你肯定在电脑上编辑过文本文件,保存为 .txt 格式。把这个文件拖到浏览器里打开,就能看到里面的纯文本内容。
但这页面未免太过单调。为了让内容更丰富,我们可以定一些规则。比如在文本周围加上一对 <h1> 标签,文本就会以标题形式展示。加入 <ul> 和 <li> 标签,就能变成列表。加入 <img> 标签,还能让一段URL文本直接显示为对应的图片。

这些带尖括号的特殊符号,我们称之为标签。只要浏览器识别到这些标签,就会渲染出对应的样式。为了将这种自带标签的文本与纯文本区分开,我们给了它一个新的后缀名: html。
浏览器只要识别到文件是 .html 格式,就会解析里面的标签。这样,我们就能在浏览器中看到包含标题、输入框等丰富元素的网页了。
不过,这个 .html 文件是从我们本地电脑的文件系统中直接打开的。
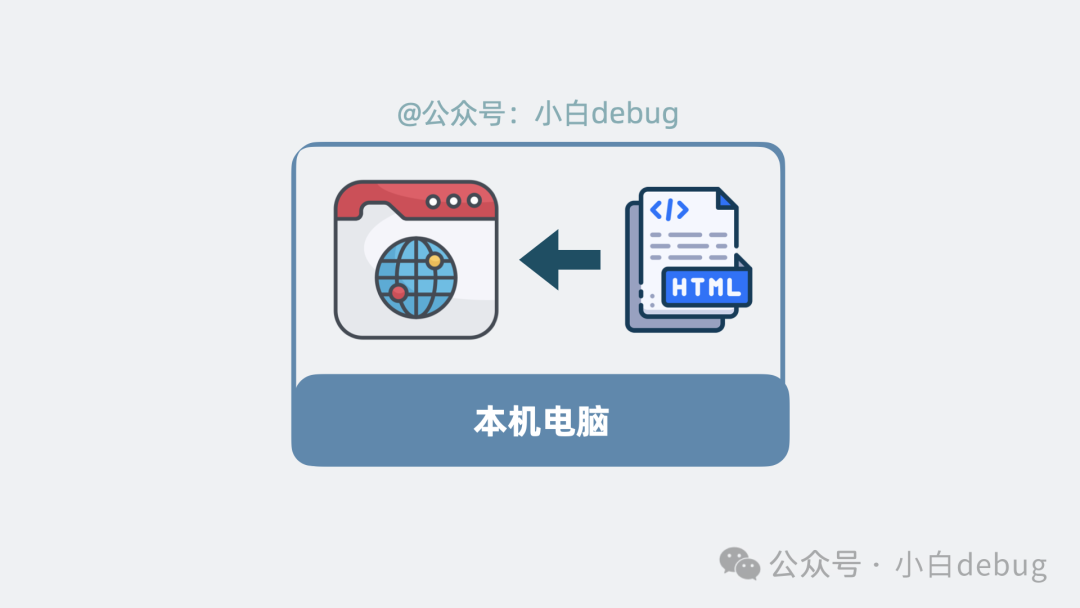
而我们平时上网访问的网页,其 .html 文件则是从某台远端服务器传送到我们电脑的浏览器,然后再打开的。
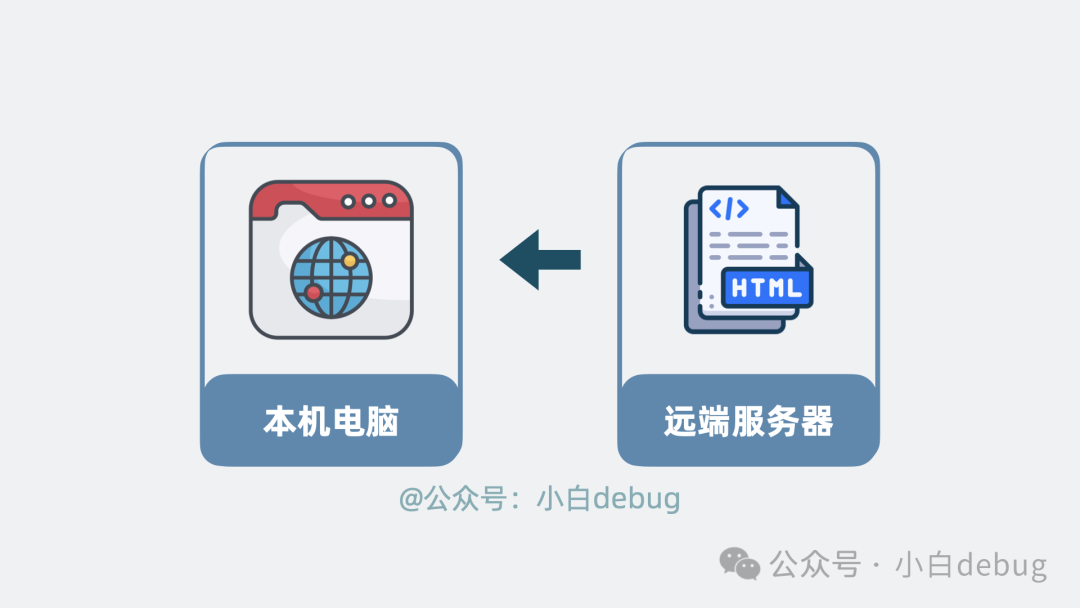
那么问题来了:我们是如何从远端服务器获取到这个 .html 文件的呢?
