payload:存放实际传递的数据(如用户ID、角色),但注意不要存放敏感信息。
- Signature:对前两部分的签名,防止数据篡改。
JWT认证流程
JWT使用示例
# 登录获取Token
POST /api/v1/auth/login
{
"username": "zhangsan",
"password": "123456"
}
Response:
{
"code": 0,
"data": {
"access_token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...",
"refresh_token": "eyJhbGc...",
"expires_in": 7200
}
}
# 使用Token访问API
GET /api/v1/users/123
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...
JWT优缺点
- 优点:无状态,服务端无需存储会话;Payload可包含用户信息,减少查询;天然支持分布式系统。
- 缺点:Token一旦签发,在过期前无法主动失效(需配合Token黑名单);Token长度较长;Payload内容可被解码,不能存敏感信息。其核心机制与常见的安全身份验证协议有共通之处。
方案3:OAuth 2.0(第三方授权)
OAuth 2.0授权流程(授权码模式)
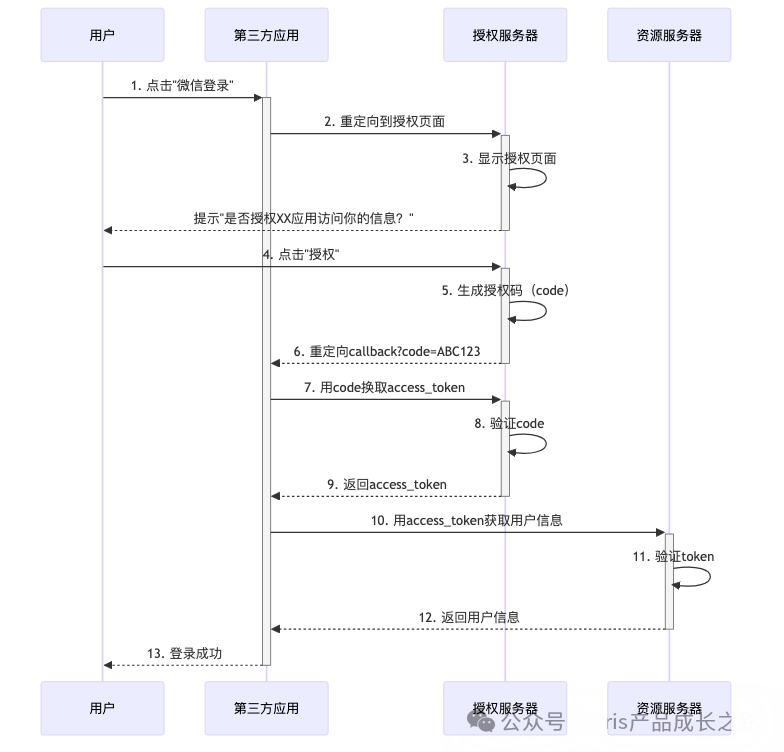
应用场景
- 第三方登录:用户使用微信、GitHub等账号登录你的应用。
- 开放平台:企业将API开放给第三方开发者调用。
