用 Claude Code 进行 AI 辅助编程已经快一年了,我的工作模式也经历了从“对话式编程”到“全自动流水线”的进化。在这个过程中,我逐渐沉淀出了一套能够稳定运行的工作流。今天就来分享一下我日常高频使用的自定义指令(Slash Commands)、一些好用的 Skills,以及 Claude Code 生态里那些值得你关注的项目,希望能为同样在探索 AI 编程的伙伴们提供一些参考。
我目前同时维护着三个活跃项目,技术栈和部署环境各不相同:
- 训练营押金退款系统——基于知识星球训练营的全栈业务系统,包含报名、支付、打卡、退款等模块。
- code80 AI编程巴士——一个旨在帮助 AI 编程爱好者快速上手的工具平台。
- 个人网站和内容系统——用于管理博客、公众号等内容的平台。
面对不同的技术栈和开发节奏,如果没有一套标准化的工作流,光是处理 Git 提交和多环境部署就足以让人崩溃。为此,我在每个项目的 .claude/commands/ 目录下都维护了一组自定义指令。Claude Code 会自动识别这些 Markdown 文件,我只需要输入 /指令名 就能触发相应的自动化流程。
/commit:一条命令搞定智能提交与推送
这是我使用频率最高的指令,几乎每次完成编码后都会用到它。
它能做什么?
输入 /commit 后,Claude 会自动执行以下操作:
- 运行
git status 和 git diff 来分析所有代码变更。
- 智能判断提交类型(例如是
feat 新功能还是 fix 修复),并确定影响范围(如 backend后端、h5移动端或 admin管理后台)。
- 生成符合 Conventional Commits 规范的提交信息。
- 依次执行
git add、git commit 和 git push 完成提交与推送。
指令背后的核心逻辑
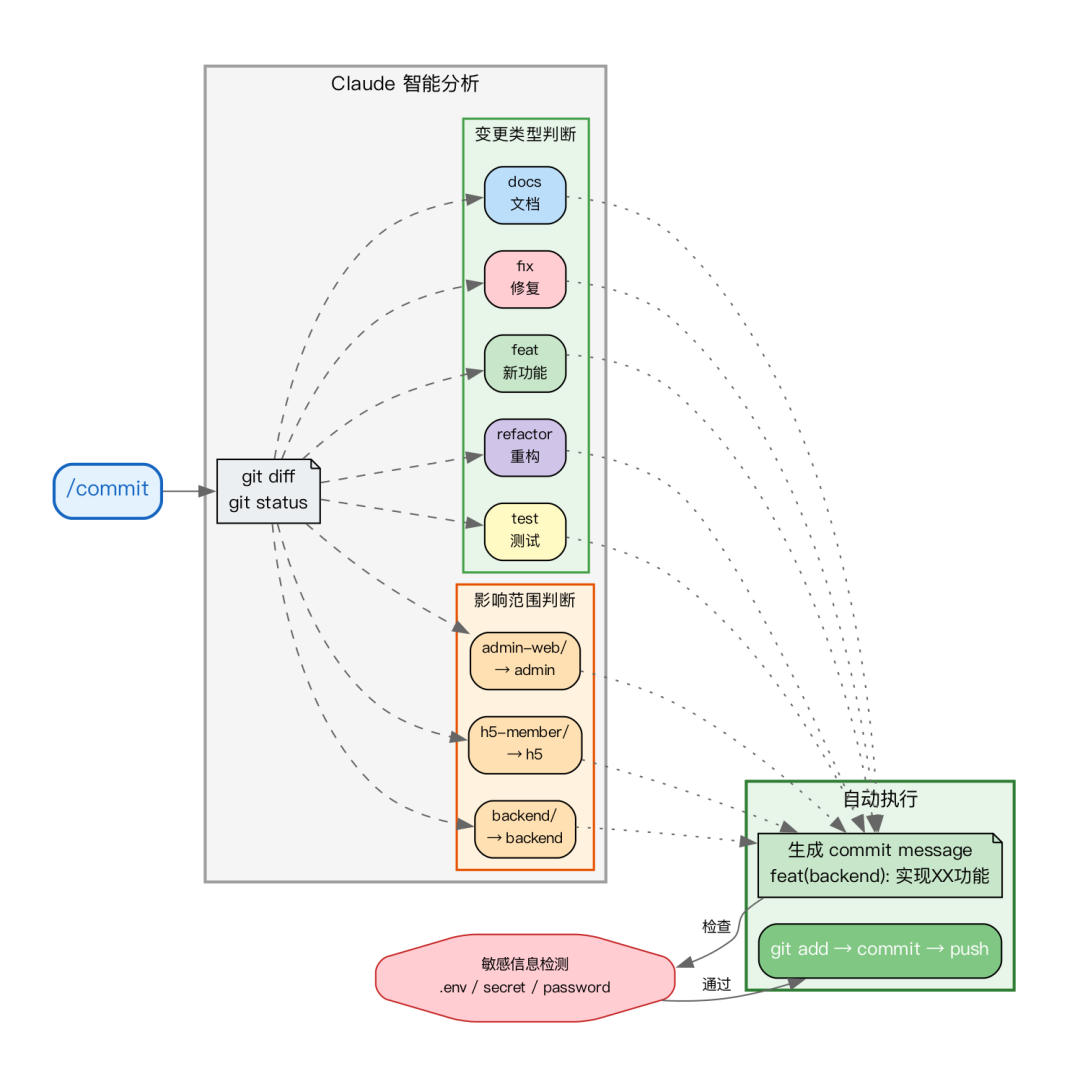
在这个指令的 Markdown 文件中,我定义了两套核心规则:变更类型判断(新增文件→feat、修复bug→fix、修改文档→docs等)和影响范围判断(根据文件路径映射到对应的模块)。Claude 会读取这些规则,并据此分析 git diff 的输出结果进行自动匹配。
实际效果演示
