关键技能不是如何写出更好的 prompt,而是知道什么时候应该停止 prompt,开始自己思考。
最近,《Advanced React》的作者 Nadia Makarevich 做了一个相当有启发的实验:她让 Claude Opus 去调试三个真实的 React/Next.js 项目 Bug,然后自己再手动验证 AI 给出的解决方案是否正确。
实验结果挺有意思的——AI 表面上“修复”了问题,但真正“对症下药”修复到点子上的,可能只有一个半。
在我看来,这个实验的价值,远不止于证明 AI 行不行。它更大的意义在于,帮我们清晰地画出了一条能力分界线:什么时候可以放心交给 AI,什么时候必须自己动手。
| Bug 类型 |
AI 修好了吗? |
找对根因了吗? |
修对了吗? |
| Zod 验证报错 |
✅ |
✅ |
🥑 半对 |
| 双重 Loading 骨架 |
✅ |
❌ |
❌ |
| Redirect 诡异报错 |
❌ |
❌ |
❌ |
三个 Bug,AI 成功“让错误消失”了两次,但只有第一个勉强算得上真正理解并正确修复。这说明了什么?AI 非常擅长“消除症状”,但不一定真正理解“病因”。

Bug 1:Zod 验证失败
问题:用户资料页面报错,控制台显示 ZodError,提示 phone 和 address 字段为 undefined。
AI 的做法:在用于测试的 mock 数据里,直接补上了这两个缺失的字段。
结果:页面确实不再报错,功能恢复正常。
但是——问题在于,这些是 mock 数据。从业务逻辑上讲,真实用户场景下,电话和地址这些字段很可能就是可选的。所以,更合理的修复方式,应该是将 Zod schema 中对应的字段标记为 .optional()。
AI 选择了一种“最直接”的修复路径,堵住了眼前的错误,却不是最符合长远设计的那一个。这就是典型的 “能修好,但修得不够聪明”。
教训:AI 的修复能让测试通过,但你需要自己判断这个修改是否符合真实的业务场景和架构原则。在涉及业务逻辑权衡时,AI 的软件测试能力就显现出其局限性了。
Bug 2:双重 Loading 骨架
问题:从首页导航到用户详情页时,页面会快速闪过两个不同的加载骨架(Skeleton)。但如果直接刷新用户详情页,则只显示一个骨架。
AI 的表现:堪称混乱。它每次给出的解释都各不相同:
- 有时候说是
loading.tsx 文件的层级问题。
- 有时候归因于服务端渲染的机制。
- 有时候建议改用
useSuspenseQuery Hook。
最终,采用 useSuspenseQuery 的方案确实“修好了”双重骨架的问题——但这个改动会引发新的问题:页面刷新时会出现 Hydration 错误。典型的拆东墙补西墙。
真正的原因:这与 Next.js 动态路由的预获取(prefetch)机制以及 Suspense 边界的交互有关。在进行 SPA 式的客户端导航时,Next.js 需要下载 RSC (React Server Component) Payload,这个过程会触发 loading.tsx 的显示;而直接刷新页面时,RSC 内容已经包含在首次返回的 HTML 中了,所以不经过 loading.tsx。
