开源教条,正在悄无声息地毁掉你的云账单。
你安装了HPA和VPA,仅仅因为云原生教义告诉你必须这样做。你调了几个参数,然后便开始祈祷。最终,你却得到了:
- 副本数像溜溜球一样上下乱跳。
- 流量高峰完全错过。
- 多个autoscaler策略互相打架。
- 一张不断膨胀的云账单。
你的扩缩容一点都不智能,它只是在被动地制造混乱。
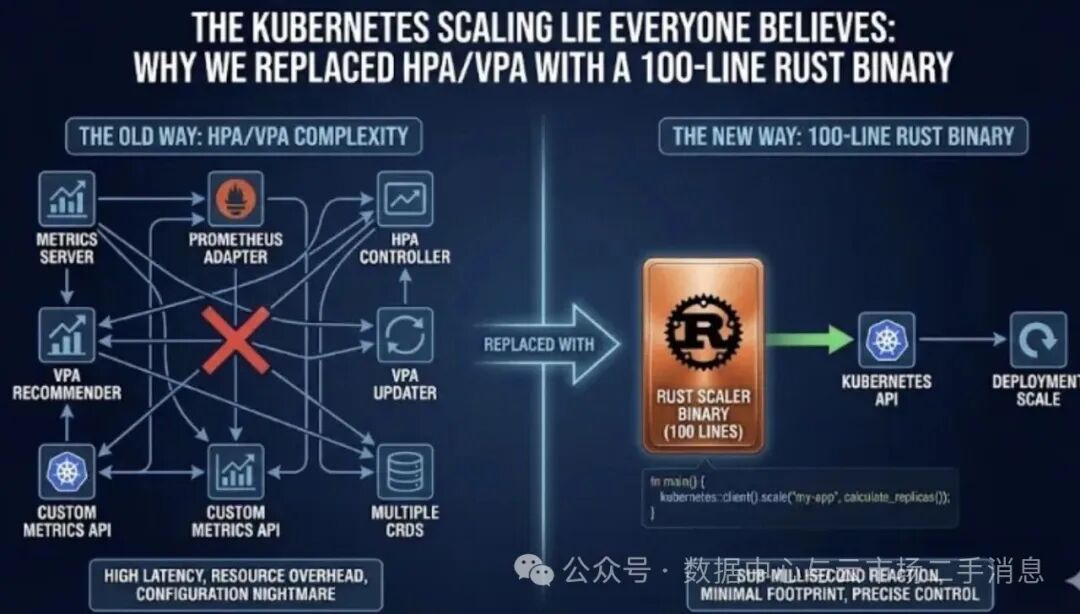
于是我们做了一件“离经叛道”的事:我们把它们全删了。没有HPA,没有VPA,也没有自定义指标适配器。我们用一个仅有100行的Rust二进制程序,运行在DaemonSet里,替换了那超过5000行Go代码构建的自动扩缩容“工业标准”方案。
结果如何?
- 第一周,基础设施成本直接下降了22%。
- p99延迟的剧烈抖动被压平成了一条直线。
- 流量高峰期,零扩缩容相关事故。
这就是Kubernetes在2026年也不会主动告诉你的真相。
为什么HPA和VPA从根上就是坏的(而且一直如此)
1. 它们只看过去
HPA反应的是过去30到60秒的CPU或内存使用率。等到它终于决定开始扩容时:
- 请求已经在队列中积压。
- 延迟已经飙升。
- 用户已经在抱怨。
反应式扩容只是在止血,而非预防。
2. 它们不会协同
典型的场景是:HPA先扩容,增加了Pod副本数。几分钟后,VPA又跳出来说:“其实,这些Pod需要更多内存。”
于是你得到了:
- 更多的Pod。
- 更大的Pod。
- 它们还运行在同一批节点上。
恭喜你,达成了全量过度配置的成就 🎉
3. 它们对成本一无所知
HPA完全不了解:
- Spot实例与On-Demand实例的巨大价差。
- 即将发生的Spot实例回收事件。
- 系统真正的瓶颈究竟是CPU、I/O、缓存还是数据库。
它只会一脸天真地,将你的应用扩展到最昂贵的资源上。
替代方案:一个极简的Rust扩缩容控制器
我们并非构建了“另一个autoscaler”。我们实现的是一个控制论意义上的反馈控制器。它的职责极其简单,只有三件:
- 读取多维信号。
- 根据规则做出单一决策。
- 调用Kubernetes API执行操作。
所有的智能,都来源于输入信号的质量,而非框架本身的复杂度。
HPA永远看不到的四个关键信号
1. 实时云定价
- 当前节点的实际成本。
- Spot实例与按需实例的实时价格与可用性。
- 基于历史数据的短期价格变化预测。
不考虑成本的扩缩容,无异于财务上的失职。
2. 核心业务指标
扩缩容的依据不应是CPU使用率,而应是:
- 每秒成功订单数。
- 关键交易链路(如Checkout)的延迟。
- 核心缓存的命中率。
我们根据真实的业务压力进行扩缩容,而不是那些间接的、滞后的资源替代指标。
3. 下游依赖健康状况
如果数据库的p95延迟正在持续上升:
- 继续扩容应用层只会加剧下游压力,雪上加霜。
- 而HPA恰恰就会这么干。
我们的Scaler具备熔断意识,会在下游出现压力时主动控制规模,保护整个系统。
4. 短期流量预测
我们集成了一个超轻量的内存时序预测模型(使用Rust的 salmon crate),可以预测未来5分钟内的流量趋势。
扩容动作发生在需求到来之前,而非事故警报之后。
核心算法(简单到残忍)
let decision = if forecasted_traffic > current_capacity * 0.7 {