例如,当我修复了一个 OAuth 认证的 Bug 后,只需输入 /commit。Claude 分析后可能会生成如下提交信息:
fix(backend): 修复OAuth state被多用户共享导致“授权已失效”错误
- 为 OAuth 重定向添加 Cache-Control 头,防止 302 缓存导致 state 复用
- 修改 OAuth 回调错误处理:重定向到干净的首页 URL,由路由守卫自动重试
这比我手动写的提交信息更加规范。关键在于,它能清晰地阐明“为什么修改”,而不是仅仅罗列修改了哪些文件。
内置的防护机制
指令中还内置了敏感信息检测。如果暂存区中存在 .env、application-prod.yml 或文件名包含 secret、password 等关键词的文件,Claude 会弹出警告。这项功能在团队协作开发中尤为重要。
/progress-save 与 /progress-load:实现开发上下文的无缝接力
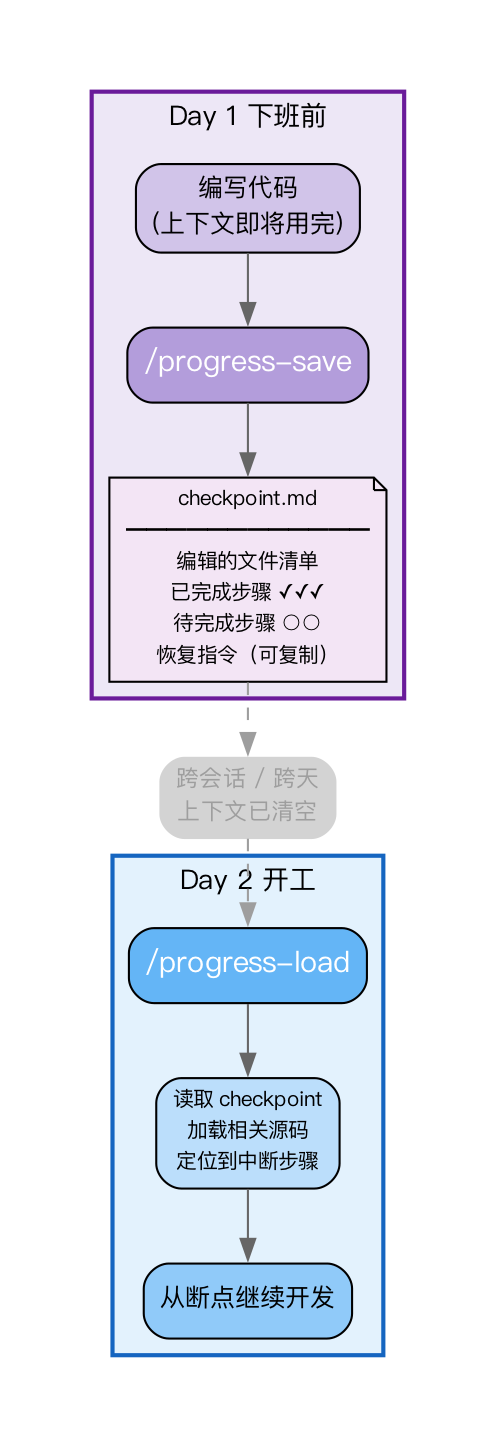
Claude Code 拥有 200K tokens 的上下文窗口,看似很大,但在进行复杂功能开发时,来回读取文件、修改代码、运行测试,上下文很快就会被耗尽,这时就需要使用 /compact 来压缩上下文。
问题在于,压缩后 Claude 会丢失一些关键的细节。更棘手的情况是第二天接着开发——全新的会话让 Claude 完全忘记了昨天的进度。虽然有 claude-mem 这类工具,但有时我们希望更主动地全局把控项目进度。
/progress-save 保存检查点
/progress-save “完成退款导出功能的后端部分”
执行后,Claude 会自动在 docs/progress/checkpoints/ 目录下生成一个结构化的检查点文件。该文件包含四部分信息:当前 Git 状态、正在编辑的文件清单、已完成/待完成的步骤列表,以及一段可直接复制的恢复指令,用于让新会话快速接上之前的进度。
/progress-load 恢复上下文
第二天开工时,只需输入:
/progress-load checkpoint-20260210-143000
Claude 便会读取指定的检查点文件,自动加载相关的源代码文件,并从上次中断的步骤继续开发。
