1. 块I/O层概述与核心地位
1.1 什么是块I/O层?
想象一下,你的计算机系统就像一个繁忙的物流中心。当应用程序需要读取或写入数据时(比如保存文档或加载视频),这些请求就像一个个包裹,需要从“内存仓库”运送到“磁盘仓库”。Linux块I/O层正是这个物流中心的智能调度系统,它负责:
- 接收来自上层(文件系统、虚拟内存系统)的运输订单(I/O请求)。
- 将这些订单合并、优化,并规划最佳的运输路线。
- 指挥具体的“运输车队”(块设备驱动)完成实际的运输任务。
- 确保整个运输过程高效、有序,避免拥堵。
用技术术语来说,块I/O层位于VFS(虚拟文件系统)之下,块设备驱动之上,是Linux内核中处理块设备I/O请求的核心子系统。
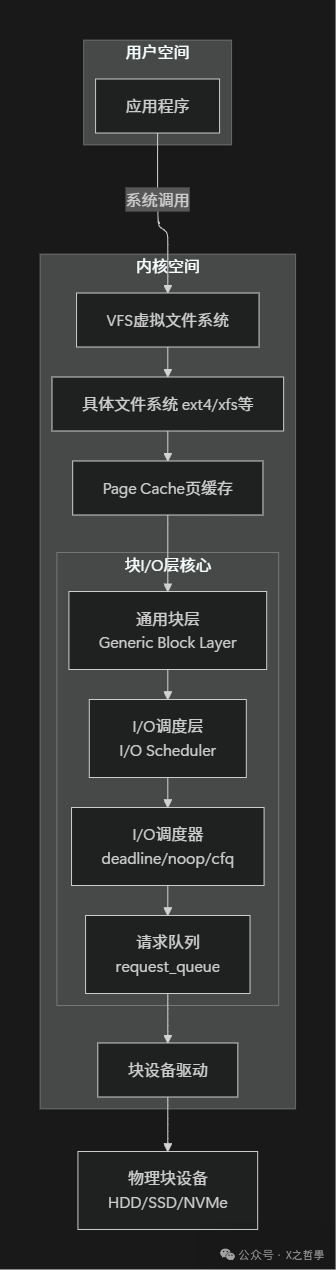
1.2 为什么需要块I/O层?
直接访问硬件会面临诸多挑战:
- 设备多样性:硬盘、SSD、NVMe、U盘...每种设备的特性和工作方式各不相同。
- 性能优化需求:机械硬盘需要优化磁头移动路径,而SSD则需关注磨损均衡。
- 请求合并:将多个小的I/O请求合并成大的请求,可以显著减少开销。
- 优先级管理:确保交互式进程的I/O请求能得到更快的响应。
- 错误处理:需要妥善处理介质损坏、传输错误等异常情况。
块I/O层的核心价值在于:
- 抽象统一接口:对上层提供统一的I/O操作接口,隐藏底层硬件的差异。
- 智能调度优化:根据设备特性(如是否为旋转磁盘)优化请求的执行顺序。
- 资源高效利用:通过减少不必要的磁盘寻道时间,大幅提高吞吐量。
- 服务质量保证:确保关键请求得到及时处理,避免“饥饿”现象。
2. 核心概念深度解析
2.1 块设备 vs 字符设备
| 特性 |
块设备 (Block Device) |
字符设备 (Char Device) |
| 数据单位 |
固定大小的块(通常512B-4KB) |
字节流,无固定大小 |
| 访问方式 |
随机访问,支持seek |
顺序访问,通常不支持seek |
| 缓存 |
有页缓存(Page Cache) |
通常无缓存或仅有简单缓冲 |
| 典型设备 |
硬盘、SSD、U盘、SD卡 |
键盘、鼠标、串口、打印机 |
| 性能特点 |
吞吐量优先,延迟敏感 |
实时性优先,延迟敏感 |
| I/O调度 |
需要复杂的调度优化 |
简单直接传递 |
生活比喻:
- 块设备像图书馆:书籍(数据块)有固定的位置编号,你可以随机借阅任何一本书。图书管理员(块I/O层)会优化整理书籍的摆放位置,以便快速查找。
- 字符设备像自来水管道:水流(数据)是连续不断的,你无法直接跳到管道中间取水,数据需要被实时处理。
2.2 核心数据结构解剖
2.2.1 struct bio - I/O请求的基本单位
bio(Block I/O)是块I/O层最基础的数据结构,它代表单个I/O操作。
// 简化版bio结构(基于Linux 5.x内核)
struct bio {
struct bio *bi_next; // 请求队列中的下一个bio
struct block_device *bi_bdev; // 目标块设备
unsigned long bi_flags; // 状态标志
