谷歌正式发布Gemini 3.1 Pro。在衡量模型解决全新逻辑模式的ARC-AGI-2基准测试中,其得分高达77.1%,相比于前代Gemini 3 Pro的31.1%,实现了超过一倍的增长。
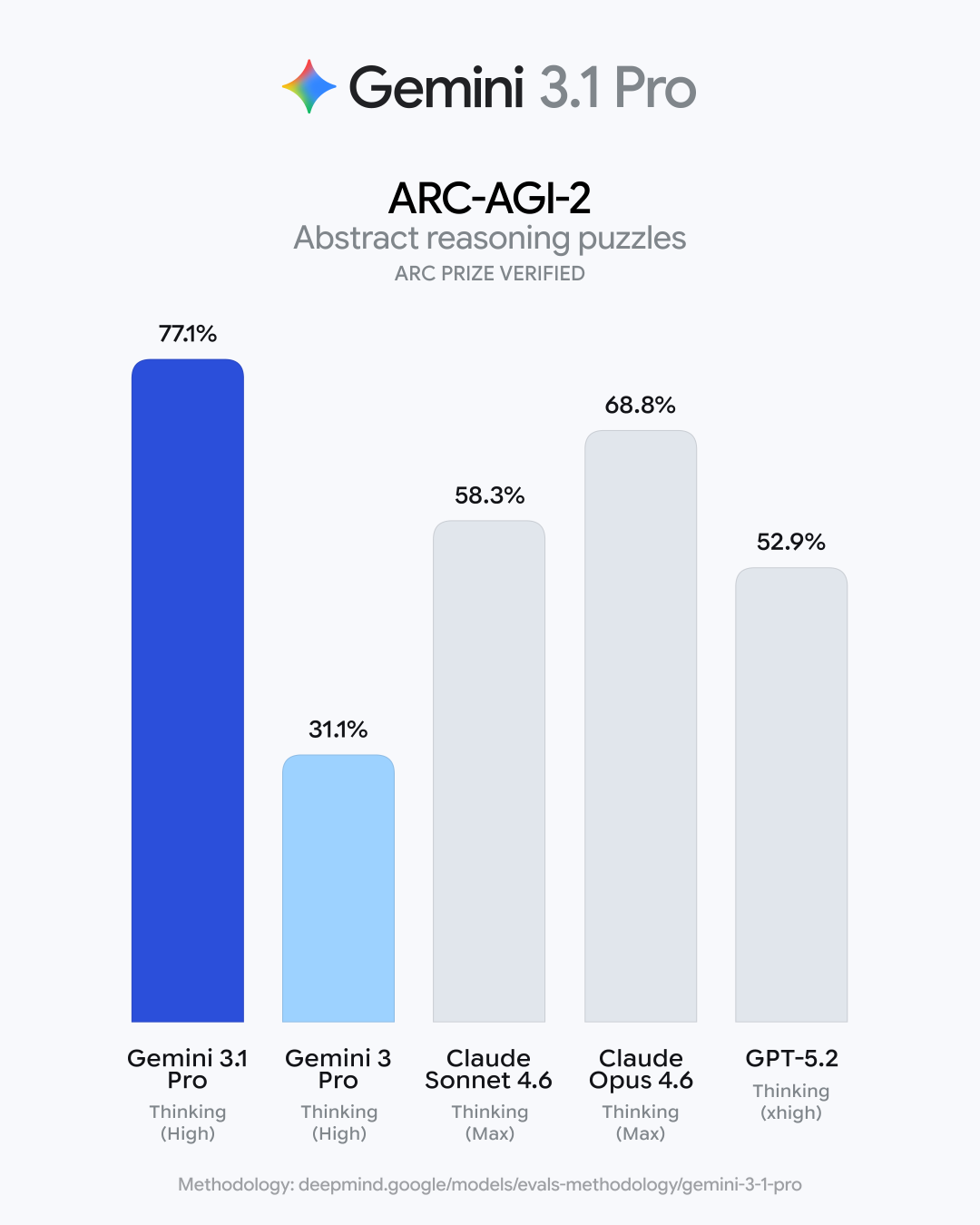
ARC-AGI-2测试的核心并非考察记忆能力,而是评估模型面对前所未见的逻辑模式时,是否能真正理解并解决问题。有社区评论指出,这一巨大进步可能意味着模型开始从简单的模式匹配转向深度的逻辑理解。
具体基准测试表现
根据官方发布的详细基准测试数据,Gemini 3.1 Pro在多个关键领域实现了显著突破:
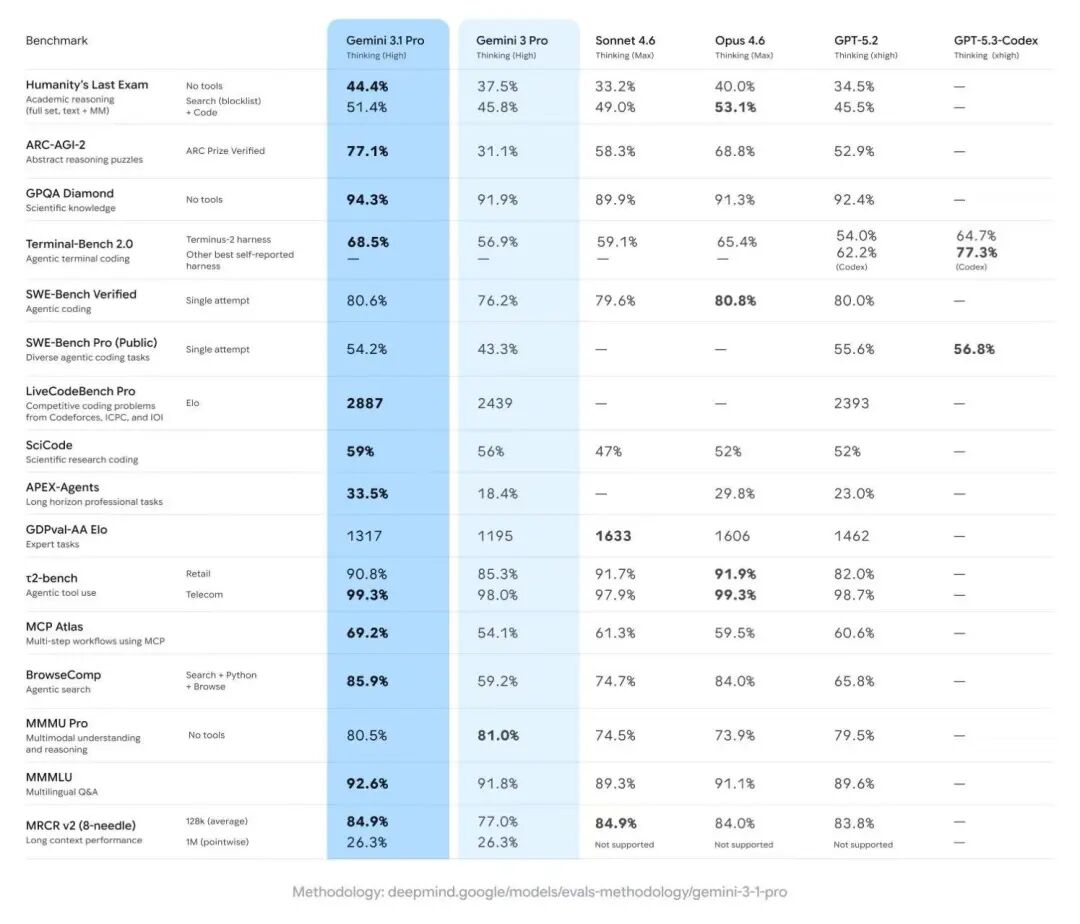
其智能体工具使用能力提升了82%,在APEX-Agents测试中从18.4%跃升至33.5%。同时,在MCP Atlas(69.2%)和BrowseComp(85.9%)测试中均位列第一。
