内存管理是 Linux 内核的核心支柱,而内存泄漏、地址冲突、访问异常等问题,往往成为内核开发与运维中的“拦路虎”。要真正解决这些问题,就必须深入理解其根源——内存地址映射的底层逻辑。MMU(内存管理单元)作为 CPU 与内存之间的关键中间层,承担着虚拟地址与物理地址转换、内存访问权限控制等核心职责,是剖析和解决 Linux 内核内存问题的核心突破口。脱离对 MMU 机制的实操认知,仅靠表面排查,往往事倍功半。
本文将从纯理论框架中跳出,聚焦 MMU 机制的实操落地。我们将结合 Linux 内核内存管理的实际场景,拆解 MMU 的工作原理与地址转换流程,并剖析其在解决内存隔离、权限管控、碎片化等常见内核内存问题中的作用。通过串联核心知识点与实操案例,帮助开发者快速掌握 MMU 机制的调试方法与应用技巧,打通从理解原理到解决实际内存问题的链路。
一、MMU 机制基础概念
1.1 MMU 是什么
MMU,即内存管理单元(Memory Management Unit),从硬件层面讲,它是计算机中专门处理中央处理器(CPU)内存访问请求的关键硬件。
打个比方,计算机内存像一个大型仓库,里面存放着各类数据和程序,而运行的众多程序就如同来取物资的客户。如果没有管理机制,客户随意翻找,仓库就会混乱,物资易损坏丢失。MMU 就像仓库大管家,制定严格有序的管理规则。每个程序访问内存,都要通过 MMU “登记” 和 “授权”,它把程序的 “需求指令”(虚拟地址)精准转换为仓库中实际的 “物资存放位置”(物理地址),确保程序顺利获取所需,也保证了内存的秩序和数据安全。
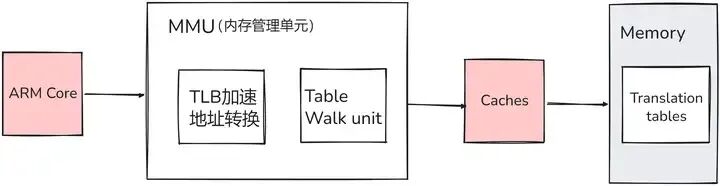
从功能上看,MMU 主要有两大核心功能:
- 虚拟地址到物理地址的转换:在现代操作系统中,为了给每个进程提供独立的地址空间,引入了虚拟地址的概念。每个进程都认为自己拥有从 0 开始的连续内存空间,而 MMU 负责将进程使用的虚拟地址映射到实际的物理内存地址上,让每个进程仿佛拥有专属的内存天地,彼此独立运行,互不干扰。
- 内存访问授权:MMU 提供硬件机制,严格审查每一次内存访问请求,只有合法的访问才能通过,有效杜绝非法操作对系统内存的破坏。例如,当一个进程试图访问不属于它的内存区域时,MMU 会及时阻止,并向操作系统报告,防止进程间相互干扰和数据泄露。
1.2 MMU 起源
在计算机发展的早期阶段,硬件资源十分有限,内存空间非常小,而且程序对内存的访问是直接而简单的。程序员需要手动分配和释放内存,稍有不慎就可能出现内存泄漏或其他错误。那个时候,程序直接访问物理内存,操作系统也只是简单地 “加载”、“运行” 或 “卸载” 应用程序。
随着计算机技术的飞速发展和软件的不断膨胀,计算机需要处理的任务越来越复杂,内存需求也越来越大。多任务处理的需求应运而生,同时,应用程序所需的内存量也不断增加,甚至超过了物理内存的大小。
为了解决这些问题,虚拟内存的思想被提出。虚拟内存就像是给计算机内存这个小仓库加了一个 “虚拟扩展空间”,程序所需的内存可以远超物理内存的大小,操作系统会把当前需要执行的部分留在内存中,而不需要执行的部分留在磁盘中。这样,就可以满足多个应用程序同时驻留内存并并发执行。
在这样的背景下,MMU 应运而生。它接替了操作系统内存管理中比较复杂的部分,比如地址翻译,将虚拟地址翻译成物理地址。同时,内存访问效率则交给了 cache(高速缓存)去做,或者通过提高内存总线的带宽来实现。
1.3 为什么需要 MMU