unsigned long bi_rw; // 读写标志
struct bvec_iter bi_iter; // 迭代器,跟踪当前处理位置
unsigned int bi_vcnt; // bio_vec数量
unsigned int bi_max_vecs; // bio_vec最大容量
atomic_t bi_cnt; // 引用计数
struct bio_vec *bi_io_vec; // bio_vec数组指针
struct bio_vec bi_inline_vecs[];// 内联bio_vec(小请求优化)
};
// bio_vec描述内存页片段
struct bio_vec {
struct page *bv_page; // 对应的内存页
unsigned int bv_len; // 数据长度
unsigned int bv_offset; // 页内偏移
};
// bvec_iter跟踪处理进度
struct bvec_iter {
sector_t bi_sector; // 设备上的起始扇区
unsigned int bi_size; // 剩余字节数
unsigned int bi_idx; // 当前bio_vec索引
unsigned int bi_bvec_done; // 当前bio_vec中已完成的字节
};
bio的关键特性:
- 分散-聚集I/O:一个
bio可以描述多个在物理内存中不连续的区域,一次性进行传输。
- 向量化操作:通过
bio_vec数组支持对多个内存页的操作。
- 迭代器模式:
bvec_iter结构支持I/O操作的部分完成与恢复,增强了鲁棒性。
- 引用计数:支持被多个组件共享,并实现安全的延迟释放。
生活比喻:
bio就像一张快递订单:
bi_bdev:目的地仓库。bi_rw:是取件还是送货(读或写)。bio_vec:包裹清单(多个包裹可能放在家里的不同位置)。bvec_iter:快递员当前正在处理清单上的第几个包裹。
2.2.2 struct request - 调度优化的请求单元
多个在磁盘上位置相邻或相关的bio会被合并成一个request,以便进行统一的调度优化。
// 简化版request结构
struct request {
struct list_head queuelist; // 请求队列链表节点
struct request_queue *q; // 所属请求队列
struct bio *bio; // 请求中的第一个bio
struct bio *biotail; // 请求中的最后一个bio
unsigned long flags; // 请求标志
int errors; // 错误计数
sector_t sector; // 起始扇区
sector_t hard_sector; // 原始起始扇区
unsigned long nr_sectors; // 总扇区数
unsigned int cmd_flags; // 命令标志
unsigned int cmd_type; // 命令类型
void *special; // 特殊目的指针
char *buffer; // 数据缓冲区(传统方式)