在软件架构领域,有一句经典的话:“没有什么是加一层中间层不能解决的,如果有,那就再加一层。” 这次我们要引入的中间层,就是 Nginx。
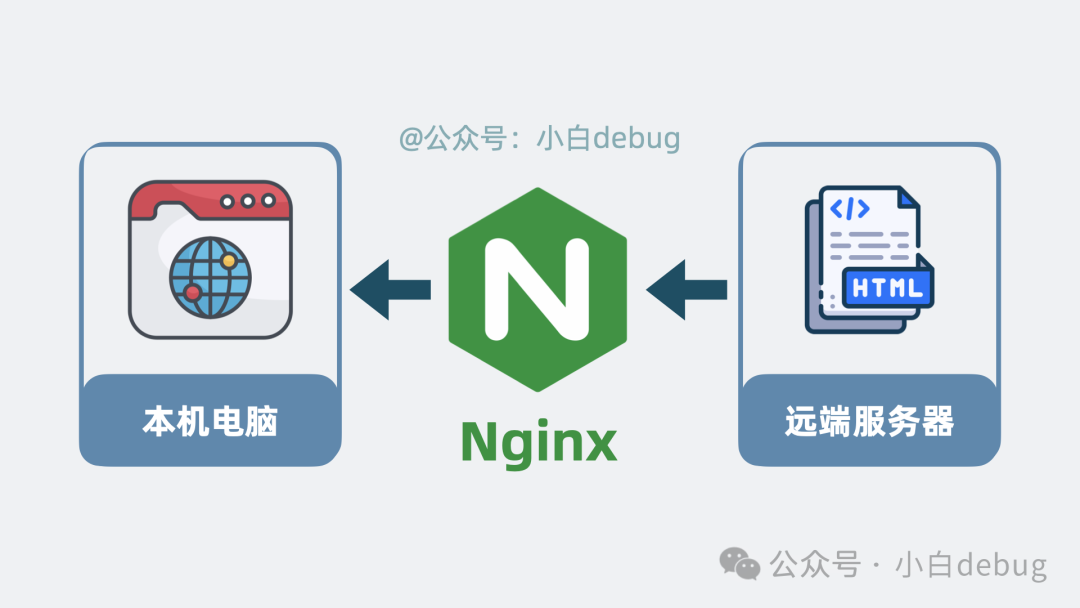
假设我们对 Nginx 一无所知,让我们来看看它是如何被一步步设计出来的。
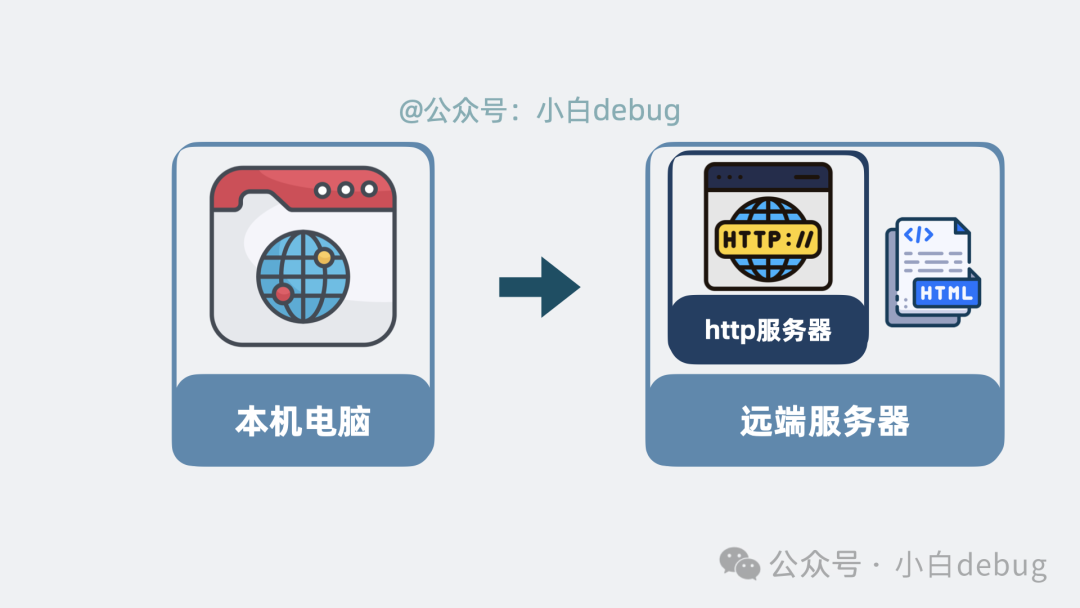
HTTP 服务器是什么?
想要让本地的浏览器获取到放在远端服务器上的 .html 文件,一个直接的方法是:在远端服务器上启动一个进程。这个进程对外提供 HTTP 服务,本质上就是提供了一个可以访问的 URL。
用户在浏览器中输入这个 URL 并回车,浏览器就会向这个进程发起 HTTP 请求。
该进程收到请求后,就将对应的 .html 文件内容发送给浏览器。浏览器收到后,完成解析和渲染,一个完整的网页就呈现出来了。
这种根据浏览器请求返回 .html 文件的服务进程,其实就是 HTTP 服务器。有了它,前端开发人员编写的各种 .html 文件就能部署到远端服务器上,对外提供网页服务了。
反向代理是什么?
