如果说2025年之前的AI文生图模型是在比拼谁画得更像“艺术家”,那么进入2026年,这场竞赛的维度已经彻底变了——现在,行业比拼的是谁更像一个合格的“乙方”。
这并非玩笑。在过去很长一段时间里,AI图片模型更像是一个才华横溢但难以沟通的画家:你让它画“一只猫”,它能给你一千种惊艳的方案;但如果你要求它“画一张海报,标题要在正中间,副标题用黑体,左下角放个二维码”,它往往会给你交出一堆乱码和错误的构图。
这种 “不可控” 和 “文盲” 属性,让AI生图始终停留在“抽盲盒”的玩乐阶段,迟迟无法真正嵌入到PPT制作、UI设计、电商运营等严肃的 工业生产流 中。
2月10日,随着阿里云 Qwen-Image-2.0 的发布,这个卡在“玩具”与“工具”之间的瓶颈被狠狠撬开了一道缝隙。

不同于以往模型单纯追求光影和分辨率的提升,Qwen-Image-2.0做了一件极具“工程师思维”的事:它不仅要把图画好看,更要把图里的 信息 写对。它试图解决的是一个长期困扰业界的难题:如何让基于概率生成的像素,能够承载精确的逻辑和文字?
在今天的发布演示中,我没看到那些虚无缥缈的艺术画作,反而看到了一张张充满了图表、数据、长段中文文案甚至《兰亭集序》书法的“硬核图片”。这标志着通义千问团队正在试图重新定义视觉生成模型的标准——不只是Visual(视觉),更是Vision(视野);不只是生成像素,更是生成可用的 结构化信息。
这让人眼前一亮,因为行业内一直弥漫着一种隐性的焦虑:如果AI只能画出漂亮的二次元人物或者赛博朋克街道,却连一张带文字的PPT都排不明白,那它究竟是生产力工具,还是昂贵的电子玩具?Qwen-Image-2.0的发布,似乎就是为了回应这种焦虑。
这是一场关于 “像素” 与 “信息” 的博弈。
告别“文盲”时代:当像素开始承载逻辑
在很长一段时间里,AI生图模型都是“文盲”。你让它画“一家叫Coffee的咖啡店”,它可能会给你画出Caffee、Covfefe甚至一堆乱码。这可能是因为text encoder(文本编码器)和visual decoder(视觉解码器)之间存在着天然的鸿沟。
但在Qwen-Image-2.0的演示中,我们看到了一个令人咋舌的案例:一张由AI全自动生成的AB Testing结果汇报PPT。

这不仅仅是“把字写对”那么简单。如果你仔细看这张图,你会发现它包含了 “准、多、齐” 三个维度的工程突破:
- 准:文字没有乱码,且逻辑对应(比如“控制组”和“实验组”的数据对比)。
- 多:支持1K Token的超长上下文输入,意味着你可以在一张图里塞进海量的信息。
- 齐:AI居然学会了对齐。左边的ROI数据和右边的转化率图表,在视觉上保持了极其工整的栅格系统。
Qwen视觉生成负责人吴晨飞解释,Qwen-Image-2.0的强大并非孤立存在,它深度依赖于Qwen语言模型(LLM)对语义的极度敏感。当我们在Prompt里写下“字号稍小一点”、“位于中心文字正上方”时,底层的LLM精准捕捉了这些空间指令,并将其翻译给了视觉生成模块。
“我们发现,当模型能把几百字的《兰亭集序》都写对时,它对画面的理解力也发生了质变。” 吴晨飞在现场展示了那张几乎“炫技”般的书法配图。

这标志着AI生图正在跨越一个临界点:图片不再仅仅是视觉审美的载体,开始成为高密度信息的容器。 从这一刻起,生成一张图,约等于生成了一份文档。
打破“生图”与“编辑”的次元壁
在大模型的上一代版本(如Qwen-Image-1.0或其他竞品)中,我们面临着一个割裂的工作流:
- 用生图模型(Text-to-Image)抽卡,直到抽出一张满意的底图。
- 把图导出来,扔进另一个编辑模型(Inpainting/Editing)里修修补补。
这两条线是平行的,也是痛苦的。生图模型不懂编辑的逻辑,编辑模型往往画质不如生图模型。
Qwen-Image-2.0做了一个极为大胆的架构调整:将“生图”和“编辑”两条技术栈强行合并。 “我们在探索中发现,分开做虽然容易,但合在一起做才能实现1+1>2。” 吴晨飞说道。
为什么要合?因为 “编辑”本质上是一种带有强约束的“生图”。当你要求AI“把这只猫换成狗”时,模型不仅要理解“狗”是什么,还要理解原图中猫的光影、透视和毛发质感。通过在同一个模型权重里同时训练这两类任务,Qwen-Image-2.0获得了一种 “全局一致性” 的能力。

