做嵌入式开发久了,你一定见过那种“一个函数调半个工程”的代码。应用层想点个灯,直接调用HAL层的函数;协议解析完想更新UI,又去include显示模块的头文件。改动一个模块,编译报错一片——这就是层与层之间耦合过紧的代价。
今天不聊那些高大上的中间件框架,就聊一个在实际项目中经过反复验证的方案:用消息订阅机制,把嵌入式系统的各层拆干净。顺带说说轻量级消息和重量级消息的适配问题,这个坑不少人踩过。
一、先看看“耦合地狱”长什么样
以前接手过一个智能表计项目,系统分三层:硬件驱动层、协议处理层、应用业务层。架构图画出来挺清晰,但打开代码一看,画风完全不对:
协议层解析完一帧数据后:
→ 直接调用 app_display_update() 刷新屏幕
→ 直接调用 app_storage_save() 写Flash
→ 直接调用 drv_led_blink() 闪个灯
应用层要发一条响应:
→ 直接调用 proto_build_response() 组帧
→ 直接调用 drv_uart_send() 发出去
这种代码能跑,但它带来了三个致命问题:
1)编译依赖传染。 协议层include了应用层的头文件,应用层又include了驱动层的头文件。你动了显示模块的一个结构体定义,协议层也得重新编译。项目大了以后,改一行代码,编译五分钟。
2)移植基本靠重写。 换个平台,驱动层全换了,结果协议层里到处是drv_xxx()的直接调用。这个协议层理论上应该跨平台复用,现在却复用不了。
3)单元测试没法做。 想单独测试协议解析逻辑?不好意思,它依赖app层和drv层的十几个函数,你得把半个工程都mock掉。
根本原因就一条:上层直接知道下层的存在,下层也直接知道上层的存在。层与层之间没有“缓冲带”。
我们期望的架构是这样的:
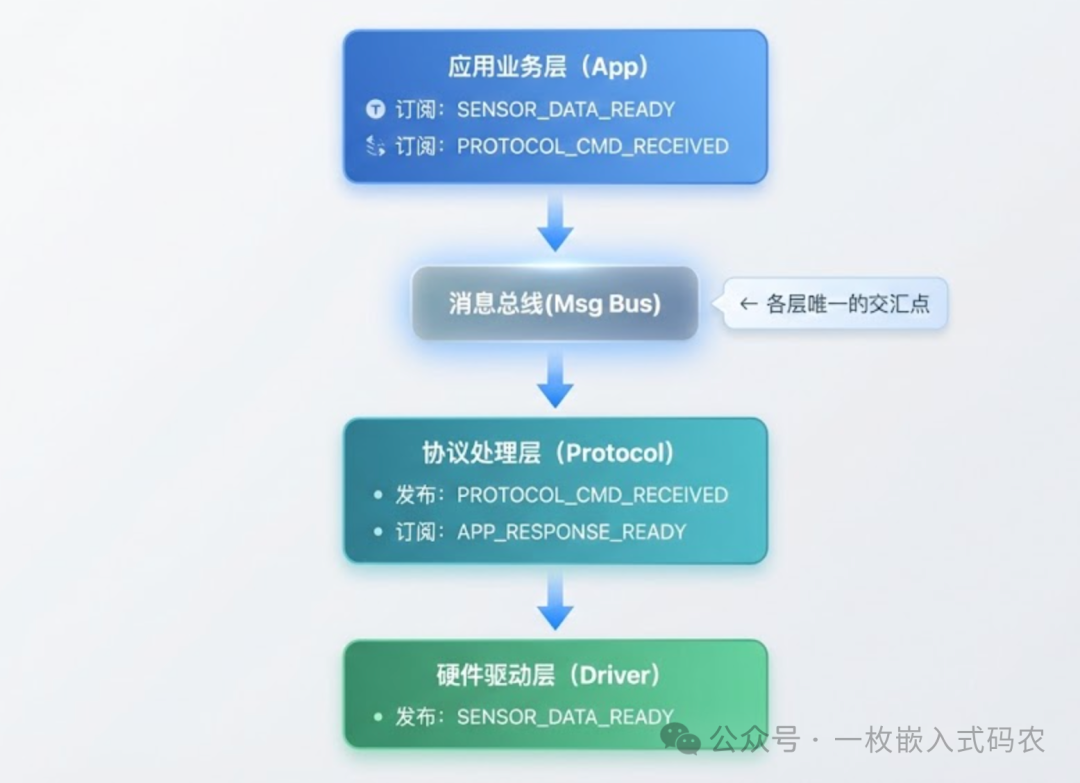
每一层只认识“消息总线”,不认识其他层。谁发的消息、谁收的消息,彼此不关心。这就是消息订阅带来的解耦效果。这种设计模式是构建高内聚、低耦合系统设计的关键。
二、消息总线的核心实现
说白了,消息总线干的事很简单:维护一张“谁关心什么消息”的表,消息来了就查表派发。
2.1 核心数据结构
先定义消息ID和回调函数的格式:
/* 消息ID枚举 —— 全局唯一,各层共用这一份定义 */
typedef enum {
MSG_SENSOR_DATA_READY = 0,
MSG_PROTOCOL_CMD_RECEIVED,
MSG_APP_RESPONSE_READY,
MSG_KEY_EVENT,
/* ... 按需扩展 ... */
MSG_ID_MAX
} MsgId_e;
/* 统一的消息体 */
typedef struct {
MsgId_e id;
uint16_t len;
void *pData; /* 指向消息负载 */
} Msg_t;
/* 订阅者回调函数原型 */
typedef void (*MsgHandler_f)(const Msg_t *msg);
