

昨天我们聊了如何复刻OpenClaw的记忆系统,旨在为所有Agent构建透明、可控的记忆层,并发布了核心工具 memsearch。
但具体到代码编程领域,如何有效地实现记忆与检索,其需求和挑战又与其他场景有所不同。因此,在 memsearch CLI 的基础上,我们专门为 Claude Code 开发了一个永久记忆插件——memsearch ccplugin。这个设计思路理论上也适用于其他支持插件的AI编程工具。
借助 memsearch ccplugin 提供的轻量级记忆方案,Claude 能够记住你的每一次对话、每一个技术决策、每一条代码风格偏好,实现跨会话、跨天的知识积累与自动检索,让历史经验随时可用。
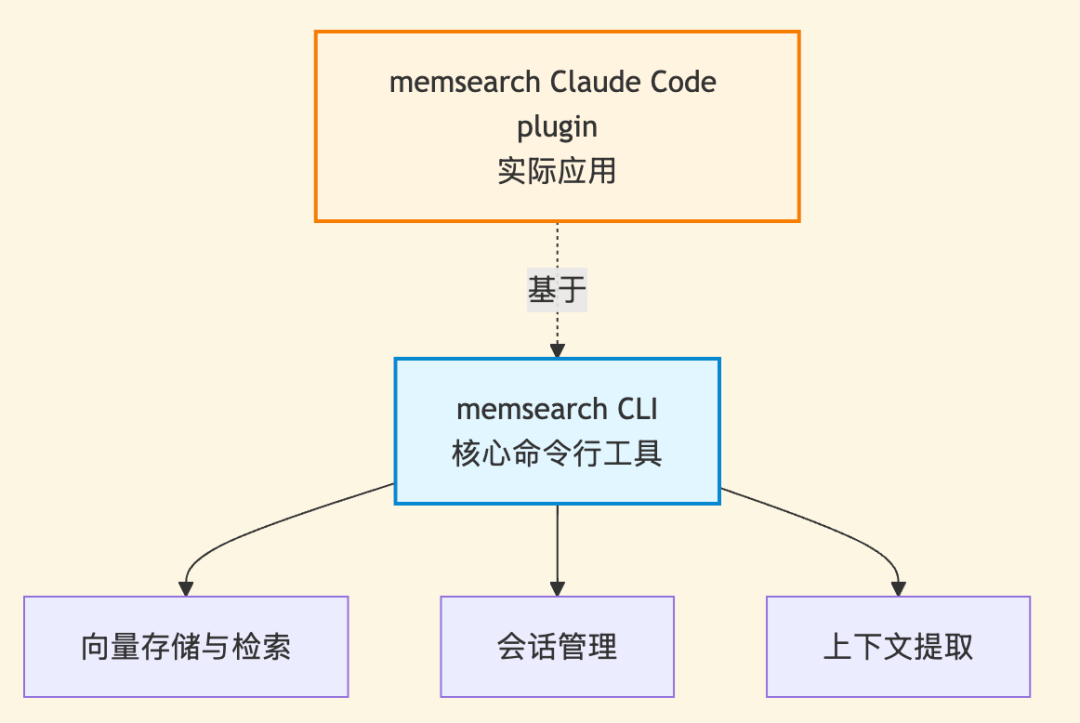
为了表述清晰,在本文中,我们将上层的 memsearch Claude Code plugin 简称为 ccplugin,而底层核心仍称为 memsearch。
我们为什么需要 memsearch ccplugin?
