到了2026年,AI真的能动手修改数据库内核这种核心代码了吗?为了验证这个想法,也为了探究一个困扰已久的技术问题,我用 Claude Code 实际操刀,把 PostgreSQL 的 Full Page Write (FPW) 机制替换成了 MySQL 的 Doublewrite Buffer (DWB),一番测试下来,性能差距竟达到了3倍。
起因
关于 Full Page Write 和 Doublewrite Buffer 这两种设计到底谁更合理,我想了挺久。之前在 pgsql-hackers 的邮件列表里发帖讨论过,但也没讨论出个所以然。
既然有疑问,最好的办法就是用代码和实验说话。正好,Claude Code 这类 AI 编码工具发展迅猛,何不试试看它能不能胜任修改数据库内核这种高难度任务?于是就有了这次从理论到代码、再到性能对比的完整实践。
Torn Page 问题:共同的敌人
无论是 PostgreSQL 还是 MySQL,它们都以“页”为单位管理数据,PostgreSQL 默认页大小是 8KB,MySQL InnoDB 默认是 16KB。然而,操作系统和磁盘的原子写入单元通常是 4KB(一个扇区大小)。
这就带来了一个问题:当数据库需要将一个完整的页(比如 8KB)写回磁盘时,实际上需要多次物理 I/O 操作。如果在这几次写操作之间系统断电或崩溃,磁盘上的页面就可能只写入了一部分——这就是 Torn Page(页撕裂)。新旧数据混杂在一起,这个页面就损坏了,无法保证数据一致性。
面对这个共同的敌人,PostgreSQL 和 MySQL 选择了完全不同的防御策略。
PostgreSQL 的策略:Full Page Write (FPW)
PostgreSQL 的解决方案是 Full Page Write。简单来说,在每次检查点(Checkpoint)之后,某个数据页的第一次被修改时,PostgreSQL 不仅会把“修改了什么”这条增量记录写入 WAL(Write-Ahead Log,预写日志),还会把整个页面的完整镜像也写入 WAL。
崩溃恢复时,如果发现某个数据页可能损坏(Torn Page),恢复进程就可以从 WAL 中找到这个页面的完整副本,直接覆盖掉坏页,然后再按顺序回放后续的 WAL 增量记录即可。这样一来,就解决了页撕裂问题。
但 FPW 带来一个非常棘手的问题:它让检查点的频率设置陷入两难境地。
- FPW 希望少做检查点:因为每次检查点之后,大量数据页的首次修改都需要写入全页镜像到 WAL,导致 WAL 日志体积瞬间膨胀,写入性能会出现断崖式下跌。这也是为什么 PostgreSQL 的
checkpoint_timeout 参数最低也只能设到 30 秒(当然,检查点也可能因为 WAL 大小超过 max_wal_size 而触发)。
- 数据库恢复理论希望多做检查点:检查点越频繁,崩溃后需要回放的 WAL 日志就越少,恢复速度就越快。
这两个目标在 FPW 机制下是直接冲突的:FPW 要求少做检查点来保证写入性能,而快速恢复要求多做检查点。
MySQL 的策略:Doublewrite Buffer (DWB)
InnoDB 存储引擎的思路则截然不同。它引入了一块独立的磁盘区域,称为 Doublewrite Buffer。
当后台进程需要将脏页刷回数据文件时,它不是直接写入最终位置,而是分两步走:
- 先将一批脏页顺序地写入 Doublewrite Buffer 这块连续区域。
- 对 Doublewrite Buffer 调用一次
fsync(),确保这批页的副本已持久化。
- 再将这批页离散地写入各自在数据文件中的实际位置。
如果崩溃发生在第3步,导致某个数据页写入不完整(Torn Page),重启时 InnoDB 会检查 Doublewrite Buffer。只要在那里找到了该页的完整副本,就可以用它来修复损坏的数据页,同样解决了页撕裂问题。
为什么我认为 Doublewrite Buffer 设计更优?