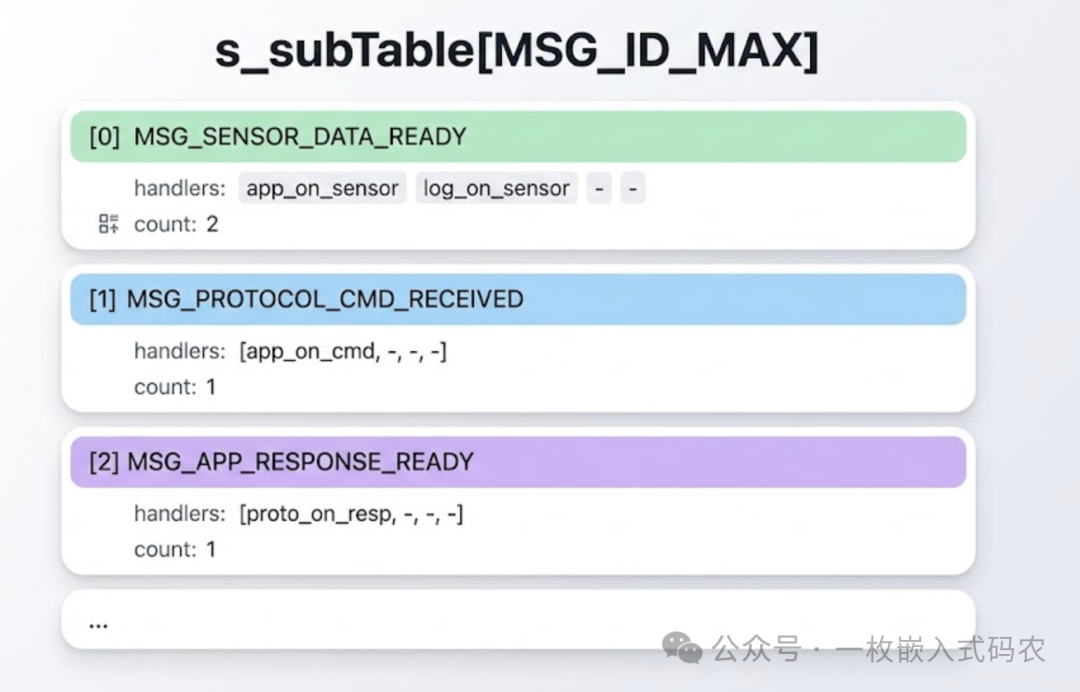
然后是核心的订阅表。在资源紧张的MCU上,我更推荐静态数组而不是链表——省掉malloc,也避免了内存碎片:
#define MAX_SUBSCRIBERS_PER_MSG 4 /* 每条消息最多几个订阅者,按项目调 */
typedef struct {
MsgHandler_f handlers[MAX_SUBSCRIBERS_PER_MSG];
uint8_t count;
} MsgSubscribers_t;
/* 订阅表:以消息ID为索引 */
static MsgSubscribers_t s_subTable[MSG_ID_MAX];
整个结构在内存里长这样:
2.2 订阅和发布
接口就两个函数,足够简单:
/* 订阅:把回调挂到对应消息ID下 */
int msg_subscribe(MsgId_e id, MsgHandler_f handler)
{
if (id >= MSG_ID_MAX || handler == NULL)
return -1;
MsgSubscribers_t *sub = &s_subTable[id];
if (sub->count >= MAX_SUBSCRIBERS_PER_MSG)
return -1; /* 订阅满了 */
sub->handlers[sub->count++] = handler;
return 0;
}
/* 发布:遍历该消息的所有订阅者,逐个回调 */
void msg_publish(const Msg_t *msg)
{
if (msg == NULL || msg->id >= MSG_ID_MAX)
return;
MsgSubscribers_t *sub = &s_subTable[msg->id];
for (uint8_t i = 0; i < sub->count; i++) {
sub->handlers[i](msg);
}
}
用起来什么效果?协议层解析完一帧数据,不再直接调用app层函数,而是:
/* 协议层 —— 只管发布,不关心谁来处理 */
void protocol_on_frame_received(uint8_t *frame, uint16_t len)
{
CmdPayload_t cmd;
parse_frame(frame, len, &cmd);
Msg_t msg = {
.id = MSG_PROTOCOL_CMD_RECEIVED,
.len = sizeof(cmd),
.pData = &cmd
};
msg_publish(&msg);
}
应用层在初始化时订阅自己关心的消息:
/* 应用层 —— 只管订阅,不关心谁发的 */
void app_init(void)
{
msg_subscribe(MSG_PROTOCOL_CMD_RECEIVED, app_handle_cmd);
