Service 的负载均衡原理
Service 通过 Endpoints 与 iptables 或 IPVS 实现对后端 Pod 的负载均衡。简单来说,Service 作为一个稳定的访问入口,其背后的流量分发机制依赖于这两个核心组件。
工作流程:
当客户端发起请求时,流程通常是这样的:
- 客户端访问 Service 的虚拟 IP(ClusterIP)和端口。
- Service 对象通过
selector 动态维护一个后端 Pod 的 IP 列表,即 Endpoints。
- 节点上的 kube-proxy 组件监听到 Service 和 Endpoints 的变化,生成相应的 iptables 或 IPVS 规则。
- 请求流量进入节点内核网络栈,被这些规则拦截并进行负载均衡转发,最终抵达具体的 Pod。

查看 Endpoints:
# 查看 Service 关联到的后端 Pod IP 和端口
kubectl get endpoints nginx-service
# 示例输出
# nginx-service 10.244.1.2:80,10.244.1.3:80,10.244.2.1:80
iptables 规则示例:
这些规则是 kube-proxy 自动生成的,实现了随机负载均衡。
# 查看与 Service 相关的 NAT 表规则
iptables -t nat -L -n | grep KUBE-SVC
# 负载均衡规则示例(简化为便于理解)
-A KUBE-SVC-XXXXXXXX -m statistic --mode random --probability 0.333
-A KUBE-SVC-XXXXXXXX -m statistic --mode random --probability 0.5
-A KUBE-SVC-XXXXXXXX -m tcp -p tcp -j DNAT --to-destination <Pod IP>:80
Ingress 的作用和配置
Service 提供了四层(TCP/UDP)的访问能力,而 Ingress 则是为了管理集群外部访问 HTTP/HTTPS 服务而设计的 API 对象,它提供了七层(应用层)的路由功能,例如基于主机名和路径的转发。
示例配置:
下面是一个典型的 Ingress 资源配置,它定义了不同域名的请求如何路由到后端的 Service。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
spec:
ingressClassName: nginx
rules:
- host: app1.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: app1-service
port:
number: 80
- host: app2.example.com
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: app2-service
port:
number: 8080
tls:
- hosts:
- app1.example.com
secretName: app1-tls
常见 Ingress Controller:
Ingress 资源本身只是一份“路由规则说明书”,需要对应的 Ingress Controller 来具体执行。社区中流行的控制器包括:
- NGINX Ingress Controller
- Traefik
- HAProxy Ingress
- Istio Gateway (属于 Service Mesh 范畴)
Headless Service 的用途
普通的 Service 会分配一个 ClusterIP 作为虚拟 IP。而 Headless Service 比较特殊,它没有 ClusterIP。当你查询它的 DNS 记录时,返回的是其 selector 所选中的 Pod 的直接 IP 地址列表。
示例:
apiVersion: v1
kind: Service
metadata:
name: nginx-headless
spec:
clusterIP: None # 关键在此,声明为 Headless Service
selector:
app: nginx
ports:
- port: 80
典型用途:
- StatefulSet 配套:StatefulSet 管理的 Pod 需要稳定的网络标识,Headless Service 为其提供 DNS 解析支持。
- 点对点通信:某些中间件(如 ZooKeeper, Kafka)或需要直接知道所有 Pod IP 的分布式应用。
- 服务发现:客户端可以通过 DNS 查询获取所有 Pod IP,然后自行实现负载均衡逻辑。
DNS 解析区别:
# 查询普通 Service,返回的是 ClusterIP
nslookup nginx-service
# 查询 Headless Service,返回的是后端所有 Pod 的 IP 地址
nslookup nginx-headless
NetworkPolicy 的作用
默认情况下,Kubernetes 集群内的 Pod 之间网络是互通的。NetworkPolicy 提供了一种 Pod 级别的网络隔离策略,你可以定义哪些 Pod 可以相互通信,以及使用哪些端口和协议,这相当于在 Pod 周围设置了防火墙规则。
示例配置:
这个策略规定:只有带有 app: frontend 标签的 Pod 可以访问带有 app: api 标签的 Pod 的 8080 端口;并且 app: api 的 Pod 只能向带有 app: database 标签的 Pod 的 5432 端口发起出站连接。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
spec:
podSelector:
matchLabels:
app: api
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
app: frontend
ports:
- protocol: TCP
port: 8080
egress:
- to:
- podSelector:
matchLabels:
app: database
ports:
- protocol: TCP
port: 5432
前提条件:
NetworkPolicy 的功能需要底层网络插件(CNI)的支持,例如 Calico、Cilium 或 Weave Net 等。如果你使用的是不支持此功能的网络方案(如 Flannel 的某些模式),NetworkPolicy 资源将不会生效。
会话保持(Session Affinity)的实现
对于一些有状态的应用,我们希望来自同一客户端的请求能始终被转发到同一个后端 Pod,这就是会话保持。Kubernetes 的 Service 可以通过 sessionAffinity 字段来配置。
apiVersion: v1
kind: Service
metadata:
name: myapp-service
spec:
type: ClusterIP
sessionAffinity: ClientIP # 设置为基于客户端IP的会话保持
sessionAffinityConfig:
clientIP:
timeoutSeconds: 10800 # 会话保持的持续时间,默认为10800秒(3小时)
selector:
app: myapp
ports:
- port: 80
targetPort: 8080
原理说明:
- 该机制基于客户端的源 IP 地址。
- 来自同一 IP 的请求,在
timeoutSeconds 定义的期限内,会被 Service 的负载均衡器(iptables/IPVS)固定转发到同一个后端 Pod。
- 适用于需要保持会话状态的应用,但需要注意如果客户端通过 NAT 网关访问,其源 IP 可能不是唯一的。
Service 与 Pod 的 DNS 解析
Kubernetes 集群内置了 CoreDNS(旧版本可能是 kube-dns)来为 Service 和 Pod 提供 DNS 解析服务,这极大简化了服务间的相互发现。
DNS 规则:
- Service:
<service-name>.<namespace>.svc.cluster.local
- Pod(通常需要启用 hostname 和 subdomain 特性,或由 StatefulSet 管理):
<pod-hostname>.<service-name>.<namespace>.svc.cluster.local
示例:
# 在同一命名空间内,可以直接使用服务名
ping nginx-service
# 访问不同命名空间的 Service,需要带上命名空间
ping nginx-service.production
# 使用完整的 FQDN(完全限定域名)
ping nginx-service.production.svc.cluster.local
Pod DNS 配置示例:
你可以为 Pod 自定义 DNS 设置,例如指定额外的 DNS 服务器或搜索域。
apiVersion: v1
kind: Pod
spec:
dnsPolicy: ClusterFirst # 优先使用集群 DNS
dnsConfig:
nameservers:
- 8.8.8.8 # 额外的上游 DNS 服务器
searches:
- default.svc.cluster.local # 额外的 DNS 搜索域
options:
- name: ndots
value: “2”
存储管理篇
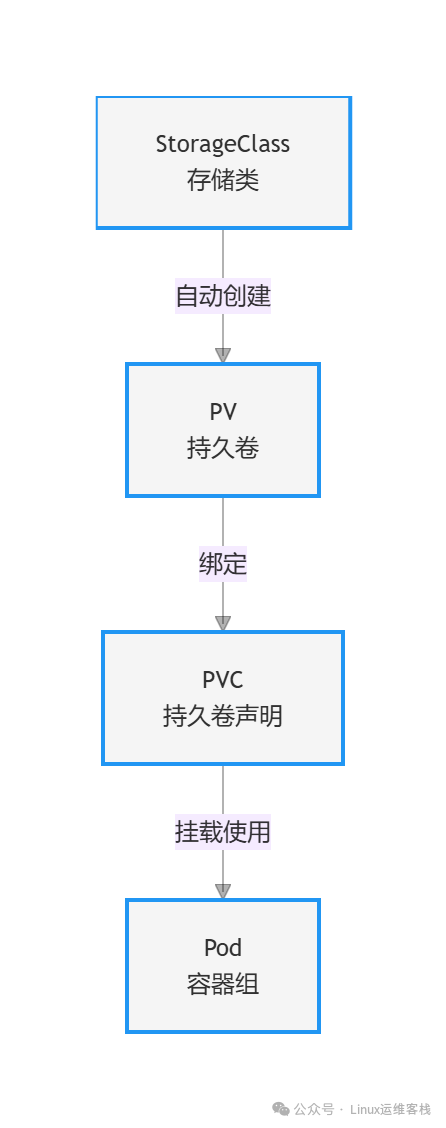
PV、PVC、StorageClass 的关系
在 Kubernetes 中,存储管理抽象出了几个核心概念,它们之间的关系是理解持久化存储的关键。
- PV (PersistentVolume):集群中的一块存储资源,由管理员预先创建或由 StorageClass 动态供应。它独立于 Pod 的生命周期。
- PVC (PersistentVolumeClaim):用户对存储资源的“声明”或“申请”。Pod 通过使用 PVC 来消费 PV 的存储空间。
- StorageClass:存储类的定义,描述了可以动态创建 PV 的“供应者(provisioner)”和参数(如磁盘类型、性能)。它实现了存储资源的动态按需分配。
完整示例:
# 1. 定义一个 StorageClass,指定动态创建 PV 的 provisioner 和参数
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs # 例如在 AWS 上使用 EBS
parameters:
type: gp2
---