在没有 MMU 的早期计算机系统中,程序直接访问物理内存,这种方式存在诸多严重问题。
- 内存安全问题:多个程序共享物理内存,它们可以随意访问和修改内存中的任何数据,一个程序的错误操作就可能导致其他程序甚至整个系统崩溃。
- 内存碎片化问题:随着程序的频繁加载和卸载,物理内存容易出现碎片化。虽然总的空闲内存空间足够,但都是分散的小块,无法为大程序提供连续的大块内存,导致程序无法正常运行。
而 MMU 通过引入虚拟地址空间,很好地解决了这些问题。
- 对于内存安全:MMU 为每个进程分配独立的虚拟地址空间,不同进程的虚拟地址空间相互隔离,一个进程无法直接访问其他进程的内存区域。
- 对于内存碎片化:MMU 采用分页或分段等内存管理技术,将物理内存划分成固定大小的页,程序使用的虚拟地址可以映射到不连续的物理页上,操作系统通过管理页表来实现地址转换,从而避免了物理内存碎片化对程序运行的影响。
二、MMU 核心工作原理
2.1 地址转换机制
在 Linux 系统中,地址转换是 MMU 最核心的功能之一。其转换过程大致如下:
当 CPU 产生一个虚拟地址时,MMU 会首先介入。假设我们有一个 32 位的虚拟地址,它会被 MMU 按照特定规则划分为两部分:页号和页内偏移。例如,对于一个页大小为 4KB(2^12 字节)的系统,虚拟地址的低 12 位就是页内偏移,而剩下的高位部分则是页号。
MMU 会拿着这个页号去查找页表(Page Table)。页表就像是一本详细的地址映射字典,记录着每个虚拟页对应的物理页框号。通过页号作为索引,MMU 在页表中精准定位到对应的表项,从中获取物理页框号。然后,MMU 将获取到的物理页框号与虚拟地址中的页内偏移进行组合,最终得到实际的物理地址。
例如,假设虚拟地址 0x08048000,经过划分,页号为 0x0804,页内偏移为 0x800,通过页表查到对应的物理页框号为 0x1000,那么最终的物理地址就是 0x1000800。这个物理地址就会被用于访问实际的物理内存。整个地址转换过程在 MMU 的高效运作下,几乎是瞬间完成的。
2.2 页表:地址转换的关键
页表在地址转换过程中扮演着至关重要的角色。从结构上看,页表是一个数据结构,通常以数组的形式存在。每个条目对应一个虚拟页,被称为页表项(Page Table Entry,PTE)。
页表项包含了丰富且关键的信息:
- 物理帧号(Frame Number):指示了与虚拟页相对应的物理内存块编号。
- 有效位(Valid/Present Bit):用于指示对应的页是否当前存在于物理内存中。若为 0,则访问会触发缺页异常。
- 修改位(Modified/Dirty Bit):记录页面是否被写入过。在页面被置换出内存时,若该位被设置,则需要先写回磁盘。
- 访问位(Accessed/Referenced Bit):记录页面是否被访问过,可用于辅助页面置换算法(如 LRU)。
MMU 开启以后,系统会呈现以下特点:
- 多个程序可以独立运行。
- 虚拟地址是连续的(物理内存允许有碎片)。
- 允许操作系统高效地管理内存。
下图显示了虚拟内存与物理内存的映射关系。单个系统中的不同处理器和设备可能具有不同的地址映射。操作系统编写程序,使 MMU 在这两个内存视图之间进行转换:
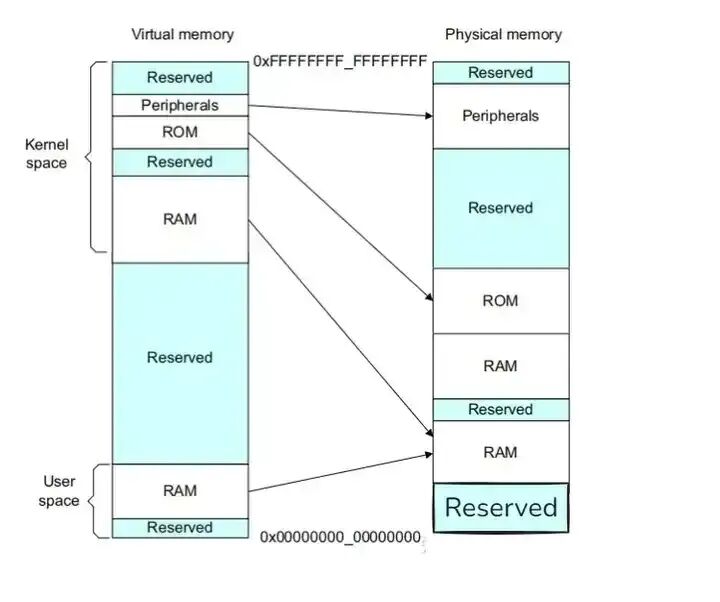
要做到这一点,虚拟内存系统中的硬件必须提供地址转换。MMU 使用虚拟地址中最重要的位来索引转换表中的条目,并确定正在访问哪个块。MMU 将代码和数据的虚拟地址转换为实际系统中的物理地址。该转换在硬件中自动执行,对应用程序透明。除了地址转换,MMU 还可以控制内存访问权限、内存顺序和缓存策略。