设想这样一个场景:早上打开 Claude Code,你想让AI继续昨天的代码重构工作。但 Claude 似乎“失忆”了,完全不记得昨天的进展。于是,你不得不翻找历史记录,开始复制粘贴上下文。这种问题虽小,但频繁发生会极大影响开发效率。
Claude Code 自身虽然具备一些记忆机制,但在实际生产级应用中往往捉襟见肘。例如,它的 CLAUDE.md 文件适合存储静态的项目规则和简短的提示,却难以承载长期、动态积累的知识。虽然也有 /resume、/fork 等命令来恢复会话,但体验并不友好:用户需要记住复杂的 session ID,手动管理一堆分叉的对话历史。
更常见的情况是,当你输入 /resume 命令后,面对一长串只有简单标题的会话列表,如果只模糊记得某些操作细节且时间久远,根本无从分辨哪个才是目标会话。
为此,市场上出现了像 claude-mem 这样的全栈式解决方案。它的核心理念是构建一套完整的记忆系统:自动捕获编码活动,用AI压缩成可搜索的摘要,并在需要时注入相关上下文。
为了实现这一目标,claude-mem 设计了一个三层记忆系统:先搜索高层摘要,需要细节时可以查看时间线,想看原始对话则能调取完整的交互记录。此外,它还提供了隐私标签、成本统计和Web可视化界面等功能。
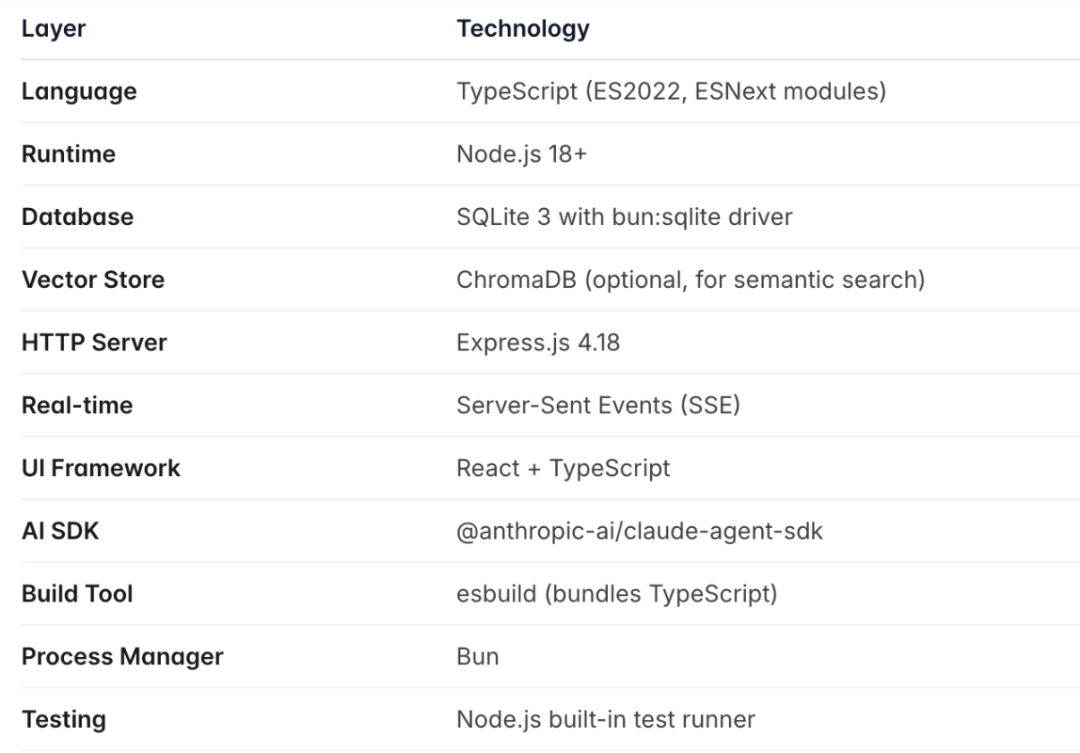
其技术栈实现如下:
平心而论,claude-mem 是一个出色的开源项目,它切实解决了Claude Code的记忆痛点。但其架构也带来了相当的复杂性,主要体现在:
- 环境与组件依赖繁重:用户需要部署Node.js、Bun、MCP runtime等基础环境,并维护包含Worker服务、Express server、React UI、SQLite、向量数据库在内的多个组件,部署和维护门槛较高。
- Context窗口与成本开销大:其基于MCP server的设计存在一个关键问题——所有工具定义会永久占用Claude的上下文窗口,且每次工具调用的请求和响应都会消耗额外tokens。在长时间会话中,这些累积开销可能导致token成本失控。
- 记忆召回的被动性:claude-mem采用“Agent驱动”模式,必须由Claude主动调用
search等工具才能触发检索。如果Claude没有“意识”到需要调取某段记忆,相关内容就不会出现。
- 数据存储不透明:记忆数据分散存储在SQLite(元数据)和Chroma(向量数据)等二进制数据库中,缺乏通用、开放的格式。用户想要迁移或直接查看记忆内容,只能通过专用接口或编写导出脚本。
正是基于对上述现状的思考,我们开始探索:AI记忆系统能否设计得更简单、更轻量?
