和传统简单的问答机器人不同,现代 AI Agent 能够通过对话形式直接完成复杂任务,从而显著提升业务转化率。本文将从工程实践角度,拆解 Agent 实现自动化交互背后的关键技术要素——Session(会话)、Memory(记忆)与Context(上下文)管理。
从“大脑”到“手脚”:理解 Agent 的本质
当我们使用 deepseek 或豆包这类大模型时,常会发现 LLM 仅能给出步骤建议,却无法执行实际操作。要将大模型变成能自主完成任务的Agent,关键在于为其整合“手脚”——也就是各类工具。
举个例子:你让豆包整理一份数据到 Excel,它能理解指令并输出表格的文本格式,但无法生成一个可下载的 .xlsx 文件,因为它缺乏与文件系统交互的能力。这时,我们需要为豆包装备一个能操作 Excel 的 MCP 工具。通过将大模型与MCP工具结合构建成 Agent,它就能真正生成并提供文件下载链接。
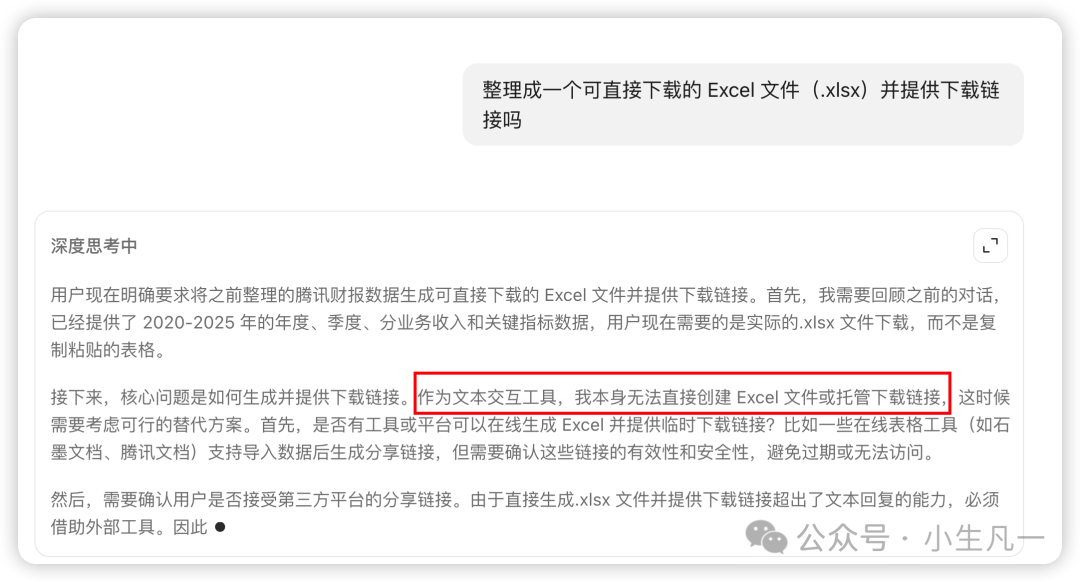
豆包可以思考步骤,但需要工具来执行生成文件的操作。