MMU 不了解系统的物理内存映射,也不了解同时运行的其他程序。每个程序可以使用相同的虚拟内存地址空间。即使物理内存是碎片化的,程序也可以使用一个连续的虚拟内存映射。应用程序被编写、编译和链接,以在虚拟内存空间中运行。
2.3 TLB:加速地址转换
TLB(Translation Lookaside Buffer),即地址转换后备缓冲器,是 MMU 加速地址转换的秘密武器。它的工作原理基于一个简单而高效的理念:缓存最近使用的地址转换信息。TLB 本质上是一种高速缓存,存储了近期最常访问的页表项。
当 CPU 产生一个虚拟地址时,MMU 会首先在 TLB 中查找。
- 如果命中(TLB Hit),则直接从 TLB 中获取物理页号,组合得到物理地址,过程极快。
- 如果未命中(TLB Miss),MMU 则需去内存中的页表中查找。找到后,不仅完成转换,还会将此新项缓存到 TLB 中,以备下次使用。
由于程序的局部性原理,TLB 的命中率通常较高,这极大提升了地址转换速度,减少了内存访问延迟。
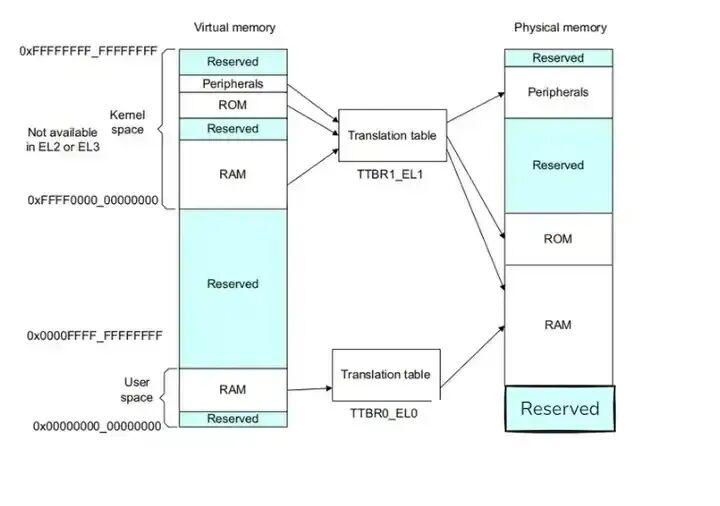
如上图所示,TLB 是 MMU 中最近访问的页面翻译的缓存。对于处理器执行的每个内存访问,MMU 将检查转换是否缓存在 TLB 中。如果所请求的地址转换在 TLB 中命中,则该地址的翻译立即可用。TLB 本质是一块高速缓存。数据 cache 缓存地址和数据,而 TLB 缓存虚拟地址和其映射的物理地址。TLB 根据虚拟地址查找,所以它是一个虚拟高速缓存。
每个 TLB entry 通常不仅包含物理地址和虚拟地址,还包含诸如内存类型、缓存策略、访问权限、地址空间 ID(ASID)和虚拟机 ID(VMID)等属性。如果 TLB 未命中,则将执行外部转换页表查找。如果翻译页表没有导致页面故障,则可以将新加载的翻译缓存在 TLB 中,以便后续重用。
简单概括:硬件存在 TLB 后,虚拟地址首先发往 TLB 确认是否命中 cache,如果命中则直接得到物理地址;否则,一级一级查找页表获取物理地址,并将映射关系缓存到 TLB 中。
如果操作系统修改了可能已经缓存在 TLB 中的转换 entry,那么操作系统就有责任使这些未更新的 TLB entry 失效。当执行 A64 代码时,有专门的 TLB 无效指令 TLBI:
TLBI <type><level>{IS} {, <Xt>}
TLB 可以保存固定数量的 entry。ARMv8-A 体系结构提供了一个被称为连续块 entry 的特性,以高效利用 TLB 空间。转换表每个 entry 都包含一个连续的位。当设置时,这个位向 TLB 发出信号,表明它可以缓存一个覆盖多个块转换的单个 entry。因此,TLB 可以为已定义的地址范围缓存一个 entry,从而可以在 TLB 中存储更大范围的虚拟地址。
三、Linux 内核中 MMU 的实际应用
3.1 Linux 内存管理架构回顾
为了更深入理解 MMU 在 Linux 内核中的作用,我们先来看看 Linux 内存管理架构的整体布局。下面是一个简化的 Linux 内存管理架构图:
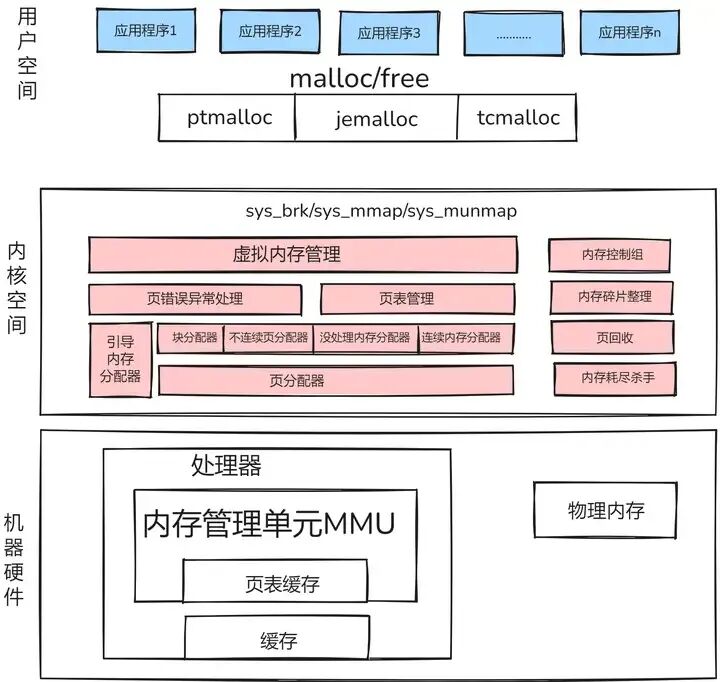
从用户空间进程开始,应用程序通过系统调用(如 malloc, free 等)向内核请求内存分配。当进程需要内存时,它会调用 malloc 函数,这实际上会触发一个系统调用进入内核空间。