memsearch ccplugin 的构建哲学与架构
与claude-mem追求功能完备的全栈架构不同,memsearch ccplugin 选择了另一条路径:极简主义。我们的目标是,以最轻量化的方式解决Claude Code的记忆问题,摒弃一切不必要的复杂性。
memsearch ccplugin 的架构核心,仅仅是 四个Shell Hook脚本 加上 一个后台文件监控(watch)进程。它完全避免了Node.js服务、MCP server、Web UI等重型组件,本质上就是几个调用底层 memsearch CLI 的Shell脚本,极大地降低了部署和维护成本。
从职责划分上看,ccplugin 本身不负责记忆存储、向量检索或文本嵌入。这些核心能力全部交由底层的 memsearch CLI 来实现。ccplugin 的唯一使命,就是充当一座高效的桥梁,将Claude Code全生命周期中的关键事件(如会话启动、用户输入、停止回复、会话结束),精准地桥接到 memsearch CLI 的对应功能上。
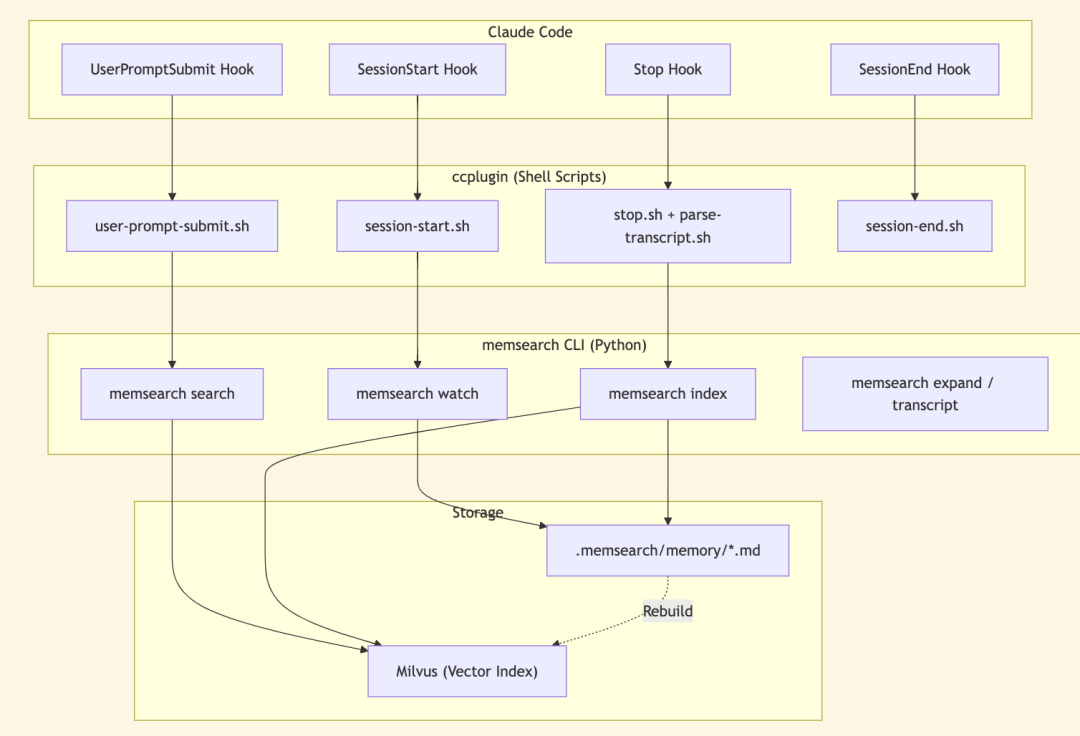
这种分层解耦的设计带来了极大的灵活性。即使你不使用Claude Code,memsearch CLI 也可以独立集成到其他IDE或Agent框架中,甚至通过命令行手动调用,完全不受单一场景的限制。
具体来说,这套架构有两大突出特色:
特色一:Markdown优先,向量索引为可重建缓存
ccplugin 将所有记忆以纯文本形式,存储在 .memsearch/memory/ 目录下的Markdown文件中。
.memsearch/memory/