编程能力同样亮眼,在评估实际编程和工具使用能力的严格测试中,SWE-Bench Verified得分80.6%,Terminal-Bench 2.0得分68.5%。
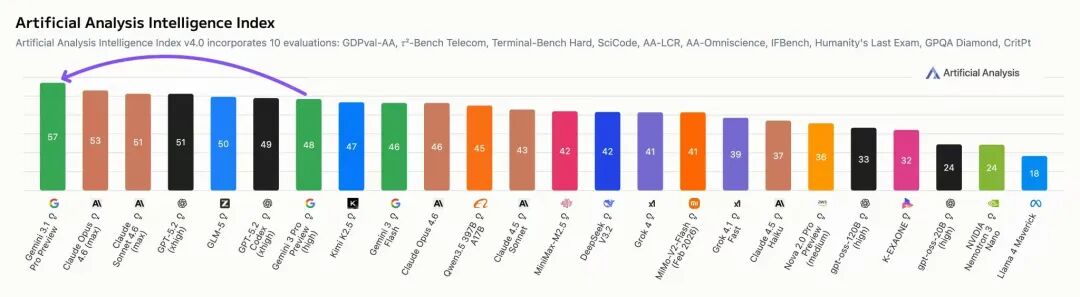
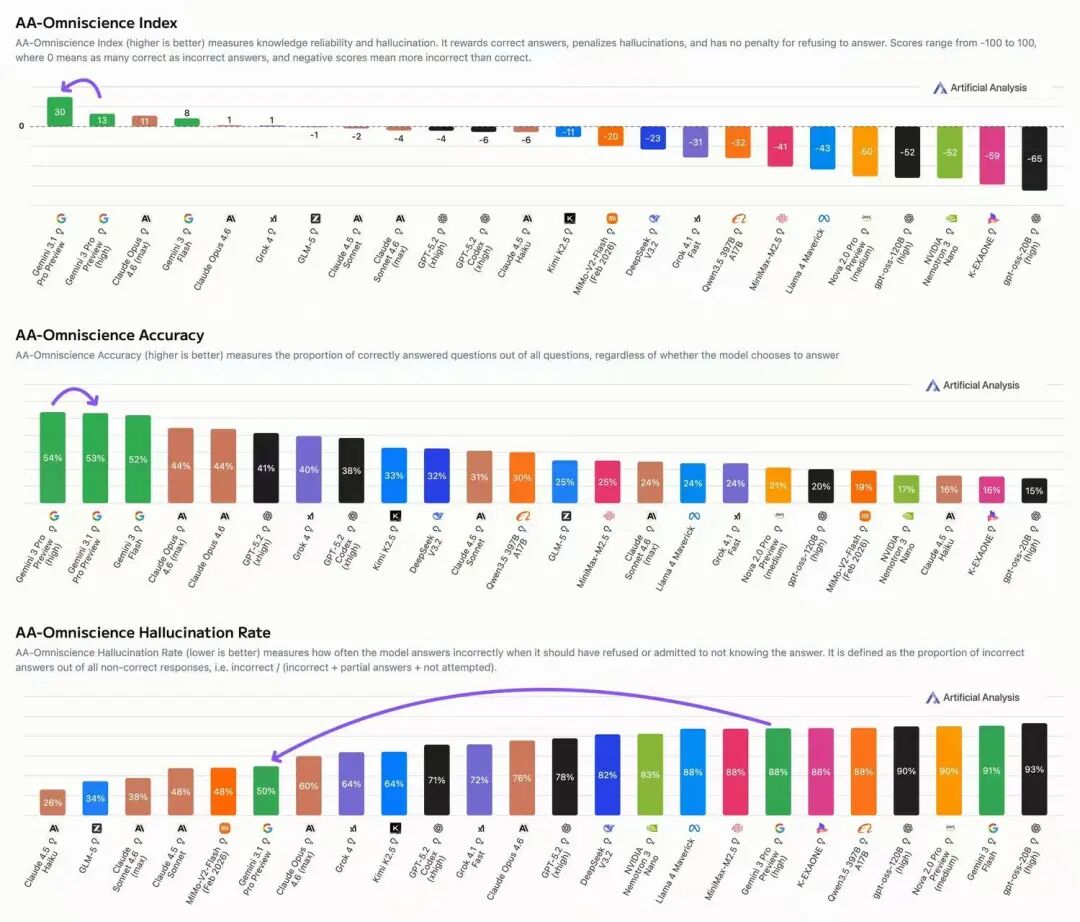
此外,根据独立分析机构Artificial Analysis发布的最新v4.0智能指数报告(该指数包含10项综合评估),谷歌Gemini 3.1 Pro预览版以57分的成绩重新夺回人工智能模型性能榜首,领先于Claude Opus 4.6。
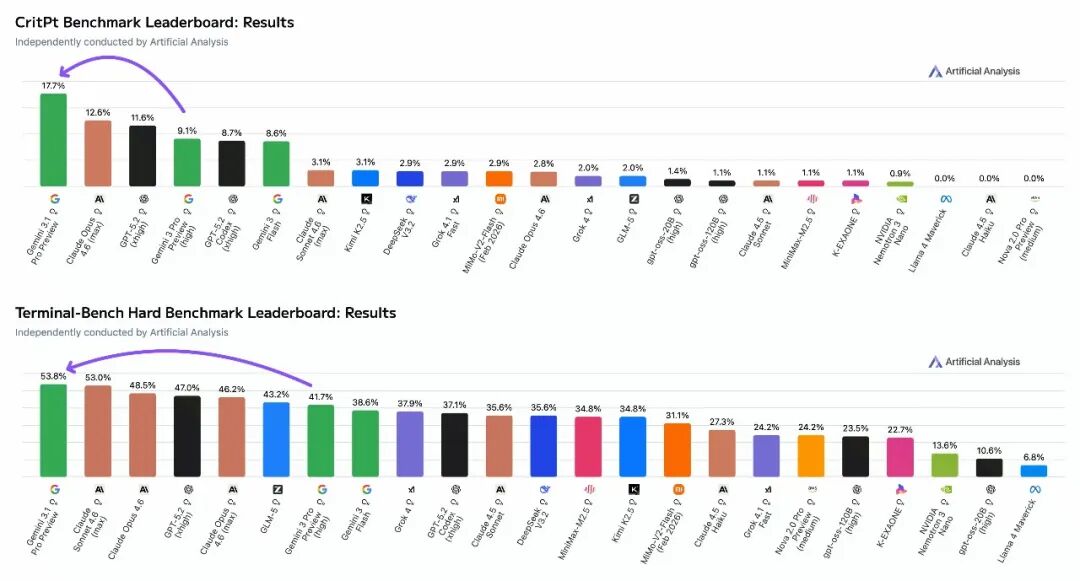
