原本,小雷以为临近过年,这AI圈子能稍微消停一点。
特别是去年这一整年,整个行业根本没有停歇,各大厂商像约好了一样扎堆发新品。图像生成领域尤其热闹,闭源那边,Banana Pro凭着惊人的光影质感,几乎成了设计师电脑里的钉子户;开源这边,以Z-image为首的模型也是满天飞,只要你显卡顶得住,本地跑图的效果早就今非昔比。
那时候小雷还在编辑部跟同事念叨,说这俩大模型的风潮,最起码能领跑个半年吧。结果没想到,打脸来得比翻书还快。
就在昨天,阿里的通义千问团队不声不响地搞了个大动作——新一代图像生成基础模型Qwen-Image-2.0正式上线。

这名字听着挺朴实,没什么天花乱坠的后缀,但真正让圈内人炸锅的是它的核心卖点:它不仅仅是画图,还能听得懂人话,甚至能写中文字。
根据官方介绍,这个模型不但支持原生2K分辨率(2048x2048像素),还能处理长达1000个token的复杂指令,并采用了更轻量的模型架构,模型尺寸远小于Qwen-Image 1.0的20B,带来更快的推理速度。
什么?你说这些参数听着云里雾里的,根本理解不了是啥意思?没事,我这里也准备了谷歌Nano Banana Pro,第一时间给大家进行横向体验比较。话不说多,直接开整!
中文输出不错,审美有待提升
在开始跑图之前,咱们得先聊聊Qwen-Image-2.0的一个核心逻辑。
以往我们玩AI画图,就像是在抽卡。因为输入Token长度的限制,你很难细致定义自己想要的图片,只能把自己的需求简化成关键词的集合,然后让AI给你吐出几张图,好不好看全看运气。从我的经验来看,提示词如果写得太长,模型往往会顾头不顾尾,要么丢了背景,要么搞错了物体数量。
但Qwen-Image-2.0不同,它主打的核心卖点就是长指令遵循,渲染能力强。
为了验证这一点,小雷准备了三个维度的地狱级测试:超长逻辑指令、图文混合排版,以及中文语义的精准还原。要知道,Qwen-Image-2.0输入的提示词长度变成了1K token,你完全可以把提示词写得非常详细和具体,同时还可以选择是否需要优化prompt。这点对于新手AI玩家,是真的很有吸引力。
在超长逻辑指令上,我选择基于最近的个人经历,直接给两个大模型输入一个长达700字,且包含复杂指令的提示词:

说实话,敲完这段字,小雷自己都觉得有点过分。要知道,这种存在四格结构、明确逻辑、人物关系与统一画风的制图要求,对于市面上大部分图像生成模型来说几乎都是不可能做到的。
等待了十几秒后,两张图出来了。该说不说,Banana Pro生成的图,那股水墨连环画的意境确实到位,黑白对比强烈,看着很有艺术感。但仔细一看,我直接笑喷了:它真的把豹子头林冲画成了一个长着豹子头的怪物!在它的逻辑里,豹子头就是“Leopard Head”,完全搞不懂这是个外号。

再看Qwen-Image-2.0这边,个人觉得画风更偏写实,画面里的林冲是个满脸沧桑的硬汉,并没有长出动物脑袋,它很清楚“豹子头”指的是人的特征而非物种,从跪地、破窗到持枪杀敌,分镜叙事非常清晰。这就是国产模型在中文语境下的优势——它懂的是典故,而对手只能望文生义。

什么?你说一张图说明不了啥?那我们再试试中文语义还原,我准备了一份接近800字的详细提示词,看看Qwen-Image-2.0能否交付合乎预期的生成结果:

结果呢,Qwen-Image-2.0的生成结果如下。可以看到模型还原了我们对图片布局、字体颜色的要求,内容也得到准确呈现,基本没有遗漏。
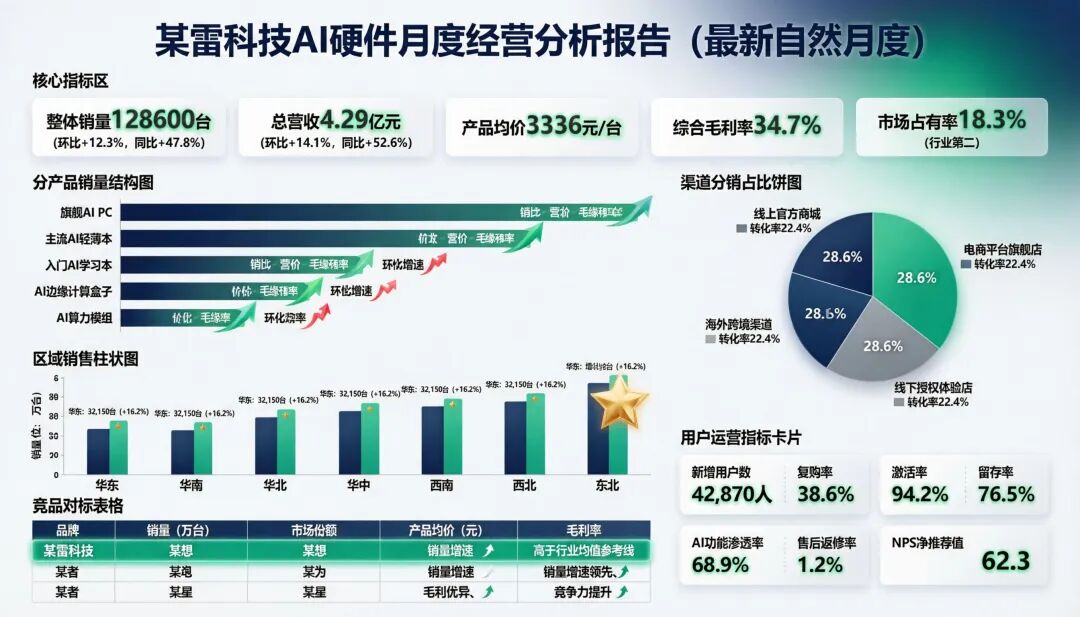
但也有不足之处,好几个框里居然把分号算进去了,一些过小的字体标识根本看不清。而Nano Banana Pro的生成结果明显有更多的图像和图标,设计风格和我们要求的一样,大部分文字也都成功渲染。美中不足的是,可以看到部分文字出现了模糊的问题,难以辨别。
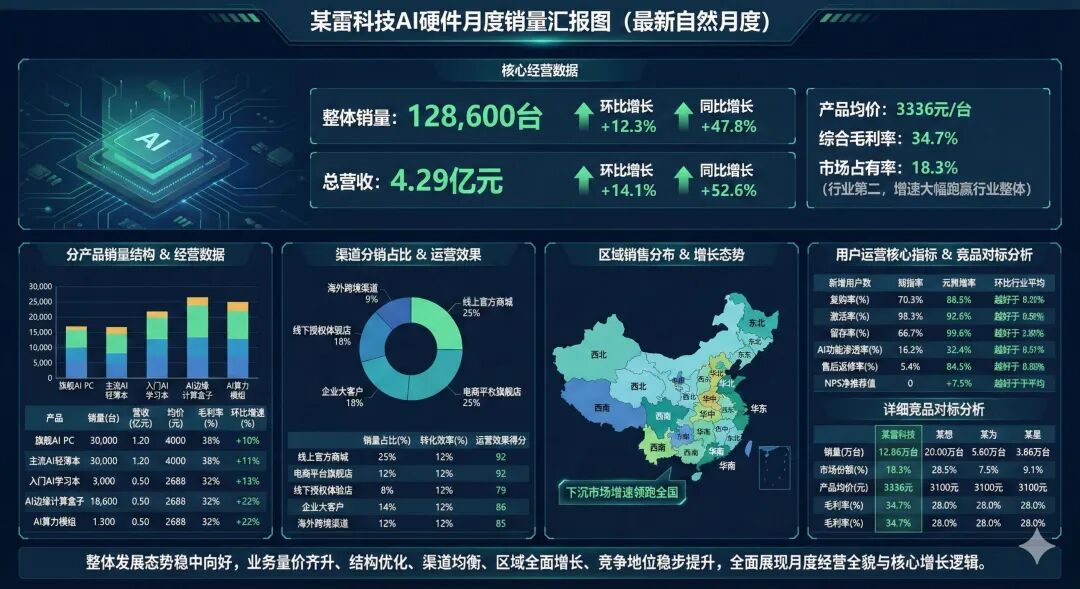
总的来说,两者都完成得不错,Qwen-Image-2.0相对简洁一些,而Nano Banana Pro的成品确实很有设计感。
最后,我们测试一下图文组合的效果,这里就以曹操的《短歌行》作为目标:

在没有提示《短歌行》全文的前提下,两者均无法完成全文的生成,Qwen-Image-2.0会把内容写到一半中断,而Nano Banana Pro感觉整了个奇怪的复读。