但一个完整的产品通常不止有前端页面,还有后端服务。以电商平台为例,前端的商品页面需要从后端的商品服务中获取最新的商品数据。
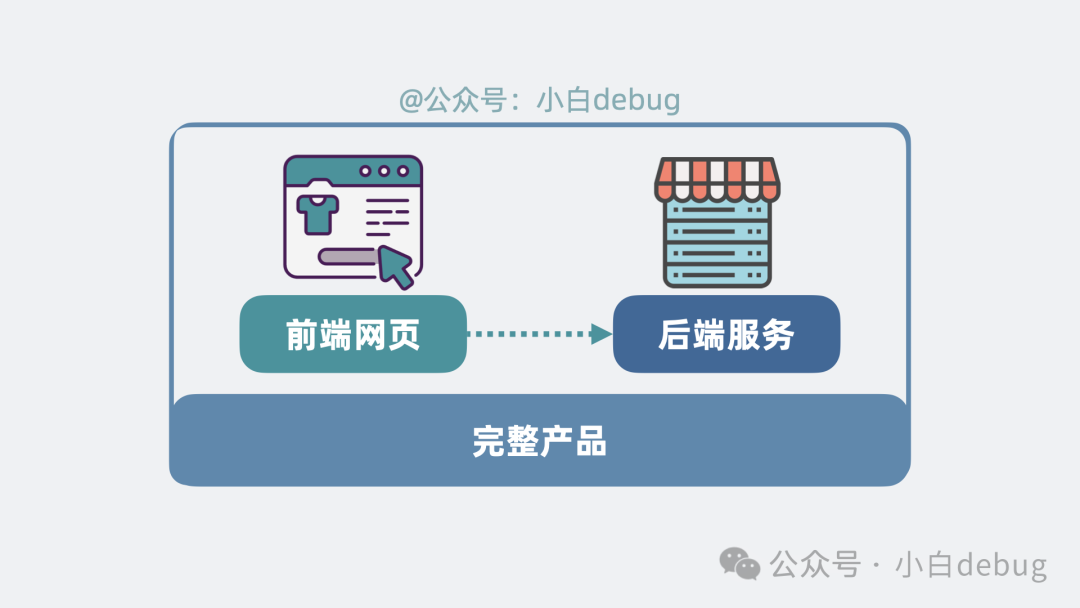
假设前端页面已经被加载到浏览器中,浏览器会根据页面代码的逻辑,向后端商品服务发起请求以获取数据。
在流量不大的时候,这没有问题。但当流量激增,单个后端服务器不堪重负时,就需要增加商品服务的实例数量。服务实例变多后,每个都有自己独立的 IP 和端口,浏览器就不知道该访问哪一个了。
因此,我们需要在这几个后端服务前面加一个进程。这个进程对外提供一个统一的 URL 域名。当请求到达时,由这个进程均匀地转发给它背后的多个服务实例,让每个实例都能分摊处理请求。这就实现了所谓的 负载均衡。
像这种对外隐藏后端具体服务器细节的代理方式,就是我们常说的反向代理。
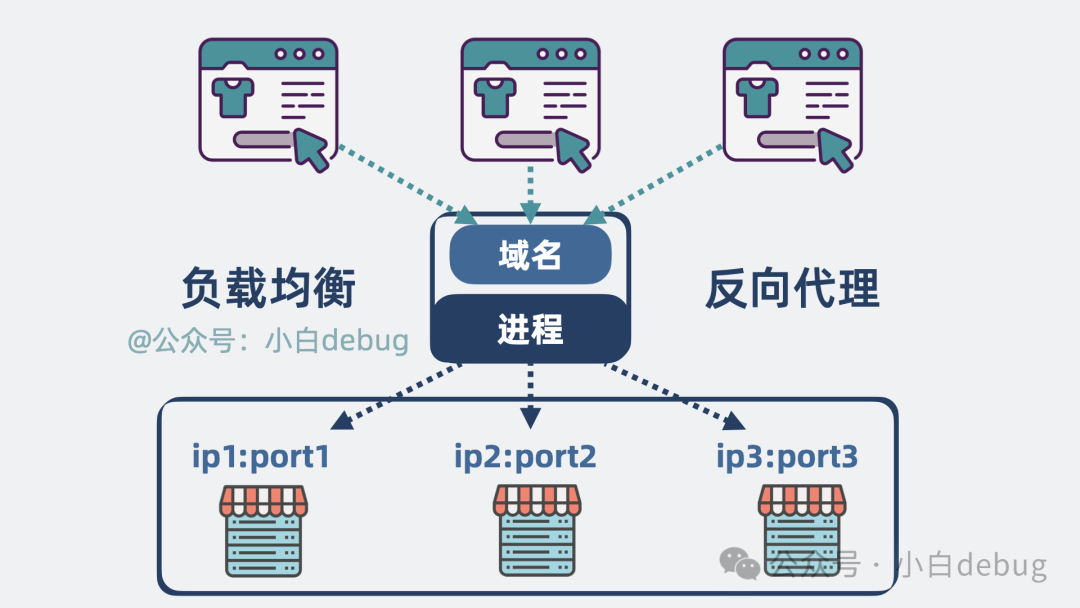
有了反向代理,对外我们就只提供一个统一的 URL 域名。后端服务可以根据实际需求,随时进行扩缩容,而前端对此无感知。
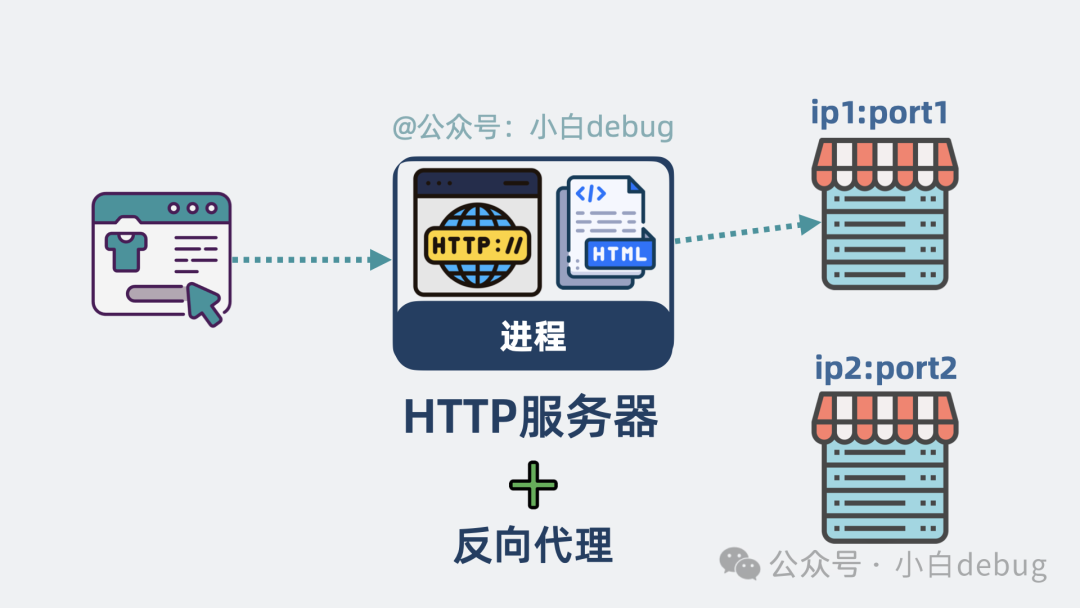
这个反向代理的功能,正好可以附加到前面那个存放 .html 文件的进程上。于是,这个进程就变得非常灵活:它既可以为前端的 .html 文件提供 HTTP 服务器的功能;当 .html 文件被加载到浏览器并向后端发起请求时,它又能为后端服务器提供反向代理的功能。
