Anthropic 最近发布了一篇引人注目的博客,介绍了他们完全使用 Claude Opus 4.6 构建的一个 C 编译器,并称之为 CCC (Claude‘s C Compiler)。团队声称它能够编译 Linux 内核,整个过程仅由人类通过编写测试用例来引导。这听起来相当有趣,也值得我们去验证这一说法,并将其与业界标准的 GCC 进行一番深入的基准测试。
CCC 的源代码可以在其 GitHub 仓库 找到。它完全用 Rust 编写,支持 x86-64、i686、AArch64 和 RISC-V 64 架构。其前端、基于 SSA 的 IR、优化器、代码生成器、窥视优化器、汇编器、链接器以及 DWARF 调试信息的生成,都是从零开始实现的,没有任何编译器特定的依赖。对于 AI 而言,这无疑是一项巨大的工作量。
编译流程简述:编译器、汇编器与链接器
在开始对比之前,有必要先了解一下编译一个 C 程序时究竟发生了什么。这个过程通常涉及四个主要阶段。
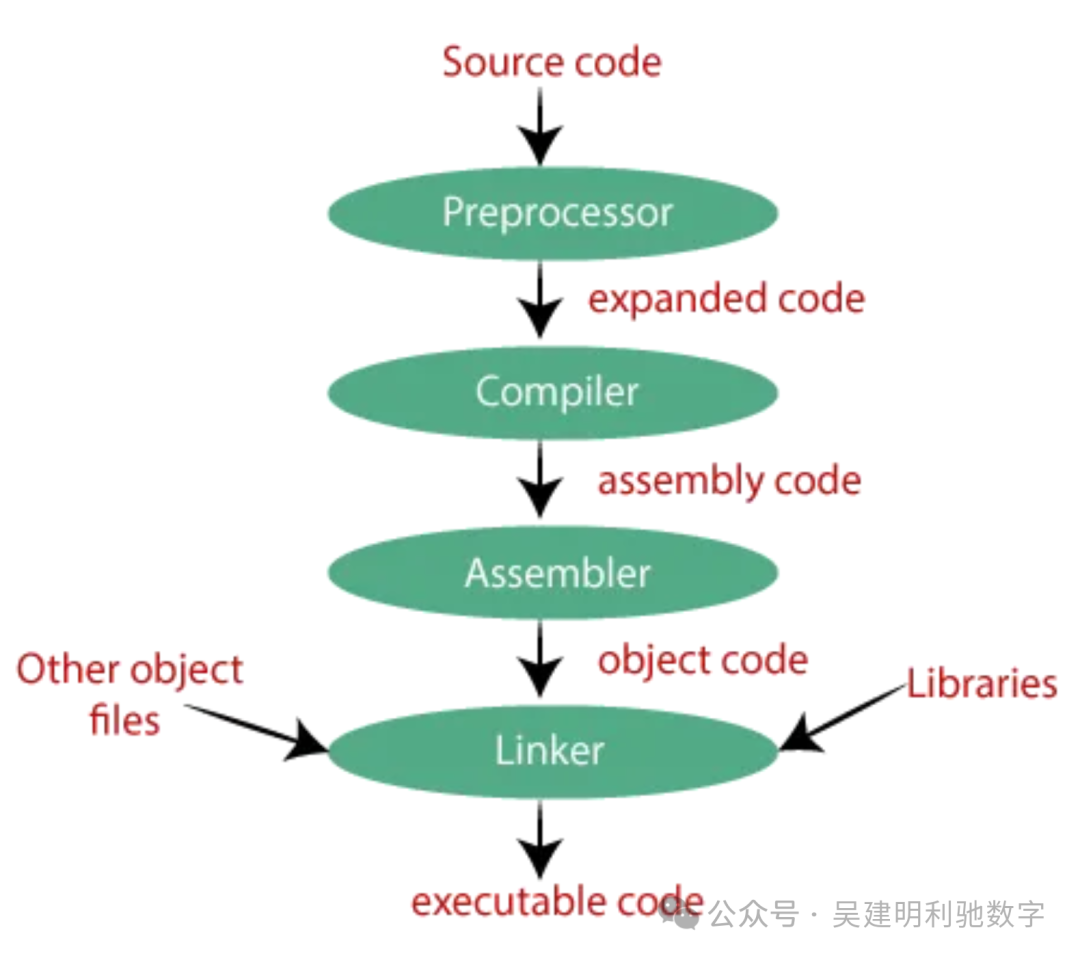
- 预处理器:处理
#include、#define 等指令,接收源代码并生成扩展后的源代码。
- 编译器:将预处理后的源代码翻译成汇编语言。这是最复杂的部分,涉及 C 语言的理解、类型检查、优化、寄存器分配等。
- 汇编器:将汇编语言转换为机器码(目标文件)。它必须精确知道目标 CPU 架构的指令编码。
- 链接器:将一个或多个目标文件合并成一个可执行文件。它负责解析文件之间的引用、设置内存布局并生成最终的二进制文件。
为什么构建一个优秀的编译器如此困难?
