实时视频生成,这个听起来就充满未来感的技术,却一直被一个“算力黑洞”所阻碍——那就是视频扩散模型中核心的3D自注意力机制。它的计算成本高得吓人,与视频的帧数、分辨率的乘积呈平方级增长。
为此,卡内基梅隆大学、布法罗大学和Morpheus AI的研究团队提出了一项名为 MonarchRT 的工作。他们没有在简单的“剪枝”思路上死磕,而是通过一种名为“Monarch矩阵”的结构化方法,对视频注意力机制进行了革命性的近似。结果令人震惊:在将注意力计算量削减 95% 的情况下,视频生成质量几乎无损,并首次在单张RTX 5090消费级显卡上,让Self-Forcing这样的先进模型实现了 16 FPS 的实时生成。

实时视频生成的算力瓶颈:为何传统稀疏注意力失灵了?
要理解MonarchRT的突破,必须先搞清楚为什么之前那些旨在“省力”的稀疏注意力方法,在实时视频生成这个战场上失效了。关键在于两个实时场景下的严苛条件:自回归 和 少步采样。
自回归 意味着模型像写小说一样,一帧一帧地生成视频,后续帧严重依赖前序帧的内容。这种模式导致了错误会在时间维度上累积,因此 每一步注意力计算都必须极其精准,容不得大的近似误差。
少步采样 则是为了追求速度。传统扩散模型可能需要50步甚至更多的去噪迭代才能获得好效果,但实时生成等不了那么久。像Self-Forcing这样的前沿模型会将步数压缩到仅4步。这意味着 每一步去噪承载的信息量剧增,注意力机制必须在更少的步骤里捕捉更复杂、更丰富的模式。
在这双重“高压”下,传统的“挑重点”(如top-k)式稀疏注意力顶不住了。论文做了一个极具说服力的实验:他们启用了一个“预言家”,让它直接查看完整计算出的稠密注意力矩阵,并只保留其中最重要的前10%的连接(即实现90%稀疏度)来近似原矩阵。
结果如何?即使开了这种“天眼”,仅用10%的计算量,生成的视频质量依然惨不忍睹,物体会出现严重的扭曲失真。
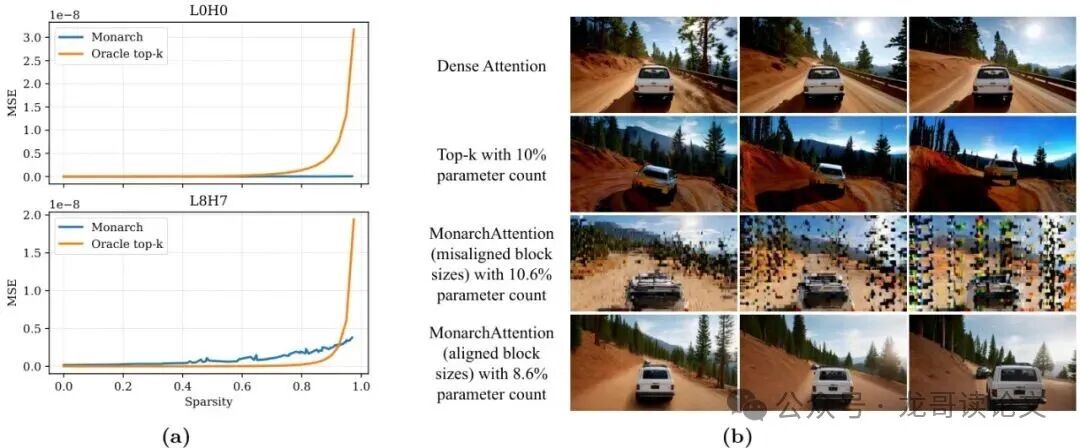
图1左图清晰地表明,随着对稀疏度的要求变高(即允许的计算量变少),基于“挑重点”的预言家方法的误差急剧飙升。这个实验有力地反驳了“视频注意力是稀疏的”这一简单假设。它揭示了一个关键事实:在实时视频生成场景下,注意力矩阵中 重要的连接太多了,单纯依靠稀疏策略根本抓不过来。
