随着大模型的快速发展,由AI Agents驱动的新一代原生应用正在迅速崛起。这类应用以大模型为核心,通过各类智能体与丰富的数据进行交互,以完成复杂的任务。然而,Agent驱动的应用迭代快,需要同时维护文本、向量、图、键值等多种数据模态,且不同数据的访问模式和流量差异巨大,这给底层数据平台带来了前所未有的挑战。那么,面向未来的AI原生应用,究竟需要什么样的数据基座?
本文将探讨AI时代数据基座架构的设计思考,解析如何通过统一的架构应对多模态数据挑战,并分享在云计算与新硬件环境下的高性能工程实践。
AI Agent驱动的应用范式变革
当今,AI Agent正在引领整个软件范式的变革。在AI时代之前,我们谈论的是SaaS(软件即服务),软件作为工具构建了标准化的工作流,辅助人类完成任务。而当SaaS被AI驱动后,范式发生了根本变化:软件变得更智能,成为可以执行复杂任务、甚至具备一定自我演化能力的智能体(Agent)。从这个角度看,它不再仅仅是辅助工具,而是能够直接提供服务的实体。
在SaaS时代,软件有明确的工作流,用户提供输入,工作流完成任务。过程中产生的数据和状态通常被记录在数据库中,且多为结构化数据。此模式的特点是:数据由软件生成,是软件运行的“副产品”。因此,开发者对数据有较强的控制力:
- 数据格式由开发者定义。
- 数据量随软件规模和用户互动缓慢增长,总体可控。
而在Agent时代,情况截然不同。首先,开发重心从“工作流”转向“Agent编排”。应用可能由多个Agent协同工作,核心驱动力是大模型。一个关键区别在于:应用在启动之初就需要外部数据作为“燃料”。这些数据可能来自知识库或外部结构化数据源,用于让大模型具备领域特异性。这意味着数据的格式、规模并非开发者所能完全掌控。
此外,AI与用户的持续交互会产生更多新数据,这些数据又需要反哺回知识库,形成数据飞轮。我们接触的许多Agent项目,在第一天就考虑了数据的“反哺”机制。最终,应用提供的是一个完整的、智能的服务。
以一个金融场景为例,一个应用中可能包含市场分析、风控、合规、交易策略等多个Agent。
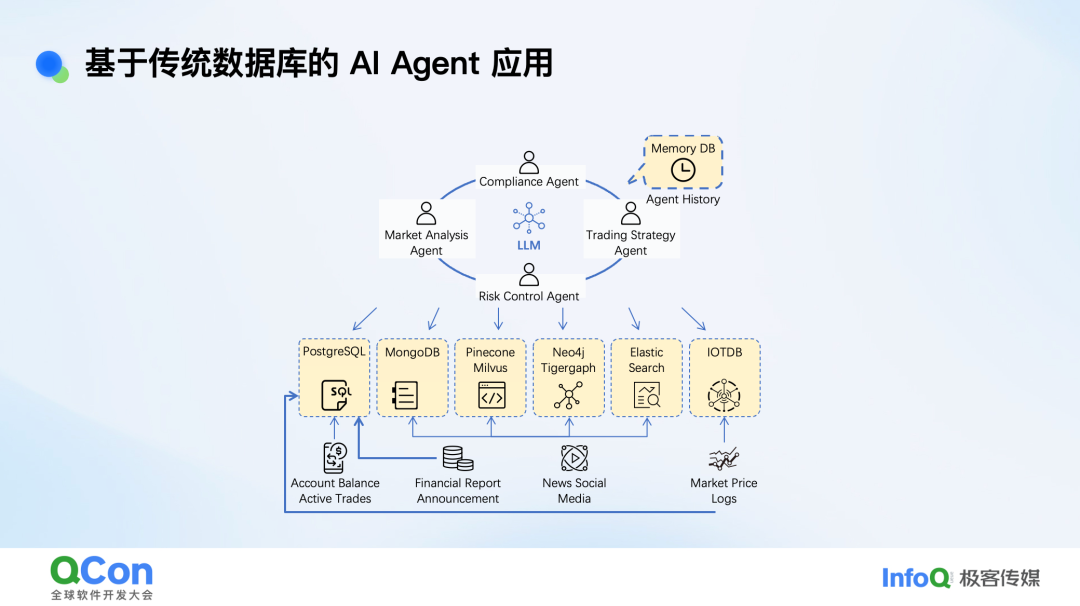
从数据视角看,这个应用可能需要多种数据库:
- 用户信息:通常存储在表格中,如 MySQL 或 PostgreSQL。
- 财报、公告、日志:半结构化数据,可能存放在 MongoDB 中。
- 文本与向量搜索:需要 Pinecone、Milvus 等向量数据库,或 Elasticsearch 进行全文检索,通常还需搭配排序器(Ranker)。