编写一门编程语言本身已经很具挑战性,而构建一个编译器则是另一个维度的难题。编程语言定义了规则,而编译器必须理解这些规则,将其翻译成机器指令,为速度和体积进行优化,处理不同 CPU 架构的边缘情况,并且每次都能生成正确的代码。
GCC 自 1987 年开始开发,近 40 年的工作中凝聚了成千上万贡献者的智慧。它支持数十种架构,实现了数百种优化,并修复了数不清的边缘案例。仅仅是优化过程(如寄存器分配、函数内联、循环展开、向量化、死代码消除、常量传播)就代表了多年的博士级研究。这也是它如此普及和强大的原因。
因此,CCC 能够编译真实的 C 代码本身已经非常值得注意。但这同时也解释了为何它的输出质量目前还远不如 GCC。构建一个能正确解析 C 语言的编译器是一回事,而构建一个能生成高效机器代码的编译器则是一个完全不同的挑战。
测试对象选择:SQLite 与 Linux 内核
Linux 内核是全球最复杂的 C 代码库之一,有数百万行代码,使用了大量 GCC 特定扩展、内联汇编、复杂的链接脚本。它并不是一个新编译器理想的入门测试对象。
相比之下,SQLite 则是一个更纯粹、标准化的选择。它以单一的合并 .c 文件分发,是经过充分测试的自包含标准 C 代码。如果一个编译器能正确处理 SQLite,那它就能应对很多其他项目;反之,则没有必要测试更大的项目。
因此,本次测试涵盖了这两个项目:SQLite 用于验证编译器的正确性和运行时性能;Linux 内核则用于测试其扩展性和兼容性。
测试环境与方法论
测试设置:
- 虚拟机:2 台基于 Debian 的 Proxmox 虚拟机,每台配置 6 vCPU, 16GB RAM, 100GB NVMe 磁盘。