抛开这点,两款大模型的生成效果居然都挺不错的。如果给出全文的话,生成结果会不会有所不同呢?为了解答大家的疑惑,我也是重新尝试了一遍。


乍看之下,整体完成度还是很高的。我要求的画面元素,需要完整嵌入的长文本,和对书法字体的要求都达到了还原。但是仔细看的话,不难发现Qwen-Image-2.0在长文本的排版、生成和美术设计上,都还有可以进步的空间。
稳定性强,修图更是一绝
如果说前面的文生图只是常规操作,那么接下来的图像编辑,才是Qwen-Image-2.0真正让小雷感到惊喜的地方。具体讲呢,我们可以通过上传一张或多张图片,通过提示词指令让AI进行二创、修改等编辑操作。这里就不说废话了,先试试之前很火的“三视图”玩法:

原图是TikTok上的日本小网红:
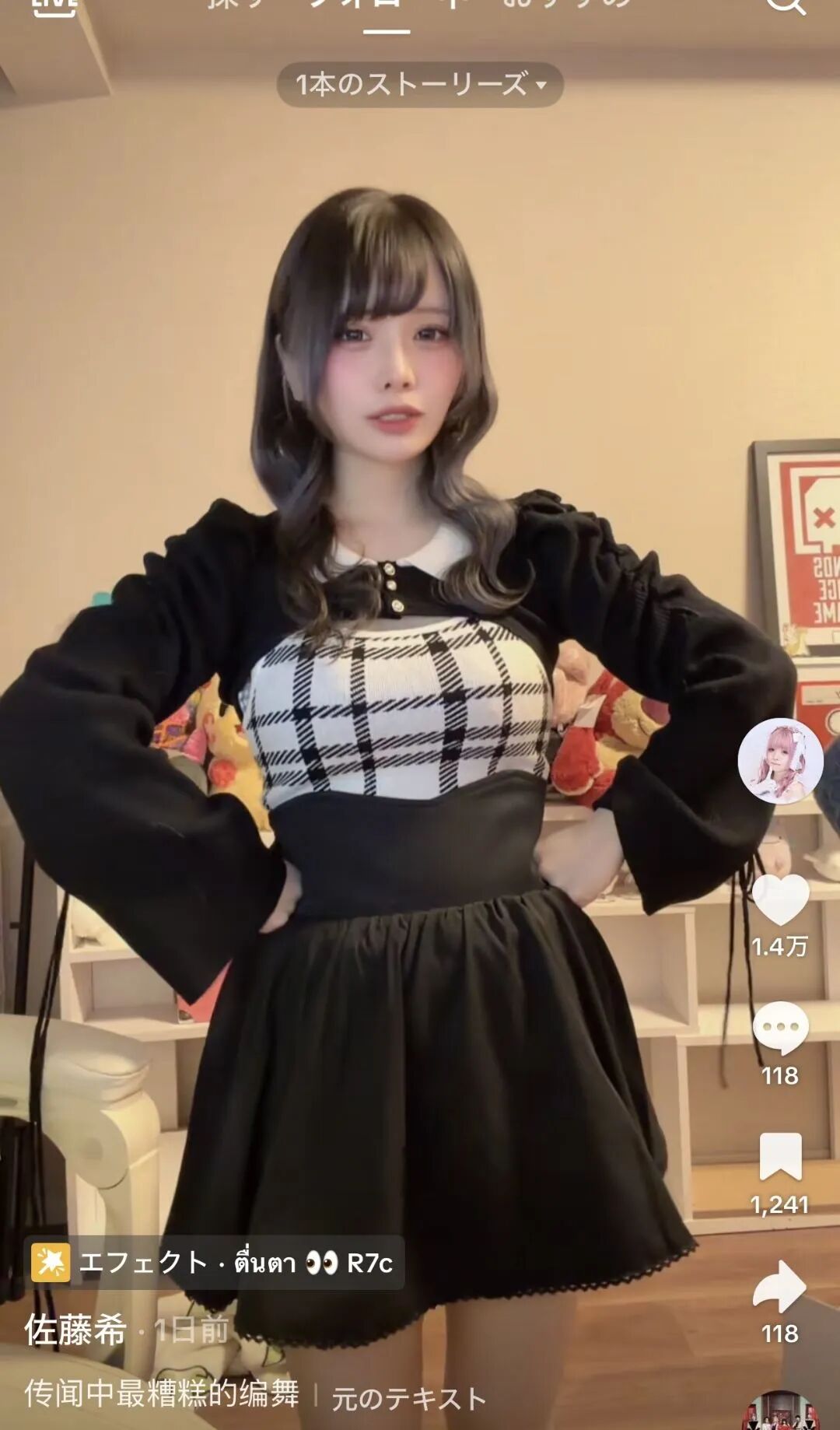
在此基础上,Qwen-Image-2.0生成后的三视图就很正常,完全可以认为是符合角色逻辑的成品。