- 知识图谱:使用 Neo4j、Tigergraph 等图数据库。
- 对话记录与短期记忆:对延迟要求苛刻,需要基于内存的数据库,如 Redis。
因此,在搭建Agent应用的第一天,就可能涉及多种数据库。外部数据的规模不可控,对扩展性有要求;而实时交互的业务则对延迟有严苛要求,必然依赖内存数据库。
下图展示了一个典型的Agent工作流:
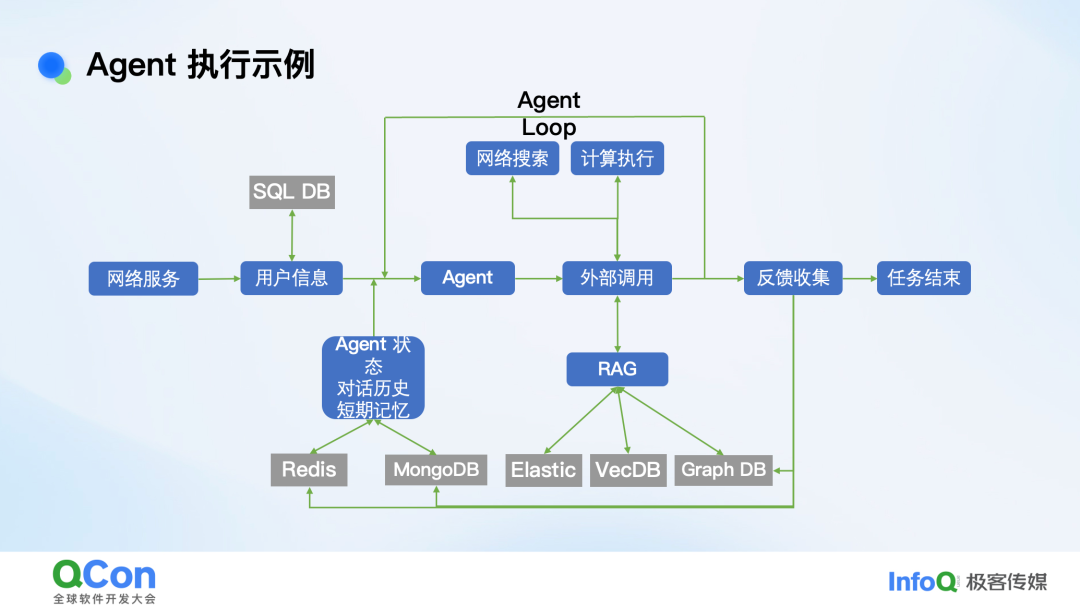
它通常是一个网络服务。用户登录后,需要查询关系型数据库获取用户信息。Agent内部的核心是“Agent Loop”(循环),因为交互往往需要多轮迭代。在此过程中,Agent会调用大模型、执行网络搜索或计算服务,并频繁使用 RAG(检索增强生成)从知识库中获取信息。
同时,Agent需要处理短期记忆和长期记忆,它们对延迟和容量的要求不同,往往需要不同的存储后端。

简单总结,从数据视角看,互联网时代与Agent时代的核心区别在于:
- 数据来源:前者数据由应用生成,可控;后者大量依赖外部数据,不可控且规模可能巨大。
- 数据类型:AI时代非结构化数据(文本、向量)占比极高。
- 数据积累:Agent的持续交互会快速积累大量对话、状态等数据。