模块化网关能力
既然所有网络流量都要经过这个进程,那么它本质上已经是一个网关了。
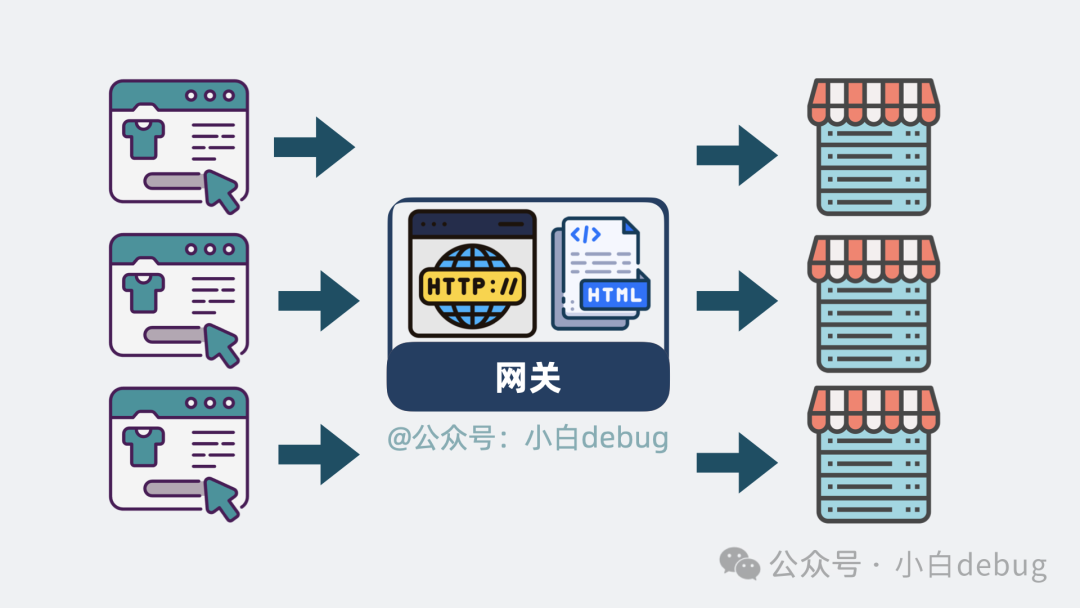
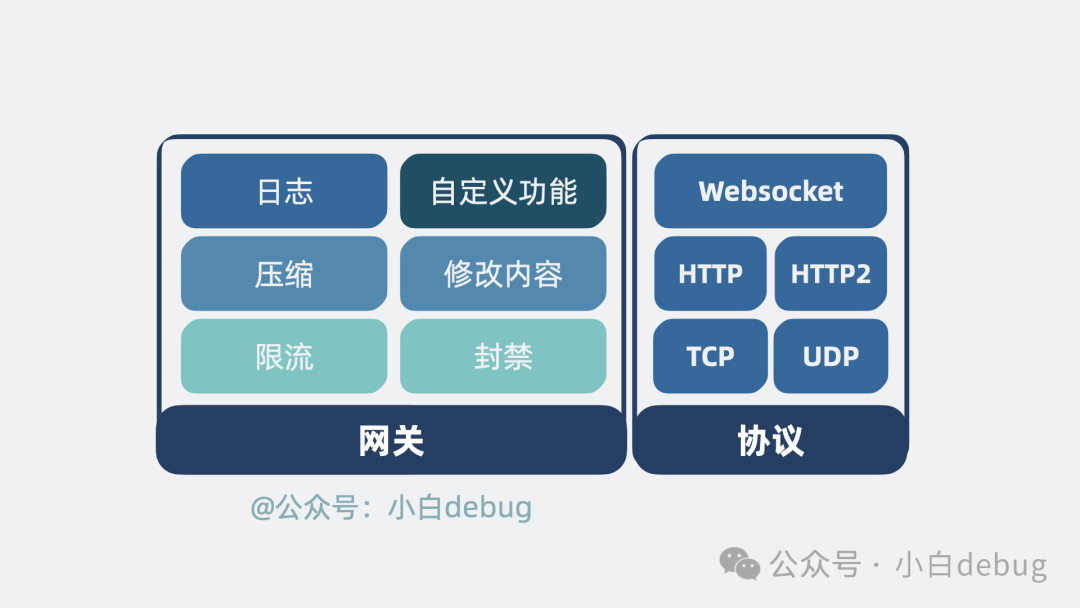
于是,我们可以顺理成章地为它增加一些通用网关能力。例如:
- 增加日志记录,方便后续排查问题。
- 增加对输入输出内容的压缩功能,以减小网络带宽消耗。
- 对特定 IP 进行限流或封禁。
- 甚至修改输入输出的内容。
能实现的功能实在太多,想象空间巨大。因此,我们将这部分功能设计为开放接口,允许用户通过自定义模块来实现特定功能。
这还不够。目前这个网关只支持 HTTP 协议。我们还可以扩展一下,让它支持 TCP、UDP、HTTP/2 和 WebSocket 等协议。你能想到的,它最好都支持;它原本不支持的,也自然会有人通过自定义模块来实现支持。
配置能力
前面提到了那么多种能力,用户肯定不会全用上。所以,我们需要一个地方让用户选择启用哪些功能。于是,我们可以引入一个配置文件,也就是 nginx.conf。用户想用什么能力,就在这个配置文件里声明清楚,非常方便。

单线程设计
现在,这个网关进程的主要任务是与上下游(客户端和服务器)建立网络连接,并在内部进行一些处理。
如果有多个客户端请求通过网络同时进入一个进程,若采用多线程并发处理,就需要考虑线程安全问题,同时线程切换也会带来性能开销。怎么解决这个问题呢?
