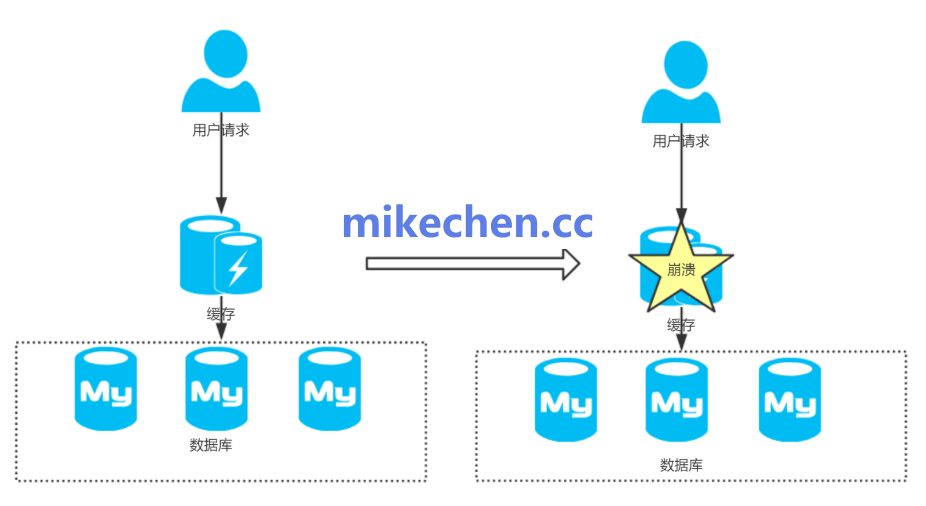
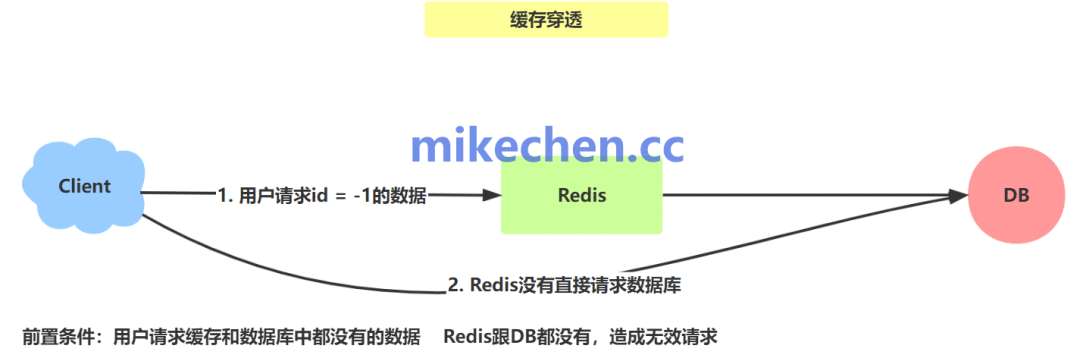
缓存穿透是指在查询一个数据库中根本不存在的数据时,由于缓存中也不存在,导致每次请求都会直接落到数据库上,从而可能压垮数据库的一种异常情况。解决此问题对维护系统高可用性至关重要。
1. 布隆过滤器:权威高效的数据存在性校验
布隆过滤器是解决缓存穿透问题最经典且高效的方法之一,尤其适用于数据量巨大、需要预先判定数据是否存在的场景。
它是一种空间效率极高的概率型数据结构。其核心原理是,将所有可能存在的数据Key,通过多个哈希函数映射到一个巨大的位图(Bit Array)中。
当一个查询请求到来时,处理流程如下:
- 首先用同样的哈希函数计算请求Key在位图中的位置。
- 如果判断为“一定不存在”:则直接返回空结果,请求不会继续访问缓存或数据库。
- 如果判断为“可能存在”:则允许请求继续向下访问Redis缓存或数据库。
优势:内存占用极低,可以拦截大量不存在的随机请求,保护后端存储。
不足:存在一定的误判率,即可能将不存在的Key判断为存在(但概率很低),且不支持删除操作。它是构建高性能缓存系统的关键组件之一,更多关于数据库与中间件的优化实践,可以参考相关专题。
2. 缓存空值:简单直接的工程化方案
这是一种简单有效的工程化解决方案。当应用层查询数据库发现某个Key确实不存在时,不直接返回空,而是将一个具有特殊意义的空值(如“NULL”、null或一个特定的默认对象)写入Redis缓存。
考虑到这类空值数据可能较多,且未来可能有真实数据被创建,通常为这些空值Key设置一个较短的过期时间(例如5-10分钟)。
优势:实现简单,能够立竿见影地拦截对同一个不存在Key的重复高并发请求。
不足:会占用Redis的内存空间来存储大量无意义的Key,如果恶意攻击的Key集合无限大,此方案效果会减弱。
3. 预热缓存:应对业务启动期的流量洪峰
此方法主要针对非恶意的、业务性的首次穿透请求,例如在新系统上线、大促活动开始等流量高峰来临之前。
核心思路是主动将预测可能被高频访问的数据,提前加载到Redis缓存中,从而在流量到来时直接命中缓存。
优势:能显著提升系统在高峰期的缓存命中率,保障服务平稳运行。
不足:依赖于准确的热点数据预测,无法防御不可预测的、恶意的随机Key攻击。
4. 认证与业务校验:最后的防线
对于明确的恶意攻击行为,除了上述缓存层方案,还应在应用层设置熔断和限流机制作为最后一道防线。
- 参数合法性校验:在API网关或业务逻辑入口,对请求参数(如用户ID、商品ID)进行格式、长度、取值范围的校验。对于明显不合法的参数,直接拦截返回。
- 请求频率限制:利用Nginx、Sentinel或Guava RateLimiter等工具,对同一用户、IP或接口在单位时间内的请求次数进行限制,超过阈值则触发限流或熔断,以保护系统核心资源。这属于运维与DevOps中保障系统稳定性的关键实践。
优势:能从请求源头遏制攻击,与缓存层方案形成互补。
不足:规则配置需要精细,过于严格可能影响正常用户体验。
综上所述,在实际项目中,通常建议组合使用多种方案。例如,对于已知的数据范围(如所有有效的商品ID),可以采用布隆过滤器进行第一层过滤;对于通过了过滤器但查询仍为空的结果,进行短时间的空值缓存;同时,在系统层面配置完善的限流降级策略,多管齐下,方能构建健壮的、可应对高并发场景的缓存体系。 |  发表于 2025-12-5 12:59:36
|
查看: 173|
回复: 0
发表于 2025-12-5 12:59:36
|
查看: 173|
回复: 0