在内核空间中,内存管理子系统负责处理这些请求。内存管理子系统与 MMU 密切协作。当内核需要为进程分配内存时,它会与 MMU 交互,更新页表等数据结构,以建立虚拟地址到物理地址的映射关系。MMU 则根据这些映射关系,在进程访问内存时进行地址转换。
3.2 关键数据结构分析
在 Linux 内核内存管理中,有两个关键的数据结构起着至关重要的作用:内存描述符(mm_struct)和虚拟内存区域(VMA, vm_area_struct)。
- 内存描述符(mm_struct):描述了一个进程的整个虚拟地址空间。每个进程都有一个对应的
mm_struct 结构体。它包含了进程的页目录指针 pgd(访问页表的入口),以及指向虚拟内存区域(VMA)链表的指针 mmap 和指向红黑树的指针 mm_rb。当 VMA 较少时使用链表管理,较多时则利用红黑树高效查找。
- 虚拟内存区域(VMA, vm_area_struct):描述了虚拟地址空间的一个连续区间。每个 VMA 代表进程虚拟地址空间中的一段,如代码段、数据段、堆、栈等。它包含了该区域的起始地址、结束地址、访问权限等重要信息。VMA 还包含一个指向
vm_operations_struct 结构的指针,其中定义了一系列操作函数(如处理缺页异常的 nopage 函数)。
通过这些数据结构,Linux 内核能够高效地管理进程的虚拟地址空间,实现内存的分配、释放和保护。
3.3 实战案例:手动创建内存映射
接下来,通过一个实战案例来更直观地了解 MMU 在内存管理中的应用,这里我们使用 mmap 函数手动创建内存映射。下面是一个使用 mmap 函数创建匿名内存映射的 C 语言代码示例:
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <errno.h>
#define MAP_SIZE 4096 // 映射区大小,这里设置为 4KB,通常是一个页的大小
int main(){
char *map_start;
int prot = PROT_READ | PROT_WRITE; // 映射区域的权限:可读可写
int flags = MAP_PRIVATE | MAP_ANONYMOUS; // 映射选项:私有映射且匿名映射
int fd = -1; // 匿名映射时,文件描述符设为-1
off_t offset = 0; // 映射偏移量,通常设为 0
// 使用 mmap 函数创建内存映射
map_start = (char *)mmap(0, MAP_SIZE, prot, flags, fd, offset);
if (map_start == MAP_FAILED) {
perror("mmap failed");
exit(EXIT_FAILURE);
}
// 向映射区域写入数据
strcpy(map_start, "Hello, MMU!");
// 从映射区域读取数据并输出
printf("Data from mapped memory: %s\n", map_start);
// 解除内存映射
if (munmap(map_start, MAP_SIZE) == -1) {
perror("munmap failed");
exit(EXIT_FAILURE);
}
return 0;
}