msg_subscribe(MSG_SENSOR_DATA_READY, app_handle_sensor);
}
static void app_handle_cmd(const Msg_t *msg)
{
CmdPayload_t *cmd = (CmdPayload_t *)msg->pData;
/* 处理命令... */
}
协议层不知道app层的存在,app层也不知道协议层的存在。 两边都只跟msg_bus.h打交道。你把app层整个删掉,协议层编译照样过——这就是解耦该有的样子。核心数据结构的组织与指针的使用息息相关。
三、轻量级消息和重量级消息怎么适配?
到这里你可能觉得方案已经完整了。但实际项目中马上会遇到一个问题:不是所有消息都一样“轻”。
一个按键事件,负载可能就一个uint8_t,4字节搞定。但一帧GPS数据,可能有200字节的NMEA报文;一次OTA升级通知,可能携带几KB的固件信息。如果消息总线只有一种处理方式,要么浪费内存,要么塞不下。
我把消息分成两类:

3.1 轻量级消息:直接嵌入
对于几个字节的小数据,最高效的方式是直接塞进消息体,用union避免额外的指针跳转:
typedef struct {
MsgId_e id;
uint16_t len;
union {
void *pData; /* 重量级:指向外部缓冲区 */
uint32_t value; /* 轻量级:直接存值 */
uint8_t bytes[8]; /* 轻量级:最多嵌8字节 */
} payload;
} Msg_t;
发一个按键消息就特别干净:
void drv_key_isr(uint8_t key_code)
{
Msg_t msg = {
.id = MSG_KEY_EVENT,
.len = sizeof(uint8_t),
};
msg.payload.value = key_code; /* 值直接嵌入,零拷贝 */
msg_publish(&msg);
}
好处是什么? 消息发布完,栈上的msg变量就可以回收了。订阅者在回调里直接读msg->payload.value,不存在“数据还在不在”的问题。生命周期管理简单到不用管。
3.2 重量级消息:引用+约定
大块数据不可能嵌进消息体(嵌进去消息体就膨胀了,每条消息都占那么大空间,不划算)。这时候用指针引用外部缓冲区:
void protocol_on_gps_frame(uint8_t *raw, uint16_t len)
{
/* raw指向接收缓冲区中的数据 */
Msg_t msg = {
.id = MSG_GPS_DATA_READY,
.len = len,
};
msg.payload.pData = raw; /* 引用传递 */
msg_publish(&msg);
/* ⚠ 发布是同步的,回调执行完才到这里 */
/* 此时可以安全释放或复用raw缓冲区 */
}
但这里有一个必须严肃对待的问题:数据的生命周期。