struct request *next_rq; // 下一个请求(用于排序)
};
request与bio的关系:
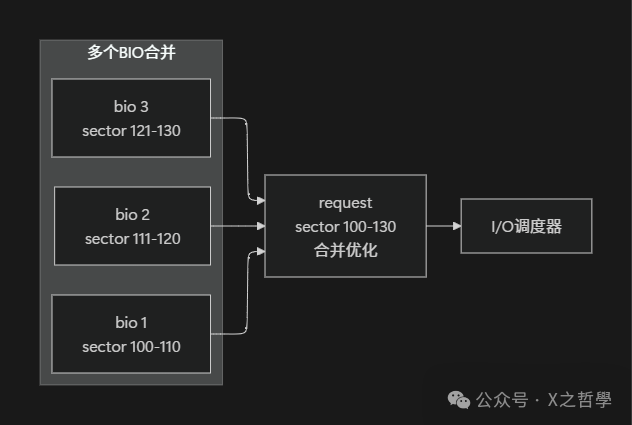
生活比喻:
bio:单个快递订单。request:快递员的一趟路线规划,这趟规划合并了送往同一小区或相邻地址的多个订单。- 合并优化:快递员把同一栋楼的多个包裹安排在一次派送中,避免了重复跑路。
2.2.3 struct request_queue - I/O请求的调度中心
// 简化版request_queue结构
struct request_queue {
// 队列管理
struct list_head queue_head; // 待处理请求链表
struct request *last_merge; // 上次合并的请求
struct elevator_queue *elevator; // I/O调度器
// 队列限制和特性
unsigned long nr_requests; // 最大请求数
unsigned int nr_congestion_on; // 拥塞开始阈值
unsigned int nr_congestion_off;// 拥塞结束阈值
// 设备特性
unsigned long max_hw_sectors; // 最大扇区数
unsigned int max_segments; // 最大段数
unsigned int logical_block_size; // 逻辑块大小
unsigned int physical_block_size;// 物理块大小
// 操作函数
request_fn_proc *request_fn; // 请求处理函数
make_request_fn *make_request_fn; // 创建请求函数
// 锁和同步
spinlock_t queue_lock; // 队列锁
struct kobject kobj; // kobject用于sysfs
// 统计信息
unsigned long nr_rb[2]; // 读写请求计数
};
2.3 I/O调度器详解
I/O调度器是块I/O层的“交通指挥中心”,它决定了请求的执行顺序,对性能尤其是机械硬盘的性能至关重要。
2.3.1 调度器类型对比
| 调度器 |
工作原理 |
适用场景 |
优点 |
缺点 |
| Noop |
简单的先进先出(FIFO)队列,基本不排序。 |
SSD、高速存储设备、虚拟机内磁盘。 |
CPU开销极低,延迟非常小。 |
没有任何优化,不适合机械硬盘。 |
| Deadline |
维护读/写两个队列,并设置截止时间,防止请求饥饿。 |
通用场景,尤其是混合读写负载。 |
避免请求饥饿,读写响应时间有上限。 |
复杂度中等,对小文件随机读写优化一般。 |
| CFQ |
完全公平队列,类似进程调度,为每个进程分配时间片和带宽。 |
桌面系统、多用户环境。 |
公平性非常好,能为不同进程提供服务质量保证。 |
CPU开销较大,平均延迟可能较高。 |
| Kyber |
基于延迟目标的自适应调度,为读/写分别设置延迟目标。 |
多队列设备(如NVMe SSD)。 |
延迟可预测,能自适应不同负载。 |