- GCC:GCC 14.2.0 (Debian 14.2.0-19)。
- CCC:Claude‘s C Compiler,通过源码构建,启用
--features gcc_m16 选项以处理 16 位启动代码。
- 内核:Linux 6.9 (x86_64 defconfig)。
- SQLite:SQLite 3.46.0 合并版。
CCC 通过一个包装脚本 (ccc_wrapper.sh) 将 .S 汇编文件路由给 GCC 处理(因为 CCC 不处理汇编),所有 .c 文件则由 CCC 处理。
方法论: 编译器通常从以下几个维度衡量,测试也围绕这些方面设计:
- 编译代码的时间
- 编译后代码的大小
- 编译后代码的执行速度
- 编译器自身的内存使用
- 生成代码的稳定性(错误与崩溃概率)
公平比较原则:
- 相同的硬件规格。
- 相同的源代码(内核配置与 SQLite 版本)。
- 测试都运行到完成,不提前终止。
- CCC 在必要时得到帮助(如通过
gcc_m16 功能处理启动代码)。
- 使用相同的基准测试脚本。
结果总览
| 指标 |
GCC |
CCC |
比率/备注 |
| 内核构建时间 |
73.2 分钟 |
42.5 分钟 |
CCC 未能完成链接 |
| 内核构建结果 |
成功生成 vmlinux |
链接失败 |
– |
| 内核峰值内存 |
831 MB |
1,952 MB |
CCC 高出 2.3倍 |
| SQLite 编译 (-O0) |
64.6 秒 |
87.0 秒 |
CCC 慢 1.3倍 |