ScaleDecision::ScaleOut
} else if node_price_spike_imminent() {
ScaleDecision::MoveToCheaperNode
} else if downstream_latency > threshold {
ScaleDecision::ScaleDown // 保护数据库
} else {
ScaleDecision::Hold
};
一次决策,一个原子操作。它可以同时考虑副本数、资源请求,并选择更具成本效益的节点容量。
没有决策抖动,没有组件拉扯,没有系统内耗。
部署:一个5分钟完成的DaemonSet
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: rust-scaler
spec:
template:
spec:
containers:
- name: scaler
image: ghcr.io/your-org/scaler:latest
args: ["--prometheus-url=http://prometheus:9090"]
env:
- name: AWS_REGION
value: us-east-1
它在每个节点上运行,为节点本地的Pod做出本地化的扩缩容决策。
没有中心化的“大脑”,也就没有单点故障。
让平台团队沉默的结果
黑色星期五实战
我们的Scaler在流量洪峰到来的前8分钟就启动了扩容流程,因为它已经学习并识别了每周的周期性流量模式。
结果:
成本感知的实例迁移
对于非关键的批处理任务,Scaler在Spot实例价格飙升的前12分钟,自动将其迁移至更稳定的按需实例集群,并在价格回落后再次迁回。
全程没有触发任何报警,也无需任何人工干预。
那个“悄无声息”的修复
它曾监测到一个老旧服务的RSS(常驻内存集)在缓慢且稳定地增长——这是一个典型的内存泄漏迹象。
没有发生:
- 凌晨3点的OOM(内存溢出)崩溃告警。
取而代之的是:
- 在随后的2小时内,Scaler逐步、平滑地提高了该服务Pod的内存
request限制。
我们是在一周后回顾日志时,才偶然发现了这个已被默默解决的问题。
2026年的真正真相
扩缩容不是一个纯粹的基础设施问题,而是一个紧密关联业务的逻辑问题。
通用的、一刀切的Autoscaler是为以下目标设计的:
- 平均的工作负载。
- 平均的公司规模。
- 技术栈的最低公分母。
而你的业务,并不“平均”。
一个你能完全理解、掌控的、小而精悍的二进制程序,其效能永远会超过一个你无法窥探其内部、庞大而笨重的通用黑盒。
把控制权拿回来
- 尝试引入业务核心指标(例如
cart_size)。
- 让你的自定义Scaler与现有的HPA并行运行一周。
- 对比两者的决策日志与实际系统状态。
你会立刻看清通用方案与定制化方案之间的差距。
云原生扩缩容的未来,不在于堆砌更多的Controller、CRD和YAML文件。而在于:用更丰富、更直接的业务数据,驱动一个极致简单的反馈循环。
有时,你技术栈中最智能、最可靠的工具,恰恰是那个由你亲手编写、完全契合自身业务脉搏的小程序。欢迎在云栈社区分享你的自定义运维工具实践与思考。
 发表于 2026-2-9 06:12:07
|
查看: 243|
回复: 0
发表于 2026-2-9 06:12:07
|
查看: 243|
回复: 0