我将这个流程固化成了一个习惯:每天下班前执行 /progress-save,每天开工后执行 /progress-load。这远比在脑子里模糊地回忆“昨天做到哪了”要可靠得多。
/deploy:实现零停机的一键多服务器部署
部署流程是我投入大量时间进行打磨的环节。我的训练营系统部署在两台生产服务器上,而 code80 项目则部署在另一台。以往手动执行构建、SCP上传、SSH重启等操作,不仅繁琐,还容易出错。
一条命令应对所有场景
现在,我通过一个脚本和自定义指令来统一管理:
./scripts/deploy/deploy-prod.sh # 构建并部署到所有服务器
./scripts/deploy/deploy-prod.sh --skip-build # 跳过构建,直接部署
./scripts/deploy/deploy-prod.sh --only camp # 仅部署到指定服务器
./scripts/deploy/deploy-prod.sh --rollback # 回滚到上一版本
./scripts/deploy/deploy-prod.sh --status # 查看所有服务器状态
四阶段标准化流水线
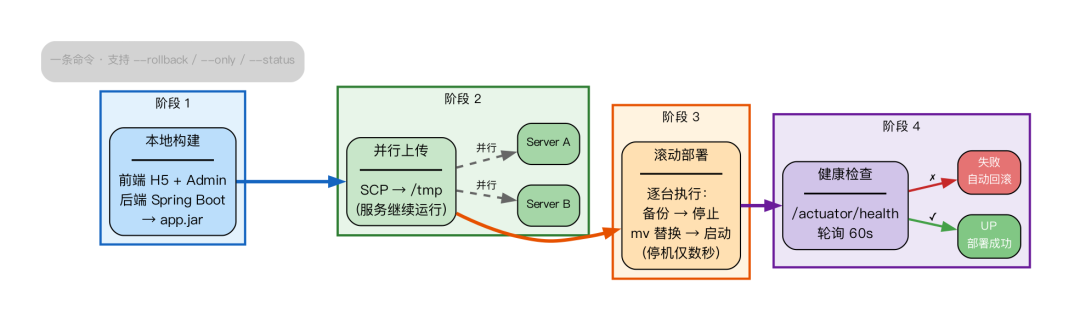
整个部署过程被分解为四个清晰的阶段:
阶段 1:本地构建。调用 build-all.sh 编译前端(H5 + Admin)和后端Spring Boot,最终打包成一个包含所有静态资源的 JAR 文件。
阶段 2:并行上传。使用 SCP 将 JAR 包同时上传到所有目标服务器的 /tmp 临时目录。这一步是并行执行的,上传期间线上服务正常运行,用户无感知。
阶段 3:滚动部署。逐台服务器执行:备份当前版本、停止服务、原子替换文件(mv)、启动服务、进行健康检查。真正的服务中断时间仅有 systemctl stop 到 systemctl start 之间的几秒钟。
阶段 4:健康检查与自动回滚。调用 Spring Boot Actuator 的 /actuator/health 端点进行健康检查,最长等待60秒,每3秒轮询一次。
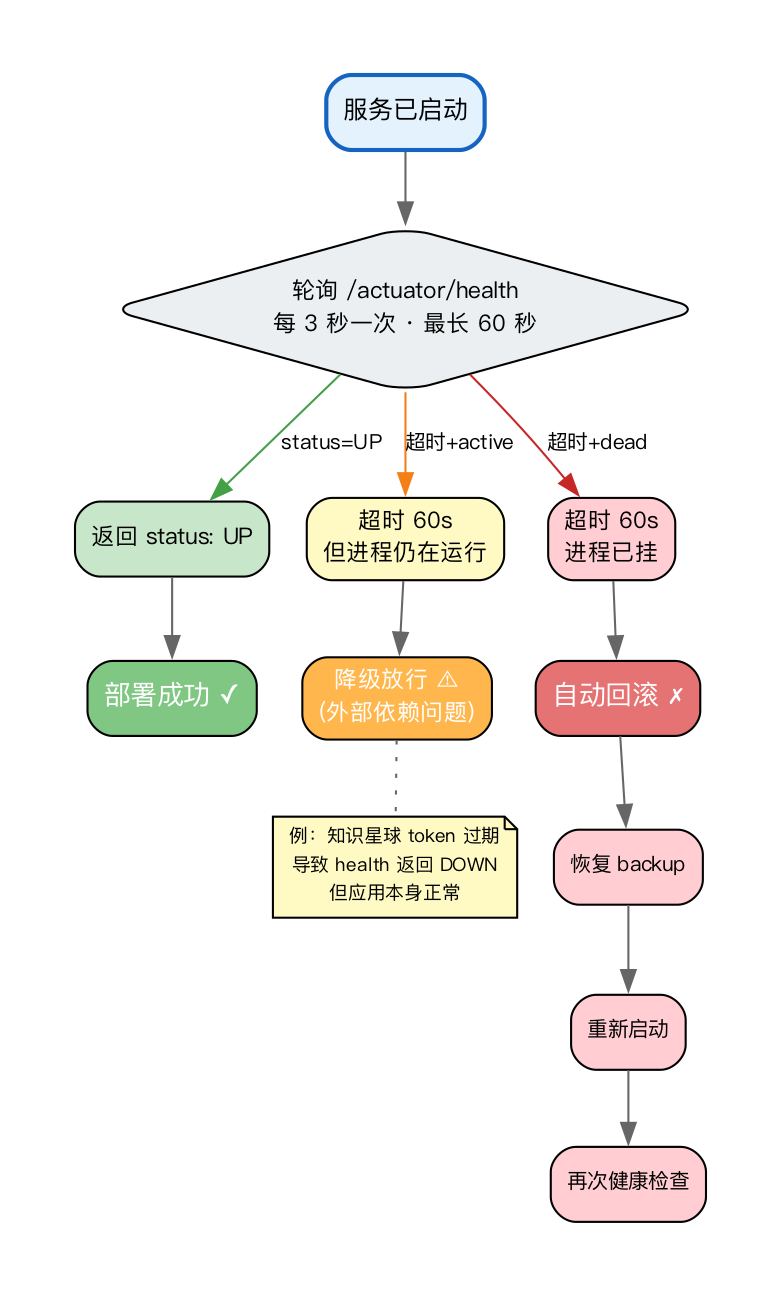