# 2. 用户创建一个 PVC,声明需要的存储大小和类型
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: fast-ssd # 指向上面定义的 StorageClass
resources:
requests:
storage: 100Gi
---
# 3. Pod 通过 PVC 名称挂载存储
apiVersion: v1
kind: Pod
spec:
containers:
- name: mysql
volumeMounts:
- name: mysql-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-storage
persistentVolumeClaim:
claimName: mysql-pvc # 使用名为 mysql-pvc 的 PVC
Volume 的类型和使用
除了持久化的 PV/PVC,Kubernetes 还支持多种临时或特殊用途的 Volume 类型。
emptyDir(临时目录):
Pod 启动时创建的空目录,生命周期与 Pod 绑定。适用于 Pod 内容器间的临时数据共享或缓存。
volumes:
- name: cache
emptyDir:
sizeLimit: 1Gi # 可以限制其容量
hostPath(宿主机路径):
将 Pod 所在节点上的文件系统目录或文件挂载到 Pod 中。需谨慎使用,因为它将 Pod 与特定节点耦合,且安全性较低。
volumes:
- name: host-data
hostPath:
path: /data
type: DirectoryOrCreate
ConfigMap / Secret:
将 ConfigMap 或 Secret 的内容以文件形式挂载到 Pod 中,常用于注入配置文件或敏感信息。
volumes:
- name: config
configMap:
name: app-config
- name: secret
secret:
secretName: app-secret
StatefulSet 使用存储的特点
对于有状态应用,StatefulSet 提供了比 Deployment 更合适的管理方式,尤其在存储方面,它与 volumeClaimTemplates 配合使用,为每个 Pod 实例提供独立且稳定的存储。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: “mysql” # 需要关联一个 Headless Service
replicas: 3
template:
spec:
containers:
- name: mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
volumeClaimTemplates: # 存储卷声明模板
- metadata:
name: data # 每个 Pod 的 PVC 将以 `<volumeClaimTemplate名称>-<statefulset名称>-<序号>` 格式命名
spec:
accessModes: [ “ReadWriteOnce” ]
storageClassName: fast-ssd
resources:
requests:
storage: 100Gi
特点总结:
- 独立 PVC:每个 Pod(mysql-0, mysql-1, mysql-2)都会根据
volumeClaimTemplates 自动创建自己独有的 PVC 和 PV。
- 有序性:Pod 的创建、扩缩容、删除是按顺序进行的。
- 稳定标识:拥有稳定的 Pod 名称、主机名和 DNS 记录。
PVC 数据的备份与恢复
备份持久化数据是生产环境运维的重要环节。这里介绍两种常见思路。
使用 Velero 工具(推荐):
Velero 是一个强大的 Kubernetes 集群备份与恢复工具,可以备份整个命名空间资源及其关联的持久卷数据。
# 安装 Velero(需提前配置对象存储)
velero install
# 创建一个备份,快照持久卷
velero backup create mysql-backup \
--include-namespaces production \
--snapshot-volumes
# 从备份进行恢复
velero restore create \
--from-backup mysql-backup
手动备份方式:
对于简单的场景或特定卷,可以运行一个临时的 Pod,挂载需要备份的 PVC,然后使用 tar, rsync 或 restic 等工具将数据导出。
# 运行一个临时 Pod,挂载 PVC
kubectl run backup-pod --image=restic/restic:latest \
--restart=Never --rm -it \
-v <pvc-name>:/data -- sh
# 在 Pod 内执行备份命令
restic backup /data
希望这篇关于Kubernetes网络、服务和存储的梳理能对你的学习和面试准备有所帮助。理解这些核心概念并熟悉其配置方式,是掌握Kubernetes的关键一步。如果在实践中遇到具体的网络策略或存储配置问题,欢迎在云栈社区的技术论坛与大家一起探讨。

 发表于 2026-2-14 06:42:51
|
查看: 301|
回复: 0
发表于 2026-2-14 06:42:51
|
查看: 301|
回复: 0