较新,需要硬件支持多队列。 |
| BFQ |
基于预算的公平队列,在CFQ基础上改进,更注重低延迟和公平性。 |
桌面系统、实时性要求高的环境。 |
极高的公平性和低延迟,交互体验好。 |
CPU开销最大。 |
2.3.2 Deadline调度器深度解析
// Deadline调度器核心数据结构
struct deadline_data {
// 排序红黑树(按扇区位置排序)
struct rb_root sort_list[2]; // 0:读, 1:写
// FIFO队列(按请求到达时间排序)
struct list_head fifo_list[2]; // 0:读, 1:写
// 批处理队列
struct list_head dispatch; // 待分发到驱动层的队列
// 参数配置
int fifo_batch; // 一次从FIFO队列中取出的请求数
int fifo_expire[2]; // 读/写请求的超时时间(毫秒)
int writes_starved; // 在处理多少次读请求后,必须处理一次写请求
int front_merges; // 是否启用前向合并
};
Deadline调度算法流程:
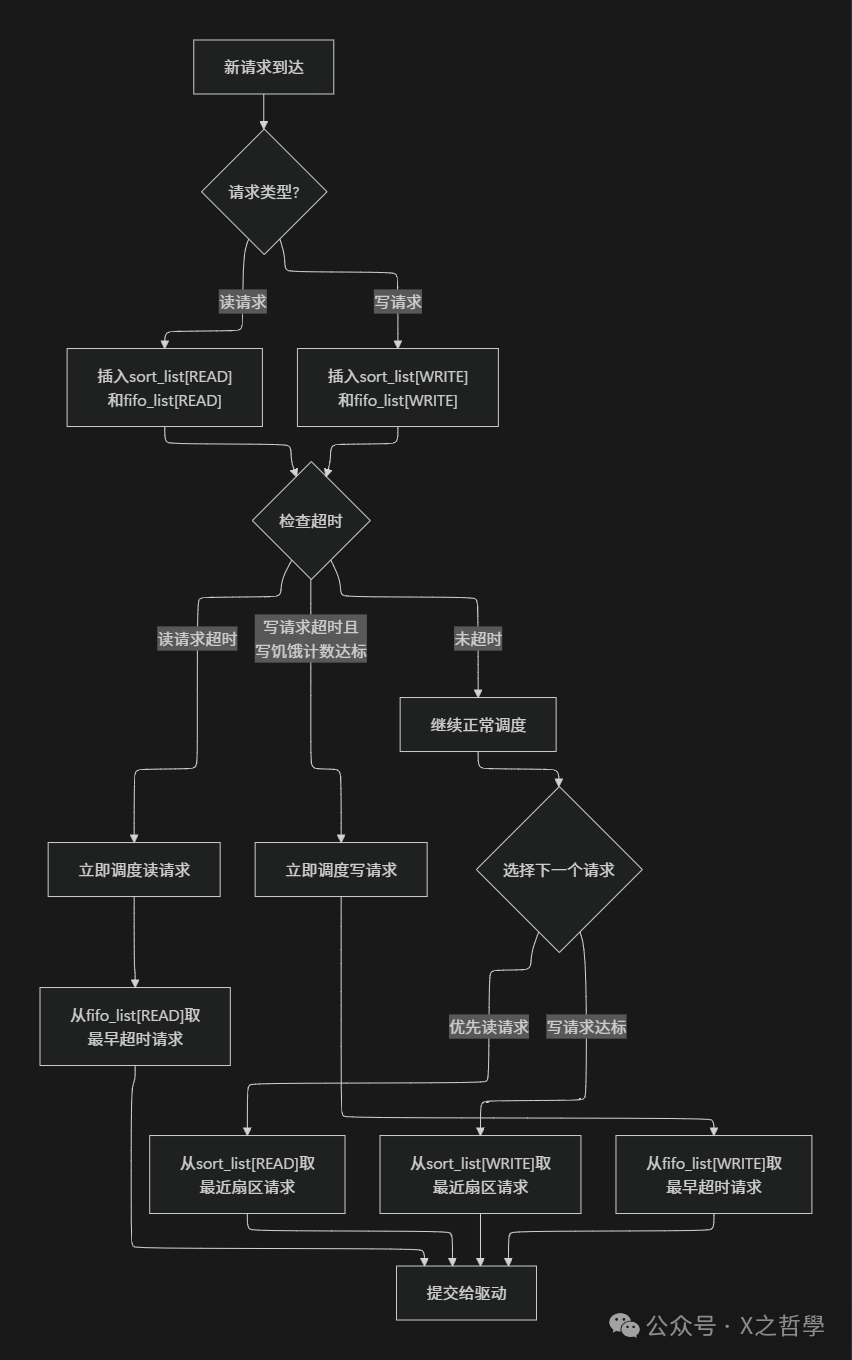
生活比喻:
Deadline调度器就像医院急诊科的分诊系统:
sort_list:按病情严重程度(扇区位置临近程度)排序的病人,优先处理危重且集中的病例。fifo_list:按到达时间排序的候诊病人。fifo_expire:最长等待时间限制,超过这个时间,病人(请求)的优先级会提升。writes_starved:确保写请求(可能不那么紧急但重要)不会因为读请求过多而永远得不到处理。
3. 块I/O完整路径分析
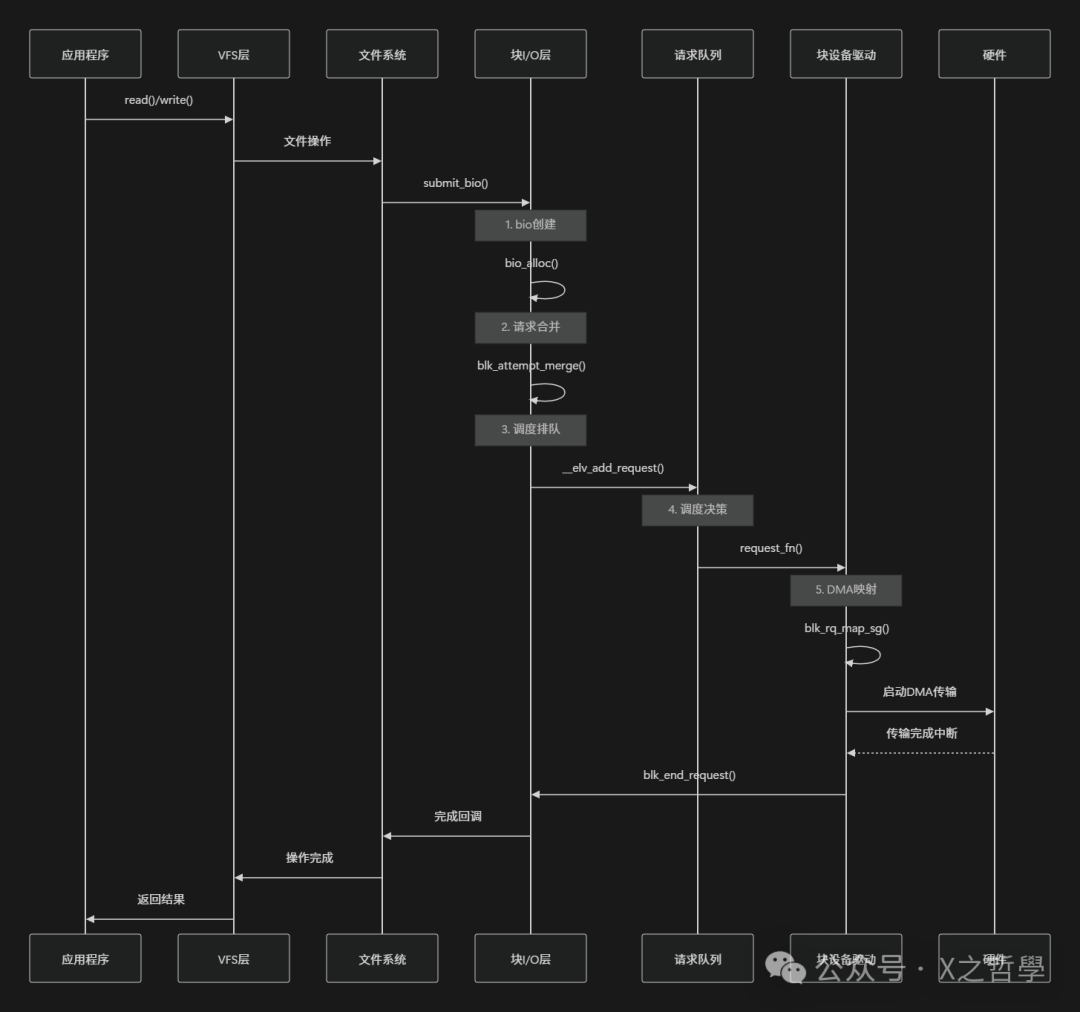
3.1 I/O路径全景图
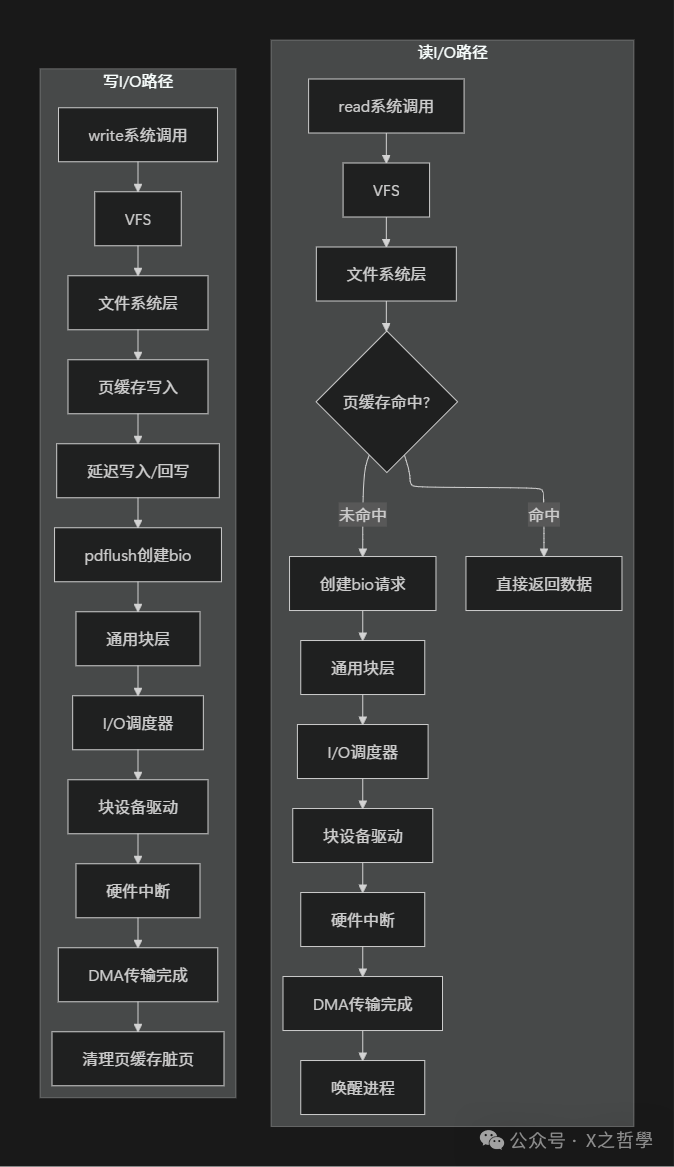
3.2 关键函数调用链
3.2.1 读路径核心函数
用户空间: read() -> glibc包装
内核入口: SYSCALL_DEFINE3(read, ...)
↓
vfs_read()
↓
特定文件系统file_operations->read()
↓
generic_file_read_iter() // 通用文件读取接口
↓
do_generic_file_read() // 核心页缓存逻辑
↓
page_cache_sync_readahead() // 触发预读
↓
ext4_file_read_iter() // 以ext4为例的具体实现
↓
submit_bio() // 提交bio到块层
↓
generic_make_request() // 通用块层入口
↓
blk_queue_bio() // 请求合并和排队
↓
__elv_add_request() // 添加到调度器队列
↓
请求被调度器选中并执行
↓
块设备驱动request_fn()
↓
硬件DMA传输
3.2.2 写路径核心函数
用户空间: write() -> glibc包装
内核入口: SYSCALL_DEFINE3(write, ...)