这种合二为一带来的红利是肉眼可见的。现场邀请的嘉宾,WPS AI PPT的产品经理罗淑敏提到,用户在做PPT时,最大的痛点不是生成图片,而是 “微调”。以前的AI生成了图片,如果上面的文字错了,或者logo位置不对,用户只能重新生成,然后就会得到一张完全不同的新图。
而现在,基于Qwen-Image-2.0的能力,用户可以指着图上的某一行字说:“把这个日期改成2026年。”模型会在保持背景、字体、颜色完全不变的情况下,只修改那几个像素。这才是工业级应用该有的样子。它不再是一次性的“盲盒”,而是可控的“泥塑”。
设计师的终极拷问:AI何时能吐出图层?
在发布会的后半程,气氛被一位特殊的嘉宾推向了高潮——头部AIGC设计师石恕之。作为AI技术的“甲方”,石老师没有客气,直接在屏幕上打出了四个大字,那是所有设计师的终极梦想,也是目前AI生图领域的“圣杯”:
“图层分离!”

目前的AI生图(如左图的模特展示)虽然精美,但对于工业流程来说是一张“死图”。设计师石恕之提出的“图层分离”需求,即希望AI能直接输出包含背景层、人物层、服装层、文字层的可编辑文件(类似PSD),这将是AIGC彻底颠覆设计行业的最后一公里。
对于设计师来说,一张合成了所有像素的JPG图片,在后期制作中几乎是废品。如果客户说“把模特的衣服换个颜色”或者“把背景里的树移走”,设计师需要耗费大量时间去抠图、补背景。
针对这个犀利的问题,吴晨飞没有回避。“我们去年底发布的Qwen-Image-Layered其实就是一次‘井底之蛙’的尝试,我们踮起脚尖看了一眼那个未来。”他坦承,目前的Qwen-Image-2.0虽然做到了生图和编辑的统一,但距离 “原生分层生成” 还有距离。但这恰恰是此次架构升级的伏笔。
既然模型已经具备了极强的 “局部重绘” 和 “语义理解” 能力,那么通过Prompt控制模型分别生成背景、主体和前景,并在latent space(潜在空间)里保持一致性,理论上是完全可行的。“未来,图像分层任务完全有机会成为基础模型能力的一部分。这不仅是输出多张图的问题,而是模型在生成的那一瞬间,脑子里就已经把世界拆解成了图层。”
AIGC正在经历一场“工业化”的大考
除了功能上的硬核突破,Qwen-Image-2.0在 “美学” 上也做了一次去魅。前两年的AI绘图,普遍带有一种浓重的“塑料感”或“油腻感”。皮肤光滑得像陶瓷,光影完美得像渲染图。这在朋友圈发发还可以,但放在高端广告或电影海报里,就显得廉价。
Qwen-Image-2.0引入了更高级的 “真实感训练”。