- 微服务间认证:服务A调用服务B,使用Client Credentials模式。
💡 实战案例:多层次鉴权设计
鉴权层级
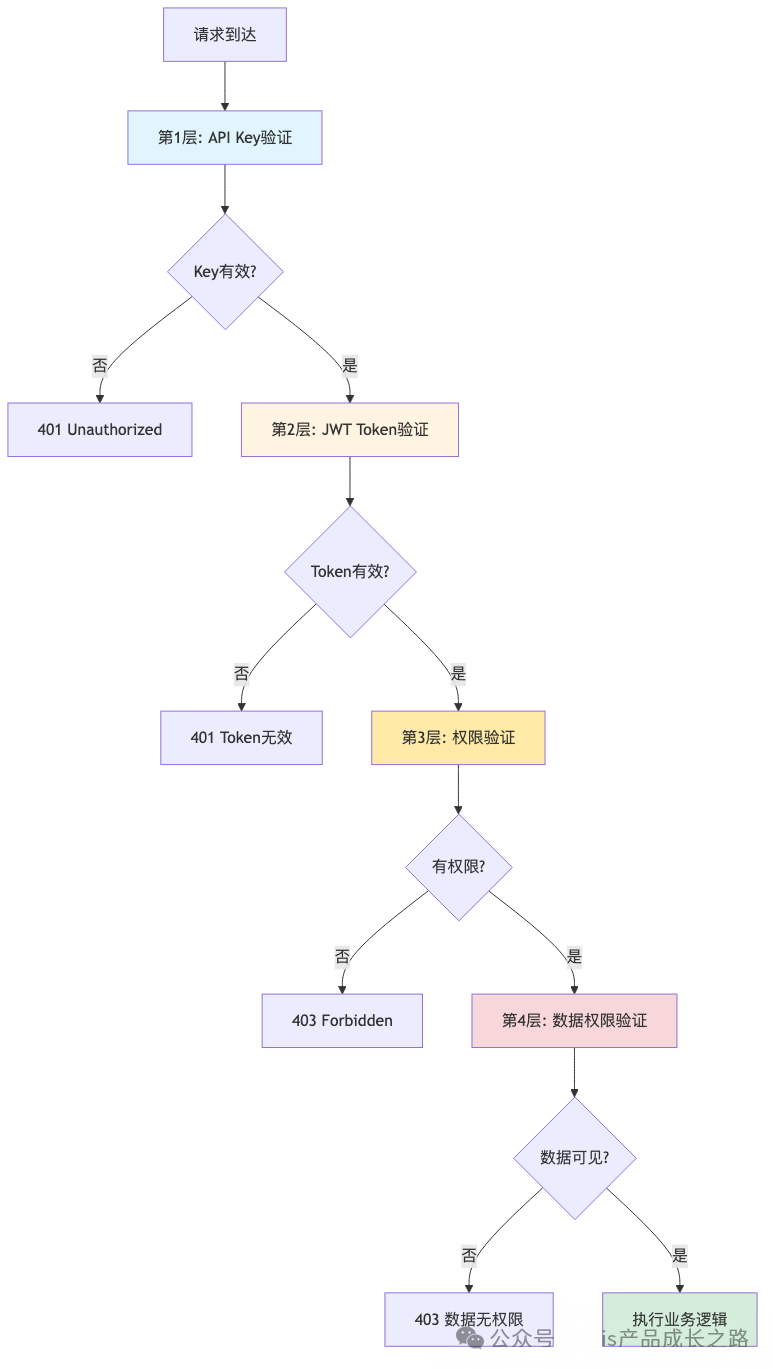
实际应用中,鉴权规则可通过配置中心动态管理。
实践3:分页、排序、筛选 - 列表查询的标准
📌 是什么与作用
列表查询是B端产品最高频的操作之一。统一、规范的分页、排序、筛选设计,能显著提升前后端开发效率和接口性能。
核心价值:
- 性能优化:避免单次查询拉取海量数据导致数据库和网络压力。
- 精准筛选:帮助用户快速定位目标数据。
- 灵活排序:按业务需求多维度展示数据。
- 统一规范:所有列表接口遵循同一套规则,降低对接成本。
🔧 分页设计方案
| 方案对比 |
方案 |
参数 |
优点 |
缺点 |
适用场景 |
| 基于页码 |
page, page_size |
简单直观,支持跳页 |
深分页性能差 |
数据量<10万,需跳页 |
| 基于游标 |
cursor, limit |
性能好,数据一致性强 |
不支持跳页 |
数据量大,无限滚动 |
基于页码分页(最常用)
# 请求
GET /api/v1/orders?page=2&page_size=20&sort=-created_at&status=paid
// 响应
{
"code": 0,
"data": {
"total": 1256,
"page": 2,
"page_size": 20,
"total_pages": 63,
"has_next": true,
"has_prev": true,
"list": [...]