解构3D注意力:位置周期、语义稀疏与密集混合的三角难题
既然“抓重点”行不通,那么视频注意力矩阵的真实结构到底是什么样的?论文给出了一个深刻的洞见:3D视频注意力是一个“三合一”的复合体,它同时包含三种相互交织的模式:
-
周期性位置模式
视频中的物体在时间和空间上是连续的。一个像素通常会更多地关注其 相邻帧 和 相邻空间位置 的像素。这种由物理连续性决定的关注模式,在注意力矩阵中会形成 明显的、重复的带状结构,并且这种结构是 密集 的(大量连接都重要)。
-
稀疏语义模式
视频中还存在超越纯粹位置关系的关联。例如,一只狗的鼻子(在某一帧的某个位置)和几帧后它的舌头(位置已改变)之间存在语义联系。这种联系是 动态的、长距离的,但在整个注意力矩阵中占比很小,表现为 稀疏的亮点。
-
密集混合
除了上述两种具体模式,注意力机制还需要一种“全局搅拌”的能力,以确保信息能在所有token之间充分流动和混合,这是生成一致、高质量内容的基石。这就要求近似方法不能丧失这种 全局的、密集的交互潜力。
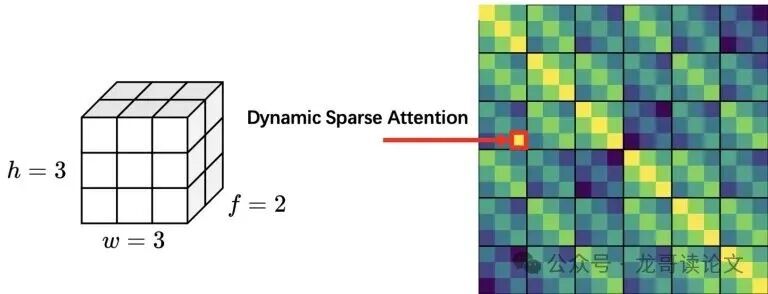
如图5所示,背景的条纹图案代表了周期性的位置模式,而那个孤立的亮斑则代表了一个稀疏的语义关联。
传统稀疏注意力(如top-k)试图只捕捉那些“亮点”,却丢失了维持视频连续性的“条纹背景”。而低秩近似方法想用几个全局模式概括一切,又难以抓住那些关键却稀疏的“亮点”。数据也支持这一观点:分析显示,为了恢复95%的注意力分数,某些注意力头需要关注多达84%的键值token,这再次印证了 视频注意力远非稀疏。
因此,实时视频生成对注意力近似提出了一个“三角难题”:必须同时、高效地刻画位置(密集)、语义(稀疏)和全局混合(密集)这三种模式。现有的单一方法都难以胜任。这促使研究人员寻找一种更强大、更统一的数学工具,而这正是 Monarch矩阵 登场的契机。关于矩阵分解与高效计算的更多思想碰撞,可以在 云栈社区 的算法板块找到深入讨论。
Monarch矩阵:一种统一而强大的结构化近似工具
Monarch矩阵 起源于对快速傅里叶变换等高效算法的数学抽象。它的核心思想很巧妙:通过一个固定的置换操作,将一个大矩阵重新排列,从而暴露出其内在的“块状低秩”结构。然后,用两个 块对角矩阵 的乘积来近似这个置换后的矩阵。