在这段代码中,我们使用 mmap 函数创建了一个大小为 4096 字节(一个内存页的大小)的匿名内存映射。创建映射后,我们通过 strcpy 函数向映射区域写入了字符串,然后再读取并输出。最后,使用 munmap 函数解除内存映射。通过这个例子,可以看到 MMU 在内存映射过程中的作用,它负责将虚拟地址空间中的映射区域与物理内存进行关联。
四、高级 MMU 技术实战
4.1 大页(HugePages)优化
大页,就是比普通内存页(如4KB)更大的内存页,如 2MB 甚至 1GB。大页的主要作用之一是解决 TLB 压力问题。由于 TLB 容量有限,大量小页会导致 TLB 命中率下降。使用大页可以显著减少页表项的数量(一个2MB大页相当于512个4KB小页),从而提高 TLB 命中率,加速地址转换,提升系统性能。
在 Linux 系统中,配置大页可以通过修改内核参数来实现。首先,查看系统支持的大页大小:
cat /proc/meminfo | grep Hugepagesize
然后,通过修改 /etc/sysctl.conf 文件,添加配置并生效:
vm.nr_hugepages = 100 # 预留100个大页
sudo sysctl -p
在 C 语言中使用大页,可以通过 mmap 函数并结合 MAP_HUGETLB 标志来实现:
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <errno.h>
#define HUGE_PAGE_SIZE (2 * 1024 * 1024) // 大页大小为 2MB
int main(){
char *map_start;
int prot = PROT_READ | PROT_WRITE; // 映射区域的权限:可读可写
int flags = MAP_PRIVATE | MAP_ANONYMOUS | MAP_HUGETLB; // 映射选项:私有映射、匿名映射且使用大页
int fd = -1; // 匿名映射时,文件描述符设为-1
off_t offset = 0; // 映射偏移量,通常设为 0
// 使用 mmap 函数分配大页内存
map_start = (char *)mmap(0, HUGE_PAGE_SIZE, prot, flags, fd, offset);
if (map_start == MAP_FAILED) {
perror("mmap failed");
exit(EXIT_FAILURE);
}
// 向大页内存区域写入数据
strcpy(map_start, "Hello, HugePages!");
// 从大页内存区域读取数据并输出
printf("Data from hugepage mapped memory: %s\n", map_start);
// 解除内存映射
if (munmap(map_start, HUGE_PAGE_SIZE) == -1) {
perror("munmap failed");
exit(EXIT_FAILURE);
}
return 0;
}
4.2 DMA 与 MMU 协同
DMA(直接内存访问)允许设备直接访问内存,无需 CPU 频繁干预。在 DMA 与 MMU 协同工作时,设备生成包含虚拟地址的 DMA 请求,MMU 会将其转换为物理地址,确保设备对内存的安全、正确访问,同时提高数据传输效率。
下面是一个简化的 Linux 内核模块示例,展示如何进行 DMA 内存分配和映射:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/dma-mapping.h>