}
}
基于游标分页(高性能)
游标(Cursor)通常是对“上一页最后一条记录”的某个唯一且有序的字段(如ID、创建时间)进行编码。
# 首次请求
GET /api/v1/orders?limit=20
Response: { "list": [...], "next_cursor": "encoded_string", "has_more": true }
# 后续请求
GET /api/v1/orders?cursor=encoded_string&limit=20
🔧 排序设计规范
排序参数格式
- 单字段:
?sort=created_at (默认升序),?sort=-created_at (降序)。
- 多字段:
?sort=-created_at,+amount (先按创建时间降序,再按金额升序)。
实现注意
后端必须对排序字段进行白名单校验,防止通过排序参数进行SQL注入攻击。
🔧 筛选设计规范
筛选参数设计

筛选参数示例
# 基础与范围筛选
GET /api/v1/orders?status=paid&min_amount=100&max_amount=500
# 时间范围
GET /api/v1/orders?start_date=2024-11-01&end_date=2024-11-30
# 多选(逗号分隔)
GET /api/v1/products?category_id=1,2,3&status=on_sale,pre_sale
对于极其复杂的筛选条件,可以考虑使用类JSON的filter参数或直接使用POST请求提交查询体,以避免URL过长和参数解析复杂度过高的问题。
💡 实战案例:订单列表API设计
完整的请求示例
GET /api/v1/orders?
page=1&
page_size=20&
sort=-created_at&
status=paid,shipped&
min_amount=100&
max_amount=1000&
start_date=2024-11-01&
end_date=2024-11-30&
keyword=iPhone
⚠️ 分页排序筛选的常见坑点
坑点1:深分页性能问题
使用LIMIT 20 OFFSET 100000查询第5001页时,数据库需要先扫描过滤前10万条记录,性能极差。
- 优化1:使用基于游标(Cursor)的分页。
- 优化2:业务上限制最大查询页码(如500页)。
坑点2:筛选参数SQL注入
绝对禁止将用户输入的筛选条件直接拼接到SQL语句中。
- 错误:
String sql = "SELECT * FROM products WHERE name LIKE '%" + keyword + "%'";
- 正确:使用参数化查询或ORM框架的安全查询方法。在设计数据层时,可以参考成熟的数据库操作最佳实践来规避此类风险。
坑点3:未限制返回数量
必须对page_size参数设置最大值(如100),防止一次请求拖垮数据库。
坑点4:时间范围未限制
对于可查询的时间范围(如订单历史),应在业务层或接口层做限制(如最多查询90天内数据),防止全表扫描。
实践4:错误码体系设计 - 清晰的错误提示
📌 是什么与作用
一套清晰、统一的错误码体系,能让错误信息变得标准化、可追溯、易排查,极大提升开发调试效率和用户体验。
核心价值:
- 快速定位:通过错误码即可快速定位问题模块与类型。
- 错误统计:便于监控系统收集和分析错误分布,驱动产品优化。