AI原生应用面临的数据挑战
上述特点从系统层面给数据管理带来了多重挑战:
- 多模态支持:单一应用需要同时支持SQL、文档、向量、图、键值等多种数据模型。
- 数据同步与一致性:短期记忆需同步至长期记忆,应用输出需反馈至知识库,存在跨模态的数据流转需求。
- 差异化性能需求:不同数据库对延迟、吞吐、规模的要求各异。
- 运维管理复杂度:快速开发的应用面临传统大厂才有的多系统运维难题,而数据是核心资产,管理成本高昂。
总之,AI Agent驱动的应用在早期就会面临复杂的数据挑战,且数据飞轮的快速迭代进一步加剧了数据库系统的压力。
多模态数据基座:统一架构的设想
面对这些挑战,一个自然的思考是:能否有一个统一的数据架构来解决问题?答案是构建一个多模态数据基座。
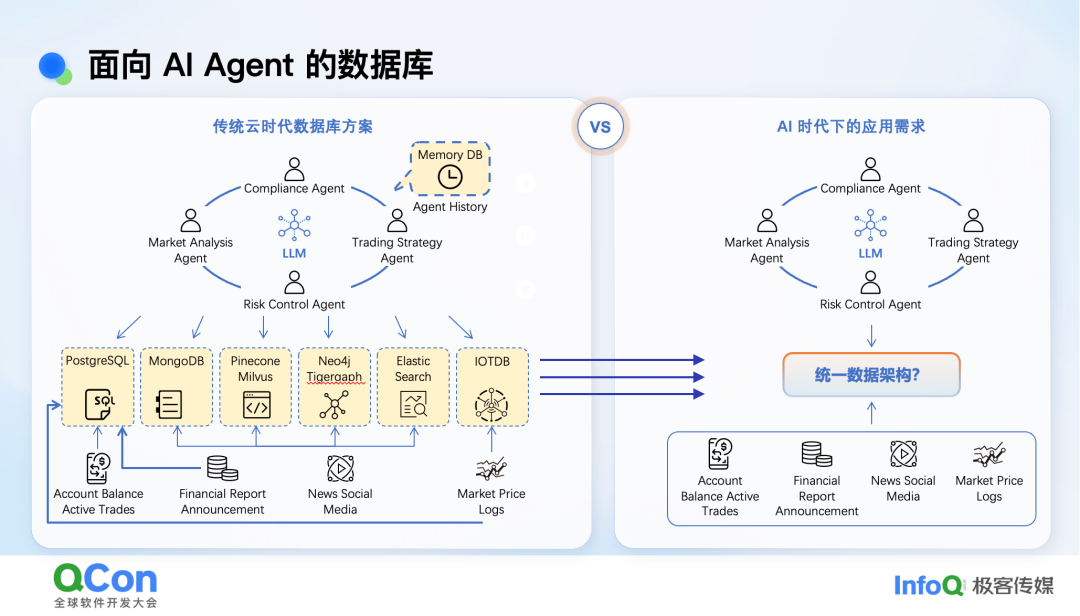
我们的设计目标有三点:
- 支持多种数据模态,并原生兼容现有API。例如,JSON API应与MongoDB兼容,SQL API应与MySQL兼容。使用标准API对开发者的可移植性和未来扩展至关重要。同时,性能是关键,多模态不能以牺牲性能为代价。
- 动态伸缩,自动管理。这与云原生的趋势完全吻合。