正确的修复思路:
- 让两个骨架看起来一模一样(从用户体验上抹平差异)。
- 采用更精细的加载策略,只在关键数据区域显示骨架,让页面框架先出来。
- 考虑使用 Server Component 直接获取数据,从根本上消除客户端的 loading 状态。
AI 在这个问题上的表现,暴露了一个关键弱点:它并不真正理解像 Next.js 这类复杂框架的底层渲染机制,只能基于模式进行猜测。而且每次猜测结果都不同,说明它在“碰运气”,缺乏一致性推理。
Bug 3:Redirect 诡异报错
问题:访问 /users 路由时,页面会短暂闪出一个错误页,然后立即重定向到 /users/1。控制台报错:Rendered more hooks than during the previous render。
AI 的表现:完全失败,且方向混乱。
它尝试了一堆方案,每个都附带着“听起来很有道理”的解释:
- 把
redirect 移到 useEffect 中(影响性能)。
- 移到
next.config.ts 配置里(很快会变得难以维护)。
- 移到 middleware 中(同样不可维护)。
- 胡乱修改
QueryProvider 的配置。
- 声称是 Next.js 版本太旧。
- 建议添加
loading.tsx 文件。
这些方案无一奏效。
真正的原因:这是一个相当罕见的边缘情况,由 Server Action + Suspense + Redirect 三者的特殊组合触发。具体来说,当一个调用 Server Action 的组件(例如 <SendAnalyticsData />)与页面级的 Redirect 同时存在时,Next.js 的渲染流程会出现混乱。
这个问题在 Next.js 的 GitHub Issues 中有所记录,但由于触发条件特殊,案例极少,因此 AI 的训练数据中几乎没有这类信息。
解法:将那个引发问题的 Server Action 调用改为普通的 REST API 请求。
这个案例揭示了 AI 在前端调试中的一个致命弱点:当遇到罕见、复杂的边缘情况时,它缺乏真正的洞察力,只会反复套用常见的修复模式,并且会显得越来越“自信”地给出错误答案。
AI 调试的能力边界
基于以上三个实战案例,我们可以大致勾勒出当前 AI 在代码调试领域的能力边界。
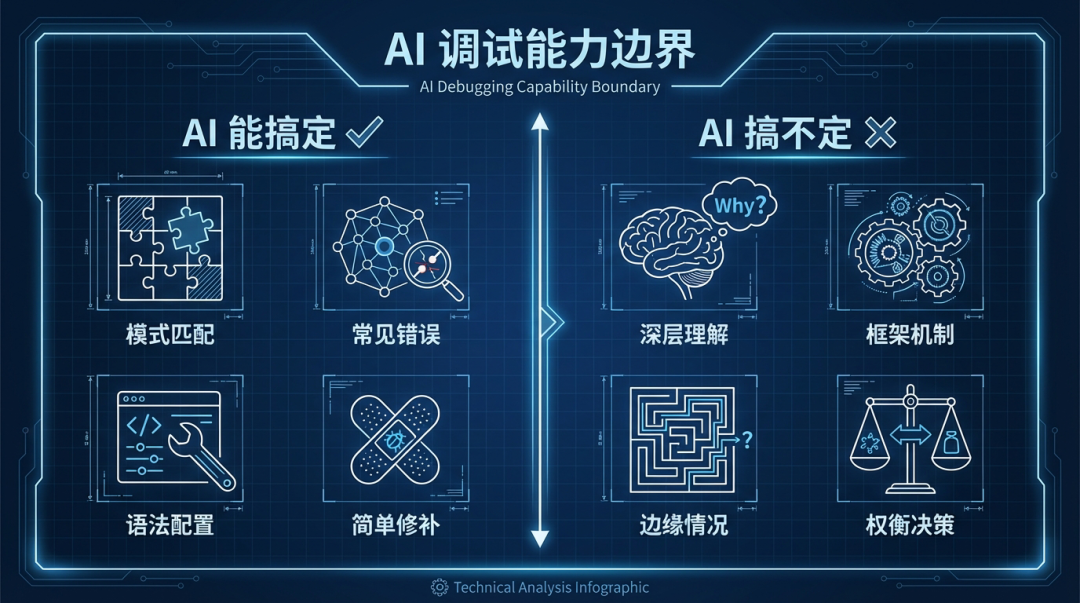
AI 游刃有余的“模式匹配”领域
在处理结构化、模式化的逻辑纠错时,AI 的表现非常出色。它本质上是一台强大的模式匹配机器,擅长从海量代码中快速定位字段缺失、类型不匹配、空值未检查等常见问题。对于语法错误、过时的 API 用法,或是需要简单补丁(如添加一个条件判断)的场景,AI 能提供即用型代码片段,极大提升基础调试的效率。
为什么开发者的深度思考依然不可替代
然而,一旦问题超出模式匹配的范畴,进入需要“理解”和“权衡”的领域,AI 的局限性就暴露无遗:
- 对框架机制的浅层理解:AI 很难洞悉像 Next.js 中 Suspense 边界与 RSC 流的精确交互、Hydration 过程的细节等深层机制。这些知识需要对运行时环境有深刻理解。
