eBPF 基金会近期发布了一份重量级研究报告 《eBPF for the Infrastructure Platform》。这份报告清晰地揭示了一个正在发生的重大转变:eBPF 已经从早期的极客专属技术,演变为支撑云原生、数据中心和现代 AI 工作负载的通用平台层。报告对当下的基础设施实践进行了深入剖析,结论非常明确——无论是超大规模云厂商,还是寻求技术革新的中小型企业,都在加速将 eBPF 作为其基础设施的共同构建块。
为何 eBPF 对现代基础设施如此关键?
eBPF(extended Berkeley Packet Filter)是 Linux 内核提供的一种革命性技术。它允许我们在内核态安全地运行用户自定义的程序,从而实时观测和操控网络数据包、系统调用、进程行为等几乎所有内核事件。这听起来很抽象,但它的核心优势非常具体:
- 零侵入、高性能:程序直接在内核执行,几乎没有上下文切换的开销。
- 安全可验证:内核中的 verifier 会严格检查程序,确保其不会导致系统崩溃或越界访问内存。
- 动态加载:无需修改内核源码,也无需重启系统,即可部署或更新 eBPF 程序。
- 跨版本兼容:借助 CO-RE(Compile Once – Run Everywhere)技术,一套编译好的 eBPF 程序可以在不同的内核版本上运行。
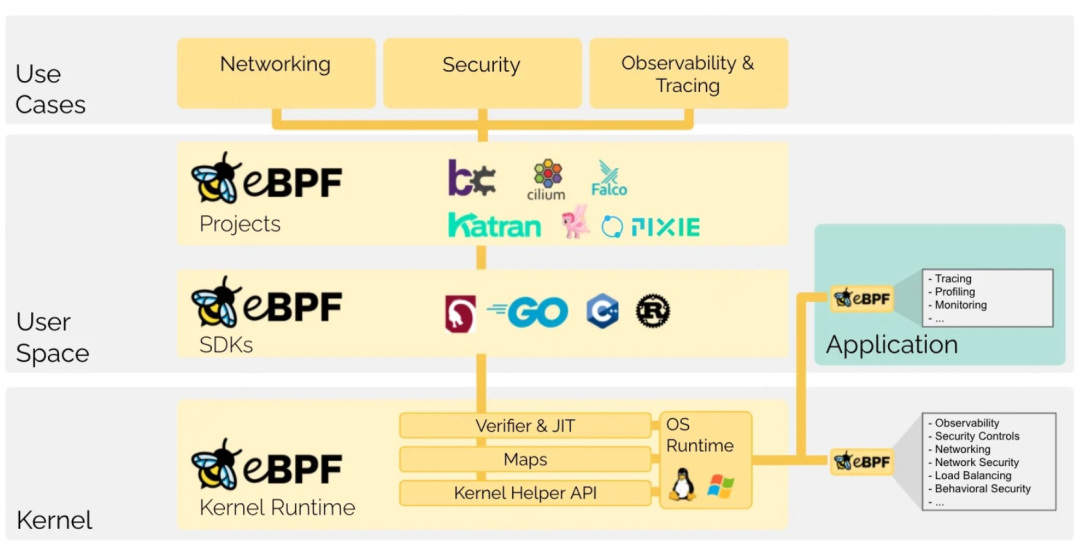
过去十年,eBPF 早已从最初的网络包过滤工具,成长为支撑可观测性、网络、安全乃至 AI/LLM 基础设施 的通用运行时。
正在取代传统工具
研究显示,基于 eBPF 的方案已在云网络和微服务架构中得到广泛应用,同时也成为那些需要在内核层面强制执行安全策略产品的核心技术。Meta、Netflix、Cloudflare 等公司最早在大规模生产环境中采用 eBPF,如今,其应用案例已扩散到更广泛的行业和场景中。

AI 与 LLM 大模型的痛点与 eBPF 的解法
现代 AI 集群,尤其是运行大语言模型(LLM)的集群,面临几个核心痛点:
- 资源调度复杂:成千上万的 GPU/TPU 相互连接,网络、内存、计算资源的调度极其复杂。
- 需要细粒度遥测:需要获取极细粒度的性能数据,例如 token 生成延迟、显存碎片情况、推理队列等待时间、RDMA 传输异常等。
- 传统监控手段不足:传统的用户态埋点监控难以覆盖内核边界的细微行为,且往往侵入性强,影响性能。
而 eBPF 的独特价值在此刻凸显出来:
- 内核边界高保真遥测:能够直接捕获系统调用、网络栈事件、CPU 调度事件,监控几乎没有盲区。
- 零代码侵入:无需修改训练框架(如 PyTorch、TensorFlow)或推理服务(如 vLLM、Triton)的任何一行代码。
- 性能开销极低:即使在拥有上万张加速卡的庞大集群中,也能维持可接受的性能影响。
- 支持 LLM 特有关注点:可以专门针对 token 生成速率、请求排队延迟、模型服务间的网络路径分析、异常 prompt 检测等场景进行定制化观测。
简单来说,AI 和 LLM 工作负载正在越来越依赖 eBPF 来获取高保真、低开销的遥测数据,从而实现更优的推理性能、更高效的工作负载调度以及大规模计算集群的资源利用率提升。这正是在 人工智能 领域构建稳健 可观测性 体系的关键一环。

生态成熟,开发门槛降低
早期 eBPF 的开发门槛极高,开发者需要精通内核源码、底层汇编语言,并时刻注意 verifier 的种种限制。如今情况已完全不同,围绕 eBPF 已经涌现出大量的开源项目和成熟的开发框架。用户可以直接使用这些现成的解决方案,或在其基础上进行二次开发,从而快速获得 eBPF 带来的能力。这些进步让 eBPF 从“内核专家专属”的工具,真正走向了“平台团队的基础设施标配”。
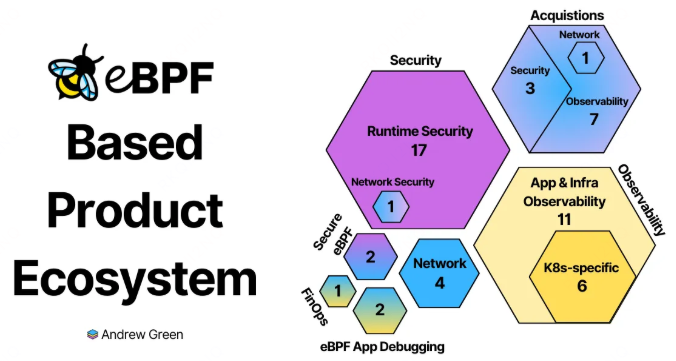
可以说,eBPF 正在重塑我们对基础设施的监控、安全和 网络 能力的理解。对于任何正在构建或运维现代计算平台,尤其是 AI 基础设施的团队而言,深入理解并善用 eBPF 已不再是一个可选项,而是保持技术竞争力的必然选择。如果你想了解更多前沿基础设施技术的实践与讨论,欢迎来 云栈社区 交流分享。 |  发表于 2026-2-18 20:34:10
|
查看: 285|
回复: 0
发表于 2026-2-18 20:34:10
|
查看: 285|
回复: 0
