开篇先对本文的核心内容进行总结:
- 直接映像:每个主存块只能放到 Cache 的“唯一固定一行”,地址 = 标记 + 行号 + 块内地址;实现简单但冲突多,命中率相对低。
- 全相联映像:任意主存块可放到 Cache 的“任意一行”,地址 = 标记 + 块内地址;最灵活、潜在命中率最高,但比较逻辑复杂、成本高,只适合小容量 Cache。
- 组相联映像:先把 Cache 分成若干组,主存块先按“组号”直接映射到一个组,在该组内用全相联方式选择一行,地址 = 标记 + 组号 + 块内地址;是前两者的折中方案,性能和复杂度比较均衡。
一、三种映像方式的总体关系
这三种映像方式本质是“主存块如何放入Cache行”的规则,从“最死板”到“最灵活”排序,核心是在访问速度、命中率和硬件成本之间取得平衡:
- 最死板:直接映像 —— 一对一,每个块只能去一个固定位置。简言之每个主存块只能放到Cache的“唯一固定一行”;实现简单但冲突多,命中率相对低。
- 最灵活:全相联映像 —— 多对多,任意块可以去任意位置。简言之任意主存块可放到Cache的“任意一行”;最灵活、潜在命中率最高,但比较逻辑复杂、成本高。
- 中间:组相联映像 —— 组间直接映像 + 组内全相联,每个块固定去某一组,组内任意挑一行。是前两者的折中方案,性能和复杂度最为均衡,也是现代CPU缓存最常用的方案。
如果你觉得抽象,可以想想生活中的“找座位”:
- 直接映像:电影院“固定座位号”——每张票(主存块)对应唯一座位(Cache行),不能换,找座快但有人占座就只能等(冲突)。
- 全相联映像:电影院“任意空位”——每张票可坐任意空座位,灵活性最高,不用等但找空位要扫遍全场(比较复杂)。
- 组相联映像:电影院“分区域选座”——先按票上的区域(组号)找到对应区域,再在区域内选任意空位,兼顾找座速度和灵活性。
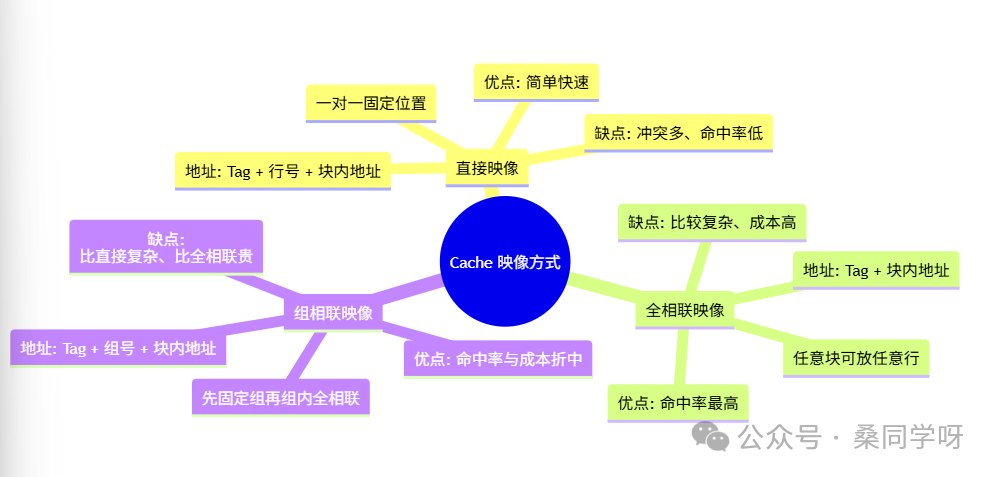
二、直接映像(Direct Mapped)
这种方式最简单但也最死板,它规定每个主存块在Cache中只有一个“专属座位”。
1. 工作原理
- 将 Cache 分成若干“行(Line)”,每行存放一个“主存块”。
- 映像规则:主存中的每一块,只能放到 Cache 中“唯一那一行”中,映射关系固定:
Cache 行号 = 主存块号 mod Cache 行数(即只取块号低若干位)。
- 查找过程:用地址中的“行号”找到对应 Cache 行;比较该行中的“标记(Tag)”与地址中的标记是否匹配。若匹配且有效位为1,即为命中,否则缺失。
直接映像 Cache 每次访问最多只要“比较一次”,因此速度很快。
2. 地址结构
主存地址被分成三段:
- 标记(Tag):高位,用来区分映射到同一Cache行的不同主存块。
- 行号(Index):中间位,用来直接选择Cache的某一行,位数 = log₂(Cache行数)。
- 块内地址(Block Offset):低位,用来在块内选择具体的字节,位数 = log₂(块大小)。
字段位数计算公式(假设地址总位数 m,Cache行数 C,块大小 B):
offset(块内地址) = log₂ B 位index(行号) = log₂ C 位tag(标记) = m − index − offset 位
3. 优缺点
- 优点:硬件实现最简单(只需1个比较器);不需要复杂替换算法;访问速度快。
- 缺点:冲突严重——多个主存块若行号相同,会争抢同一Cache行,即使其他行空闲;命中率最低,易出现“颠簸(thrashing)”。
4. 简单例子
假设:Cache 大小 64 B;块大小 8 B;主存地址 32 位。
- Cache 行数:64 / 8 = 8 行 →