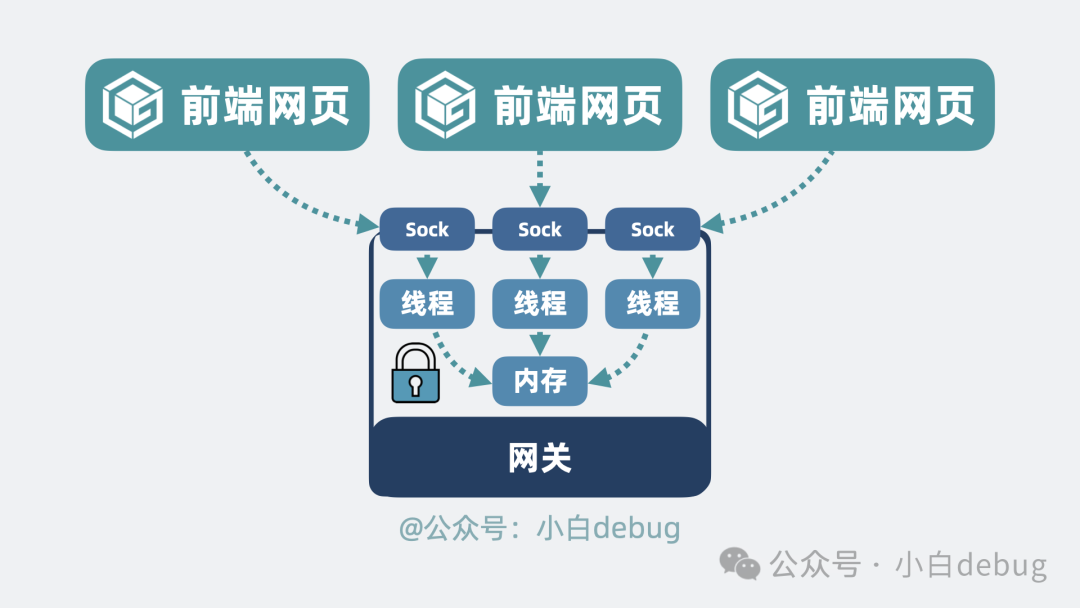
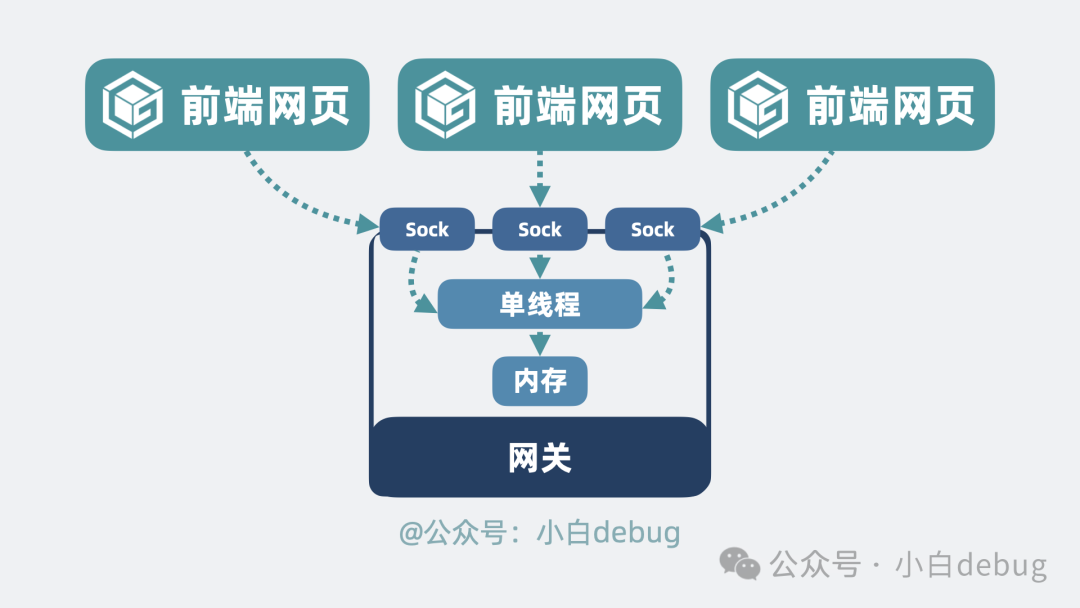
很简单!不管外部有多少个网络连接,网关进程在收到客户端请求后,都统一放到一个线程上进行处理。在一个线程内处理所有客户端请求,什么并发问题和线程切换开销,完全不存在!