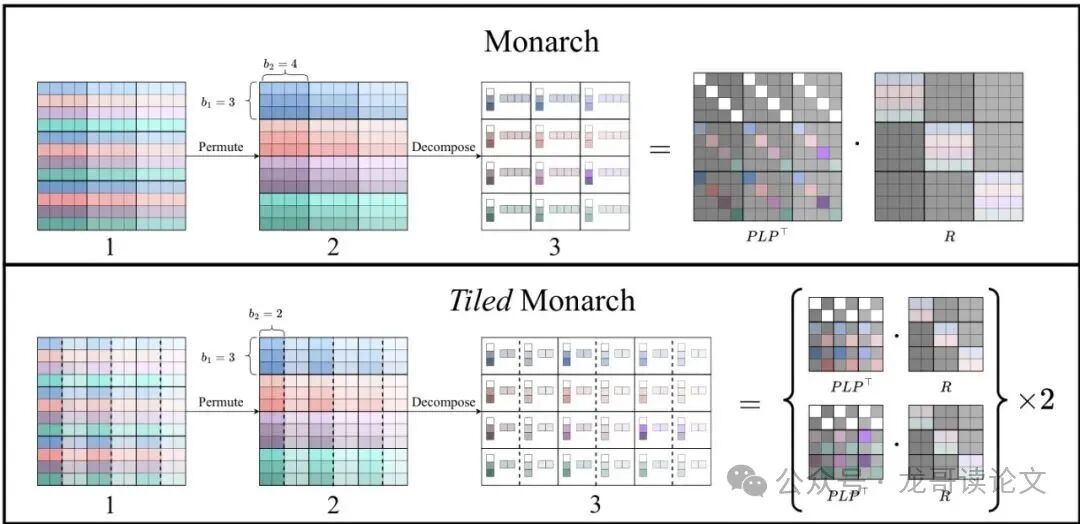
简单来说,它假设一个矩阵经过巧妙重排后,可以被视为许多小块,而每个小块都近似是一个秩为1的矩阵(即可表示为两个向量的外积)。Monarch的强大之处在于其 表达能力的统一性:它不仅可以表示稀疏矩阵或低秩矩阵,还能表示介于两者之间的各种复杂结构。在计算上,得益于块对角结构,它能实现接近线性的复杂度。
此前已有研究提出 MonarchAttention,将Monarch矩阵用于近似注意力机制。如图3所示,它通过交替优化算法,根据查询Q和键K直接迭代地优化Monarch的两个因子L和R,最终得到一个 稠密的、但对Monarch结构高度适配的注意力矩阵近似。
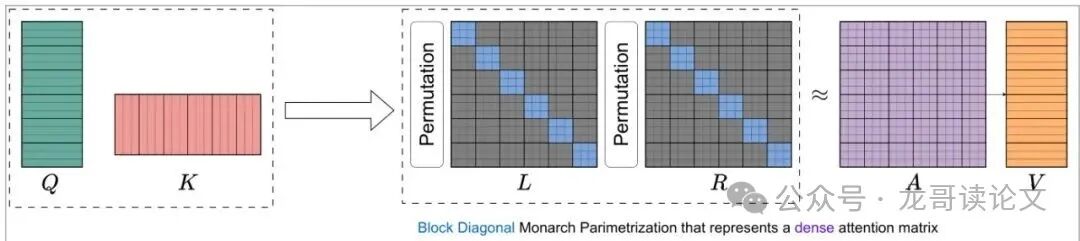
这正是解决前述“三角难题”的潜力股:用结构化的稀疏参数,来表达可能非常稠密的注意力。然而,直接将MonarchAttention套用到视频生成上效果并不理想,MonarchRT正是通过三项关键创新扫清了这些障碍。
MonarchRT三大创新:对齐、分块与微调
创新一:块对齐策略
Monarch分解中“块”的划分必须与视频数据的时空维度对齐。例如,对于一个形状为(帧数f,高度h,宽度w)的视频,总token数 N = fhw。如果选择块大小 (b1, b2) = (f*h, w),这意味着我们把所有帧和所有行(即整个时空“柱状体”)放在一个块里,只在宽度维度上进行块间交互。这样的对齐能让Monarch的块对角结构完美地刻画视频中位置衰减的周期性模式。
如果块划分是混乱的(例如随机打乱token索引),就会把毫不相干的像素混在同一个块里,导致该块无法用低秩来近似,最终生成效果如图1第二行所示,会产生严重的像素错乱。
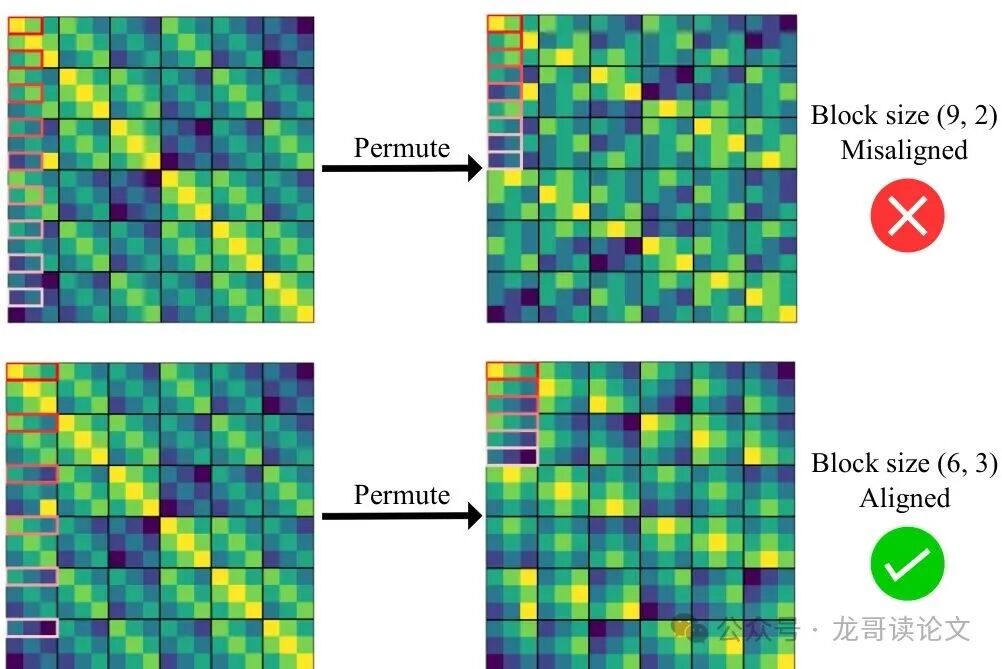
图7直观对比了对齐与未对齐块划分的效果。未对齐时,块内部结构混乱;对齐后,块内部呈现清晰的规律性,更接近低秩。
创新二:平铺Monarch参数化
对齐解决了位置模式的表征问题。但有时,一个块内可能恰好包含了多个稀疏的语义关联,这会破坏该块的“低秩性”。原始Monarch参数化对此无能为力,因为它的总块数是固定的。