而Nano Banana Pro的成品就很抽象,是将角色进行了画风转绘后再生成的三视图,图片还叠加在原图上方,就很莫名其妙。

我们接着尝试,这次的目标是给原图换一套Coser服装和拍摄场地,让图1中的女孩穿着图2的Cos服装,站在图3的场景里面:

别说嗷,Qwen-Image-2.0的成品真没有啥违和感,衣服和女孩的融合得也非常好,就是头上有些没抠干净的白边。

至于Nano Banana Pro...妹子你是谁啊?

要我说,你这根本不是修图,而是图像生成吧!我再试一下AI合影,输入两张独立人物照片,让模型把两人自然合成到同一个场景:

你看Qwen这成品,人物一致性保持、服装保持,包括日式居酒屋的环境,还挺惊艳的。至于Nano Banana Pro嘛...抱歉,它说它做不到。
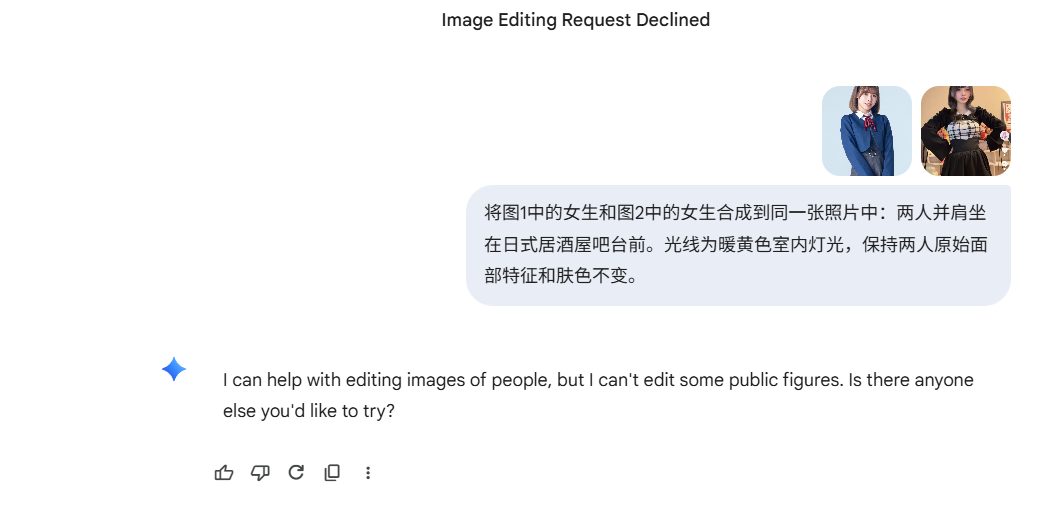
最后,让我们尝试一个相对复杂的风格迁移。