- 国际化:错误码可映射到不同语言的错误描述,支持多语言。
- 对接友好:为第三方集成提供明确的错误含义和处理指引。
🔧 错误码设计规范
错误码结构(推荐5位数字)
格式:XXYYZ
XX:模块编码(10-99),如40代表通用参数模块。YY:错误类型(00-99),如01代表“不存在”类错误。Z:具体错误序号(0-9)。
示例:40401 = 模块40(通用) + 类型04(不存在) + 序号1 = “资源不存在”。
错误码分层示例
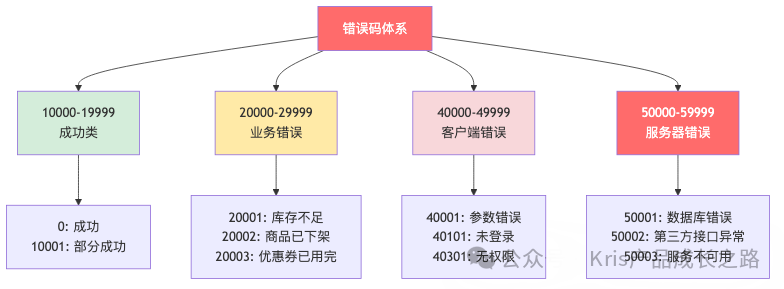
| 错误码范围 |
模块说明 |
示例 |
0 |
成功 |
0 |
40000-40099 |
通用参数错误 |
40001 参数缺失 |
40100-40199 |
认证错误 |
40101 Token无效 |
40300-40399 |
权限错误 |
40301 无访问权限 |
40400-40499 |
资源错误 |
40401 用户不存在 |
42900-42999 |
限流错误 |
42901 请求过于频繁 |
50000-59999 |
服务器错误 |
50001 系统内部错误 |
💡 错误响应设计
标准错误响应格式
{
"code": 40001,
"message": "请求参数错误",
"data": null,
"errors": {
"email": "邮箱格式不正确"
},
"trace_id": "abc123xyz",
"timestamp": 1698825600
}
不同场景的错误响应
- 参数错误:应在
errors字段中提供详细的字段级错误信息。
- 业务错误:可在
data中附带相关上下文(如当前库存数)。
- 系统错误:面向用户的消息应友好(如“系统繁忙”),同时返回
trace_id供运维排查,切勿泄露服务器堆栈等敏感信息。
🎯 错误处理的最佳实践
- 错误信息国际化:根据请求头的
Accept-Language返回对应语言的message。
- 错误分类统计:建立错误看板,监控各错误码的发生频率,驱动系统优化。
- 维护错误码文档:为每个错误码提供清晰的描述、触发场景、用户操作建议和开发处理建议。
小结:上篇4个实践的核心要点
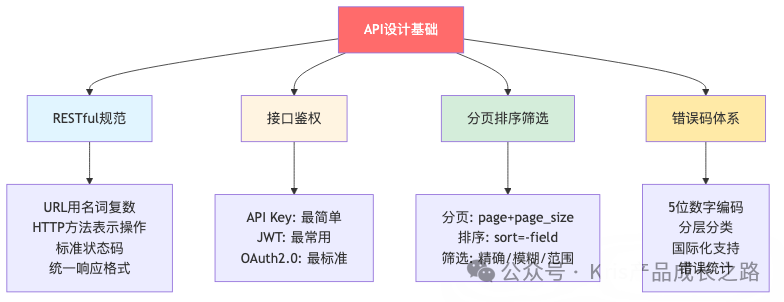
| 实践 |
解决的核心问题 |
产品经理的关注点 |
| RESTful规范 |
API的“语法”与结构如何设计 |
定义核心资源、规划URL层级 |
| 接口鉴权 |
如何确保API访问安全可控 |
选择鉴权方案、定义角色与数据权限规则 |
| 分页排序筛选 |
如何高效、灵活地查询列表数据 |
定义常用的筛选维度、排序方式和分页规则 |
| 错误码体系 |
如何统一、清晰地反馈错误 |
定义业务错误分类、编写用户友好的错误文案 |
下篇:
- 实践5:接口版本管理 - 向后兼容的艺术
- 实践6:幂等性设计 - 防止重复提交的关键
- 实践7:限流熔断机制 - 保障系统稳定的屏障
- 实践8:API文档规范 - Swagger/OpenAPI实战
接口版本、幂等性、限流熔断与文档规范 :https://yunpan.plus/t/1244-1-1
 发表于 2025-12-4 00:34:48
|
查看: 230|
回复: 0
发表于 2025-12-4 00:34:48
|
查看: 230|
回复: 0