- 跨模态访问与一致性。需要消融不同数据库之间的壁垒,支持高效、一致的跨模态数据访问,而非通过中间件简单拼凑。
在阐述多模态架构前,先回顾一下数据库架构的演进历史。
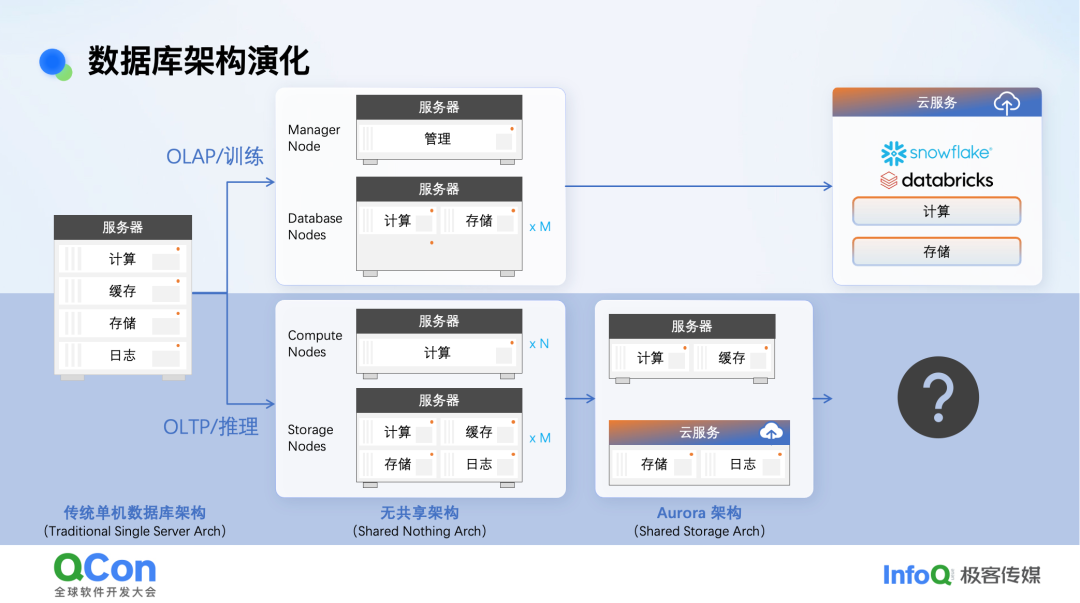
数据库早期是单机架构。随后分化为OLAP(分析型)和OLTP(事务型)。在云时代,OLAP数据库走向存算分离架构。而OLTP数据库的演进更为复杂,因为其极度依赖内存缓存来保证毫秒级延迟。无共享(Shared Nothing)架构下,计算与缓存分离,网络访问会引入延迟。因此,业界提出了类似Aurora的共享存储(Shared Storage)架构,将计算与缓存放在一起,下方连接共享存储,以保障低延迟。
我们的思路是,在计算与存储之间引入一个数据基层。
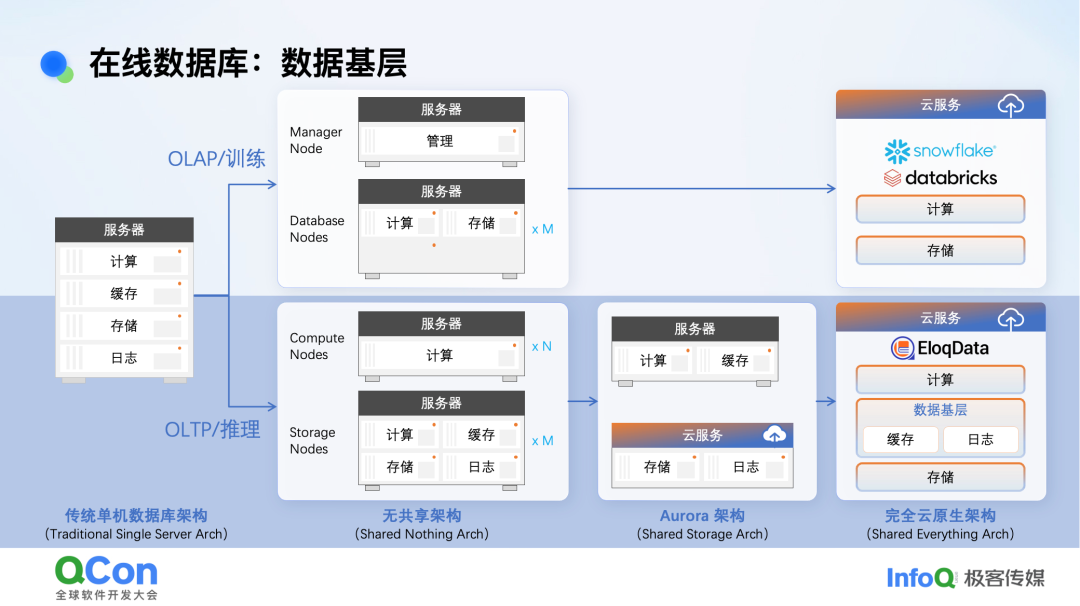
在这个基层中,缓存是核心,是保证所有在线数据操作低延迟的关键。无论是向量搜索、全文检索还是图遍历,热点数据都必须在缓存中。
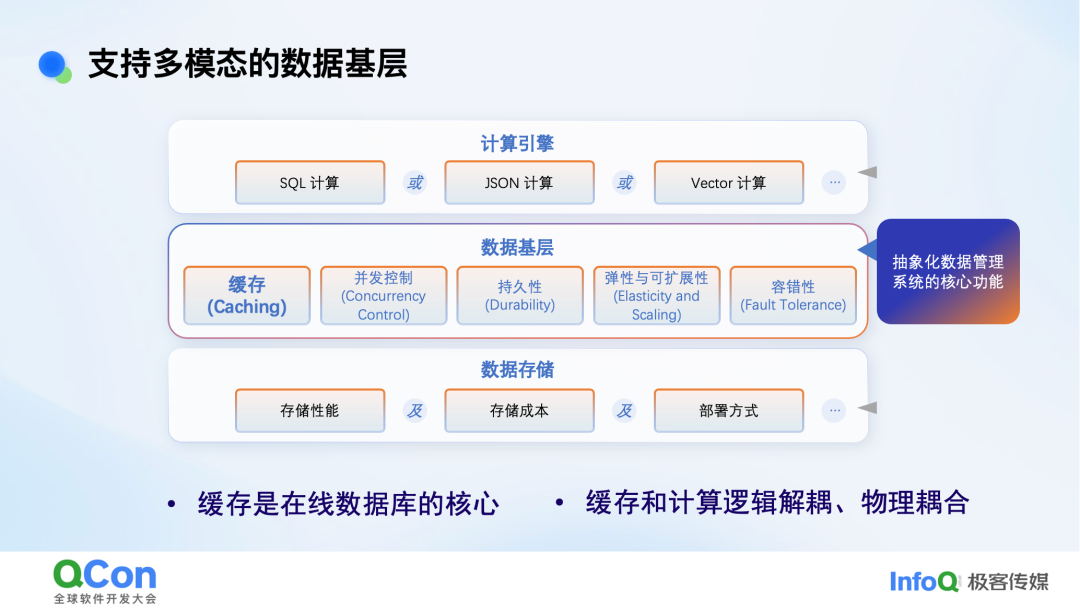
在我们的架构中,上层是可插拔的计算引擎(SQL、JSON、Vector等),下层是持久化存储,中间则是抽象出的数据基层。它封装了在线数据库的核心功能:缓存、并发控制、持久性、弹性扩展和容错。