通过为豆包(Douba)集成 MCP 工具,构建出能处理文件的实际 Agent。
基石:Session(会话)管理
理解了 Agent 的概念后,我们需要关注交互的基础单元——Session(会话)。
对话式 Agent 通常涉及多轮交互。在工程实现上,我们通常将同一个对话窗口内的所有交互记录视为一个 Session。
- 当用户开启新窗口或点击“新对话”时,系统会初始化一个新的 Session ID。
- 类似元宝、ChatGPT 应用左侧的历史对话列表,本质上就是不同 Session 的索引,方便用户切换和管理不同主题的对话。
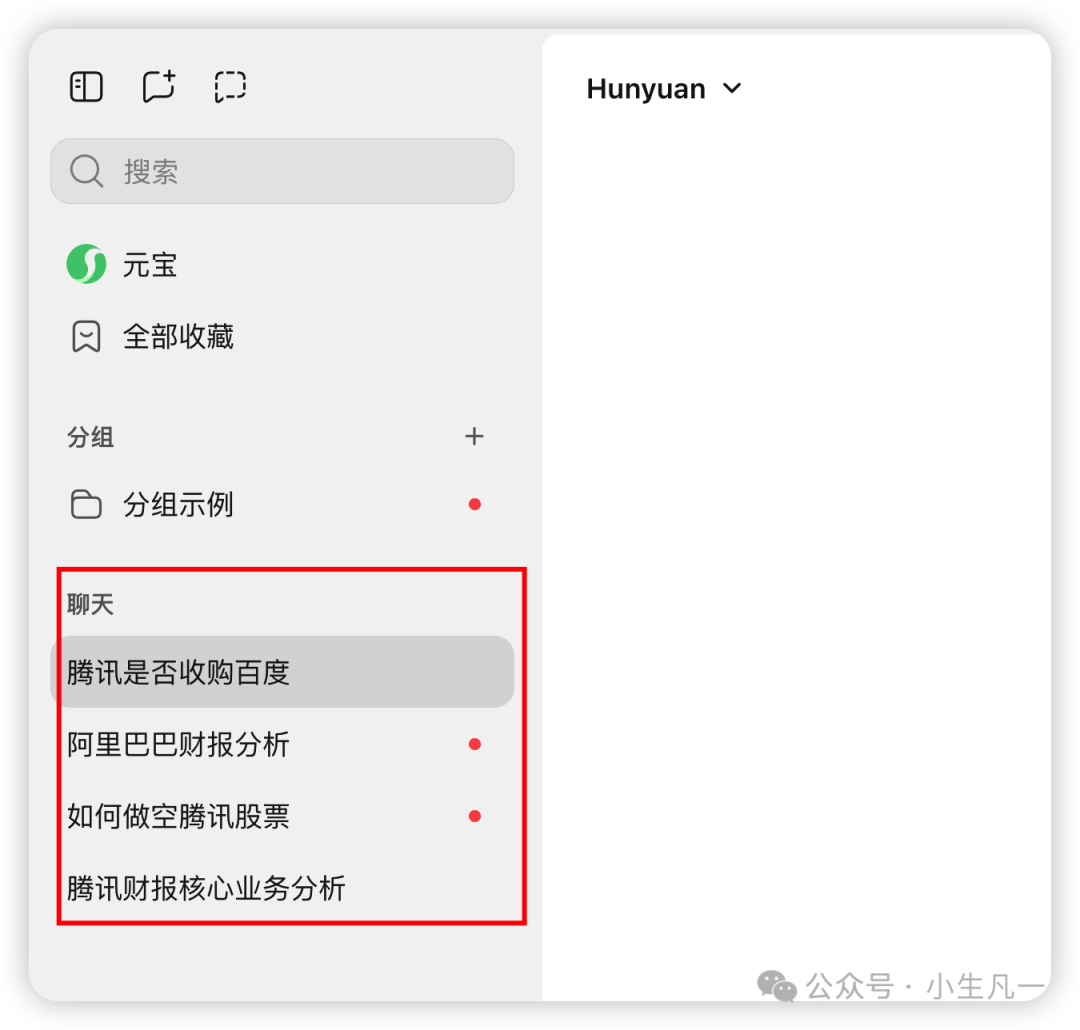
应用中的历史对话列表,即不同 Session 的索引。
核心:Memory(记忆)机制
大模型本质上是 Stateless(无状态) 的。这意味着它不知道自己上一句说了什么,每一次请求都是独立的。所有的“记忆”都依赖于后端工程架构——将历史记录作为输入再次传给模型。
记忆通常被分为 短期记忆 和 长期记忆:
- 短期记忆:当前 Session 对话中的内容,用于保持单次对话的连贯性。
- 长期记忆:跨 Session 持久化存储的信息,如用户的长期兴趣偏好(例如爱好打篮球、喜欢二次元等)。

一个关键实践是:在每次 Session 结束后,可以利用模型对对话内容进行摘要提炼,并将摘要归档至用户的长期记忆中。 这既节省了存储空间,又保留了核心信息。
那么,如何高效地维护和检索 Session 中的对话内容呢?为了让输入给大模型的 prompt 更精准,我们常使用 Vector DB(向量数据库) 进行存储。因为向量数据库支持语义向量化,相比传统数据库的精确匹配,它能更容易实现语义相似性检索,从而找出与当前问题最相关的历史对话片段提供给模型。业界比较成熟的向量数据库方案有 Elasticsearch (ES)、Milvus、Faiss 等。
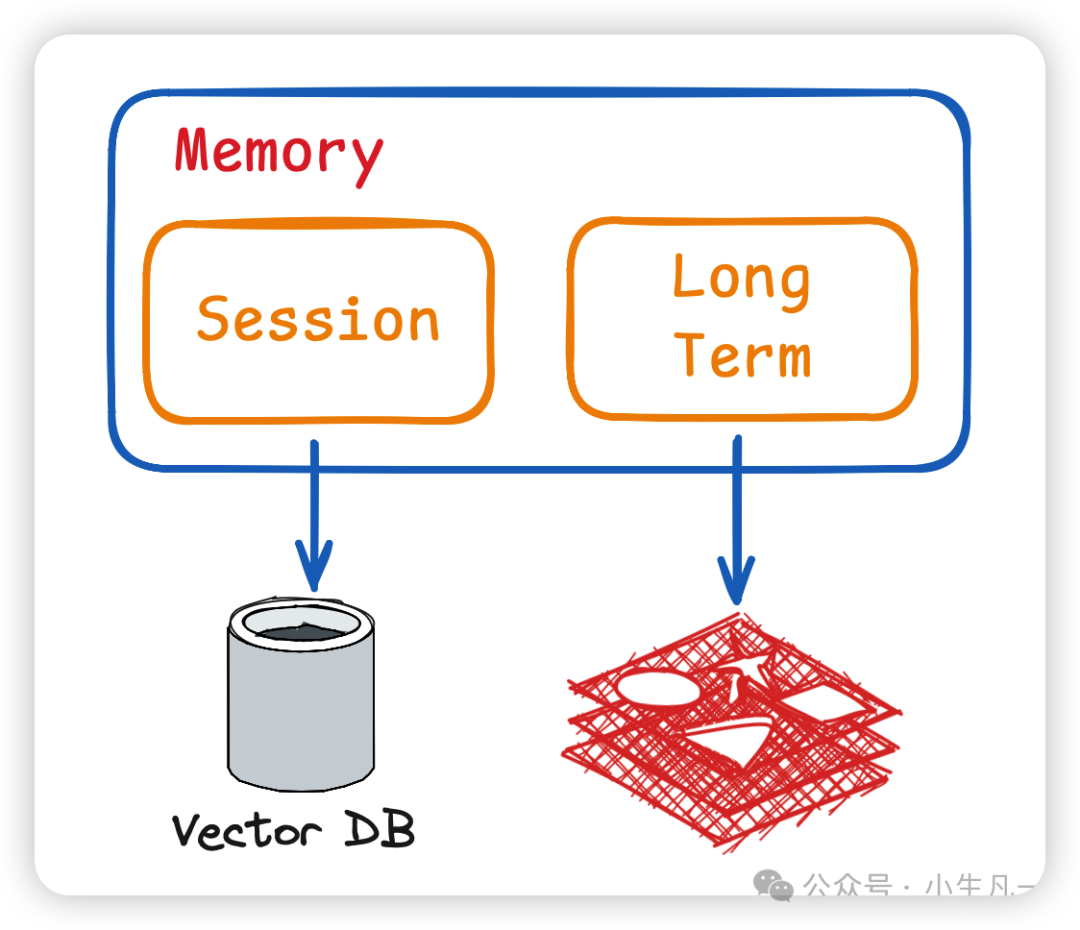
Memory 的实现架构:Session 记忆通常借助向量数据库检索,Long Term 记忆持久化存储。