| SQLite 二进制大小 |
1.55 MB |
4.27 MB |
CCC 大 2.7倍 |
| SQLite 运行时 (-O0) |
10.3 秒 |
2 小时 06 分 |
CCC 慢 737倍 |
| SQLite 运行时 (-O2) |
6.1 秒 |
2 小时 06 分 |
CCC 慢 1,242倍 |
| 编译器内存使用 |
272 MB |
1,616 MB |
CCC 高出 5.9倍 |
| 崩溃/段错误测试 |
5/5 通过 |
5/5 通过 |
– |
需要特别注意,只有在与 GCC 的 -O2 优化级别(耗时7分多钟)对比时,CCC 的编译时间才会显得“快5倍”,但这仅仅是因为 CCC 完全跳过了优化工作。在公平的 -O0 (无优化) 对比中,CCC (87秒) 实际上比 GCC (65秒) 慢了约 25%。
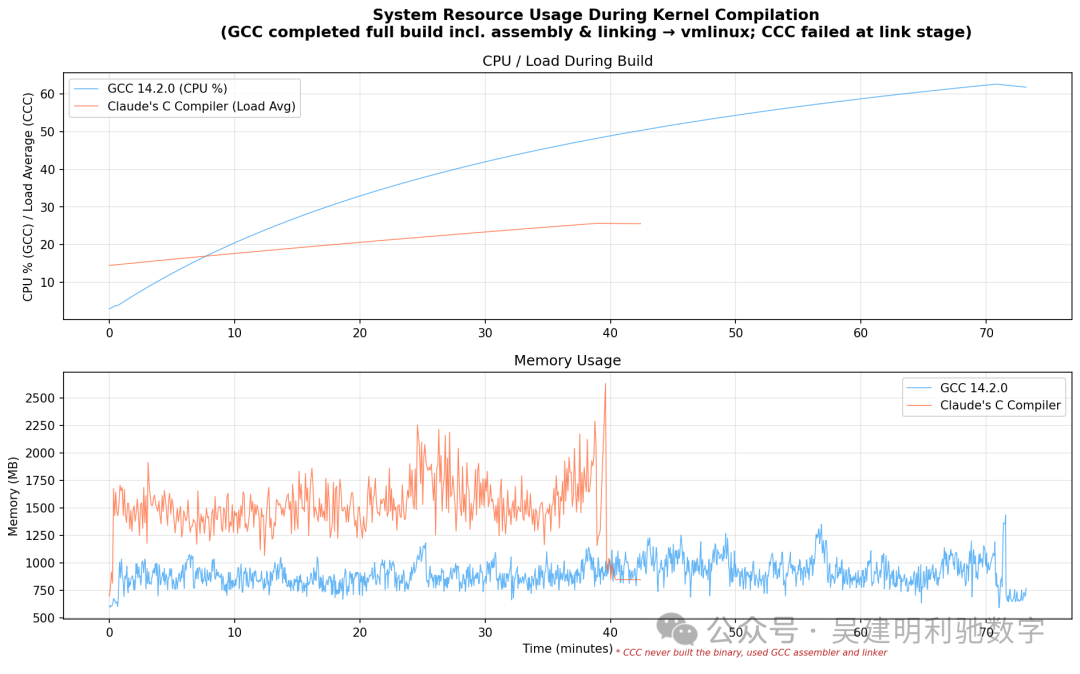
Linux 内核 6.9 编译测试
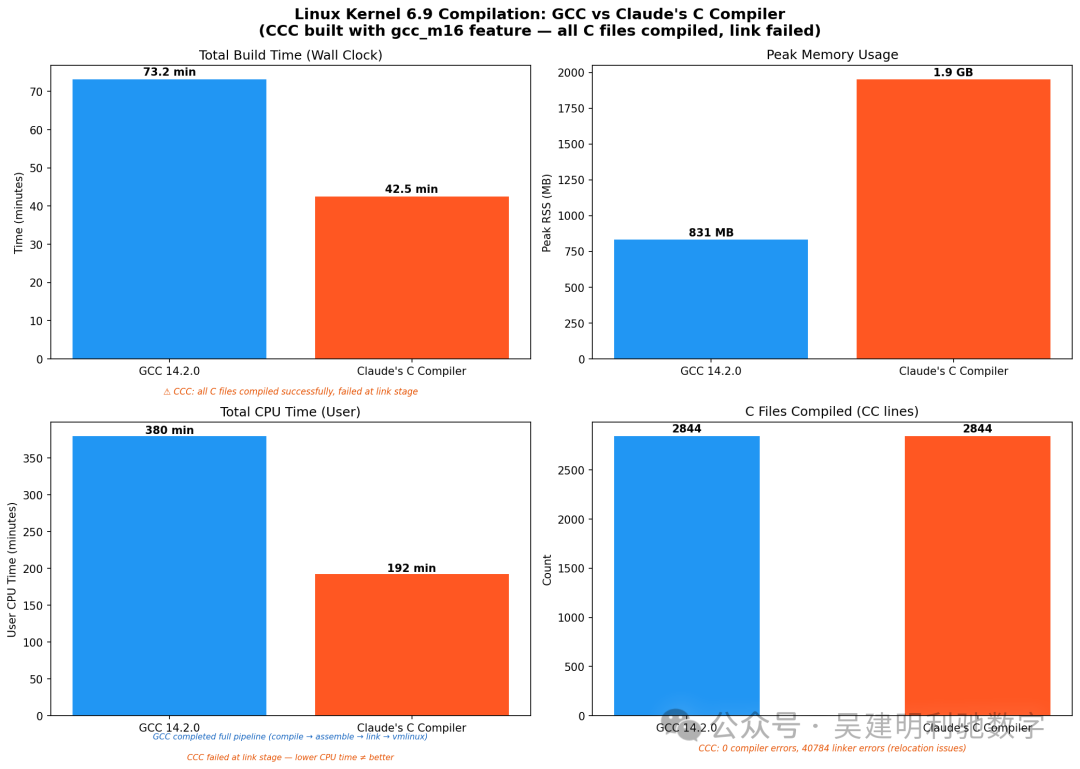
| 指标 |
GCC 14.2.0 |
CCC |
| 实际构建时间 |
73.2 分钟 |
42.5 分钟 (仅编译.c文件) |
| 用户态CPU时间 |
379.7 分钟 |
192.3 分钟 |
| 峰值内存使用 |
831 MB |
1,952 MB |
| 编译的C文件数 |
2,844 |
2,844 |
| 编译器错误 |
0 |
0 |
| 链接器错误 |
0 |
40,784 |
| 最终结果 |
成功生成 vmlinux |
链接失败 |
发生了什么?