健康检查有一个值得注意的细节:我的系统依赖外部知识星球 API,当其 token 过期时,健康检查接口会返回 DOWN,但应用本身实际上是正常的。因此,脚本做了降级处理:如果超时但应用进程仍在运行,则选择放行,避免因外部依赖问题误触发回滚。只有当应用进程真正启动失败时,才会自动回滚到备份版本。
在 Claude Code 中集成
在 .claude/commands/deploy.md 中定义了相应的自动化部署指令。实际使用时,我通常在修改完代码后直接告诉 Claude“部署到生产环境”,它会自动调用这个部署脚本并验证健康检查结果。
/upstream:智能同步上游分支并自动解决冲突
在多人协作或自己频繁切换分支时,同步上游分支的变更是高频操作。手动执行 git fetch + git rebase 并解决冲突,在冲突较多时可能耗费半小时以上。
典型使用场景
/upstream
最常见的场景是:我在 feature/admin-dashboard 分支上开发管理后台,而此时 main 分支已经被其他人(或其他 AI Agent)合并了新的代码。开发到一半,我需要将这些上游变更同步过来。
Claude 的智能冲突处理
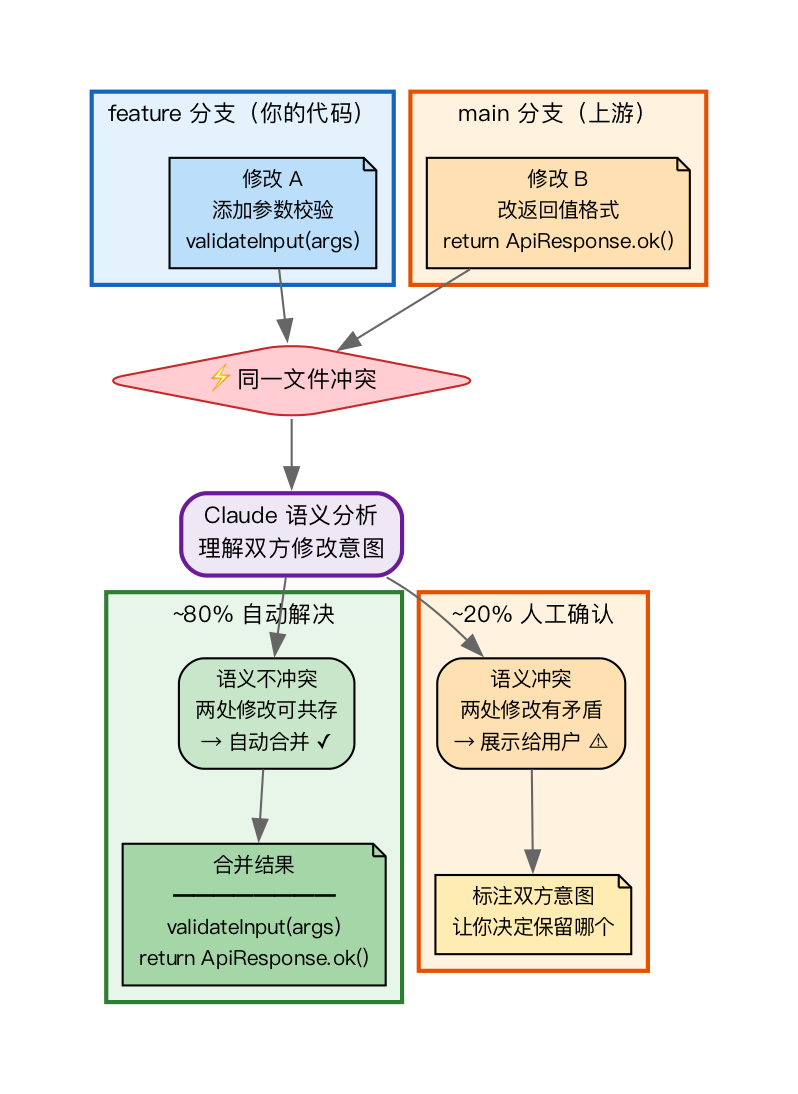
Claude 会先执行 git fetch 获取远程最新代码,然后进行 git rebase origin/main。关键在于其冲突处理方式——它并非机械地进行行差异对比,而是尝试理解代码的语义,判断“这两处修改的意图分别是什么,合并后应该是什么样子”。
例如,一个常见的冲突是两个人同时修改了同一个 Service 方法:一个增加了参数校验,另一个修改了返回值格式。Claude 能够识别出这两处修改并不矛盾,从而自动合并,而不是让开发者二选一。
当然,也存在 Claude 无法判断的情况,比如两个人对同一段业务逻辑做了方向完全不同的重构。此时,Claude 会将冲突清晰地展示出来,并标注双方的修改意图,交由开发者决定。
实际效果
上周一次同步操作涉及12个文件的冲突。如果手动处理,光是理解每个冲突的上下文就需要不少时间。Claude 自动解决了其中10个(都属于不矛盾的并行修改),仅将剩下的2个展示给我确认,整个过程不到两分钟。