工程关键:Context(上下文)管理
鉴于模型的无状态特性,我们需要在每次请求时,构造一个包含完整信息的 Context(上下文) 发送给模型。一个标准的 Context 通常包含以下几种角色(Role)的消息:
- User:用户的输入。
- Assistant:模型之前返回的回答。
- System:系统预设的指令,用于定义 Agent 的人设、行为约束等。
- Tool:工具调用的信息链,包括函数名、参数、执行结果等。
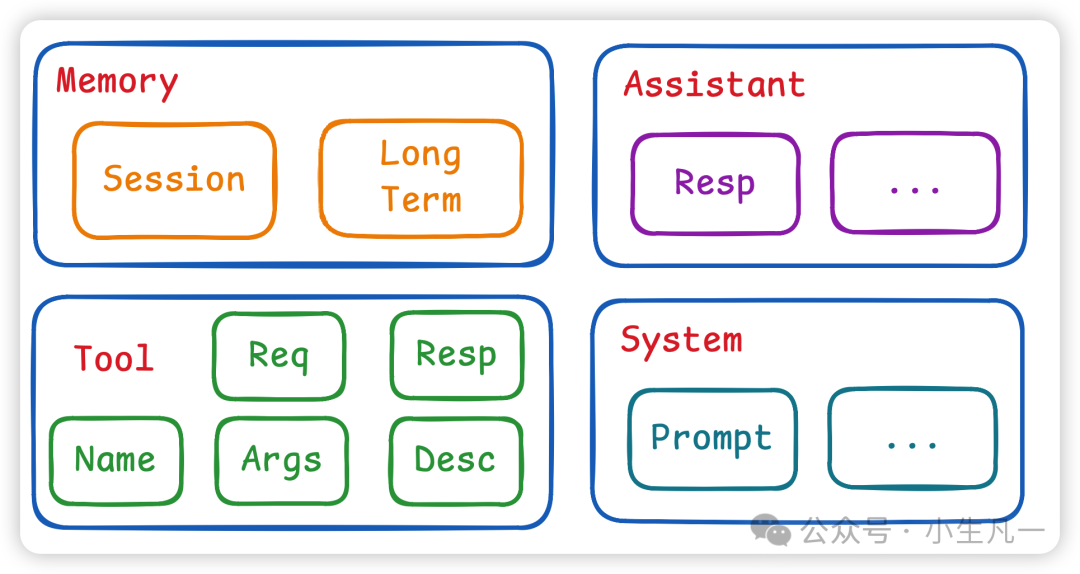
构成上下文的四种核心消息类型。
上下文管理的核心任务,就是决定哪些历史消息(来自 Memory)和系统指令需要被加载到当次请求的上下文窗口中。然而,模型的上下文窗口长度是有限的,并且输入的 Token 越多,成本越高,响应也可能越慢。因此,我们需要一套精细的 Context Management 策略来平衡信息量与资源消耗。
这里可以借鉴操作系统的内存管理思路:
- PageIn(换入):从向量库或缓存中,选取与当前用户问题高相关性的内容,加载到本次 Context 中。
- PageOut(换出):将低相关性或已经处理过的信息从当前 Context 中移除,为更重要的信息腾出空间。
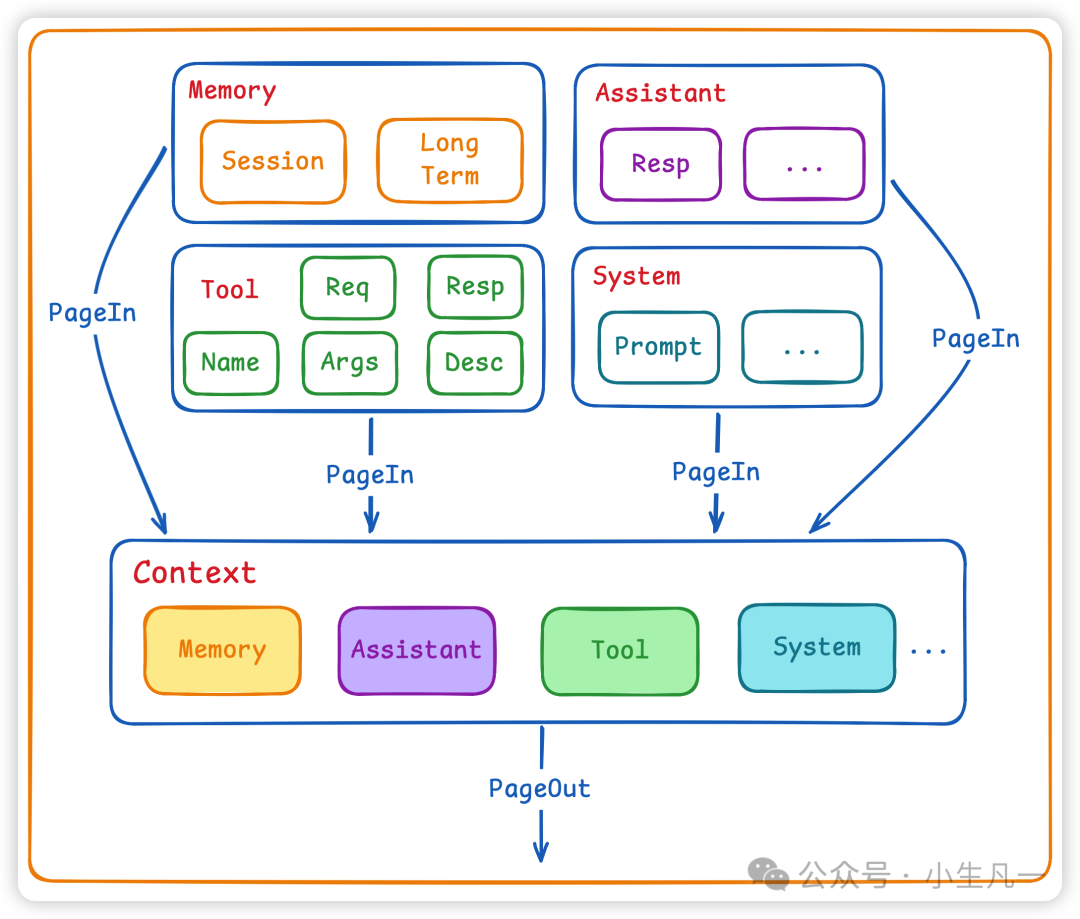
一个展示了 Memory, Assistant, Tool, System 信息如何通过 PageIn/PageOut 机制进出 Context 的流程图。
随着对话轮次增加,上下文会不断膨胀。我们需要设定压缩策略来精简上下文,控制其长度。压缩通常涉及两个层面的策略:
1. 压缩触发时机
- 对话轮次 > N 轮(如10轮)
- 累计消耗的 Token 数 > M(如 4000 Token)
2. 压缩实现策略
- 时序淘汰(如FIFO):优先遗忘最早发生的对话。
- 语义相关性淘汰:利用向量检索技术,仅保留与当前问题最相关的历史信息,剔除无关噪音。
- 摘要总结:这是更高级的策略。将多轮早期对话交给模型进行总结,然后用一个简短的“摘要”消息替代原先冗长的多轮对话记录,从而大幅压缩上下文长度。