CCC 成功编译了 Linux 6.9 内核中的 每一个 C 源文件,且没有任何编译器错误(0错误,96警告)。对于一个完全由 AI 构建的编译器来说,这确实令人印象深刻。
然而,在链接阶段,构建失败了,产生了约 40,784 个“未定义引用”错误。错误主要分为两类:
__jump_table 重定位错误:CCC 为内核跳转标签(用于静态键/追踪点)生成了错误的重定位条目。__ksymtab 引用错误:CCC 为内核模块导出生成了格式错误的符号表条目。
这些是链接器可见的错误,源于 CCC 在重定位/符号生成阶段的缺陷,而非 C 语言编译错误。这也印证了链接器是整个工具链中最复杂的部分。
SQLite 3.46 基准测试
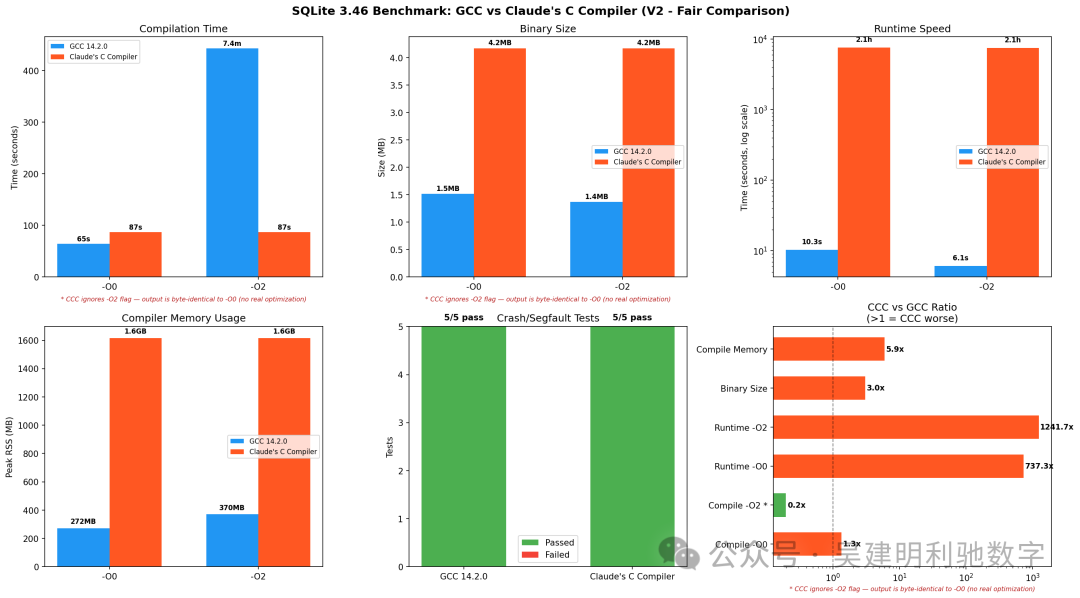
编译表现
| 指标 |
GCC -O0 |
GCC -O2 |
CCC |
| 编译时间 |
64.6 秒 |
7 分 23 秒 |
1 分 27 秒 |
| 编译器峰值内存 |
272 MB |
370 MB |
1,616 MB |
| 生成的二进制大小 |
1.55 MB |
1.40 MB |
4.27 MB |
一个关键发现:CCC 使用 -O0 和 -O2 标志编译出的二进制文件字节完全一致 (4,374,024 字节)。CCC 虽然有 15 个 SSA 优化过程,但它们在任何优化级别下都会执行。-O 标志被接受但被完全忽略,没有分级优化。
为何这很重要?
当使用 GCC -O2 编译时,它会执行几十个额外的优化过程:指令选择、寄存器分配、循环展开、函数内联、死代码消除、向量化等。GCC 花费 7 分钟进行这些优化,效果显著:-O2 二进制运行速度比 -O0 快 1.7 倍。
CCC 则完全没有这些优化工作。将“CCC 编译时间”与“GCC -O2 编译时间”对比,就像比较黑白打印机和彩色打印机。黑白打印机更快,但完成的是完全不同的任务。
运行时性能
| 指标 |
GCC -O0 |