/gitsync:一键将代码变更同步到多个本地项目
这个指令解决了我特有的一个痛点:同时维护多个项目时,某些通用性改动(如部署脚本、Claude指令配置)需要同步到所有相关项目。
问题背景
我的训练营系统和 code80 项目共用一套部署脚本模板和一些通用的 Claude Code 指令配置(例如 /commit 的规则)。当我在一个项目中优化了部署脚本后,另一个项目也需要同步更新。项目一多,手动复制文件极易遗漏,或者同步到一半被打断后遗忘。
/gitsync 的工作方式
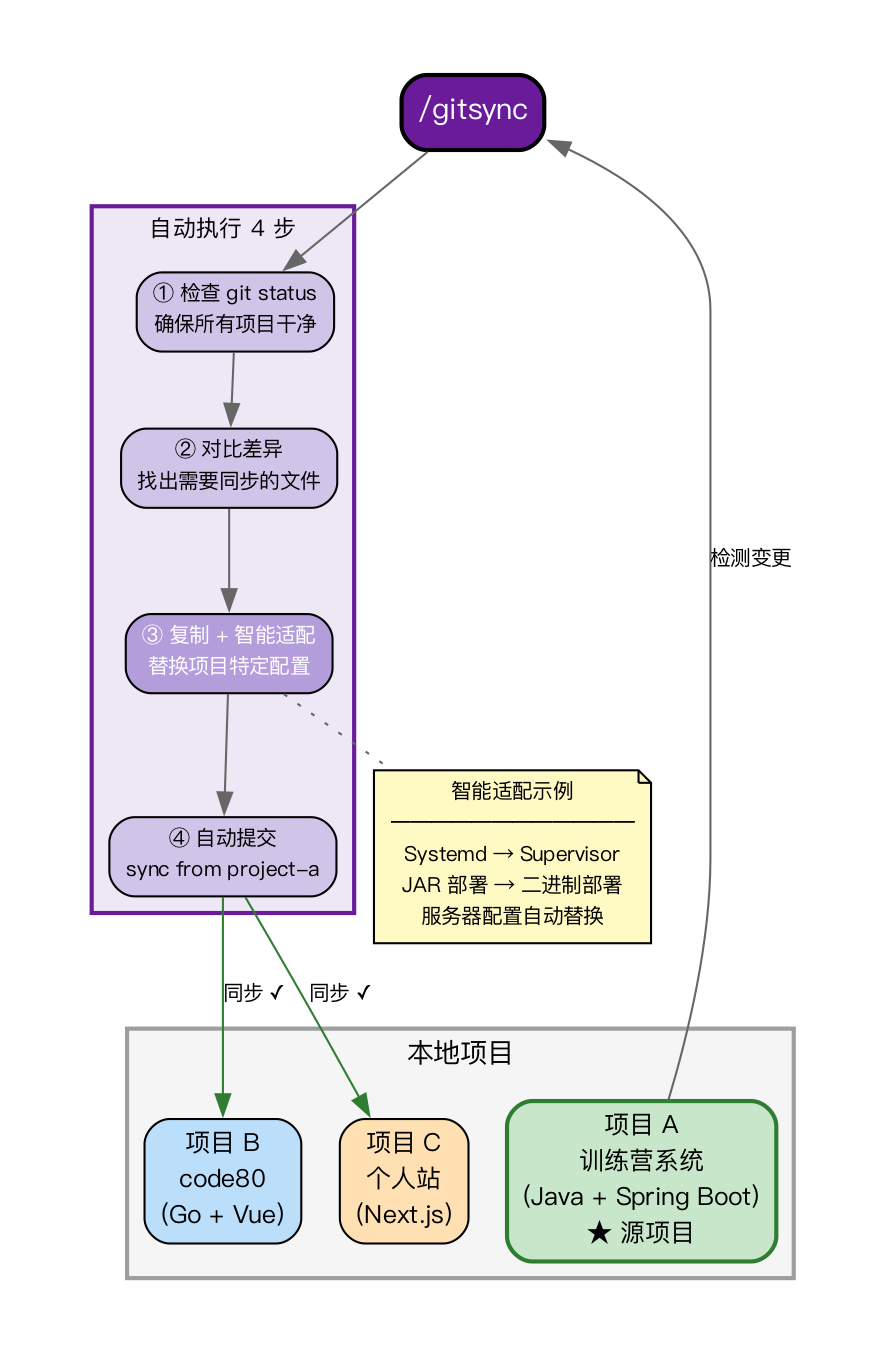
/gitsync
告诉 Claude 哪些项目需要同步以及同步哪些文件或目录,它会自动完成以下四步:检查所有目标项目的 Git 状态以确保工作区干净 → 对比源项目与目标项目的差异 → 将变更复制过去并保持目录结构 → 在每个目标项目中自动提交,并标注 “sync from project-a”。
其“智能适配配置”的能力是关键——并非无脑复制,而是理解脚本内容,将项目特定的部分(如服务器地址、部署路径、服务名称)替换为目标项目的对应值。例如,将训练营项目的零停机部署脚本同步到 code80 项目时,Claude 会自动将 Java/Systemd 的配置适配为 Go/Supervisor 的配置。
/review 与 /bug-add:构筑代码质量与经验护城河
/review-file 代码审查
/review-file backend/src/service/PaymentService.java
Claude 会从四个维度对指定文件进行审查:功能性(逻辑是否正确)、安全性(是否存在注入、越权等风险)、性能(有无 N+1 查询、内存泄漏隐患)、测试覆盖(关键路径是否有测试保障)。
/bug-add 构建团队经验库
踩过的坑不应该重复踩。每次解决一个线上 Bug 后,我会使用 /bug-add 指令将其记录到经验库中。Claude 会引导你填写:问题描述、错误日志、解决方案、根本原因、预防措施。最终生成标准格式的 Bug 记录,并保存到 docs/Bug经验库.md 中。
当下次遇到类似问题时,执行 /bug-search OAuth 就能快速搜索到历史解决方案。