多 worker 进程
但是,单个进程用单线程处理海量流量,即便再高效,压力也非常大。万一处理速度慢了,用户体验就会变差。
怎么办呢?既然多线程不行,那我们就采用多进程。
于是,我们可以将单个进程扩展为多个进程,我们管它们叫 worker 进程。进程之间相互独立,一个 worker 进程崩溃了,不会影响到其他 worker 进程。
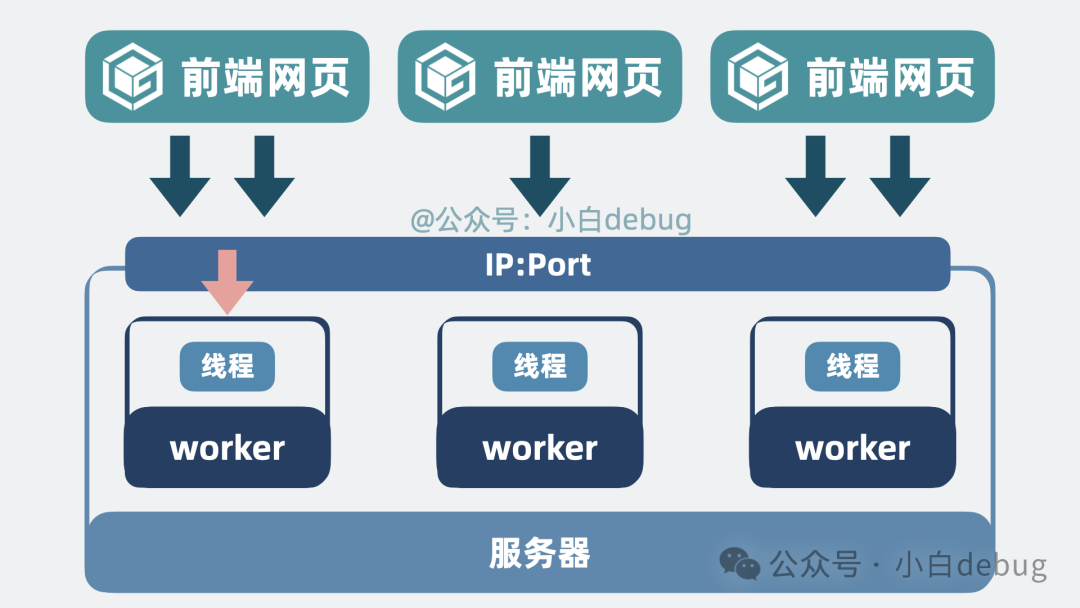
让多个 worker 进程同时监听同一个 IP 地址和端口。一旦有流量进入,操作系统内核会通过某种机制(如 SO_REUSEPORT)将连接分配给其中一个 worker 进程处理。将worker 进程的数量设置为与操作系统CPU 核数一致,这样每个进程都能独占一个 CPU 核心,全力处理请求。

思考题: 为什么多个进程可以同时监听同一个端口而不会出现“端口已被占用”的错误?这背后的机制是什么?
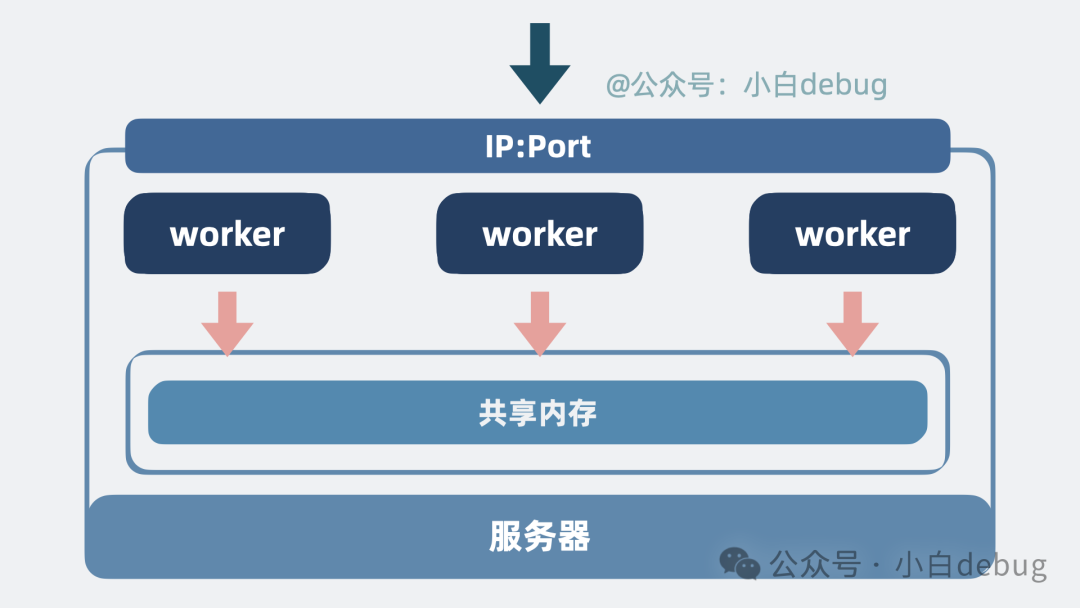
共享内存
在多 worker 进程的架构下,同一个客户端的多个请求可能会被随机分配到不同的 worker 上。对于像“限流”这样需要统计请求次数的场景,计数会被分散到各个 worker 进程中单独进行,这就无法实现全局准确的限流。
因此,需要为这些 worker 进程分配一块共享内存区域,方便多个进程之间共享同一份数据,从而确保系统逻辑的一致性。
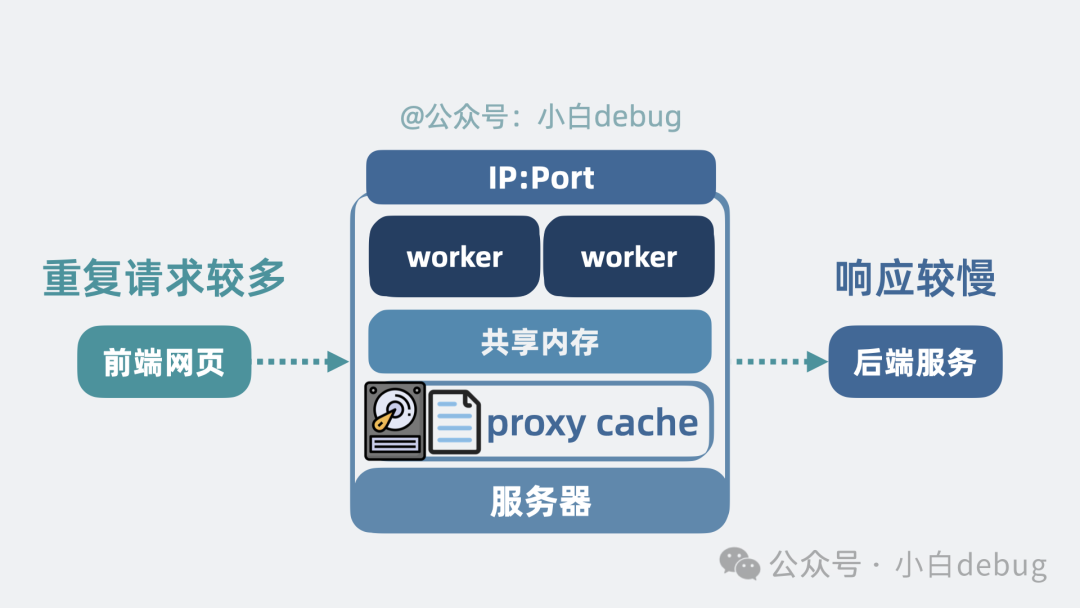
Proxy Cache(代理缓存)