MonarchRT提出了 “平铺” 扩展。如图2底部所示,它将每个大块进一步细分为更小的“瓦片”,每个瓦片独立进行Monarch分解。这样,在保持与视频维度对齐的大框架下,通过增加瓦片数量,可以灵活地提升模型容量,以捕捉那些不凑巧落在同一个块内的多个语义关联,实现了近似精度与计算开销的单调可调。
创新三:微调与高效内核
MonarchAttention的迭代优化在推理时太慢。为了达到高质量(可能需要10次迭代),延迟太高;如果只做1次迭代,质量又会下降。
MonarchRT的解决方案很巧妙:对模型进行微调。在微调过程中,模型学会了如何让单次迭代的MonarchAttention就能产生出色的效果。如图4右所示,经过微调的1次迭代MonarchRT,其质量堪比未微调时的10次迭代,从而极大地降低了推理延迟。
此外,团队还手写了 定制的Triton GPU内核,针对Monarch的块对角结构进行了极致优化,进一步压榨硬件性能。这种专注于底层性能优化的实践,正是许多 开源实战 项目追求的目标。
突破性成果:95%稀疏度下的无损质量与16 FPS实时生成
那么,MonarchRT的实际表现究竟如何?论文在多个前沿视频生成模型上进行了全面测试,结果堪称惊艳。
1. 质量保持:95%稀疏度下的无损表现
在自回归实时模型 Self-Forcing 上,MonarchRT在 注意力计算量减少95% 的情况下,其生成视频在人类评估和自动化指标上,与使用完整注意力计算的原始模型 质量相当。而其他稀疏注意力方法在超过85%稀疏度时质量就会大幅下滑。

表1显示,经过微调的MonarchRT在几乎所有VBench子项上都与原始模型持平甚至略有优势。
2. 速度飞跃:超越FlashAttention系列内核
得益于高效的内核实现和95%的稀疏度,MonarchRT在注意力计算速度上实现了巨大飞跃。如表5和表6所示,在RTX 5090上,MonarchRT比著名的FlashAttention-2快11.8倍;在H100上,比FlashAttention-3快5.6倍;甚至比最新的FlashAttention-4也有1.4倍的领先。
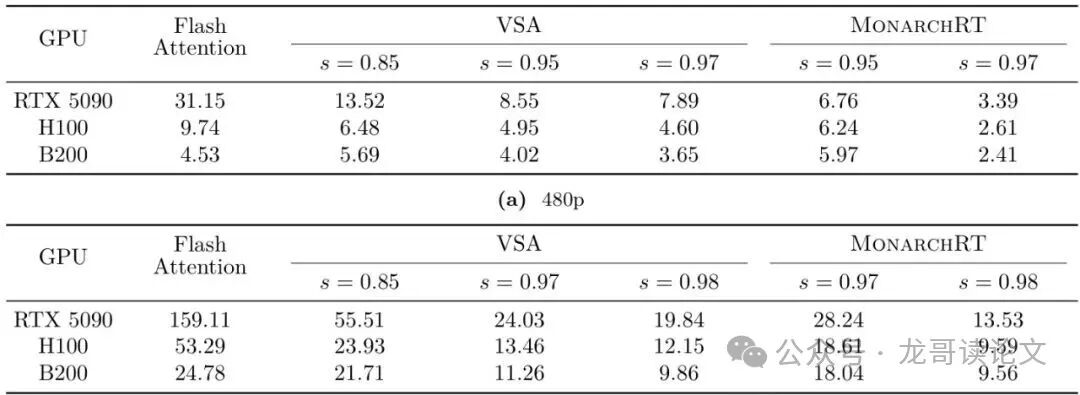
表5和表6表明,MonarchRT在高分辨率下的速度优势更加明显。
3. 最终成就:单卡16 FPS实时生成