模型在处理高真实感人像时,不再追求过度的磨皮美白,而是能够精准还原皮肤的纹理、皱纹的深度以及毛孔的质感。这种“不完美”的真实,恰恰是摄影级质感的精髓。这背后其实是模型对物理世界光线传输规律的更深层理解。它不再是简单地堆砌像素,而是在模拟光子如何打在皮肤上,如何穿过树叶,如何在玻璃上反射。
这一系列突破,让人不禁发问:这波AI浪潮,究竟是由模型驱动,还是由应用驱动?Qwen团队给出的答案非常务实,他们不仅是在造模型,更是在应对一场 “工业级” 的压力测试。与实验室里的Benchmark不同,现实商业世界对AI的要求是残酷的。以阿里的电商场景为例,每天可能有数百万个新商品上架,每一个都需要主图、详情页、营销海报。在这种海量、高并发、且直接关联GMV(交易总额)的业务场景中,AI不能只是一个“抽卡游戏”。
它必须具备 “确定性”。商家不能接受AI生成的海报里文字是乱码,也不能接受微调一个背景导致商品主体变形。正是这种对 良品率 和 可控性 的极致追求,倒逼了Qwen-Image-2.0的技术演进:
- 为了解决海报制作痛点,必须攻克 复杂文字渲染;
- 为了解决广告图修改痛点,必须实现 生图编辑一体化;
- 为了满足专业设计流,必须探索 图层分离。
这标志着AIGC正在从“作坊式”的尝鲜阶段,正式迈入 “流水线” 的工业化阶段。在这个阶段,技术的价值不再仅仅取决于它能画出多么惊艳的单图,而在于它能否像电力一样,稳定、精准、低成本地接入到WPS、淘宝、千问APP这些国民级应用的后台,成为支撑数字经济运转的 基础设施。 “准、多、齐” ,这三个朴素的字眼背后,实际上是AI模型向工业标准的一次集体看齐。
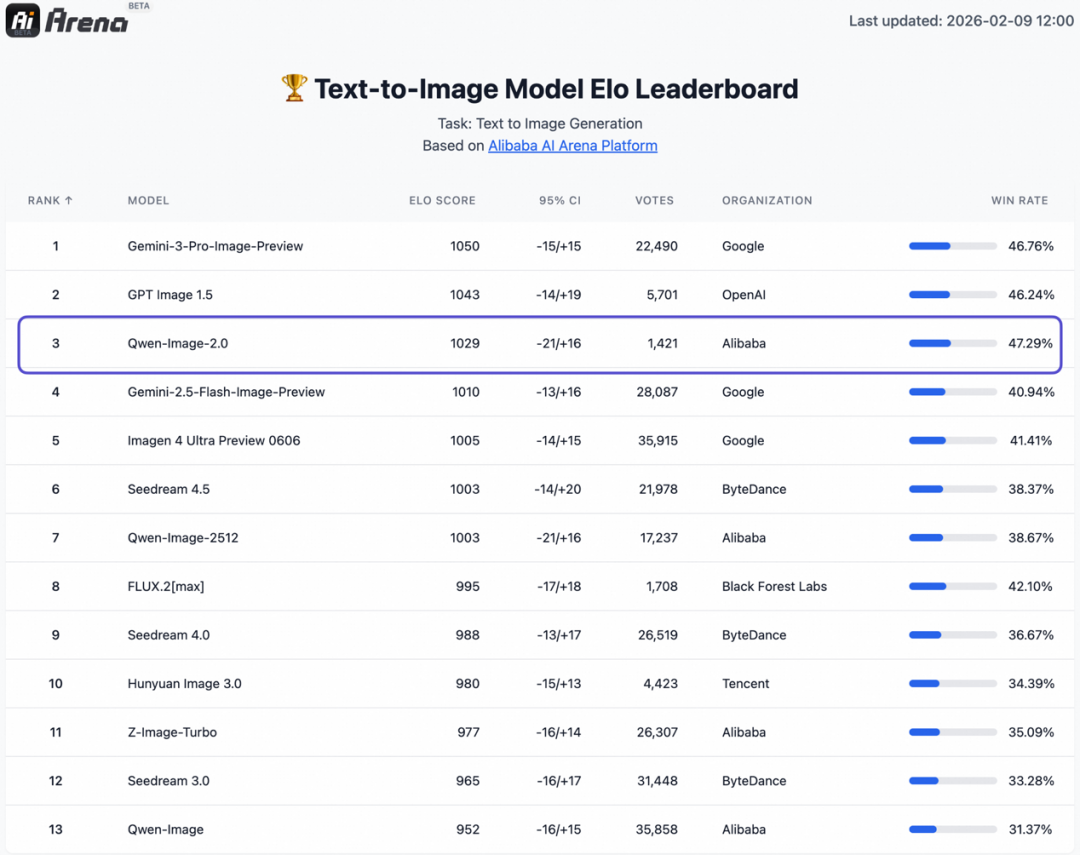
在最新的AI Arena权威评测中,Qwen-Image-2.0以1029的Elo分数位列全球第三,紧随GPT Image 1.5和Google的旗舰模型之后。这一成绩不仅验证了其架构的先进性,更表明经过海量业务场景打磨的模型,在通用能力和鲁棒性上已经具备了世界级的竞争力。
AI不再是一个高高在上的艺术家,它正在变成一个随叫随到的美工、排版师和摄影助理。它能听懂你关于“字号再小一点”的碎碎念,也能理解你对“五彩斑斓的黑”的无理要求,甚至能帮你搞定那个令人头秃的AB Test汇报PPT。
当AI开始能够处理复杂的排版,开始思考图层的逻辑,开始在意像素级的真实感时,我们离那个“人人都是超级个体”的时代,才算真正近了一步。而这一切,可能就始于这一行行被AI准确渲染出来的汉字,始于这一张张可以被无限编辑的图片。
据了解,阿里云百炼上已开通API邀测,开发者也可通过Qwen Chat免费体验新模型。技术的演进最终服务于实际需求,关于AIGC工业化落地的更多深度讨论,也欢迎在云栈社区的智能与数据板块继续交流。

 发表于 2026-2-11 15:40:34
|
查看: 187|
回复: 0
发表于 2026-2-11 15:40:34
|
查看: 187|
回复: 0