作为网关,它在收到前端网页的请求后,会转发给后端,并将后端的处理结果返回给前端。如果它能将后端响应的结果缓存起来,那么下次收到相同的请求时,就可以直接将缓存的数据返回给前端,从而显著减少响应时间和后端负载。
那么,这些缓存数据放在共享内存里吗?内存成本较高,不太合适。我们可以维护一些磁盘文件,用于暂存后端的响应结果。当后续有相同请求到达时,直接从磁盘读取数据返回。
这又是经典的 “空间换时间” 策略:用廉价的磁盘空间,换取网络传输和后端计算的耗时。对于后端响应较慢或重复请求较多的场景,读写磁盘总比直接将请求打到后端要快得多。这些用于缓存响应数据的磁盘文件,就是所谓的 proxy cache。
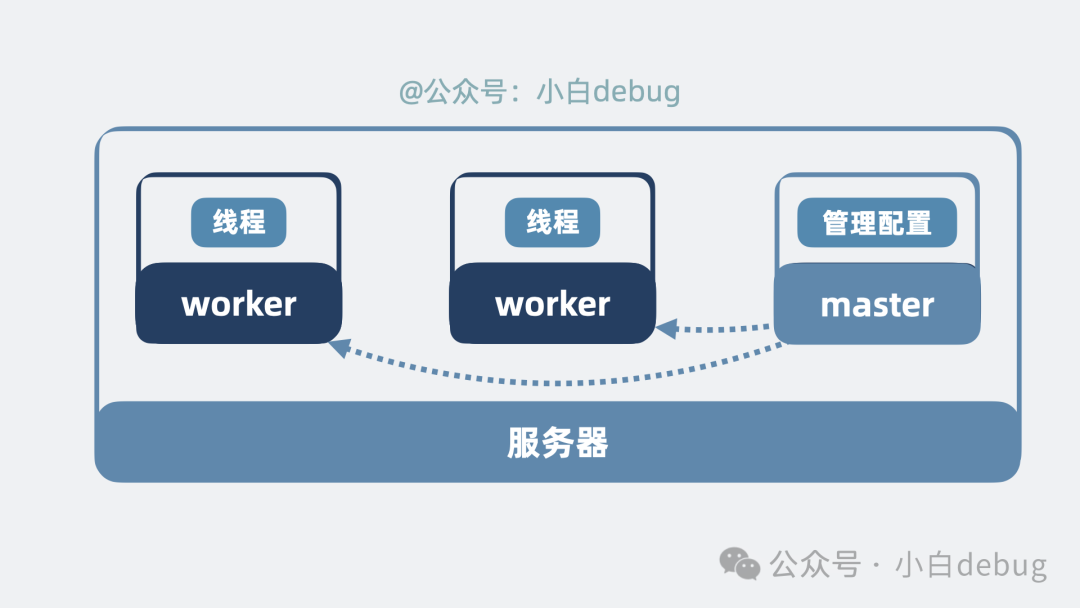
引入 Master 进程
但这还不够。现在每个 worker 都会分担一部分流量。如果需要更新功能,所有 worker 同时重启,其上的网络连接就会全部中断。
更好的方式是:创建新 worker 和关闭旧 worker 的过程逐个、依次进行(即滚动升级)。这样,即使某个 worker 重启导致连接断开,客户端还可以连接到其他正在运行的 worker,从而保证服务在任意时刻都可用。
因此,我们需要一个新的进程来协调各个 worker 的启动、关闭和重载等操作。这个协调进程,就是所谓的 master 进程。让 master 进程读取前面提到的 nginx.conf 配置文件,并统一管理多个 worker 进程的生命周期。
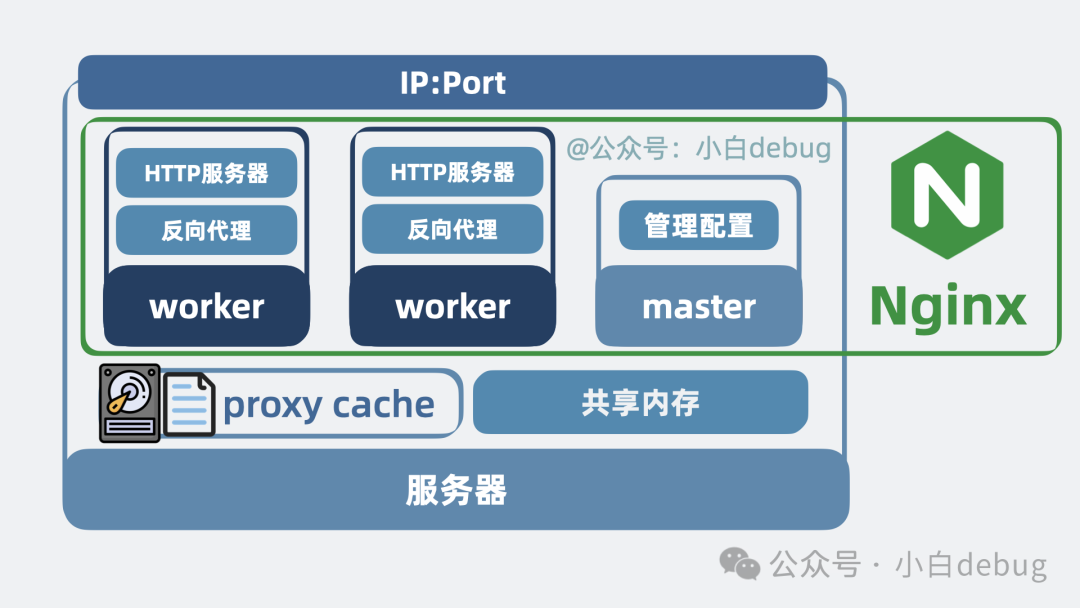