GCC -O2 |
CCC |
| 总运行时间 |
10.3 秒 |
6.1 秒 |
2 小时 06 分 |
| 用户态CPU时间 |
9.68 秒 |
5.46 秒 |
7,518 秒 |
| 程序峰值内存 |
7.4 MB |
7.0 MB |
9.6 MB |
CCC 编译的 SQLite 在功能上是正确的——所有查询结果与 GCC 版本一致,5 个崩溃/边缘情况测试也全部通过。但它的运行速度极慢。
逐查询性能剖析
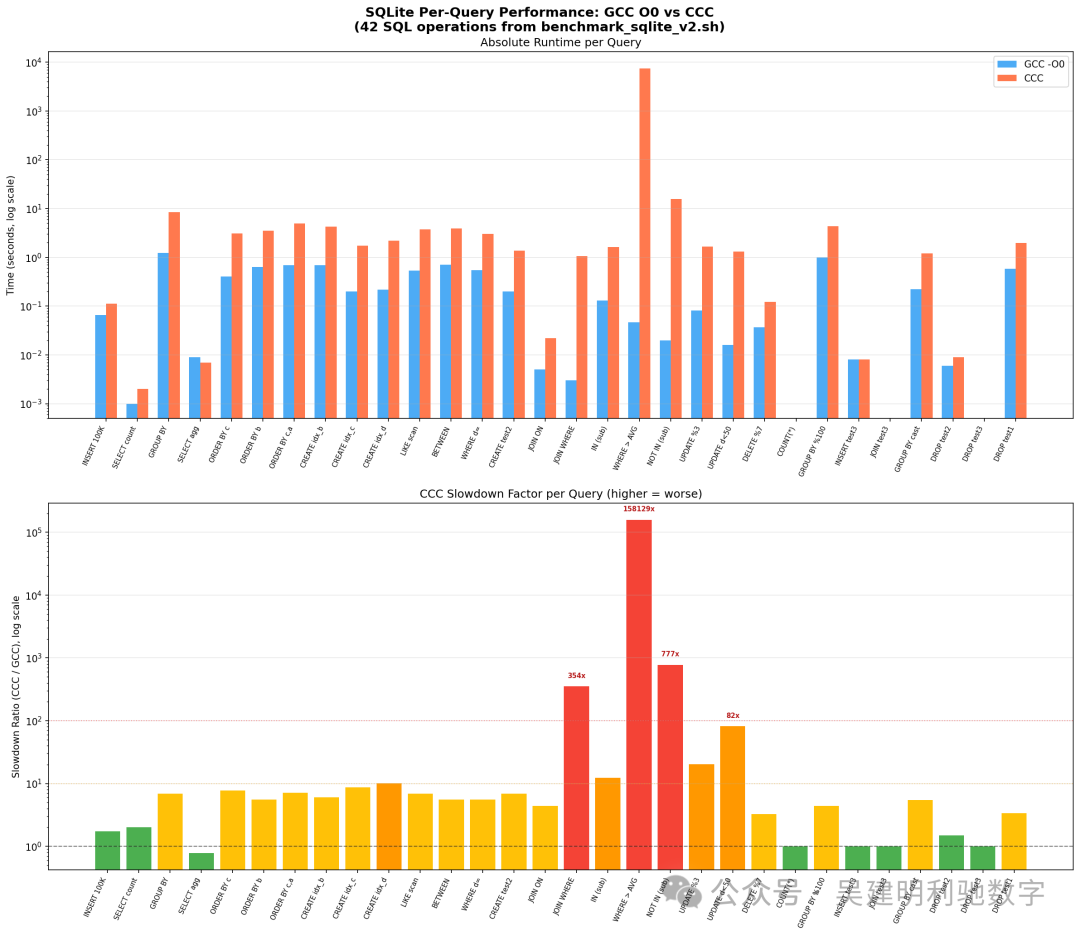
性能下降并非均匀。简单查询仅慢 1 到 7 倍,但涉及嵌套循环的复杂操作则呈指数级变慢:
| 查询 |
操作 |
GCC -O0 |
CCC |
慢速因子 |
| Q18 |
WHERE a NOT IN (SELECT a FROM test2) |
0.047s |
7,432s |
158,129x |
| Q38 |
跨表连接 + GROUP BY |
0.002s |
52.5s |
26,235x |
| Q19 |
WHERE a IN (SELECT a FROM test2) |
0.020s |
15.5s |
777x |
| Q16 |
INNER JOIN ON (count) |
0.003s |
1.06s |
354x |
| Q21 |
UPDATE … WHERE d < 50 |
0.016s |
1.31s |
82x |
| Q03 |
GROUP BY d ORDER BY COUNT(*) DESC |
1.218s |
8.39s |
6.9x |
| Q01 |
插入 100K 行 |
0.065s |
0.113s |
1.7x |
| Q42 |
删除表 |
0.051s |
0.057s |
1.1x |
显然,涉及嵌套迭代(子查询、连接)的操作慢了数个数量级,而简单的顺序操作仅略慢。
根本原因分析:为什么 CCC 的代码如此之慢?