其中,缓存与计算是逻辑解耦、物理耦合的。物理耦合指缓存尽量使用本地内存,减少网络读取;逻辑解耦指通过统一的缓存抽象来弥合不同数据模态的差异。

这里的缓存并非简单的键值哈希表,而是为了支持复杂数据结构(如倒排索引、向量索引、图邻接表)而设计。
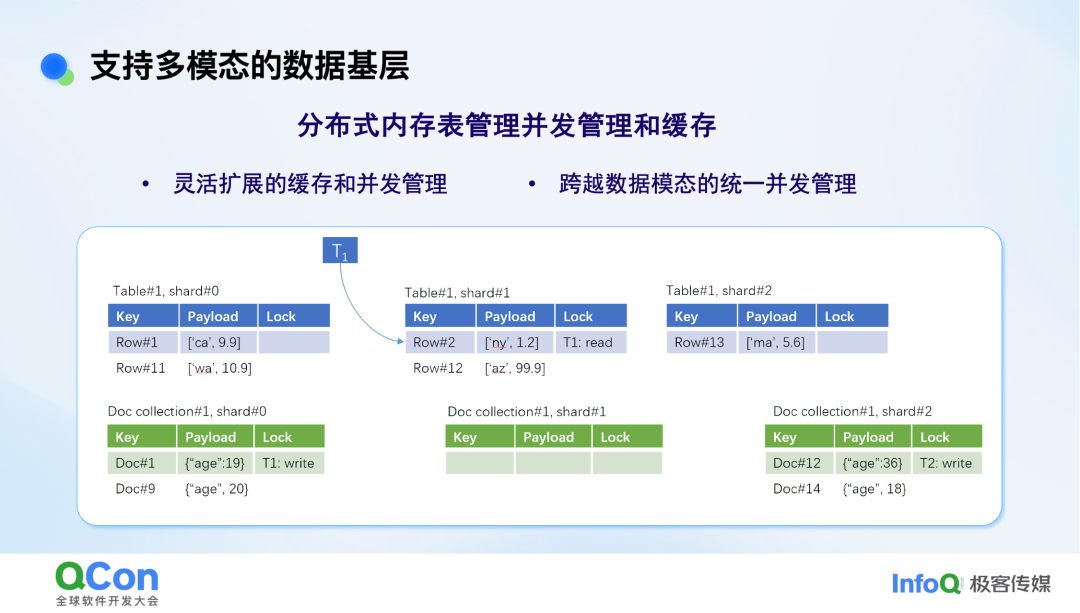
我们通过一个逻辑上的分布式内存表来管理不同模态的数据,并实现统一的并发控制。
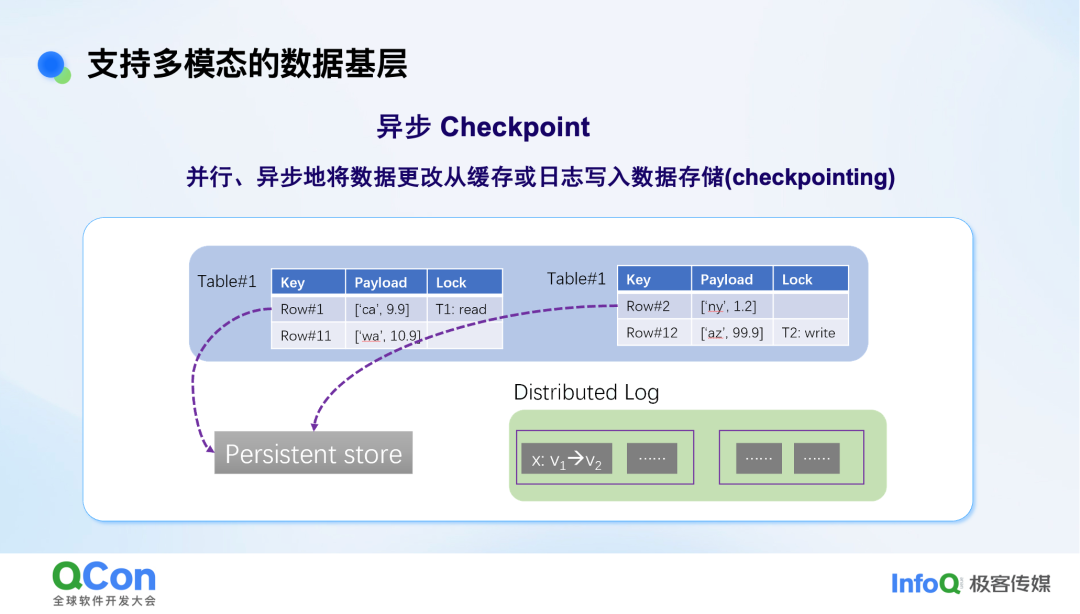
数据更改首先实时更新到缓存和日志中,随后通过异步Checkpoint机制并行、异步地持久化到存储,避免实时操作阻塞。

系统具备容错与恢复能力,在发生故障时,可以从日志和存储中恢复未完成Checkpoint的数据。
通过这样的设计,我们构建了一个融合数据库架构。
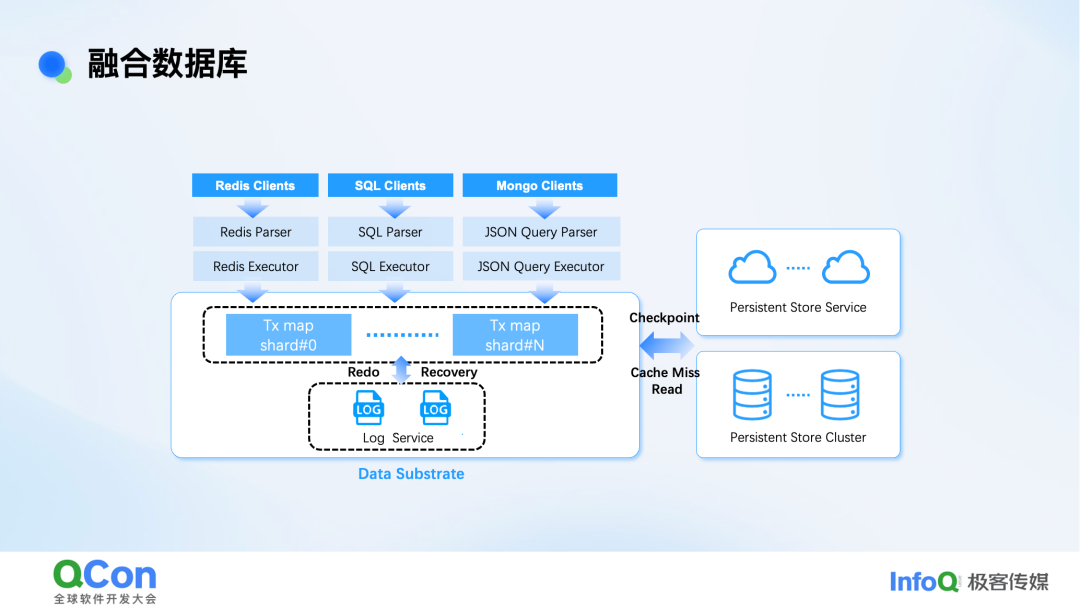
它通过统一的数据基层,装配多种计算引擎。由于缓存与计算物理耦合,性能可媲美原生数据库;由于兼容标准协议,生态迁移成本低。

总结其优势:支持多模态并兼容现有标准;提供跨模态一致访问;可通过垂直与水平伸缩满足多样化性能需求;实现单一系统的统一管理。