Nginx 是什么?
好啦,到这里,当初那个简陋的单进程网关服务,已经演变成了一个:
- 支持通过动态配置文件启用多种通用网关能力和多种网络协议。
- 采用单 master、多 worker 的架构。
- 多个 worker 进程之间可以共享内存和使用 proxy cache。
- 对外提供一个统一的 IP 和端口。
- 同时支持 HTTP 服务器和反向代理功能的高性能网关服务。
它,就是 Nginx。
Nginx 不仅原生支持日志、限流、压缩等各种通用能力,还支持通过模块扩展自定义功能。只要你写好配置,它就能高效地为你工作。在性能上,达到每秒数万请求(QPS)非常轻松,应对大多数 Web 服务的流量绰绰有余。
现在,你是否对 Nginx 的架构有了更清晰的理解?当然,技术的探讨是永无止境的。在 云栈社区,有更多关于系统架构、高并发和 运维 的深度讨论,欢迎你来一起交流学习。
最后,遗留一个问题:想必你也发现了,到目前为止,Nginx 本身也只是运行在某台服务器上的一组进程。一旦这台服务器宕机,Nginx 服务也就不可用了,这依然存在 单点问题。
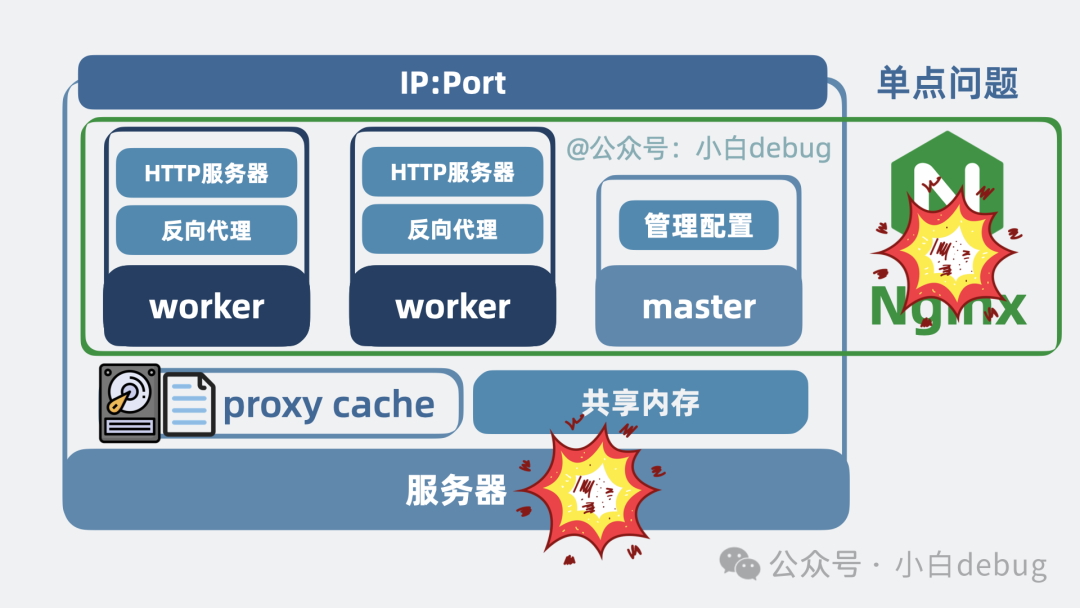
那么,如何解决 Nginx 的单点问题呢?Nginx 本身有集群模式吗? 这是一个值得深入思考和实践的运维架构课题。
 发表于 2026-2-11 14:16:11
|
查看: 153|
回复: 0
发表于 2026-2-11 14:16:11
|
查看: 153|
回复: 0