因为pData只是个指针,不拥有数据。如果发布者在回调还没执行完就把缓冲区释放了或者覆盖了,订阅者读到的就是脏数据。
我在项目中定下一条铁律:
同步发布模式下(也就是msg_publish直接调回调),发布者保证在publish返回前不动缓冲区。 这是最简单的契约,不需要引用计数,不需要深拷贝。
如果你的系统是异步投递(比如把消息扔到队列里,另一个任务取出来再派发),那订阅者收到消息时,原始缓冲区可能早就被覆盖了。这时候有两种应对:
方案A:发布时深拷贝到队列。 消息入队时把payload数据也memcpy进去。简单粗暴,但队列要足够大。
方案B:引用计数。 给大块数据包一层引用计数的wrapper,最后一个订阅者用完才真正释放。实现稍复杂,但内存利用率高。
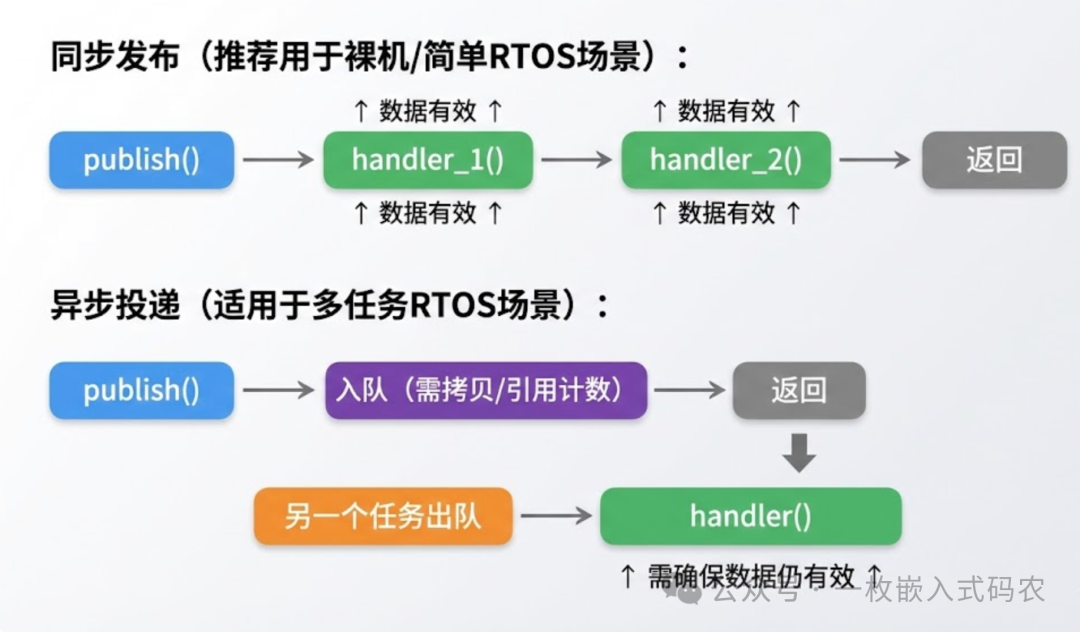
多数裸机项目和轻量RTOS项目,同步模式就够用了。别过度设计。如果你在云栈社区搜索相关话题,会发现很多关于实时系统网络通信的讨论也遵循类似的“契约式”设计。
四、几点实战经验
最后分享几条我踩坑后总结的经验,不一定放之四海而皆准,但至少帮你少走弯路:
1)消息ID全局统一定义,放在一个独立头文件里。 比如msg_id.h,各层只include这一个文件。千万别各层各定义一套,会打架。
2)回调里不要做太重的事。 同步发布模式下,msg_publish的耗时等于所有订阅者回调耗时之和。如果某个回调里去刷屏、写Flash,发布者会被卡住。重操作应该在回调里设个标志位,回到主循环再慢慢做。
3)中断里发布消息要小心。 如果你的msg_publish是直接调用回调,那中断里发布就意味着回调也运行在中断上下文中。要么保证回调足够短,要么把中断里的发布改成“放入队列、主循环再派发”。
4)订阅上限要合理设置。 MAX_SUBSCRIBERS_PER_MSG设太大浪费RAM,设太小运行时才发现订阅失败——这在嵌入式里是很隐蔽的bug。建议加个assert或错误日志,开发阶段就暴露问题。
5)调试时加一层trace。 在msg_publish里加条件编译的打印,把消息ID和订阅者个数输出到串口。系统行为不符合预期时,这条trace能帮你快速定位“消息发了没?谁收了?”。
写在最后
消息订阅不是什么新概念,桌面软件、服务器后端玩了几十年了。但嵌入式场景有它的特殊性:内存小、没有动态分配的底气、对实时性有要求。所以照搬互联网那套pub/sub框架肯定不行,得做裁剪。
这篇文章给出的方案,核心代码不到100行,额外RAM开销可控(取决于消息ID数量和订阅者上限),没有动态内存分配,裸机和RTOS都能用。在我经历的几个项目中,模块间的编译依赖减少了60%以上,协议层的跨平台复用也真正落了地。
如果你正在被“改一处、崩一片”的耦合问题困扰,不妨从最痛的那两个模块开始,先引入消息总线做个试点。一旦尝到解耦的甜头,你就回不去了。
 发表于 2026-2-19 00:38:42
|
查看: 198|
回复: 0
发表于 2026-2-19 00:38:42
|
查看: 198|
回复: 0