├── 2026-02-09.md
├── 2026-02-10.md
└── 2026-02-11.md
每个文件代表一天的会话摘要,格式人类可读、可直接编辑。以下是 memsearch 项目自身的记忆文件示例:

你可以清晰看到时间、会话ID、每轮对话的ID以及由AI生成的会话摘要。这意味着,你想知道AI记住了什么,直接打开Markdown文件即可。想修改或删除某段记忆?用任何文本编辑器编辑就行。需要迁移数据?直接复制整个 .memsearch/memory/ 文件夹。
在此设计中,Milvus向量索引仅作为加速语义检索的派生缓存。所有索引都可以随时从Markdown源文件完整重建。这确保了整个系统没有不透明的二进制数据库,数据完全可追溯、可控制。

特色二:自动注入与零上下文消耗
透明的存储是基础,高效的使用才是关键。ccplugin 的记忆召回是完全自动的。
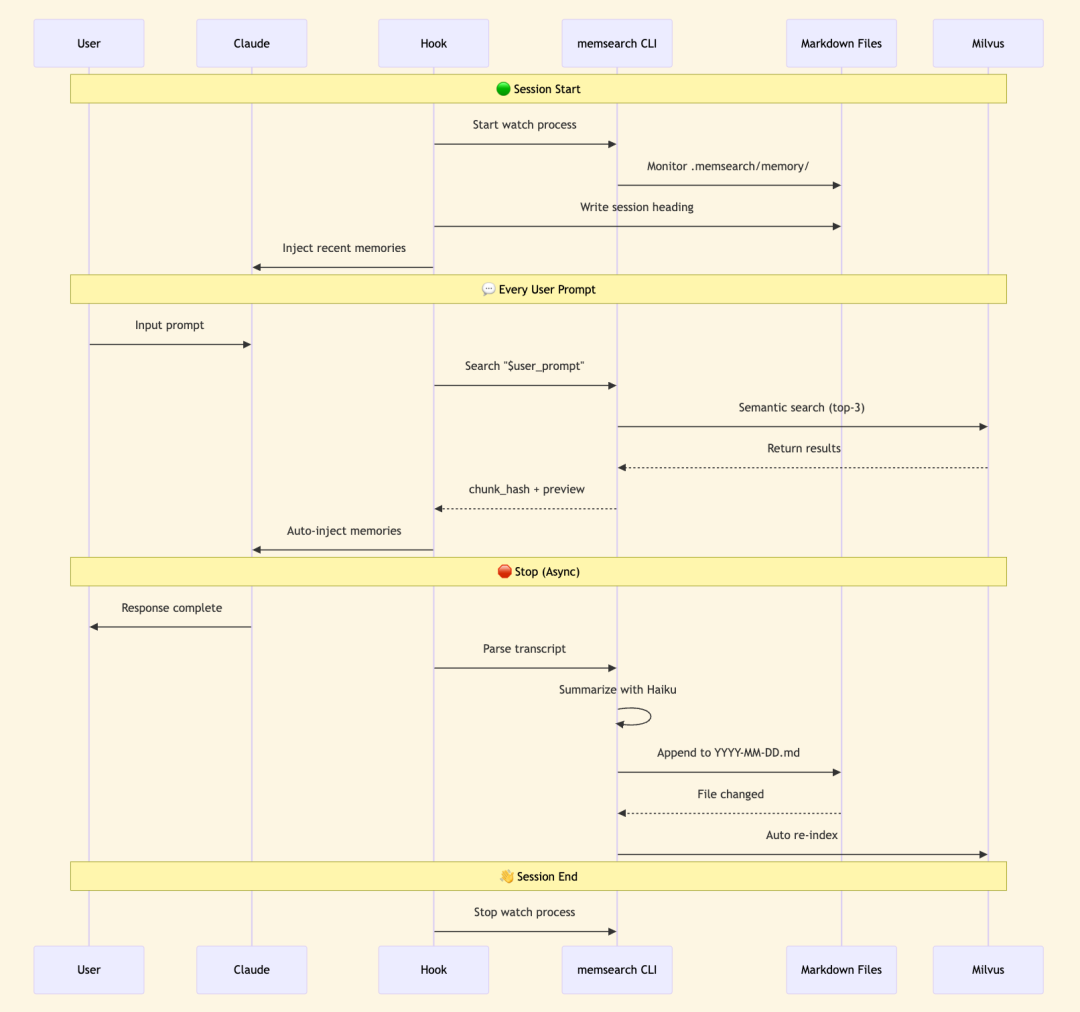
每次你在Claude Code中输入提示(prompt),UserPromptSubmit Hook会自动触发语义搜索,并将最相关的3条记忆(top-3)直接注入到对话上下文中。Claude无需主动决定“是否要搜索”,它直接就获得了相关的历史上下文。
在这个过程中,Claude看不到任何MCP工具定义,因此不会占用宝贵的上下文窗口(Context Window)。Hook机制在操作系统CLI层面运行,注入的只是纯文本搜索结果,没有进程间通信(IPC)的开销,也彻底避免了工具调用所产生的额外token成本,从根源上杜绝了上下文开销累积的问题。