-
严重的寄存器溢出
现代 CPU 拥有少量高速的寄存器。优秀编译器会尽量将频繁使用的变量保存在寄存器中。当变量过多时,它们会被“溢出”到较慢的堆栈内存中。
CCC 最致命的问题就是极度的寄存器溢出。SQLite 的核心函数 sqlite3VdbeExec 有上百个局部变量和一个巨大的 switch 语句。由于 CCC 缺乏良好的寄存器分配,它几乎将所有变量都溢出到堆栈。
GCC -O0 生成的代码片段 (高效使用堆栈):
movl -8(%rbp), %eax ; 加载循环计数器
cmpl -36(%rbp), %eax ; 与 n 比较
jl .L6 ; 条件跳转
movl (%rax), %edx ; 直接从内存加载 a[i]
cmpl %eax, %edx ; 在寄存器中比较
CCC 生成的代码片段 (严重的内存搬运):
movq -0x1580(%rbp), %rax ; 从很深的堆栈偏移量加载
movq %rax, -0x2ae8(%rbp) ; 存到另一个很深的堆栈偏移量
movq -0x1588(%rbp), %rax ; 加载下一个值
movq %rax, -0x2af0(%rbp) ; 存到下一个偏移量
; ... 还有几十次类似的内存拷贝
CCC 使用了深达 -0x2ae8 (约11KB) 的堆栈偏移量。每个操作都遵循 堆栈 -> 寄存器 -> 堆栈 的模式,使用 %rax 作为临时的传递寄存器。
-
优化标志 (-O2 等) 完全无效
CCC 在所有优化级别下运行相同的 15 次 SSA 优化。
$ diff <(ccc -O0 -S test.c -o -) <(ccc -O2 -S test.c -o -)
(没有差异)
这意味着 -O2 没有任何效果,每个 CCC 生成的二进制文件本质上都是 -O0 质量。
-
代码膨胀
CCC 生成的代码量是 GCC 的 2.78 倍 (838,359 行汇编 vs 301,424 行)。更大的代码量导致更多的指令缓存未命中,进一步放大了寄存器溢出带来的性能惩罚。
-
损坏的帧指针与缺失的调试信息
调试 CCC 编译的程序时,堆栈回溯显示帧指针数据损坏,且二进制文件中缺少内部函数符号,使得性能分析和调试几乎无法进行。
为何子查询慢了 158,000 倍?
NOT IN (子查询) 模式导致 SQLite 执行嵌套循环:外表的 10 万行,每一行都要扫描内表的 1 万行数据,总计约 10 亿次迭代,每次迭代都调用庞大的 sqlite3VdbeExec 函数。
由于 CCC 的每次迭代有约 4 倍的开销(寄存器溢出),加上 2.78 倍代码膨胀带来的额外缓存未命中,性能惩罚是复合性的,最终导致超过 10 万倍的总体慢速。
主要发现与总结
CCC 的成功之处:
- 正确性:成功编译了内核所有 C 文件 (0错误),并为 SQLite 所有查询生成了正确结果。
- 稳定性:所有测试未出现崩溃或段错误。
- GCC 兼容性:接受大多数 GCC 命令行标志,可作为替代品进行编译尝试。
CCC 的不足与局限:
- 极差的运行时性能:复杂操作慢 737 倍至 158,000 倍。
- 链接器不兼容:无法处理内核复杂的重定位需求,链接失败。
- 巨大的代码体积:二进制文件是 GCC 的 2.7-3 倍大。
- 高内存消耗:编译时内存使用是 GCC 的 5.9 倍。
- 伪优化支持:
-O0 到 -O3 的输出完全相同。
- 缺失调试支持:缺乏 DWARF 信息,帧指针损坏,无函数符号。
- 编译速度:在公平的
-O0 对比中,CCC 比 GCC 慢约 25%。
总结评分
| 类别 |
胜者 |
备注 |
| 编译速度 |
GCC |
GCC -O0 比 CCC 快 25% |
| 二进制大小 |
GCC |
CCC 的二进制大 2.7-3 倍 |
| 运行时速度 |
GCC |
CCC 慢 737 倍到 158,000 倍 |
| 编译器内存 |
GCC |
CCC 多消耗 2.3-5.9 倍 RAM |
| 正确性/稳定性 |
平局 |
两者均通过所有测试 |
| 优化层级支持 |
GCC |
CCC 完全忽略 -O 标志 |
| 内核链接能力 |
GCC |
CCC 在链接阶段失败 |
一个尴尬的起点:无法编译 Hello World