#include <linux/mm.h>
MODULE_LICENSE("GPL");
static int __init dma_mmu_init(void){
struct device *dev = NULL; // 这里假设设备指针已正确初始化
size_t size = 4096; // 分配的内存大小,这里设为 4KB
dma_addr_t dma_handle;
void *dma_buf;
// 分配 DMA 内存
dma_buf = dma_alloc_coherent(dev, size, &dma_handle, GFP_KERNEL);
if (!dma_buf) {
printk(KERN_ERR "DMA allocation failed\n");
return -ENOMEM;
}
// 这里可以进行对 dma_buf 的操作,例如写入数据
// 释放 DMA 内存
dma_free_coherent(dev, size, dma_buf, dma_handle);
return 0;
}
static void __exit dma_mmu_exit(void){
printk(KERN_INFO "DMA MMU module removed\n");
}
module_init(dma_mmu_init);
module_exit(dma_mmu_exit);
4.3 KVM 虚拟化中的 MMU
在 KVM(基于内核的虚拟机)虚拟化中,MMU 扮演着至关重要的角色,它实现了二级地址转换。
- Guest Virtual Address (GVA) -> Guest Physical Address (GPA):由虚拟机内操作系统的 MMU 完成。
- GPA -> Host Physical Address (HPA):由 KVM 的 MMU(借助硬件的 EPT 或 NPT 技术)完成。
通过这种机制,KVM 能够高效管理虚拟机内存,实现虚拟机之间及虚拟机与宿主机之间的内存隔离和安全访问。对于虚拟机内的应用,整个过程是透明的。
五、MMU 性能优化实战
5.1 TLB 优化策略
- 大页使用:如前所述,大页能显著减少 TLB 项数量,提高命中率。例如,128条目的TLB,使用4KB页覆盖512KB,使用2MB页可覆盖256MB。
- 页面着色(Page Coloring):用于降低 TLB 冲突。通过将物理页按规则分组,使不同虚拟页映射到 TLB 时能均匀分布,减少冲突,提高利用率。
- 预取优化(Prefetch Optimization):利用硬件或软件机制,根据局部性原理提前将可能访问的页表项加载到 TLB 中,减少未命中。
5.2 页表遍历加速
ARMv8.1 引入了 TT(Translation Table Walk)指令来加速页表遍历。传统的多级页表遍历需要多次内存访问,而 TT 指令通过硬件加速,能直接根据虚拟地址快速定位物理地址,大大减少了遍历时间。例如,TTL T0, [X1] 指令可直接转换 X1 寄存器中的虚拟地址。
5.3 内存访问模式优化
不合理的内存访问模式(如频繁跨页访问)会导致页表抖动,降低性能。应基于局部性原理优化访问模式。
不佳示例(列优先访问,易导致抖动):
#define N 1000
void matrix_multiply_column_major(int A[N][N], int B[N][N], int C[N][N]){