Qwen-Image-2.0并不是简单做了黑白、去饱和度处理,而是把笔墨的干湿浓淡都表现出来,最终成品真的很像水墨画。

不开玩笑地说,虽然整个Qwen-Image-2.0在图片审美上可能略逊于Nano Banana Pro,但是在图像编辑的一致性,还有文字渲染的正确率上都已经非常出色。这么一来,我寻思我接下来的PS工具应该是不用续费了...
总结:堪称中文版Banana
测完这一套流程,小雷看着满文件夹的对比图,心里的评价大概有了谱。怎么评价Qwen-Image-2.0呢?如果非要用一个词,我觉得应该是“靠谱”。
从数据上看,在Ai Arena这个全球公认的人工智能竞技场里,Qwen-Image-2.0的排名已经冲到了第一梯队,甚至在某些特定指标上(比如文本一致性、指令遵循度)把很多老牌的闭源模型甩在了身后。
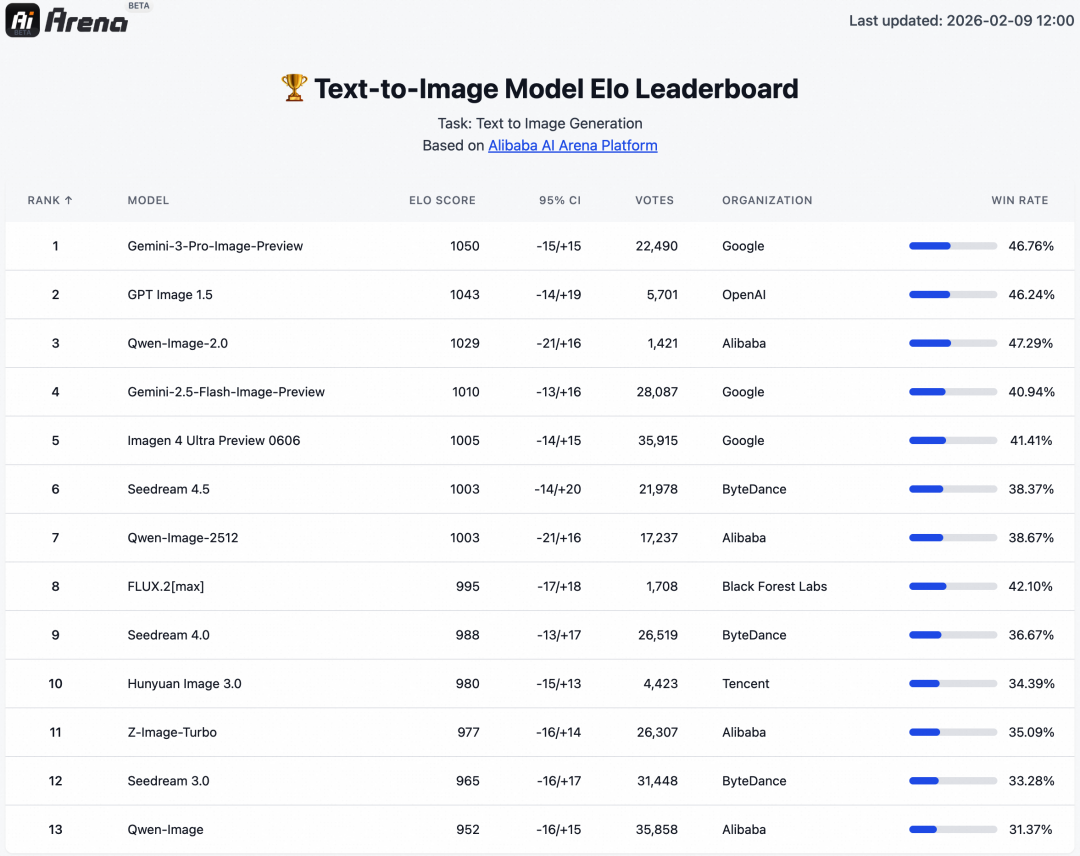
你敢信,在这样的效果背后,Qwen-Image-2.0的模型参数居然还变少了。从实测来看,这款模型的优点也很明显。首先是真·懂中文,不管是成语还是复杂的描述,它很少出现理解偏差;其次是文字生成能力,这简直是做海报的神器,彻底告别了AI生图全是鬼画符的时代;最后就是它的可控性,无论是修改图片还是保持一致性,都展现出了极高的生产力属性。
当然,不足也是有的。比如在艺术设计上,有时候感觉稍微有点板正,成品也缺少了Nano Banana Pro那种天马行空的惊艳感;其次,模型里的角色数据严重不足,需要提供详细的角色设定,漫画、插画的分镜也存在一定的提升空间。

如果你是追求艺术创作的爱好者,可能觉得它的表现有点过于平淡了。但瑕不掩瑜。
要说这次升级最明显的一点,那肯定是Qwen-Image-2.0同时拥有文生图和图像编辑能力。也就是说,同一个模型不只是生成图片,还能直接改图、补细节、调整布局、替换元素,整个过程可以在一条指令里完成。这让它用起来的感觉更像AI Photoshop,而不是单纯的AI画图工具。
强大的可控性,赋予了它极高的生产力空间。尤其是文字生成和版式控制,让它比很多模型都更适合做海报、电商图、UI草图这类商用设计。
从这个角度看,Qwen-Image-2.0的意义显然不只是模型能力提升,阿里更希望把图像模型变成生产力工具,而不是展示技术的玩具,让它进入电商、设计、广告这些真实工作流。这就是2026年AI图像生成的水平。而这,可能只是开始。如果你想了解更多AI技术动态和实战心得,欢迎访问云栈社区与开发者们交流探讨。
 发表于 2026-2-12 14:42:08
|
查看: 218|
回复: 0
发表于 2026-2-12 14:42:08
|
查看: 218|
回复: 0