综合质量和速度的提升,带来了里程碑式的成果。在单张RTX 5090显卡上,使用4步采样的模型,结合MonarchRT,端到端生成视频的延迟被大幅降低。这使得在Self-Forcing模型上实现 16 FPS的实时视频生成 成为了可能。

最后,让我们直观感受一下MonarchRT的生成效果。以下动图展示了在不同复杂提示词下,MonarchRT生成的视频画面,其细节、一致性和动态效果都令人印象深刻。





核心问题解答
这篇论文解决的核心问题是什么?
它精准地命中了实时视频生成中3D自注意力机制计算成本过高这一核心瓶颈。特别针对“自回归”和“少步采样”这两个严苛条件,提出了一种能大幅减少计算量(高达95%稀疏度)且几乎不损失生成质量的新方法。
Monarch矩阵到底是什么?
Monarch矩阵是一种“结构化矩阵”,是一个强大的数学框架。它通过固定的置换和块对角分解,能够统一地表示稀疏矩阵、低秩矩阵以及介于两者之间的复杂结构。因此,它比单一的稀疏或低秩近似具有更强的表达能力,非常适合用来刻画视频注意力这种混合模式。对这类底层 注意力机制 的革新,是推动AIGC发展的关键。
Self-Forcing、Wan 2.1这些模型是什么?
它们都是当前最先进的视频生成扩散模型。Wan 2.1 更偏向高质量、多步(如50步)生成。Self-Forcing 则专为实时交互设计,采用自回归和少步(如4步)采样,是本文主攻的“实时模型”代表。其他致力于实时视频生成的研究还包括Genie 3, WorldPlay等。
总结与展望
MonarchRT的工作展示了一条高效视频生成的清晰路径:通过深入理解注意力机制的内在结构(位置周期性+语义稀疏性+全局混合),并采用Monarch矩阵这一强大的结构化工具进行近似,成功地在计算效率和生成质量之间取得了突破性平衡。
这项研究不仅提供了一个高效的工程解决方案,其开源代码也为社区后续的复现与改进奠定了坚实基础,更重要的是,它为理解和优化高维数据(如图像、视频、3D)的注意力机制提供了新的理论视角和实用框架。随着算力需求的持续增长,这类结构化、高效化的模型设计思路将变得越来越重要。
 发表于 2026-2-20 19:52:19
|
查看: 189|
回复: 0
发表于 2026-2-20 19:52:19
|
查看: 189|
回复: 0
