上周系统上线前,一个接口突然爆出诡异Bug:本地调试一切正常,一到测试环境就频繁报“参数绑定失败”,Controller 里用 @RequestBody 接收的参数全是 null。
排查过程相当曲折,接口参数校验、JSON格式、依赖版本查了个遍,都没发现问题。最后才恍然大悟,问题的难点不在代码本身,而是忽略了 RequestBody 底层的运行机制。
有些问题,代码写得再漂亮也没用,关键在于是否理解其运行原理。RequestBody 只能读取一次,就是这类问题的典型代表。

问题出现的真实背景
在简单的 CRUD 系统里,请求链路很短:Controller → Service → DAO。RequestBody 通常只在参数绑定时被读取一次,自然不会出问题。
但在企业级系统中,请求到达 Controller 之前,往往已经历了多层处理:
- 接口幂等校验(防重复提交)
- 请求签名 / 防重放攻击
- 全量请求日志落库
- 安全审计 / 风控策略
- 参数脱敏 / 敏感词过滤
这些能力有一个共同点:都需要读取请求体(RequestBody)。
于是问题就出现了——当某个前置组件(如过滤器、拦截器)已经读取过 RequestBody 后,后续 Controller 中的 @RequestBody 参数绑定就会直接失效。
很多人忽略的一个事实
先说结论:RequestBody 不是“参数对象”,而是“数据流”。
在进入 Spring MVC 框架进行参数转换之前,它的真实形态是 HttpServletRequest 的输入流:
Spring 只是通过 HttpMessageConverter 帮你完成了从流到对象的转换:

而一旦底层的 InputStream 被提前消费:
Converter 无数据可读- 参数绑定失败
Validation 校验无法执行
这也是为什么问题现象看起来像是“参数丢失”。
为什么只能读取一次?
从 Servlet 规范来看,本质原因有以下四点:
1️⃣ HTTP Body 是流式传输
请求体不会一次性全部加载到内存,而是通过网络边传输边读取,这是一种节约资源的设计。
ServletInputStream inputStream = request.getInputStream();
InputStream 的特性决定了它:
- 没有
rewind (倒回)方法
- 没有
reset (重置)方法
- 没有副本机制
读取一次,游标就到达末尾,无法再次读取。
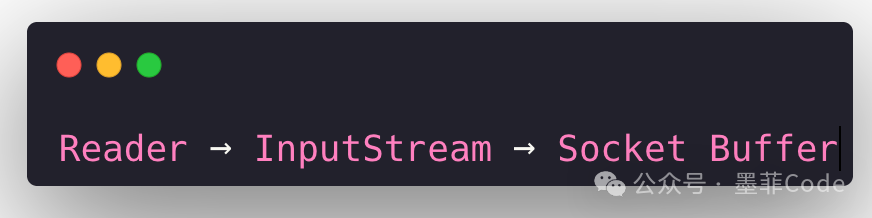
无论是获取字符流 (Reader) 还是字节流 (InputStream),它们本质上都指向同一个底层数据源(如 Socket Buffer),消费其中任何一个,另一个也会受到影响。
4️⃣ Servlet 规范不提供缓存机制
规范只定义了读取数据的接口,并未强制要求或提供数据回放(Replay)的机制,具体实现由各应用服务器和框架自行决定。
Spring MVC 参数绑定发生在什么时候?