面向未来硬件的工程实践
工程实践需要适应AI时代的基础设施环境:云计算、高速网络、NVMe存储以及GPU等高性能硬件。
过去十年,CPU性能增长约1.5倍,而存储性能(IOPS)增长超过11倍,网络性能增长约20倍。趋势表明,存储IOPS的快速增长将使得数据系统逐渐变为CPU瓶颈。若不优化,传统数据库性能将无法随IO设备升级而提升。
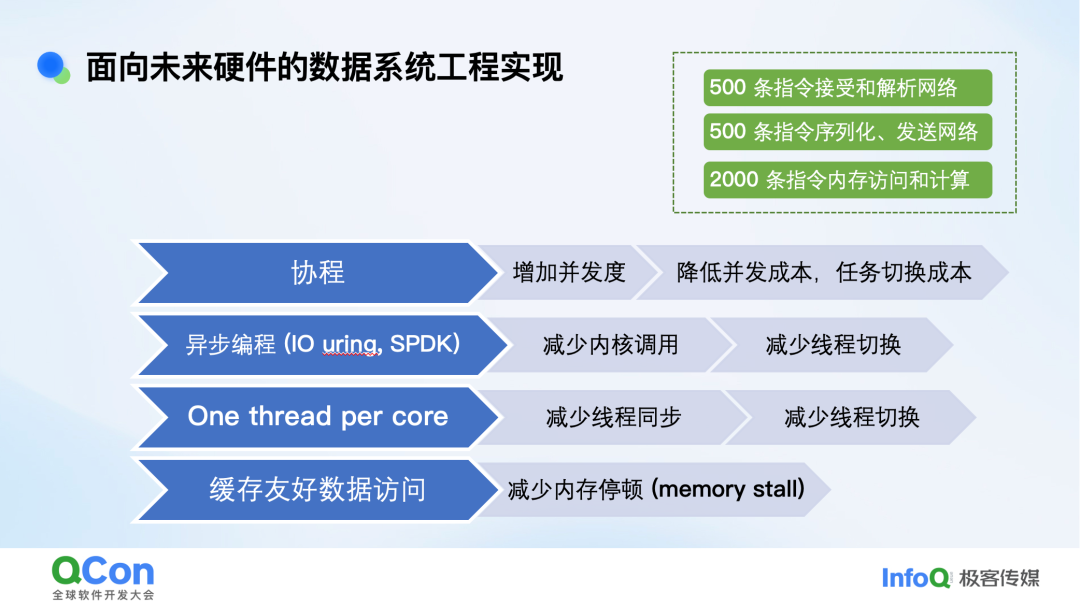
为此,我们采取了一系列工程优化:
- 协程:增加并发度,降低任务切换成本。
- 异步编程(如io_uring, SPDK):减少内核调用与线程切换。
- One thread per core:减少线程同步与切换开销。
- 缓存友好数据访问:减少内存停顿(memory stall)。
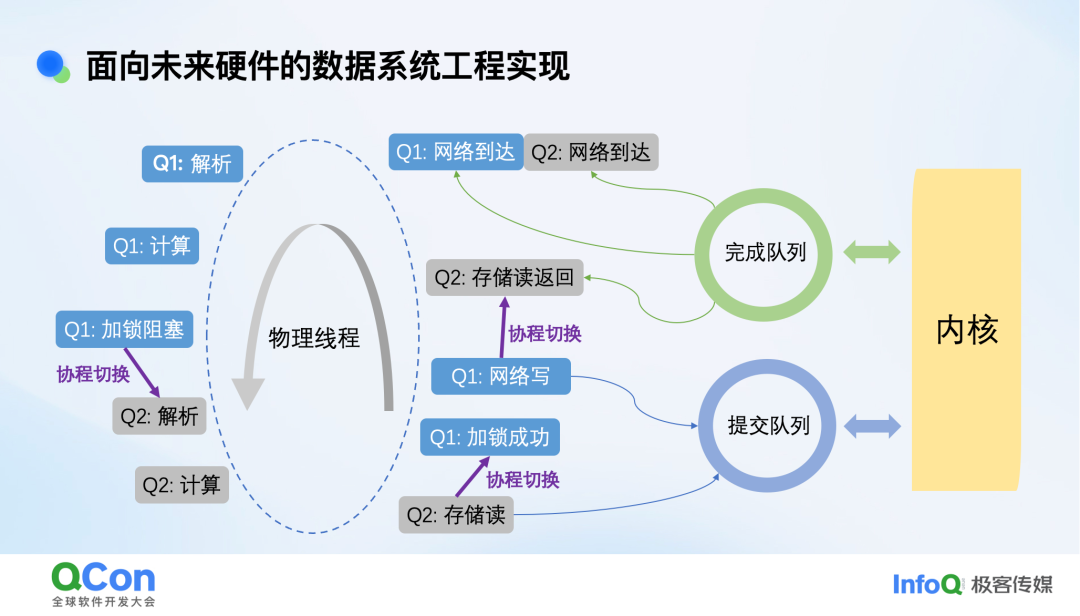
我们实现了一个实验性的KV存储(EloqStore)来验证这些理念。

其特点是:多读单写;数据结构为Crash-safe B+-tree;每个请求由协程执行;IO请求通过io_uring提交后即切换协程。
我们在特定环境中进行了测试:
- 16核CPU
- 仅分配4GB内存给KV缓存(故意制造缓存未命中)