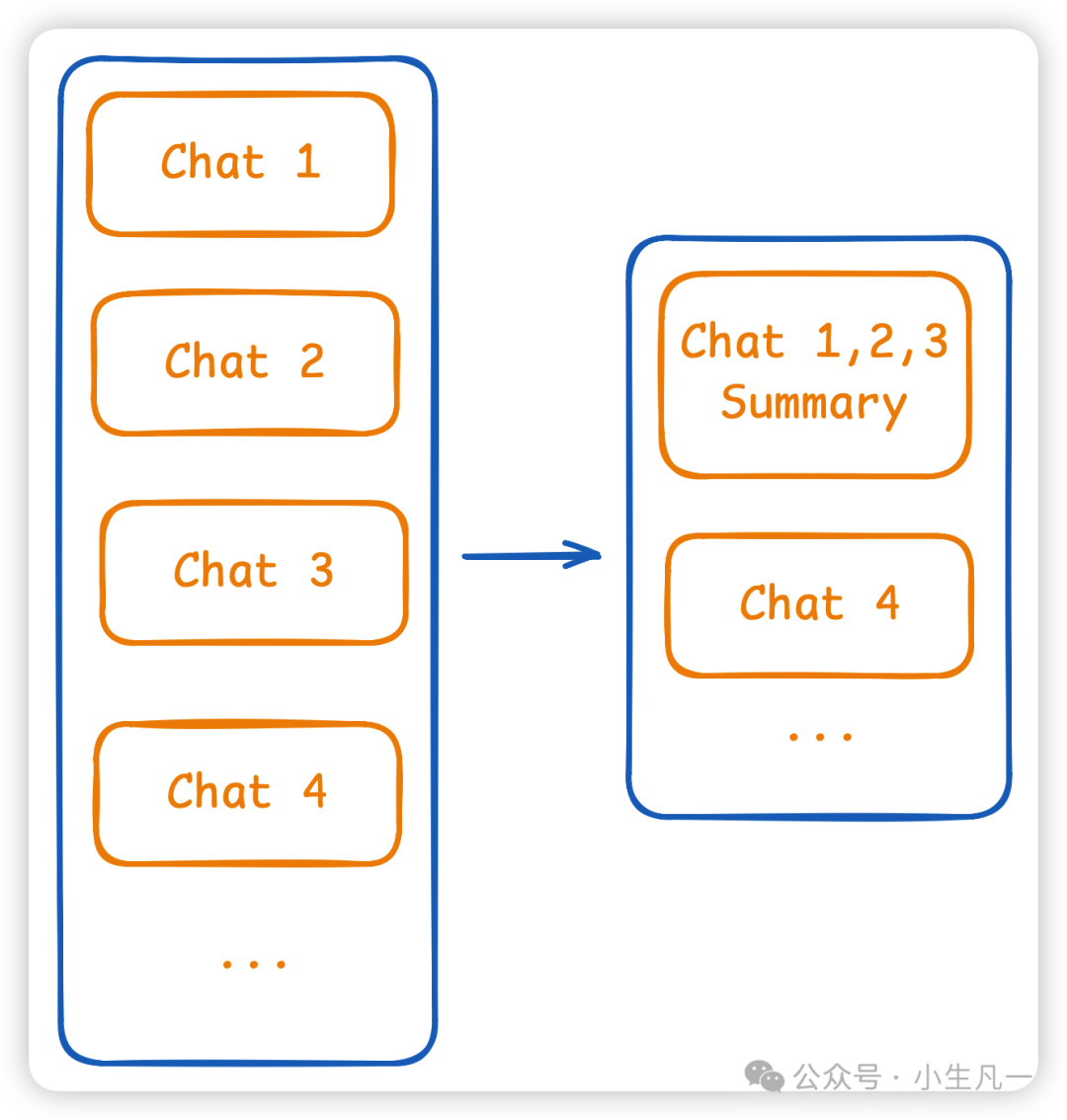
对话压缩示例:将前几轮对话总结为一条摘要信息,与最新对话一起构成新的上下文。
总结
构建一个高效的 AI Agent,远不止是调用大模型 API 那么简单。它需要一套完整的工程架构来支撑其“记忆”与“思考”。Session 定义了交互的边界,Memory 赋予了其回忆的能力,而精细化的 Context 管理则是保证其长期稳定、高效、低成本运行的关键。 这些技术要素共同构成了智能体与用户进行连贯、个性化且能处理复杂任务对话的基础。对这类 人工智能 工程化细节感兴趣的开发者,欢迎在 云栈社区 交流探讨。
参考:
[1] https://yonglun.me/context-engineering-sessions-memory/
 发表于 2026-2-11 07:55:45
|
查看: 360|
回复: 0
发表于 2026-2-11 07:55:45
|
查看: 360|
回复: 0