这是很多人忽略的关键点。@RequestBody 的解析时机是在请求分发的过程中:

也就是说:参数绑定发生在 Controller 方法调用之前,但在 Filter / Interceptor 执行之后。
因此:
Filter 中读取了流 → 必然影响后续绑定Interceptor 中读取了流 → 同样影响- 即使在
Controller 前的 AOP 切面中读取 → 也为时已晚
构建“可回放请求体”
既然原生的流不可重复读取,我们就必须人为构建一套“副本机制”。核心策略是:第一次读取时进行缓存,后续读取都基于缓存创建新的流。

实现目标:
- 不改变现有业务代码
- 不影响
Spring MVC 的参数绑定
- 不破坏
Security / Validation 等框架功能
- 支持任意组件(过滤器、拦截器、AOP等)重复读取请求体
核心实现方案
方案架构
解决方案的核心是在请求处理链的最前端,用一个自定义的 Filter 包装原始的 HttpServletRequest,将其替换为我们自己实现的、支持重复读的 RequestWrapper。

关键代码实现讲解
1️⃣ RequestWrapper:缓存请求体
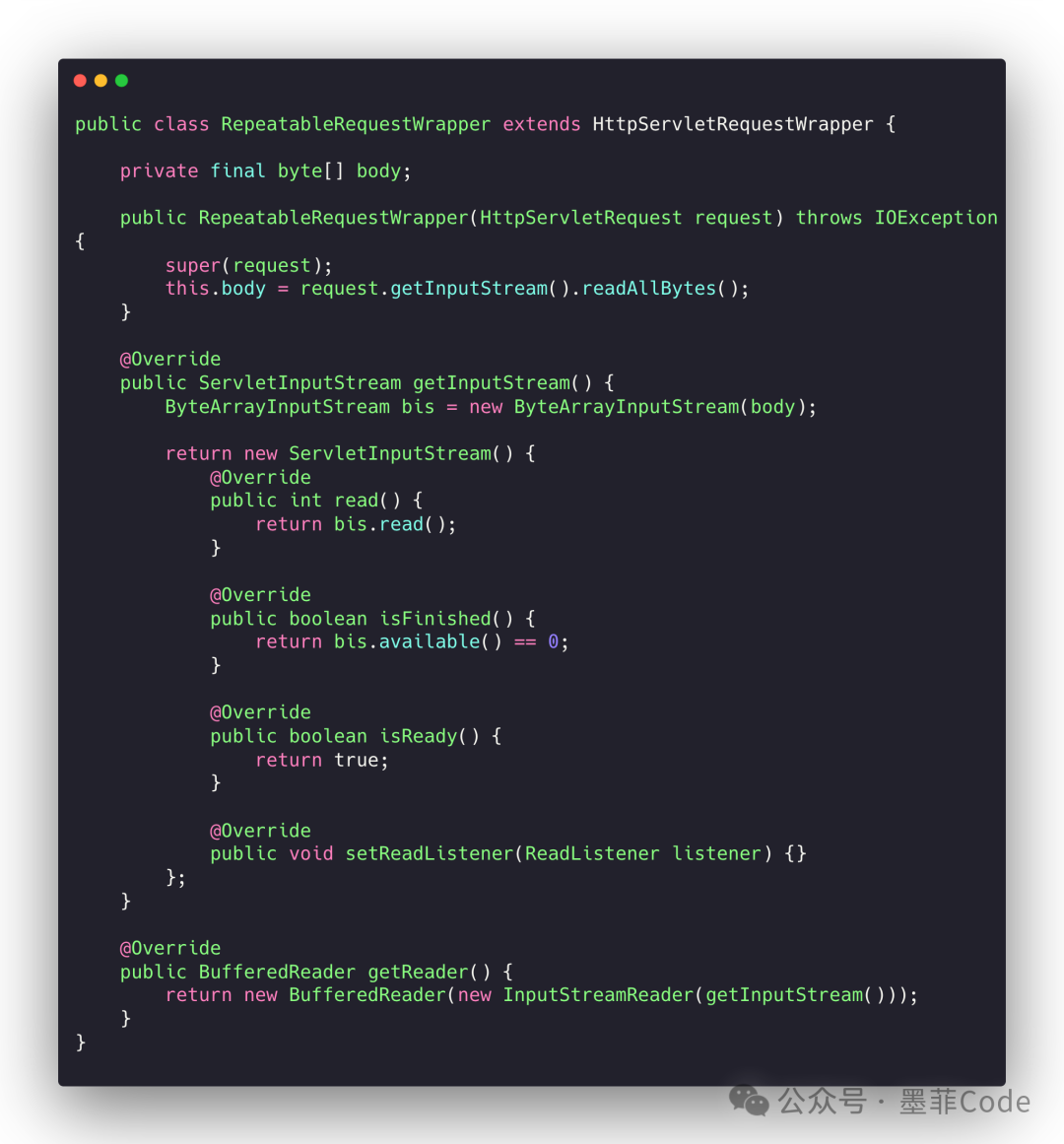
public class RepeatableRequestWrapper extends HttpServletRequestWrapper {
private final byte[] body;
public RepeatableRequestWrapper(HttpServletRequest request) throws IOException {
super(request);
this.body = request.getInputStream().readAllBytes();
}
@Override
public ServletInputStream getInputStream() {
ByteArrayInputStream bis = new ByteArrayInputStream(body);
return new ServletInputStream() {
@Override
public int read() {
return bis.read();
}
@Override
public boolean isFinished() {