这个经验库积累了三个月,目前已有20多条记录。其中一些 Bug 会反复出现(如知识星球 token 过期、微信 OAuth state 冲突),现在都能实现快速定位和解决。
/parallel-epic:实现多 AI Agent 并行开发
这个指令是为了配合 Claude Code 的 Agent Teams 功能而设计的。它能让多个 AI Agent 并行处理不同的开发任务。
/parallel-epic dev-a
执行后,指定的 Agent 会自动进入一个工作循环:寻找任务 → 阅读用户故事(Story)→ 编写代码并测试 → 运行测试 → 标记任务完成 → 使用 /compact 压缩上下文 → 继续下一个任务。
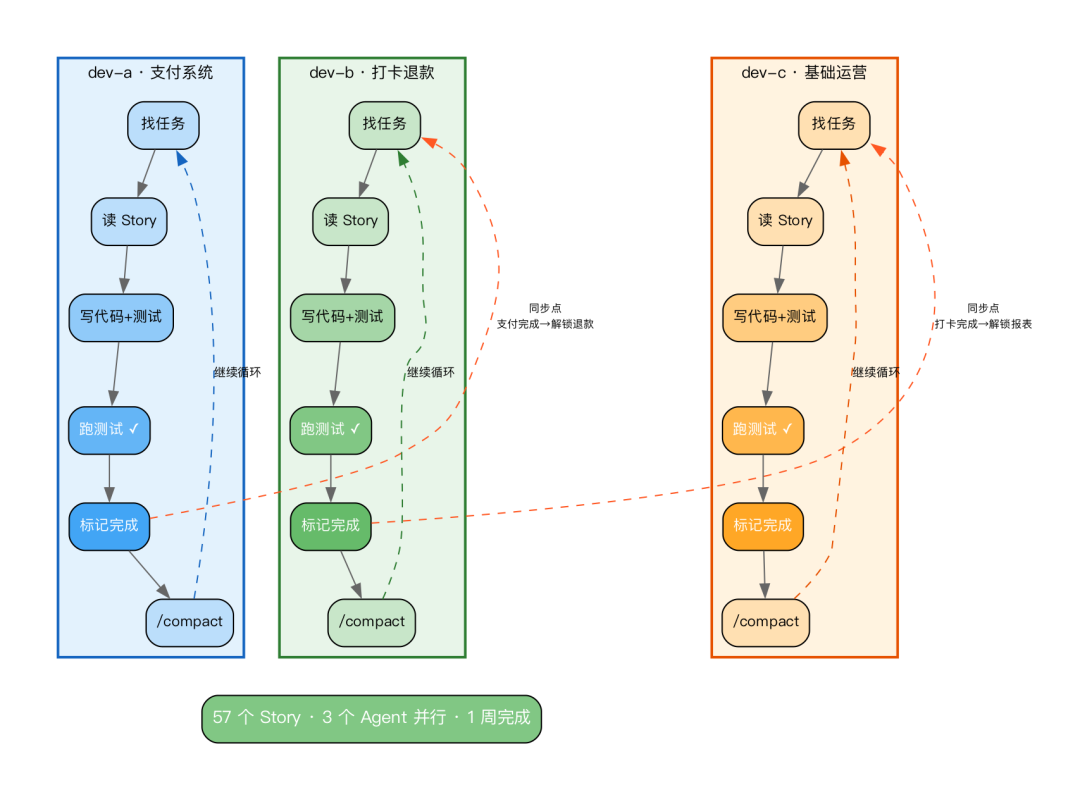
我可以启动三个 Agent,分别负责不同的业务线:dev-a 负责支付系统,dev-b 负责打卡与退款,dev-c 负责基础运营。故事之间存在依赖关系,通过同步点(Sync Points)进行管理——例如,dev-a 完成支付回调接口后,会自动通知 dev-b 可以开始处理退款逻辑。
我们曾用这套流程跑通了一个完整的 Sprint(包含57个用户故事),三个 Agent 并行工作,在一周内完成了原本预估需要两周的开发量。
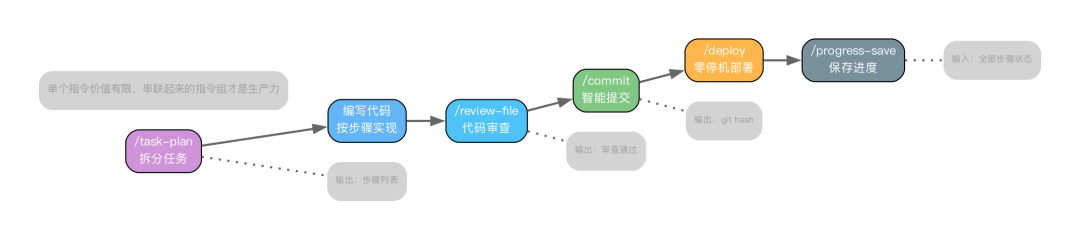
我的完整 AI 编程工作流全景
将上述所有指令串联起来,就构成了我日常的 AI 编程工作流:
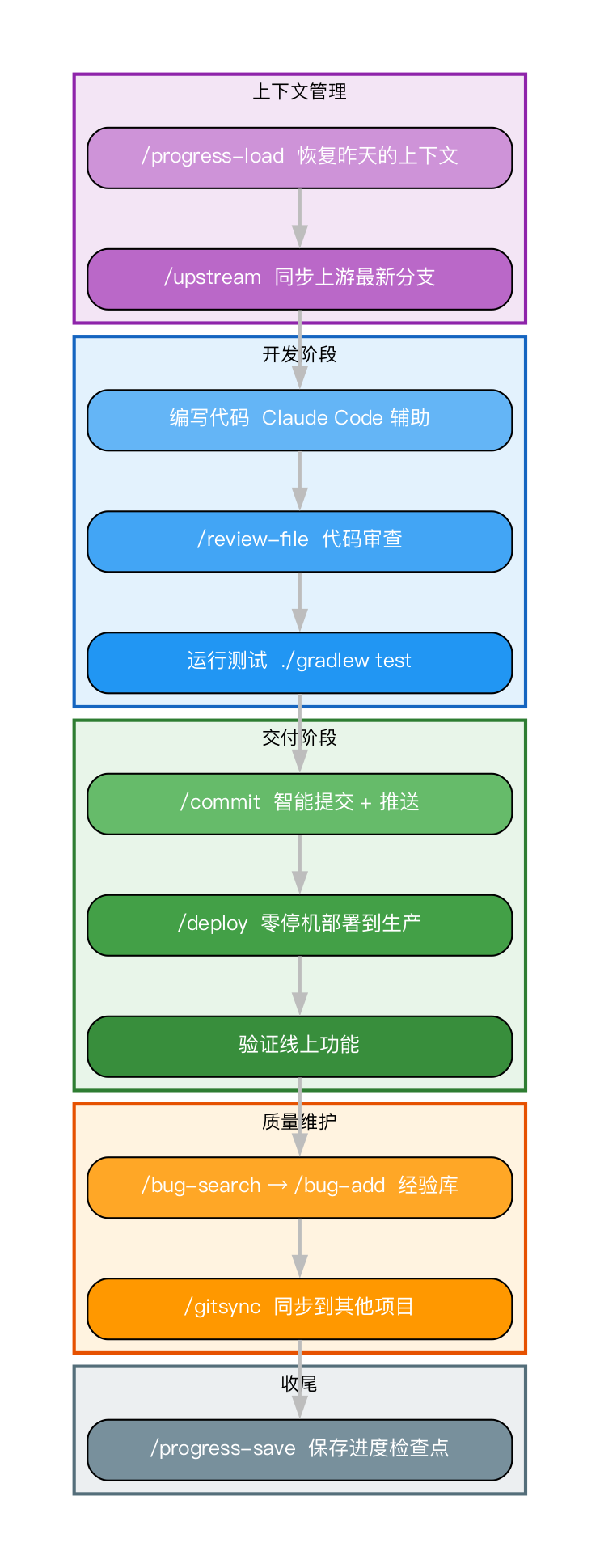
这套流程最大的好处在于高度可重复且标准化。无论是我亲自操作,还是让 Claude 自动执行,每一个步骤都有明确的规范和预期输出。
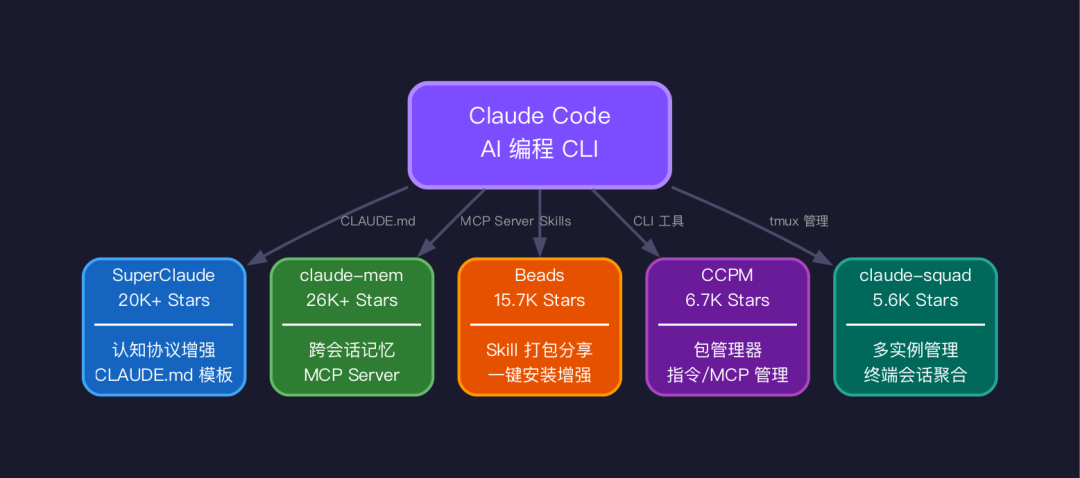
Claude Code 第三方生态:值得关注的高星项目
Claude Code 本身能力强大,而社区也涌现出不少高质量的增强项目,值得关注:
SuperClaude(20K+ Stars)