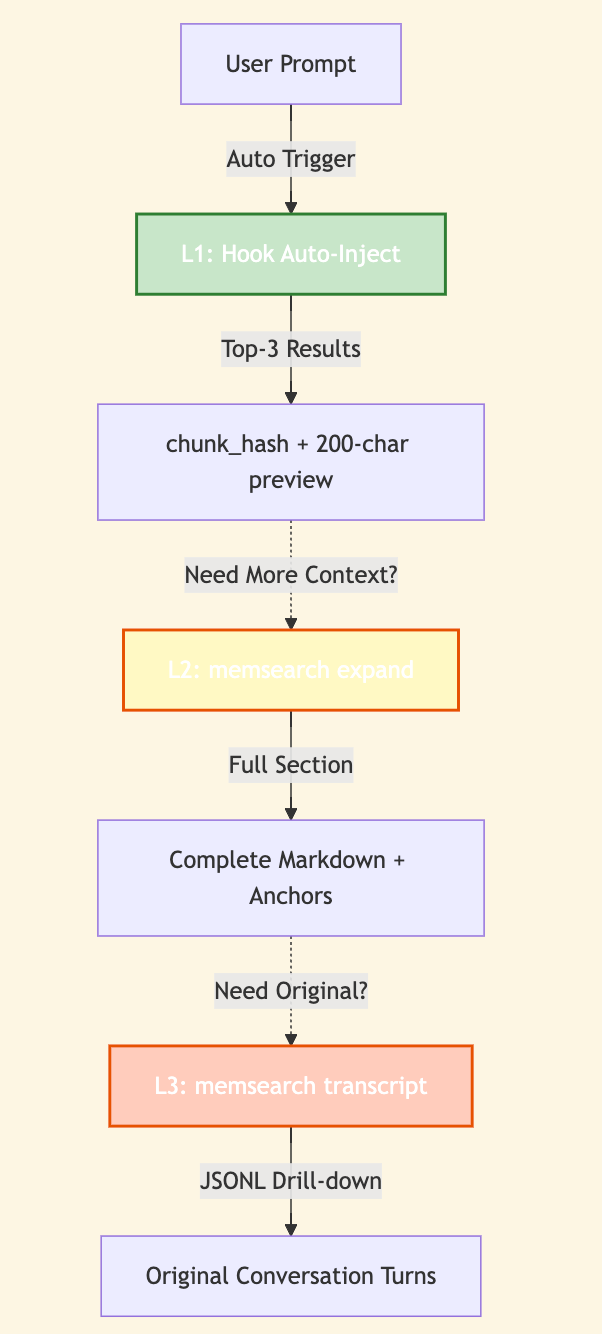
此外,为了兼顾默认效率与特殊场景的灵活性,我们设计了一套三层渐进式检索逻辑:
- L1 (自动层):每次输入时自动注入top-3语义搜索结果(包含
chunk_hash和约200字的预览),满足日常多数需求。
- L2 (按需层):当需要更完整的上下文时,可以手动运行
memsearch expand 命令,获取完整的Markdown章节及其元数据。
- L3 (深入层):如需追溯到原始对话记录,可运行
memsearch transcript --turn 命令,调取JSONL格式的原始交互记录。
这套逻辑确保了默认使用时的极度轻量化,同时保留了按需深入挖掘细节的能力。
解决了“怎么用”的问题,我们再来看看“存什么”以及“怎么存”。
ccplugin 的Markdown记忆内容是通过一套后台异步、低成本的流程自动生成的:每当你停止Claude的回复时,Stop Hook会异步触发,解析本次对话记录(transcript),并调用成本极低的Claude Haiku模型生成一段简洁的会话摘要,然后将其追加到当天的Markdown文件中。
与此同时,一个后台的watch进程会监控Markdown文件的变化。一旦检测到有新内容追加,它会自动将新增部分索引到Milvus向量库中,从而确保记忆的实时可检索性。整个流程在后台静默运行,对用户无干扰,且API调用成本极低。
快速上手指南
只需要简单几步,你就可以为你的Claude Code装上“永久记忆”:
第一步:安装插件
在Claude Code的终端中运行以下命令,从插件市场安装。