↓
vfs_write()
↓
特定文件系统file_operations->write()
↓
__generic_file_write_iter() // 通用文件写入接口
↓
generic_perform_write() // 执行写入操作
↓
balance_dirty_pages_ratelimited() // 脏页平衡控制
↓
特定文件系统写入方法(如ext4的write_begin/end)
↓
mark_buffer_dirty() // 标记缓冲区为“脏”
↓
(延迟写入)由pdflush/回写线程稍后处理
↓
submit_bio() // 提交写bio
↓
...后续路径与读类似...
3.3 请求合并优化
请求合并是块I/O层提升机械硬盘性能最重要的优化之一,它能显著减少磁头寻道时间。
3.3.1 合并类型
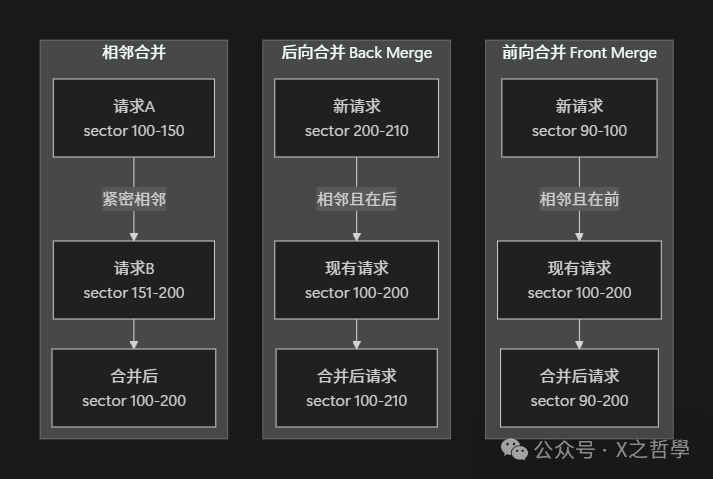
3.3.2 合并算法实现
// 请求合并的核心逻辑(简化版)
static bool blk_attempt_merge(struct request_queue *q,
struct request *rq,
struct bio *bio) {
if (!blk_rq_merge_ok(rq, bio))
return false;
// 检查前向合并:新bio的结束扇区紧挨着旧请求的开始扇区
if (blk_rq_pos(rq) == bio_end_sector(bio)) {
rq->biotail->bi_next = bio;
rq->biotail = bio;
rq->__data_len += bio->bi_iter.bi_size;
rq->nr_phys_segments++;
return true;
}
// 检查后向合并:新bio的开始扇区紧挨着旧请求的结束扇区
if (blk_rq_end_sector(rq) == bio->bi_iter.bi_sector) {
bio->bi_next = rq->bio;
rq->bio = bio;
rq->__sector = bio->bi_iter.bi_sector;
rq->__data_len += bio->bi_iter.bi_size;
rq->nr_phys_segments++;
return true;
}
return false;
}
4. 块设备驱动开发实例
4.1 最简单的块设备驱动框架
下面是一个实现内存块设备(RAM Disk)驱动的完整示例:
#include <linux/module.h>
#include <linux/blkdev.h>
#include <linux/vmalloc.h>
#define RAMDISK_SIZE (1024 * 1024 * 16) // 16MB内存盘
#define SECTOR_SIZE 512
static struct my_block_device {
struct request_queue *queue;
struct gendisk *gd;
u8 *data;
spinlock_t lock;
} dev;
// 请求处理函数
static void my_request_fn(struct request_queue *q) {
struct request *req;
while ((req = blk_fetch_request(q)) != NULL) {
struct my_block_device *dev = req->rq_disk->private_data;
unsigned long start = blk_rq_pos(req) * SECTOR_SIZE;
unsigned long len = blk_rq_bytes(req);
// 数据缓冲区
void *buffer;
if (rq_data_dir(req) == WRITE) {
// 写请求:从请求复制数据到内存盘
buffer = kmap_atomic(bio_page(req->bio)) + bio_offset(req->bio);
memcpy(dev->data + start, buffer, len);
kunmap_atomic(buffer);
} else {
// 读请求:从内存盘复制数据到请求
buffer = kmap_atomic(bio_page(req->bio)) + bio_offset(req->bio);
memcpy(buffer, dev->data + start, len);
kunmap_atomic(buffer);
}
// 完成请求
if (!__blk_end_request_cur(req, 0))
req = NULL;
}
}
// 磁盘操作结构
static struct block_device_operations my_fops = {
.owner = THIS_MODULE,
};
static int __init my_init(void) {
// 1. 分配内存盘空间
dev.data = vmalloc(RAMDISK_SIZE);
if (!dev.data)
return -ENOMEM;
// 2. 初始化自旋锁
spin_lock_init(&dev.lock);
// 3. 创建请求队列
dev.queue = blk_init_queue(my_request_fn, &dev.lock);
if (!dev.queue) {
vfree(dev.data);
return -ENOMEM;