GitHub 上目前最热门的 Claude Code 增强框架。它通过一组精心设计的 CLAUDE.md 模板,显著提升了 Claude Code 的“认知”能力。其核心理念是为 Claude 注入“认知协议”,例如强制进行测试驱动开发、在编码前必须先分析现有模式、自动分割超过300行的文件等。这不仅仅是一套提示词模板,更是一套严格的行为规范。
claude-mem(26K+ Stars)
旨在解决 Claude Code 最大的痛点之一:跨会话记忆。它在 Claude Code 之上构建了一层持久化记忆系统,通过 MCP Server 实现。该系统能够记住你的编码偏好、项目决策历史、曾经踩过的坑,并在开启新会话时自动加载这些记忆。我使用的 /progress-save//progress-load 可以看作是一个手动版的记忆管理,而 claude-mem 则实现了自动化版本,两者可以互补。
Beads(15.7K Stars)
倡导“万物皆可打包为 Claude Code 的 Skill”。它提供了一种标准化的方式来打包和分享对 Claude Code 的能力增强。你可以将自己的自定义指令、MCP 配置、CLAUDE.md 模板打包成一个“Bead”,供其他人一键安装使用。
CCPM(6.7K Stars)
Claude Code 包管理器。类似于 npm 之于 Node.js,CCPM 是 Claude Code 生态中的包管理工具,用于管理自定义指令、Skills、MCP Server 的安装、更新和卸载。
claude-squad(5.6K Stars)
用于管理多个 Claude Code 实例的终端工具。如果你在使用 Agent Teams 功能,这个工具能帮助你在一个终端界面中管理所有 Agent 的会话——查看状态、切换窗口、聚合日志输出。
编写高效自定义指令的实用技巧
根据我的实践经验,分享几个编写自定义指令的关键技巧:
1. 指令描述要具体、可执行
避免使用模糊的自然语言描述,而应将 Claude 需要执行的每一步具体操作(尤其是 Bash 命令)清晰列出。Claude 对精确的 Markdown 列表和代码块的解析远比模糊的人话更准确。
- 好的写法:“执行以下 Git 命令:
git status --short / git diff / git log -3 --oneline”
- 差的写法:“步骤1:看看代码改了什么”