return bis.available() == 0;
}
@Override
public boolean isReady() {
return true;
}
@Override
public void setReadListener(ReadListener listener) {}
};
}
@Override
public BufferedReader getReader() {
return new BufferedReader(new InputStreamReader(getInputStream()));
}
}
① 为什么缓存为 byte[]?
InputStream 本质是字节流,用 byte[] 缓存最直接。byte[] 可以随时用来构造新的 ByteArrayInputStream,实现重复读。- 性能上优于先转换成字符串再转回字节流。
因为流内部有“游标”指针,读取一次后游标就到末尾了。

所以必须在每次调用 getInputStream() 时,都基于缓存的 byte[] 创建一个全新的 ByteArrayInputStream。
③ 为什么同时要重写 getReader() 方法?
因为部分组件(或某些框架内部)可能会使用 Reader(字符流)来读取请求体。如果不重写此方法,它返回的 Reader 可能仍然基于原始的、已被消费的流,导致读取不一致或失败。
2️⃣ Filter:入口替换 Request
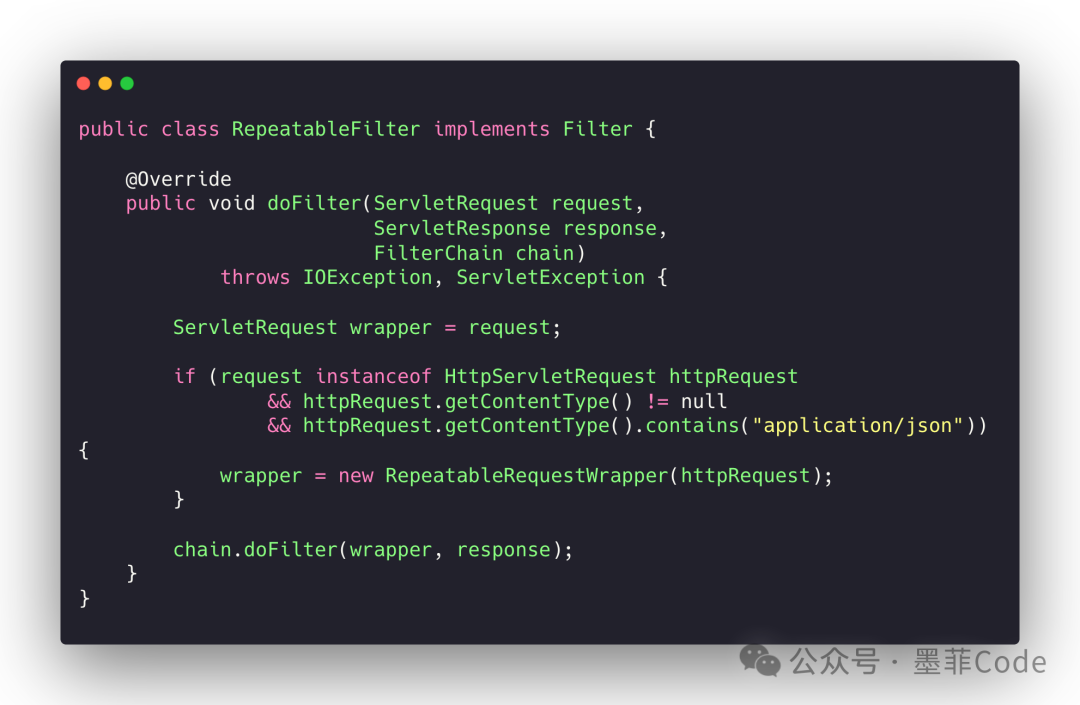
public class RepeatableFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
ServletRequest wrapper = request;
if (request instanceof HttpServletRequest httpRequest &&
httpRequest.getContentType() != null &&
httpRequest.getContentType().contains("application/json")) {
wrapper = new RepeatableRequestWrapper(httpRequest);
}
chain.doFilter(wrapper, response);
}
}
① 为什么只处理 application/json 类型?