}
// 4. 分配gendisk结构
dev.gd = alloc_disk(1); // 1个次设备号
if (!dev.gd) {
blk_cleanup_queue(dev.queue);
vfree(dev.data);
return -ENOMEM;
}
// 5. 设置gendisk属性
dev.gd->major = register_blkdev(0, "myramdisk");
dev.gd->first_minor = 0;
dev.gd->fops = &my_fops;
dev.gd->queue = dev.queue;
dev.gd->private_data = &dev;
snprintf(dev.gd->disk_name, DISK_NAME_LEN, "myramdisk");
set_capacity(dev.gd, RAMDISK_SIZE / SECTOR_SIZE);
// 6. 添加磁盘到系统
add_disk(dev.gd);
printk(KERN_INFO "My RAM disk initialized: %lu sectors\n",
RAMDISK_SIZE / SECTOR_SIZE);
return 0;
}
static void __exit my_exit(void) {
del_gendisk(dev.gd);
put_disk(dev.gd);
blk_cleanup_queue(dev.queue);
unregister_blkdev(dev.gd->major, "myramdisk");
vfree(dev.data);
printk(KERN_INFO "My RAM disk removed\n");
}
module_init(my_init);
module_exit(my_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Kernel Developer");
MODULE_DESCRIPTION("Simple RAM disk block device driver");
4.2 驱动与块I/O层的交互
5. 性能优化技术深度剖析
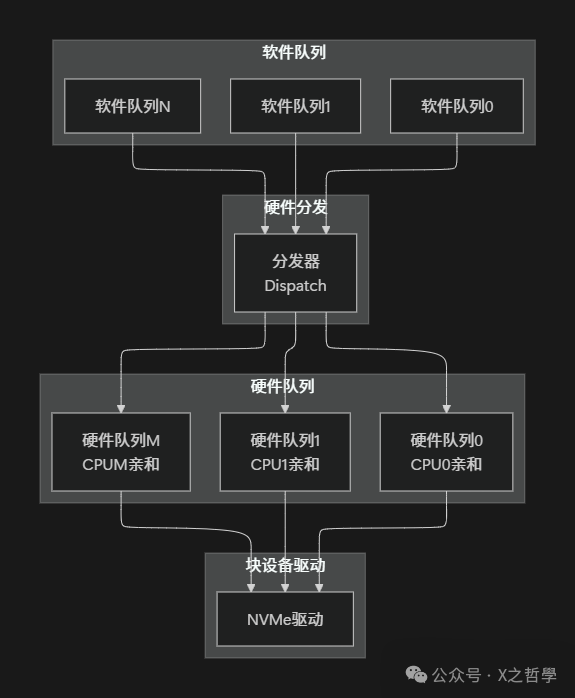
5.1 多队列块层(blk-mq)
传统的单请求队列块层在高速NVMe设备上容易成为瓶颈,blk-mq(Multi-Queue)架构应运而生,它能够充分利用多核CPU和设备的并行能力。
5.1.1 blk-mq架构
5.1.2 blk-mq核心数据结构
// 多队列硬件上下文(每个硬件队列一个)
struct blk_mq_hw_ctx {
struct blk_mq_ctx **ctxs; // 软件上下文数组
unsigned long state; // 状态标志
unsigned int queue_num; // 队列编号
atomic_t nr_active; // 活动请求数
struct request_queue *queue; // 所属请求队列
struct blk_mq_tags *tags; // 标签集合
struct blk_mq_ops *ops; // 操作函数
};
// 多队列软件上下文(通常每个CPU核心一个)
struct blk_mq_ctx {
unsigned int cpu; // 关联的CPU编号
unsigned int index_hw; // 对应的硬件队列索引
struct list_head rq_list; // 请求链表
struct blk_mq_hw_ctx *hctxs[]; // 硬件上下文指针数组
};
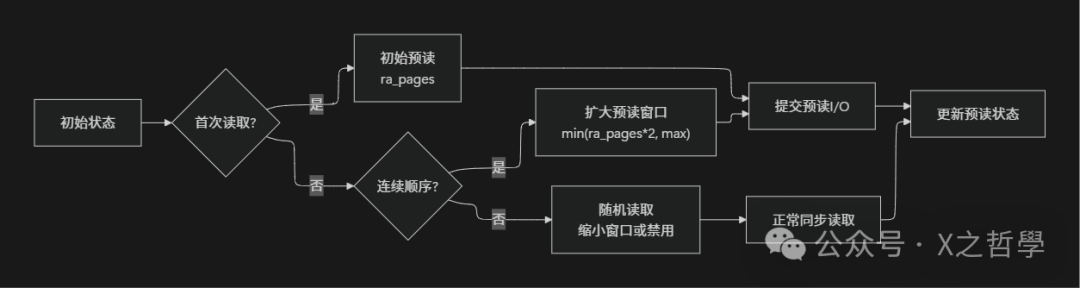
5.2 I/O预读(Read-ahead)机制
预读是提高顺序读性能的关键技术,它基于局部性原理,在应用程序实际请求数据之前,预先将后续可能用到的数据读入页缓存。
// 预读算法核心状态结构
struct file_ra_state {
pgoff_t start; // 当前预读窗口的起始页索引
unsigned int size; // 当前预读窗口的大小(页数)
unsigned int async_size; // 异步预读的大小
unsigned int ra_pages; // 最大预读页数
unsigned int mmap_miss; // mmap访问缺失计数
loff_t prev_pos; // 上次读取的位置
};
预读状态机:
5.3 回写(Writeback)机制
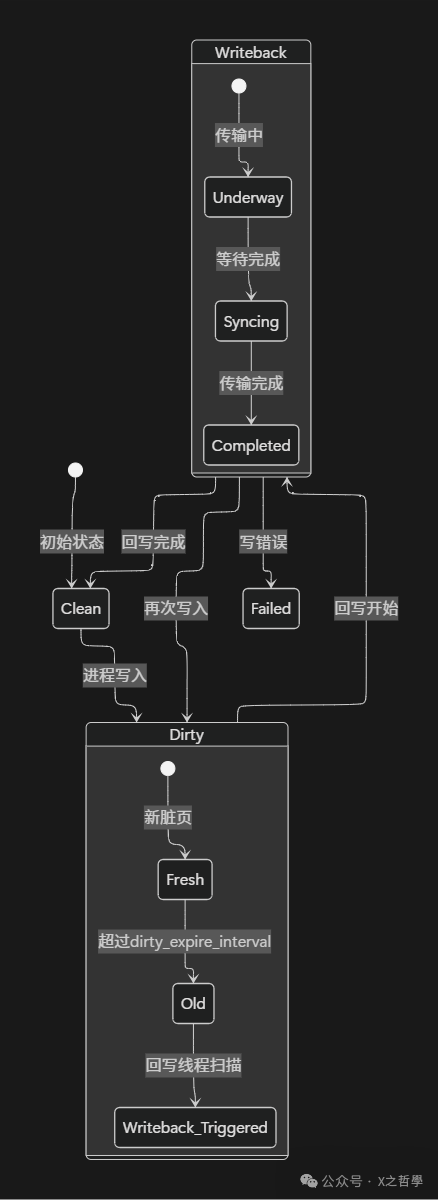
Linux采用复杂的回写机制来平衡内存性能和数据可靠性。写入的数据通常先保存在页缓存(脏页)中,由后台线程定期或根据条件刷写到磁盘。
5.3.1 回写控制参数
| 参数 |
默认值 |
描述 |
dirty_background_ratio |
10% |
系统开始后台回写脏页的内存占比阈值。 |
dirty_ratio |
20% |
进程在写入时,因脏页超过此比例而被强制同步回写的阈值。 |
dirty_expire_interval |
3000ms |
脏页在内存中最长可驻留的时间。 |
dirty_writeback_interval |
500ms |
回写线程(pdflush等)被唤醒的时间间隔。 |
vm.dirty_bytes |
- |
以字节数表示的脏页限制(与dirty_ratio互斥)。 |
vm.dirty_background_bytes |
- |