1. 前台路径 vs 后台路径
如果我们忽略数据合并等细节,只考虑保证数据不撕裂的基本 I/O 开销:
- FPW = 1 次 WAL 写入(前台) + 1 次数据页写入(后台)
- DWB = 2 次数据页写入(都在后台)
虽然都是两次 I/O,但关键区别在于:FPW 的那一次“完整页写入”发生在前台的 WAL 写入路径上,这直接影响了用户提交 SQL 的延迟(Latency)。而 DWB 的两次写入都在后台刷脏路径上,对用户请求的直接影响要小得多。
2. 批量(Batch)优化的空间不同
DWB 的写入不需要每次调用 fsync(),可以积累一批脏页,写满一个 Buffer 后才同步一次,能更好地利用磁盘的顺序写入性能。WAL 写入虽然也能批量提交,但毕竟它处于事务提交的关键路径上,不能让用户等待过久,其批量优化的空间相对有限。
3. 不存在检查点频率的矛盾
DWB 机制不依赖检查点来防止页撕裂。这意味着 DBA 可以放心地提高检查点频率(例如,为了加速崩溃恢复),而不用担心会像 FPW 那样引发严重的写放大和性能下降。这是一个很大的设计优势。
性能测试对比
为了验证理论,我进行了实际的性能测试。
主要配置如下:
shared_buffers=4GB
wal_buffers=64MB
synchronous_commit=on
maintenance_work_mem=2GB
checkpoint_timeout=30s
每个测试场景都会重建数据库,测试前执行 VACUUM FULL 并进行 60 秒预热,每个负载运行 300 秒。
测试场景: IO 密集型,--tables=10 --table_size=10000000
测试结果图表如下,清晰展示了不同并发下三种模式的性能差异:
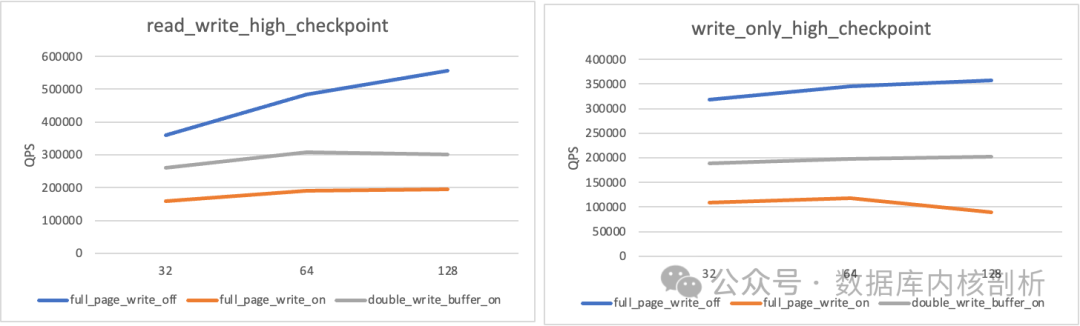
详细的量化数据如下表所示:
| 场景 |
并发 |
FPW OFF (QPS) |
FPW ON (QPS) |
DWB ON (QPS) |
FPW OFF (TPS) |
FPW ON (TPS) |
DWB ON (TPS) |
FPW OFF (ms) |
FPW ON (ms) |
DWB ON (ms) |
| read_write |
32 |
360,764 |
158,865 |
260,171 |
18,038 |
7,943 |
13,009 |
1.77 |
4.03 |
2.46 |
| read_write |
64 |
484,988 |
190,654 |
307,735 |
24,249 |
9,533 |
15,387 |
2.64 |
6.71 |
4.16 |
| read_write |
128 |
556,021 |
194,301 |
301,791 |
27,801 |
9,715 |
15,387 |
4.60 |
13.17 |
9.81 |
| write_only |
32 |
318,879 |
108,696 |
188,760 |
53,146 |
18,116 |
31,460 |
0.60 |
1.77 |
1.02 |
| write_only |
64 |
345,766 |
117,533 |
197,251 |
57,628 |
19,589 |
32,875 |
1.11 |
3.27 |
1.95 |
| write_only |
128 |
356,725 |
89,144 |
202,884 |
59,454 |
14,857 |
33,814 |
2.15 |
8.61 |
3.78 |
结果一目了然:
- 以关闭 FPW 的性能作为基线(最佳)。
- 开启 FPW 后,性能下降到基线水平的 ~25%。
- 而开启 DWB 后,性能可以保持在基线水平的 ~57%。
尤其是在 write_only 128 并发的高压场景下,DWB 的吞吐量是 FPW 的 2.3倍,平均延迟也全面优于 FPW。这个性能差距相当显著。
代码实现与思考
这次内核修改的代码已经开源,你可以在 GitHub - baotiao/postgres 查看。整个修改过程主要依靠 Claude Code 完成,这本身也验证了 AI 辅助进行数据库内核级别代码修改的可行性,为开源实战和系统调优提供了新的思路。
从测试结果看,在本文设定的 IO 密集型场景下,DWB 机制相比 FPW 展现出了明显的性能优势,尤其是在高并发写入时。这主要得益于其将关键 I/O 压力转移到了后台,并且解耦了检查点与崩溃恢复完整性的绑定关系。
当然,数据库设计没有银弹。FPW 与 WAL 深度集成,逻辑上更简洁;DWB 作为独立模块,在特定负载下性能更优。这场“模块化”与“紧耦合”之间的设计哲学差异,以及它们在不同硬件(如 NVMe SSD)、不同工作负载下的表现,依然值得深入探讨。如果你对这类数据库底层机制对比或性能优化实践感兴趣,欢迎在 云栈社区 交流分享你的看法和经验。
 发表于 2026-2-10 04:38:12
|
查看: 208|
回复: 0
发表于 2026-2-10 04:38:12
|
查看: 208|
回复: 0