2. 内置常见的错误处理分支
如果指令中没有涵盖异常处理逻辑,Claude 在遇到错误时可能会自由发挥——例如尝试强制推送,或者静默忽略错误。因此,务必在指令中覆盖常见异常场景:没有变更时跳过提交、推送失败时提示先拉取最新代码、存在冲突时列出冲突文件等。
3. 结合 CLAUDE.md 定义全局规范
自定义指令解决的是“怎么做”的问题,而项目根目录或全局配置中的 CLAUDE.md 文件则定义了“做事的原则和规范”。两者配合使用,效果更佳。我在全局 ~/.claude/CLAUDE.md 中定义了提交信息规范、代码风格约定、项目结构要求等,所有自定义指令在执行时都会参考这些全局规则。
4. 让指令之间形成工作流闭环
单个指令的价值是有限的,而串联起来的指令组才能爆发出真正的生产力。每个指令的输出应尽可能成为下一个指令的输入。例如,/task-plan 拆分出的任务步骤,可以被 /progress-save 记录为检查点中的“待完成步骤”。
总结
Vibe Coding 的精髓并非随意地编写提示词,而是用工程化的思维来系统化管理 AI 编程的整个流程。自定义指令正是构建这一流程的骨架:
/commit 标准化了代码提交流程。/upstream 将繁琐的分支同步与冲突处理缩短至两分钟。/progress-save + /progress-load 有效解决了开发上下文断裂的难题。/deploy 将手动部署转化为安全、一键式操作。/gitsync 确保了多项目间的代码同步不再遗漏。/review 和 /bug-add 为代码质量保驾护航并积累团队经验。/parallel-epic 解锁了多 AI Agent 并行开发的高效模式。
这些指令本身都是简单的 Markdown 文件,语法易懂,十分钟就能创建一个。但当它们组合成一个有机的工作流时,就能让你将精力完全聚焦在“要做什么”这个创造性问题上,而将“具体怎么做”的细节交给 Claude 去自动化执行。这种工作模式的转变,才是 AI 编程带来的核心价值。如果你对打造自己的自动化工作流感兴趣,欢迎到我们云栈社区的开发者板块交流探讨。
 发表于 2026-2-11 17:39:07
|
查看: 156|
回复: 0
发表于 2026-2-11 17:39:07
|
查看: 156|
回复: 0