以字节数表示的后台回写触发限制。 |
5.3.2 回写状态机
6. 调试与性能分析工具
掌握块I/O层的系统调优,离不开一系列强大的观测和调试工具。
6.1 常用工具命令
6.1.1 基础监控命令
# 1. iostat - 查看块设备I/O统计
iostat -x 1 # 每秒显示一次扩展统计信息
# 关键字段解读:
# %util - 设备利用率(百分比),100%表示设备满负荷
# await - 平均I/O等待时间(毫秒)
# svctm - 平均I/O服务时间(毫秒)
# r/s, w/s - 每秒读/写请求次数
# rkB/s, wkB/s - 每秒读/写的数据量(KB)
# 2. iotop - 类似top的I/O监控工具
iotop -o # 只显示当前正在进行I/O操作的进程
# 3. blktrace - 块层跟踪工具(需要blkparse解析)
blktrace -d /dev/sda -o trace # 跟踪/dev/sda设备
blkparse -i trace -o output # 解析跟踪结果
# 4. /proc/diskstats - 磁盘统计原始数据
cat /proc/diskstats
# 字段说明(部分):
# 读完成次数 合并读次数 读扇区数 读花费时间(毫秒)
# 写完成次数 合并写次数 写扇区数 写花费时间
# 当前正在处理的I/O数 I/O花费的总时间 加权I/O花费时间
6.1.2 高级分析工具
# 1. btt - blktrace时间分析工具
btt -i trace.bin -o analysis
# 2. fio - 灵活且功能强大的I/O基准测试工具
fio --name=test --ioengine=libaio --rw=randread \
--bs=4k --numjobs=16 --size=1G --runtime=60 \
--group_reporting
# 3. perf - Linux性能分析神器
perf record -e block:block_rq_issue -ag
perf script # 查看记录的结果
# 4. bpftrace - 基于eBPF的动态追踪工具
bpftrace -e 'tracepoint:block:block_rq_issue {
printf("%s %d\n", comm, args->bytes);
}'
6.2 内核调试技巧
6.2.1 动态调试
// 在代码中添加条件调试信息
#define DEBUG
#ifdef DEBUG
#define dbg_print(fmt, args...) \
printk(KERN_DEBUG "%s:%d: " fmt, __FILE__, __LINE__, ##args)
#else
#define dbg_print(fmt, args...)
#endif
// 使用内核动态调试功能(dyndbg)
echo "file drivers/block/*.c +p" > /sys/kernel/debug/dynamic_debug/control
6.2.2 Ftrace跟踪
# 启用块层相关的事件跟踪
echo 1 > /sys/kernel/debug/tracing/events/block/enable
# 实时查看跟踪结果
cat /sys/kernel/debug/tracing/trace_pipe
# 跟踪特定事件,如请求发出和完成
echo block:block_rq_issue > /sys/kernel/debug/tracing/set_event
echo block:block_rq_complete >> /sys/kernel/debug/tracing/set_event
6.3 性能问题诊断矩阵
| 症状 |
可能原因 |
诊断命令 |
解决方案 |
| 高await时间 |
磁盘过载,I/O队列过长;调度器策略不当。 |
iostat -x |
优化应用减少I/O;更换为deadline或noop调度器;调整队列深度。 |
| 低吞吐量 |
请求大小(bs)太小,合并不充分;设备本身带宽低。 |
blktrace, iostat |
调整应用I/O大小;调大max_sectors_kb;检查硬件。 |
| CPU使用率高 |
I/O中断过于频繁;复杂调度器(如CFQ/BFQ)开销大。 |
perf top, mpstat -P ALL 1 |
尝试noop调度器;启用中断合并(/proc/irq/*/smp_affinity)。 |
| 延迟不稳定 |
写操作阻塞了读操作;存在请求饥饿现象。 |
iosnoop(bcc工具) |
使用deadline调度器并调整writes_starved;设置read_expire。 |
| 设备利用率100% |
工作负载已超出设备物理极限。 |
iostat -x |
考虑升级更高性能硬件(如SSD);在应用层做负载均衡。 |
7. 实际案例:数据库I/O优化
7.1 PostgreSQL块I/O优化
# 1. 选择合适的I/O调度器(针对SATA/SAS硬盘,推荐deadline)
echo deadline > /sys/block/sda/queue/scheduler
# 2. 调整预读大小(根据数据库工作负载和存储设置,通常可以调大)
blockdev --setra 8192 /dev/sda # 设置预读为8192个扇区(即4MB)
# 3. 调整队列深度,允许更多请求排队以利于合并和调度
echo 256 > /sys/block/sda/queue/nr_requests