for (int j = 0; j < N; j++) {
for (int i = 0; i < N; i++) {
int sum = 0;
for (int k = 0; k < N; k++) {
sum += A[i][k] * B[k][j]; // 按列访问B,不连续
}
C[i][j] = sum;
}
}
}
优化示例(行优先访问,利用空间局部性):
#define N 1000
void matrix_multiply_row_major(int A[N][N], int B[N][N], int C[N][N]){
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
int sum = 0;
for (int k = 0; k < N; k++) {
sum += A[i][k] * B[k][j];
}
C[i][j] = sum;
}
}
}
六、调试与问题排查
6.1 常见 MMU 相关错误
- 段错误(Segmentation Fault):程序试图访问非法内存地址(如野指针、已释放内存)。
int *ptr;
*ptr = 10; // 野指针,导致段错误
- 权限违规(Permission Violation):程序以超出权限的方式访问内存(如向只读内存写入)。
char *str = "Hello";
str[0] = 'h'; // 修改只读字符串常量,导致权限违规
- 总线错误(Bus Error):通常与硬件层面的内存访问问题相关(如内存控制器故障、奇偶校验错误)。
6.2 调试工具集
6.3 实战:调试内存泄漏
假设存在以下存在内存泄漏的 C++ 代码:
#include <iostream>
#include <cstdlib>
void leak_memory() {
int *ptr = new int[100];
// 这里没有释放 ptr,导致内存泄漏
}
int main() {
for (int i = 0; i < 10; i++) {
leak_memory();
}
return 0;
}
使用 Valgrind 调试:
g++ -g -o leaky_program leaky_program.cpp
valgrind --tool=memcheck --leak-check=full --show-leak-kinds=all ./leaky_program
Valgrind 会输出类似以下信息,精准定位泄漏点:
==12345== 400 bytes in 1 blocks are definitely lost
==12345== at 0x4C2DB8F: operator new[](unsigned long)
==12345== by 0x40068E: leak_memory() (leaky_program.cpp:5)
==12345== by 0x4006B7: main (leaky_program.cpp:10)
根据提示,在 leak_memory 函数中添加 delete[] ptr; 即可修复。
希望这篇结合原理与实战的 MMU 解析,能为你解决 Linux 内核内存问题提供扎实的助力。在 云栈社区 中,我们持续分享更多底层系统与性能优化的深度内容,欢迎一起交流探讨。
 发表于 2026-2-11 08:05:22
|
查看: 281|
回复: 0
发表于 2026-2-11 08:05:22
|
查看: 281|
回复: 0