JSON 是 @RequestBody 注解最常用、最典型的绑定场景。- 避免对文件上传 (
multipart/form-data)、大流量请求等进行不必要的缓存,防止内存暴涨。
② 为什么这个 Filter 必须配置在最前面?
因为谁先读到流,谁就决定了流的“生死”。必须在任何其他可能读取请求体的组件之前,完成请求的包装和缓存。
3️⃣ Filter 顺序配置
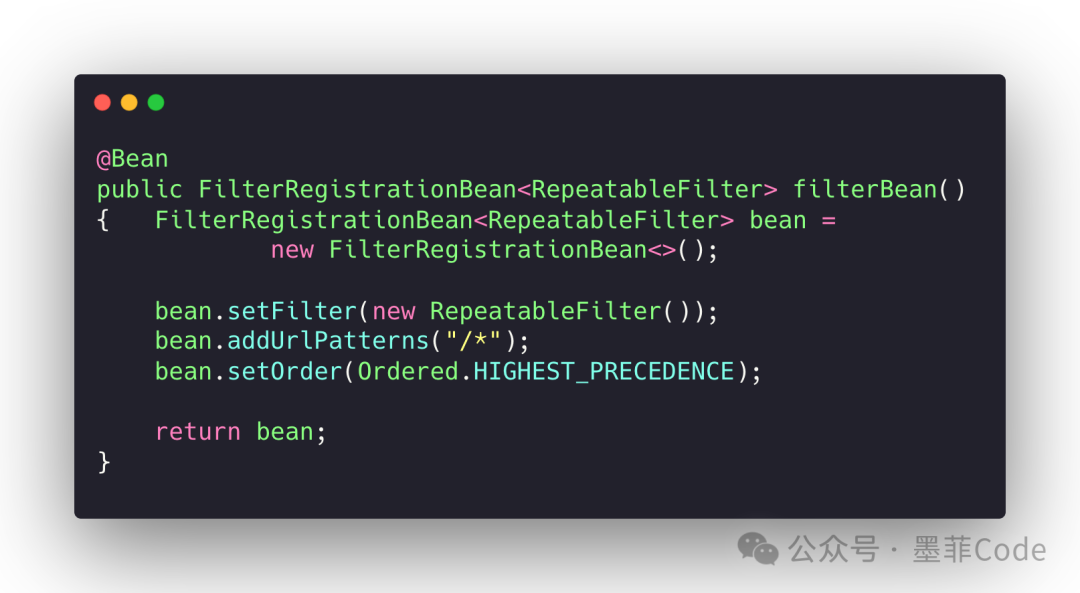
在 Spring Boot 中,通过 FilterRegistrationBean 将我们的过滤器注册为最高优先级,确保它最先执行。
@Bean
public FilterRegistrationBean<RepeatableFilter> filterBean() {
FilterRegistrationBean<RepeatableFilter> bean = new FilterRegistrationBean<>();
bean.setFilter(new RepeatableFilter());
bean.addUrlPatterns("/*");
bean.setOrder(Ordered.HIGHEST_PRECEDENCE);
return bean;
}
进阶工程思考
这部分才真正体现方案的深度和工程性考量。
1️⃣ 大请求体的内存风险
缓存机制意味着所有请求体内容都会暂存在内存中,其内存占用公式很简单:

单次请求Body大小 × 并发请求数 = 总内存占用
优化策略:
- 限制缓存大小:设置一个阈值(如 1MB 或 10MB),超过则不进行缓存,降级为单次读取,并在日志中告警。
- 文件上传直接跳过:对于
multipart/form-data 类型的请求,其 InputStream 可能指向临时文件,不应全部读入内存。
- 考虑使用磁盘临时文件:对于确实需要缓存且体积较大的请求体,可以考虑写入临时文件,但这会引入IO开销。
2️⃣ 与 Spring Security 的顺序关系
如果系统使用了 Spring Security,必须保证我们的可重复读 Filter 在 Security 的过滤器链之前执行。