# 4. 对于某些旧硬盘,禁用NCQ可能更稳定(现代硬盘通常不需要)
echo 1 > /sys/block/sda/device/queue_depth
# 5. 文件系统挂载选项优化
# 在/etc/fstab中添加如下的挂载选项(以ext4为例):
# /dev/sda1 /var/lib/pgsql ext4 noatime,nodiratime,data=writeback 0 2
# - noatime,nodiratime: 减少元数据写入。
# - data=writeback: 提高写入性能(牺牲一点安全性,需确保有电池备份缓存BBWC/超级电容)。
7.2 MySQL InnoDB优化
# my.cnf配置文件中的关键I/O优化项
[mysqld]
# I/O相关优化
innodb_flush_method = O_DIRECT # 绕过OS页缓存,避免双重缓存
innodb_read_io_threads = 8 # 后台读I/O线程数
innodb_write_io_threads = 8 # 后台写I/O线程数
innodb_io_capacity = 2000 # InnoDB认为的磁盘I/O能力(IOPS),根据SSD/HDD调整
innodb_io_capacity_max = 4000 # 在压力下允许达到的最大I/O能力
# 日志文件相关(影响刷写频率)
innodb_log_file_size = 4G # 更大的日志文件减少检查点和日志刷写频率
innodb_log_buffer_size = 256M # 大的日志缓冲区
sync_binlog = 1 # 每次事务提交都刷写binlog,保证安全
8. 总结与最佳实践
8.1 核心要点总结
通过对Linux块I/O层的深入剖析,我们可以总结出其核心设计要点:
- 分层抽象架构:块I/O层作为文件系统和具体设备驱动之间的桥梁,提供了统一的抽象接口,屏蔽了硬件差异。
- 核心数据结构流:
bio -> request -> request_queue构成了I/O请求从提交到执行的核心数据流。
- 智能调度优化:多种I/O调度器(如CFQ、Deadline、BFQ、Noop)适应不同的应用场景,通过合并、排序等手段显著提升性能,尤其是对机械硬盘。
- 异步处理机制:完善的预读(Read-ahead)和延迟回写(Writeback)机制,巧妙地平衡了I/O延迟和系统吞吐量。
- 面向现代的扩展性:
blk-mq多队列架构的引入,充分适配了NVMe等现代高速存储设备的并行特性。
8.2 最佳实践表格
| 场景 |
推荐调度器 |
关键参数调整思路 |
核心监控指标 |
| 桌面系统 |
BFQ |
启用low_latency模式,优先保证交互响应。 |
应用启动时间,UI操作流畅度。 |
| 数据库服务器 |
Deadline |
增大nr_requests,调整read_expire/write_expire。 |
await(平均等待时间),%util(利用率)。 |
| Web服务器 |
CFQ或Noop |
对于静态文件服务,可设置slice_idle=0让CFQ更积极。 |
IOPS,吞吐量(rkB/s/wkB/s)。 |
| NVMe SSD |
None或Kyber |
设置合适的queue_depth(如32),启用多队列。 |
延迟分布(使用fio或latencytop)。 |
| 虚拟化环境 |
MQ-Deadline |
可能需启用nomerges=2(禁用合并)以避免访客间相互影响。 |
各虚拟机(VM)的I/O延迟公平性。 |
8.3 故障排查检查表
当遇到I/O性能问题时,可以按照以下清单进行系统性排查:
- 基础检查
iostat -x 1:查看设备利用率、等待时间、吞吐量是否异常。iotop:定位是哪个进程在大量进行I/O操作。cat /sys/block/*/queue/scheduler:确认当前使用的I/O调度器。
- 深入分析
blktrace + blkparse:跟踪I/O请求在块层的完整路径,分析延迟产生在哪个环节。perf record -e block:*:进行性能剖析,查看热点函数。- 检查
/proc/sys/vm/dirty_*系列参数:确认脏页回写策略是否合理。
- 优化调整
- 根据工作负载特征(随机/顺序,读/写比例)选择合适的I/O调度器。
- 调整
read_ahead_kb(预读)和nr_requests(队列深度)。
- 评估并优化文件系统挂载选项(如
noatime, data=writeback等)。
- 对于数据库等特定应用,参考其最佳实践进行配置。
8.4 最终思考
Linux块I/O层是操作系统中最为复杂和精密的子系统之一。它远不止是一个简单的数据“搬运工”,而是:
- 智能的交通管制系统:在看似无序的I/O请求洪流中建立秩序与效率。
- 高效的资源协调者:在速度、公平性和数据可靠性之间取得精妙平衡。
- 硬件的翻译官:将通用的“读/写”操作指令翻译成千差万别的硬件设备能理解的语言。
- 系统性能的调音师:通过一系列可调参数,使同一套系统能适配从嵌入式设备到超算中心的不同工作负载。
深入理解块I/O层,不仅能够帮助我们在日常运维中进行有效的性能分析和故障排查,更是窥探现代操作系统设计哲学与工程智慧的一扇绝佳窗口。随着存储技术(如SCM持久内存、ZNS SSD)的持续演进,块I/O层也必将不断革新,但其核心使命永恒不变:在应用程序与物理存储介质之间,构建一条高效、可靠的数据高速公路。
 发表于 2025-12-6 00:09:48
|
查看: 114|
回复: 0
发表于 2025-12-6 00:09:48
|
查看: 114|
回复: 0