- NVMe SSD(三星9100 Pro, PCIe 4环境下随机读约100万IOPS)
- 数据量:10亿条记录,Key 8字节,Value 64字节,总容量约60-70GB

性能对比如下图所示:
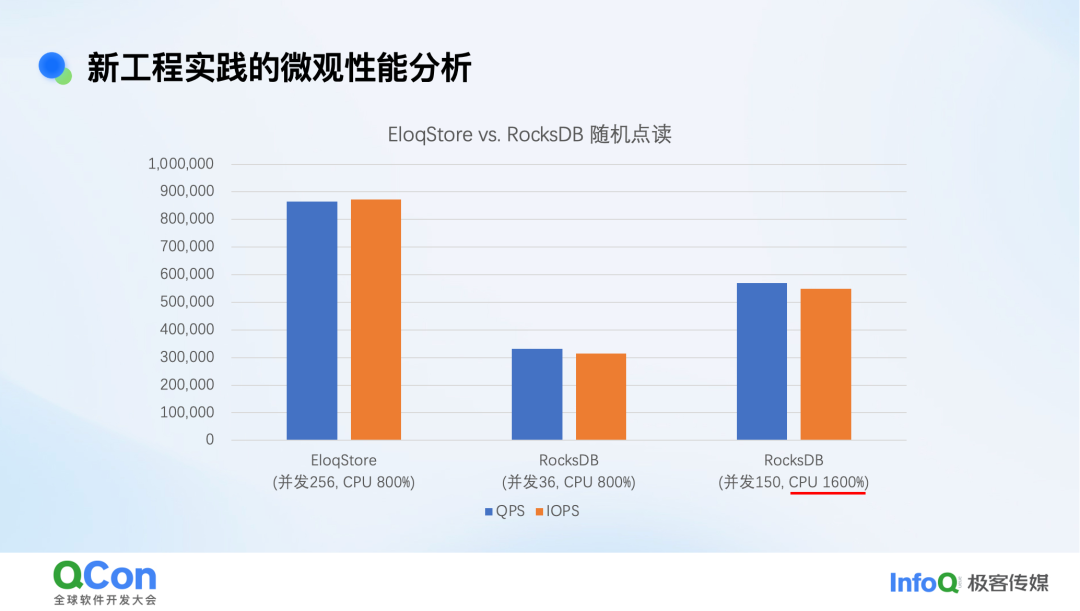
测试结果表明,在相同的CPU占用率下,我们基于新工程实践的设计(EloqStore)能够接近硬件IOPS的理论上限,性能显著优于传统架构(RocksDB)。这证实了传统数据库架构在新型硬件下会遇到CPU瓶颈,单纯升级存储设备收益有限。
总结与展望
AI Agent时代正引发软件范式的变革,这必然导致数据管理方式的巨变。未来的数据基座需要:支持多模态数据、原生兼容现有API、提供高性能访问、具备弹性伸缩能力,并易于管理。
相应的工程实践也必须面向未来硬件,通过协程、异步IO、缓存优化等手段突破CPU瓶颈,充分释放高速存储与网络的潜力。希望本次关于多模态数据基座架构与工程实践的探讨,能为你在云栈社区构建下一代AI应用提供有价值的参考。
 发表于 2026-2-13 02:20:11
|
查看: 222|
回复: 0
发表于 2026-2-13 02:20:11
|
查看: 222|
回复: 0