- 缺乏“权衡”能力:当面临架构抉择时,例如“是修改数据 Schema 还是清洗现有数据”、“优先用户体验还是实现简洁性”,AI 通常只能给出折中或泛泛的建议,无法结合具体的业务上下文做出最具性价比的决策。
- 对边缘情况束手无策:如 Bug 3 所示,对于训练数据中罕见或不存在的问题组合,AI 缺乏真正的推理能力,容易陷入胡猜乱试的循环。
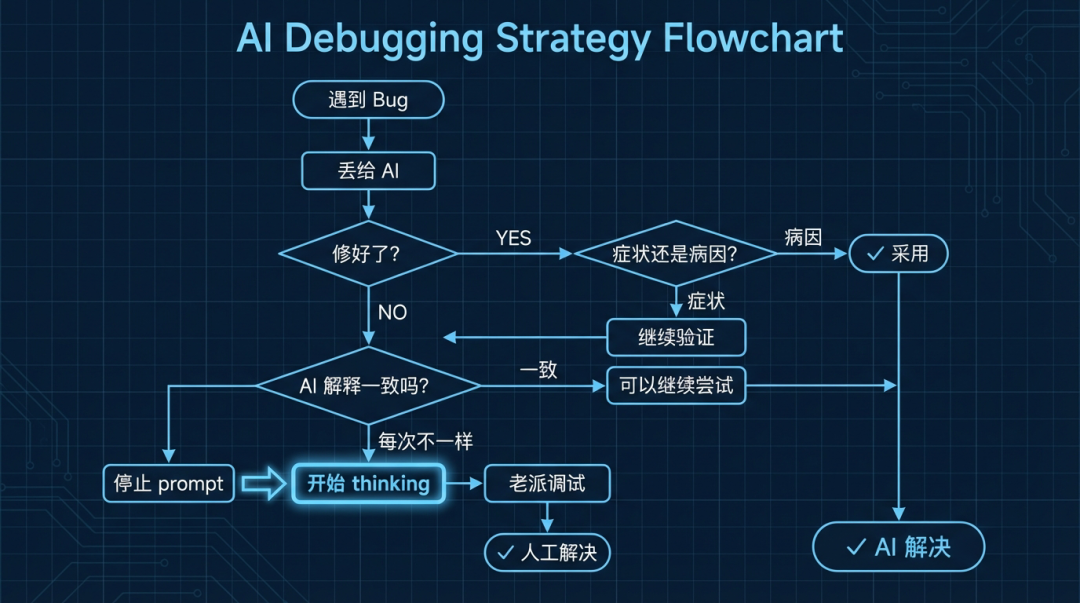
给开发者的实用 AI 调试策略
基于这次实验,我们可以总结出几条更高效、更安全地使用 AI 进行调试的策略:
1. 让 AI 打头阵,快速过滤简单问题
遇到报错,完全可以第一步就丢给 AI:“这是错误信息和相关代码,请修复。” 对于它能解决的常规问题,通常一分钟内就能得到可用的方案,这能节省大量翻阅基础文档的时间。
2. 严格扮演“审查者”角色,验证每一个修复
AI 给出修复方案后,切勿直接合并代码。务必问自己三个问题:
- 它修复的是表面症状,还是根本病因?
- 这个修改在真实的业务场景和系统架构下是否合理?
- 这个改动是否会引入新的潜在问题或技术债?
3. 警惕“自信的矛盾”,这是停止信号
如果 AI 对同一个问题给出了多次不同的解释,但每次语气都无比肯定——这是一个强烈的危险信号,表明它正在“瞎猜”。此时应立即停止无意义的 Prompt 纠缠,转而采用传统调试方法。
4. 保持并磨练你的“老派”调试技能
在这次实验中,作者最终定位问题依靠的都是一些经典的、AI 无法替代的调试手段:
- 视觉定位法:给可疑组件添加显眼的彩色边框,观察渲染顺序和时机。
- 性能剖析:录制 Performance Profile,精确分析网络请求、组件渲染的生命周期。
- 二分删减法:逐个删除或注释掉组件,观察问题是否随之消失,从而定位问题源头。
这些方法需要你对基础 & 综合的计算机原理有扎实理解,但往往是破解复杂 Bug 的钥匙。
5. 最关键的一课:知道何时放弃
正如开篇所言:真正的技能,不在于写出多精巧的 Prompt,而在于懂得何时应该停止与 AI 对话,开始启动你自己的思考。
如果 AI 在同一个问题上连续尝试两三次都未能给出正确方向,就别再耗下去了。直接去查阅官方文档、搜索 GitHub Issues、甚至阅读相关源码,这些“笨办法”往往比继续追问 AI 更高效。
小结
你可以把当前的 AI 调试工具,想象成一个知识渊博但经验尚浅的实习生:它能秒杀教科书里的经典例题,但遇到需要结合具体情境灵活变通的综合题时,就容易抓瞎,而且无论对错都显得信心满满。
因此,使用它的最佳策略是:让它冲锋陷阵,你负责运筹帷幄与最终验收。
当你发现它开始原地转圈、解释前后矛盾、或修复方案越改越乱时,那就是触及其当前的能力天花板了。这时,就该你这位“资深工程师”亲自上场,运用经验和深度思考来解决问题了。如果你想与更多开发者交流这类实战中的架构与调试心得,欢迎来云栈社区一起探讨。
 发表于 2026-2-12 14:33:29
|
查看: 237|
回复: 0
发表于 2026-2-12 14:33:29
|
查看: 237|
回复: 0