index 需要 3 位。
- 块内地址:log₂ 8 = 3 位。
- 标记:32 − 3 − 3 = 26 位。
访问主存地址 0x0000_0020:
- 取低6位(index 3位 + offset 3位):
...0010 0000
offset(低3位):000index(接下来3位):001(对应Cache行号1)- 该主存块只能放到Cache第1行,命中条件是第1行的Tag与地址中的Tag一致。
冲突示例:频繁交替访问“块号8”和“块号16”:
- 块号8 mod 8 = 0(对应Cache行0)
- 块号16 mod 8 = 0(也对应Cache行0)
两者会争抢Cache第0行,导致频繁替换,命中率骤降,这就是直接映像的核心缺点。
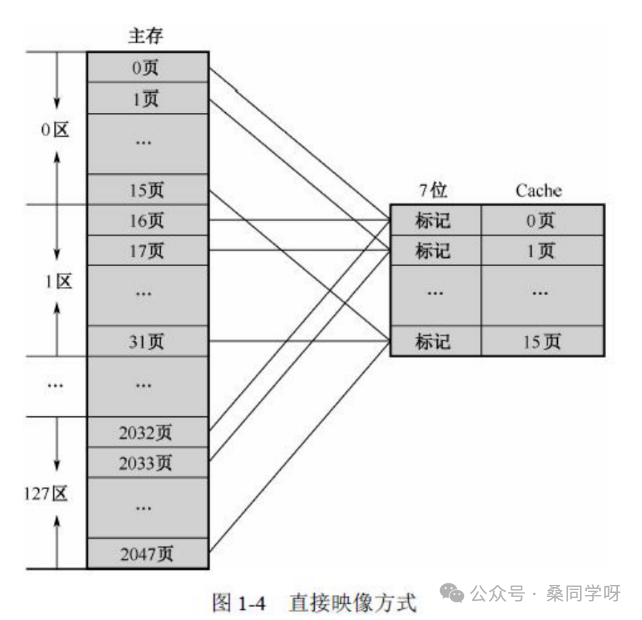
三、全相联映像(Fully Associative)
这是最自由的映射方式,打破了固定座位的限制。
1. 工作原理
- 映像规则:主存中任意一块,都可以放到 Cache 中的任意一行。
- 查找过程:不需要行号,直接将主存地址中的“标记(Tag)”,与Cache中“所有行的标记”同时比较。若有任意一行的Tag匹配且有效位为1,即为命中;否则缺失。装入新块时,若Cache满则需使用替换算法(如LRU)。
- 关键:比较次数 = Cache总行数,硬件复杂度高。
2. 地址结构
在全相联中,不需要“index”字段,因为任意位置都能放。地址只分两段:
- 标记(Tag):高位,需要包含完整的主存块标识信息,位数 = 主存地址总位数 − 块内地址位数。
- 块内地址(Block Offset):低位,用于块内寻址。
示例:块大小 16 B → offset = log₂ 16 = 4 位;地址32位 → tag = 32 − 4 = 28 位。地址结构为:[Tag(28) | Offset(4)]。
3. 优缺点
- 优点:灵活性最高,空间利用率最好,无冲突缺失。
- 缺点:比较逻辑复杂(需要大量并行比较器);硬件成本高、功耗大;仅适合小容量Cache(如TLB快表)。
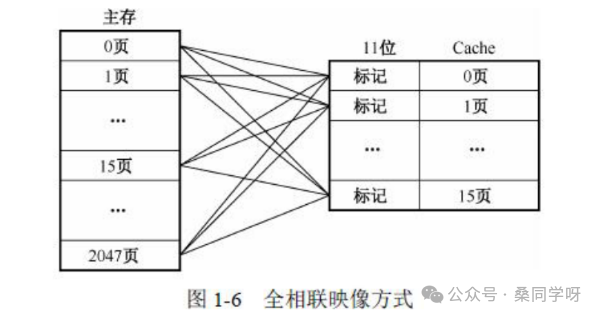
四、组相联映像(Set-Associative)
这是直接映像和全相联的“混血儿”,也是目前最主流的方案,旨在取两者之长。
1. 工作原理(直接 + 全相联的折中)
- 先把 Cache 分成若干组(Set),每组有若干行(称为 E 路组相联)。
- 映像规则:
- 组间映射:主存块按“组号”直接映射到某一个组,
组号 = 主存块号 mod Cache组数。
- 组内映射:在对应组内,采用全相联映像,主存块可放到该组的任意一行。
- 查找时:用地址中的“组号”找到对应的Cache组;在该组内,比较每一行的Tag(比较次数=组内路数E)。
极端情况:
E = 1(每组1行) → 等价于直接映射。- 组数为 1(只有一组) → 等价于全相联。
2. 地址结构
主存地址分为三段:
- 标记(Tag):高位,区分同一组中不同的主存块。
- 组号(Set Index):中间位,选择Cache的某一组,位数 = log₂(Cache组数)。Cache组数 S = Cache总行数 C / 组内路数 E。
- 块内地址(Block Offset):低位。
字段位数计算公式:
offset = log₂B 位index(组号) = log₂S = log₂(C/E) 位tag = 总位数 − index − offset 位
3. 优缺点
- 优点:比直接映像更灵活,冲突减少,命中率更高;比全相联简单(比较器数量=E,而非总行数C);性能与成本均衡。
- 缺点:比直接映像复杂一些(多路比较增加少量延迟和成本)。