# 在Claude Code终端运行
/plugin marketplace add zilliztech/memsearch
/plugin install memsearch
第二步:重启Claude Code
安装完成后,重启Claude Code。插件会自动完成初始化配置。
第三步:验证记忆生成
完成一次完整的编码对话后,你可以通过以下命令查看当天生成的记忆摘要。
cat .memsearch/memory/$(date +%Y-%m-%d).md
第四步:体验自动记忆检索
下次启动Claude Code开始新会话时,系统会自动在后台检索并注入相关记忆,你无需任何额外操作即可享受上下文连贯的编程体验。
总结与对比
回到最初的问题:如何为AI编程助手添加记忆?claude-mem 和 memsearch ccplugin 代表了两种不同的设计思路,各有优劣。

- claude-mem 提供了更丰富的功能(如Web可视化、精细化管理)、更完善的用户界面以及更灵活的控制逻辑。如果你需要团队协作、对记忆内容进行复杂的标签管理或可视化审计,它是一个强大的选择。
- memsearch ccplugin 则追求极简设计,实现了零上下文消耗、完全透明的数据存储和极低的维护门槛。如果你只想为Claude Code增加一个轻量、可靠、不添乱的记忆层,而不想引入额外的复杂度,那么它可能更适合你。
没有绝对的好坏,只有是否适合你的需求。 我们的目标是提供一种更简单、更可控的选项,让AI编程助手的记忆回归“工具”的本质。
项目资源
 发表于 2026-2-14 04:22:07
|
查看: 548|
回复: 0
发表于 2026-2-14 04:22:07
|
查看: 548|
回复: 0