在 Anthropic 发布 CCC 后的几小时内,GitHub 上就出现了 Issue #1 —— “Hello world 无法编译”。即使是 README 中的示例代码,在新安装的系统上也失败了:
$ ./target/release/ccc -o hello hello.c
/usr/include/stdio.h:34:10: error: stddef.h: No such file or directory
/usr/include/stdio.h:37:10: error: stdarg.h: No such file or directory
ccc: error: 2 preprocessor error(s) in hello.c
与此同时,GCC 顺利完成了编译。问题在于 CCC 的预处理器没有在正确的系统路径中查找编译器自带的头文件(如 stddef.h)。该问题获得了大量关注,许多人评论道“我的工作很安全”。截至目前,这个问题依然处于开放状态。
结论
Claude‘s C Compiler (CCC) 无疑是一个引人注目的成就。它证明了 AI 有能力从零开始构建一个功能基本正确的 C/C++ 编译器,并能编译像 Linux 内核这样复杂的项目中的数千个文件。
然而,它距离生产环境使用还有很长的路要走:
- 生成的代码效率极低,核心问题是糟糕的寄存器分配算法。
- “编译 Linux 内核”的声明需要加注:它成功编译了所有 C 文件,但未能成功链接生成最终的可执行内核。
- 优化系统形同虚设,无法产生不同优化级别的代码。
对于 Anthropic 证明 Claude 能构建复杂软件的目标而言,CCC 是一次巨大的成功。但对于任何追求高性能、高可靠性软件编译的开发者而言,GCC、Clang 等成熟的编译器依然是唯一务实的选择。
复现方法
前提条件
- 两台虚拟机(建议 >=6 vCPU, 16GB RAM, 50GB 磁盘)。
- Debian/Ubuntu 环境,安装
build-essential, cargo, git, flex, bison, bc, libelf-dev, libssl-dev。
构建 CCC
git clone https://github.com/anthropics/claudes-c-compiler
cd claudes-c-compiler
cargo build --release --features gcc_m16
运行基准测试
# 内核测试
bash scripts/benchmark_kernel.sh gcc /usr/bin/gcc results/kernel_gcc
bash scripts/benchmark_kernel.sh ccc /path/to/ccc_wrapper.sh results/kernel_ccc
# SQLite测试
bash scripts/benchmark_sqlite.sh gcc gcc results/sqlite_gcc_v2
bash scripts/benchmark_sqlite.sh ccc /path/to/ccc_wrapper.sh results/sqlite_ccc_v2
生成图表
python3 -m venv .venv
.venv/bin/pip install matplotlib numpy
.venv/bin/python scripts/analyze.py
所有用于测试和对比的脚本、结果及图表均可在 compare-claude-compiler 仓库找到。
引用链接
[1] Building a C compiler with a team of parallel Clauses
[2] claudes-c-compiler GitHub Repository
[3] Issue #1: Hello world fails to compile
[4] compare-claude-compiler (基准测试代码仓库)
本文旨在提供深度的技术对比与分析,相关讨论欢迎在云栈社区的对应板块进行。
 发表于 2026-2-10 01:56:18
|
查看: 243|
回复: 0
发表于 2026-2-10 01:56:18
|
查看: 243|
回复: 0