4. 例子
假设:主存地址32位;Cache大小8KB;块大小64B;2路组相联。
- 计算参数:
offset = log₂64 = 6位- Cache总行数 C = 8KB / 64B = 128行
- 组数 S = 128行 / 2路 = 64组 →
index = log₂64 = 6位
tag = 32 − 6 − 6 = 20位- 地址结构:
[Tag(20) | Index(6) | Offset(6)]
- 访问过程:访问地址A时,用Index找到对应组(如第10组),在该组的2行中比较Tag。命中则读取,缺失则装入(组内有空行则直接放,满则按LRU等算法替换一行)。
五、三种方式对比总结
| 映像方式 |
映像规则简述 |
地址字段结构 |
比较次数 |
空间利用率/命中率 |
实现复杂度 |
典型适用场景 |
| 直接映像 |
每块只能到一个固定行 |
Tag + 行号 + 块内地址 |
1 次 |
利用率较低、冲突多 |
最简单 |
大容量、对性能要求稍低的Cache |
| 全相联映像 |
任意块可放任意行 |
Tag + 块内地址 |
C 次(或全部并行) |
利用率最高、潜在命中率高 |
最复杂 |
小容量、对命中率要求极高的部件(如TLB) |
| 组相联映像 |
组间直接,组内全相联 |
Tag + 组号 + 块内地址 |
E 次(组内路数) |
较高,介于两者之间 |
中等 |
通用 CPU 的 L1/L2 Cache |
六、实战计算:一个例子串讲三种方式
假设条件:主存地址 32 位;Cache 数据容量 8 KB;块大小 64 B。
- 公共参数:Cache 总行数 = 8 KB / 64 B = 128 行;块内地址
offset = log₂ 64 = 6 位。
-
直接映像:
index = log₂ 128 = 7 位tag = 32 − 7 − 6 = 19 位- 地址结构:
[Tag(19) | Index(7) | Offset(6)]
- 访问:用 Index 找行,比较该行 Tag。
-
全相联映像:
- 无 index
tag = 32 − 6 = 26 位- 地址结构:
[Tag(26) | Offset(6)]
- 访问:将 Tag 与所有 128 行的 Tag 比较。
-
2 路组相联映像:
- 组数 S = 128行 / 2路 = 64 组 →
index = log₂ 64 = 6 位
tag = 32 − 6 − 6 = 20 位- 地址结构:
[Tag(20) | Index(6) | Offset(6)]
- 访问:用 Index 找组,在组内的 2 行中比较 Tag。
核心对比:组相联在“组间”保留了直接映像的简单性(快速定位到组),但在“组内”提供了灵活性,有效减少了冲突,同时避免了全相联的巨大硬件开销。
七、实际应用与做题要点
实际CPU中的典型选择
现代处理器在设计缓存层级时,充分权衡了速度、命中率和成本:
- L1 数据/指令 Cache:通常采用 4 路或 8 路组相联,追求高速度和不错的命中率。
- L2/L3 Cache:容量更大,可能采用更高路数(如16路、24路)的组相联,或更复杂的索引技术来进一步减少冲突。
- TLB(页表缓存):容量小但对命中率要求极高,常采用高度相联(如全相联)的方式。
核心做题技巧与公式
理解下面的计算逻辑是解决相关题目的关键,它建立在扎实的计算机基础之上,特别是二进制和位操作:
地址字段划分通用步骤:
- 先算块内地址 Offset:
Offset 位数 = log₂(块大小 B)
- 再算索引 Index:
- 直接映射:
Index 位数 = log₂(Cache总行数 C)
- 组相联映射:
Index (组号) 位数 = log₂(组数 S) = log₂(C / E),其中 E 为路数。
- 全相联映射:无 Index。
- 最后算标记 Tag:
Tag 位数 = 地址总位数 − Index位数 − Offset位数。
易混淆点澄清:
- “直接映射”的冲突是结构性的,与程序访问模式关系很大。
- “全相联”的 Tag 最长,因为它要唯一标识整个主存块。
- “组相联”的组数不等于 Cache 行数,而是
行数 / 路数。
- 计算 Cache 总容量时,除了数据位,别忘了加上 Tag 位、有效位、脏位(写回策略时)等控制位。
八、精选例题与解析
通过实战题目可以更好地巩固概念。以下是几道经典题型及其解析思路。
例题1(概念辨析):
Cache 一般包含三种基本地址映射方式:全相联映射、直接映射和组相联映射。关于这三种映射方式,下列说法中不正确的是( )。
A. 全相联映射是指主存中的任意一块都可以映射到 Cache 中任意一块的方式
B. 直接映射是指主存中的某块只能映射到满足特定关系(如模 Cache 行数)的 Cache 块中
C. 组相联映射在组间采用直接映射、组内采用全相联映射,兼具二者优点
D. 全相联映射的缺点是 Cache 空间利用率低
答案与解析:D。全相联映射的优点是空间利用率高、冲突少;其缺点是硬件实现复杂、成本高。因此D项描述错误。
例题2(直接映射行号计算):
某计算机主存地址为 32 位,按字节编址。Cache 大小为 16KB,块大小为 16B,采用直接映射方式。主存地址 0x0000A460 所在的块在 Cache 中的行号(十进制)是( )。
A. 582 B. 70 C. 138 D. 139
解析步骤:
- Cache 行数 = 16KB / 16B = 1024 行 →
index 占 10 位。
- 块大小 16B →
offset 占 4 位。
- 将地址 0x0000A460 转换为二进制,取低14位(10位index + 4位offset):
...10 0100 0110 0000。
- 其中
index 部分为 10 0100 0110(二进制),转换为十进制:
2^9 + 2^6 + 2^2 + 2^1 = 512 + 64 + 4 + 2 = 582。
答案:A. 582
例题3(组相联地址结构):
Cache 共有 64 块,每块 128 字,按字编址,采用 4 路组相联映射。主存共有 4096 页,每页大小与 Cache 块相同。主存地址中 Tag、Set Index、Block Offset 字段分别占( )。
A. 8, 4, 7 B. 8, 8, 7 C. 8, 16, 7 D. 16, 8, 7
解析步骤:
- 块大小 = 128 字 →
offset = log₂128 = 7 位。
- Cache 总块数 64,4 路组相联 → 组数 S = 64 / 4 = 16 组 →
set index = log₂16 = 4 位。
- 主存共 4096 页 = 2^12 页,每页大小等于一块 → 主存页号(即块号)部分占 12 位。
- 这12位中,
set index 占去4位,剩下的就是 tag:12 − 4 = 8 位。
答案:A. 8, 4, 7
掌握这三种映射方式的原理、地址划分方法和优缺点,是理解现代存储体系与进行性能优化的基石。希望这篇深度解析能帮助你建立起清晰的知识框架。
本文涉及的核心概念属于计算机体系结构的重要部分。如果你想深入探讨或在实际项目中应用这些原理,欢迎在云栈社区与更多技术爱好者交流。
 发表于 2026-2-14 04:43:17
|
查看: 388|
回复: 0
发表于 2026-2-14 04:43:17
|
查看: 388|
回复: 0