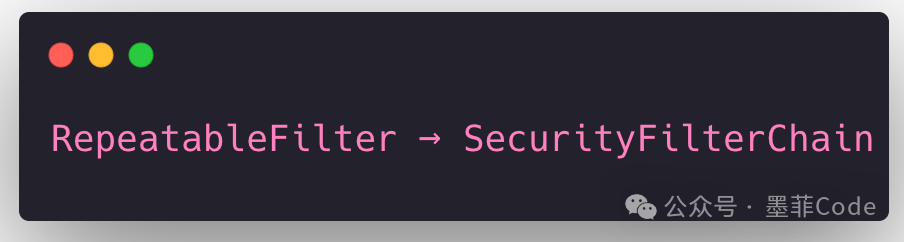
因为 Security 的过滤器(如用于签名校验、权限验证的过滤器)也可能需要读取请求体。如果它们在我们的包装器之前执行,读取后依然会导致后续流程中流被耗尽。
3️⃣ 与日志系统的整合
推荐将日志记录(如全量请求日志落库)也放在我们的 RequestWrapper 之后进行。这样,日志组件可以直接从缓存中获取请求体内容,避免了重复读取流带来的IO消耗,也保证了日志内容的完整性。
经验总结
- 本质原因:
RequestBody 只能读取一次,是由 Servlet 规范和 InputStream 的流式特性决定的,并非 Spring 的 Bug。
- 影响链路:在 Spring MVC 中,参数绑定依赖于底层的
InputStream,任何提前读取操作都会破坏这一过程。
- 工程解法:唯一的通用解决方案是 “缓存 + 包装 + 前置替换”。通过自定义
Filter 和 HttpServletRequestWrapper 构建支持重复读的请求对象。
- 关键细节:方案的稳定性由
Filter 的执行顺序和合理的缓存策略(如大小限制、类型过滤)共同决定。
- 基础设施思维:当系统引入安全、幂等、审计等全局能力时,可重复读取请求体就从一种技巧升级为必须的基础设施能力。
结语
从一次诡异的参数绑定失败问题入手,我们深入剖析了 HttpServletRequest 中 RequestBody 的流式本质。理解这一点,是解决此类问题的关键。优秀的工程实践不仅仅是修复一个 Bug,更是构建一套健壮、可复用的底层机制,以应对未来更复杂的业务场景。
如果你在 Spring Boot 或其它 Web开发 框架中也遇到过类似的“灵异”问题,不妨从底层原理和运行机制入手,或许能找到更根本的解决方案。更多深入的技术讨论和实践,欢迎到 云栈社区 与广大开发者交流。
 发表于 2026-2-12 13:50:31
|
查看: 202|
回复: 0
发表于 2026-2-12 13:50:31
|
查看: 202|
回复: 0