在报告涉及的六项领先评估中,最突出的是CritPt物理推理测试。该测试使用未发表的研究级物理问题,对模型的科学推理能力要求极高。Gemini 3.1 Pro Preview得分为18%,超出第二名5个百分点。
在编程能力方面,该模型在Terminal-Bench Hard(智能编程和终端使用)和SciCode(编程)测试中均排名第一,分别获得54%和59%的成绩,领跑编程指数榜单。
在知识可靠性与幻觉控制方面,模型也取得了重大进步。在AA-Omniscience测试中,其幻觉率从88%大幅降至50%,同时准确率保持在53%的稳定水平。这17分的提升主要得益于模型在不确定答案时,减少了错误的猜测行为。
性能与成本效率
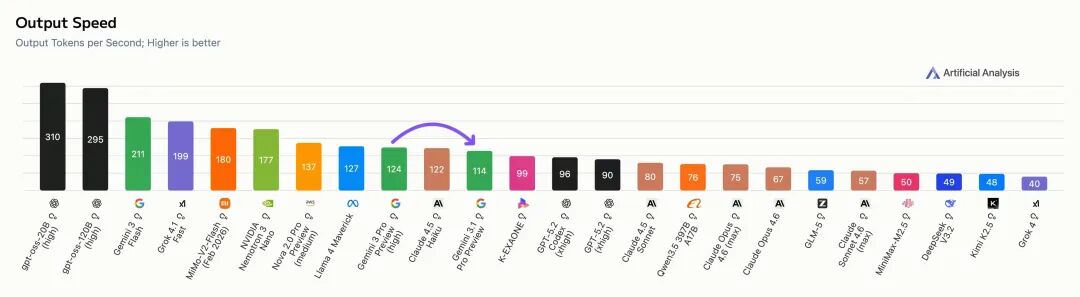
速度方面,Gemini 3.1 Pro Preview的平均输出速度为每秒114个令牌,虽比前代略慢,但在智能指数前十的模型中仍属较快,仅次于谷歌自家的其他模型。
模型保持了100万令牌的上下文窗口,支持工具调用、结构化输出和JSON模式。在多模态理解与推理方面,Gemini 3.1 Pro Preview在MMMU-Pro测试中排名第一,进一步巩固了谷歌在该领域的优势。
需要指出的是,在评估实际工作任务的GDPval-AA测试中,模型的ELO分数虽然从前代提升了100多分,达到1316,但仍落后于Claude Sonnet 4.6、Opus 4.6、GPT-5.2 (xhigh)等竞争对手。
成本控制是本次发布的一大亮点。Gemini 3.1 Pro Preview运行完整智能指数测试的总成本仅为892美元,不到Claude Opus 4.6 (max) 和 GPT-5.2 (xhigh) 等顶级模型的一半,尽管仍比GLM-5等开源模型高出约2倍。
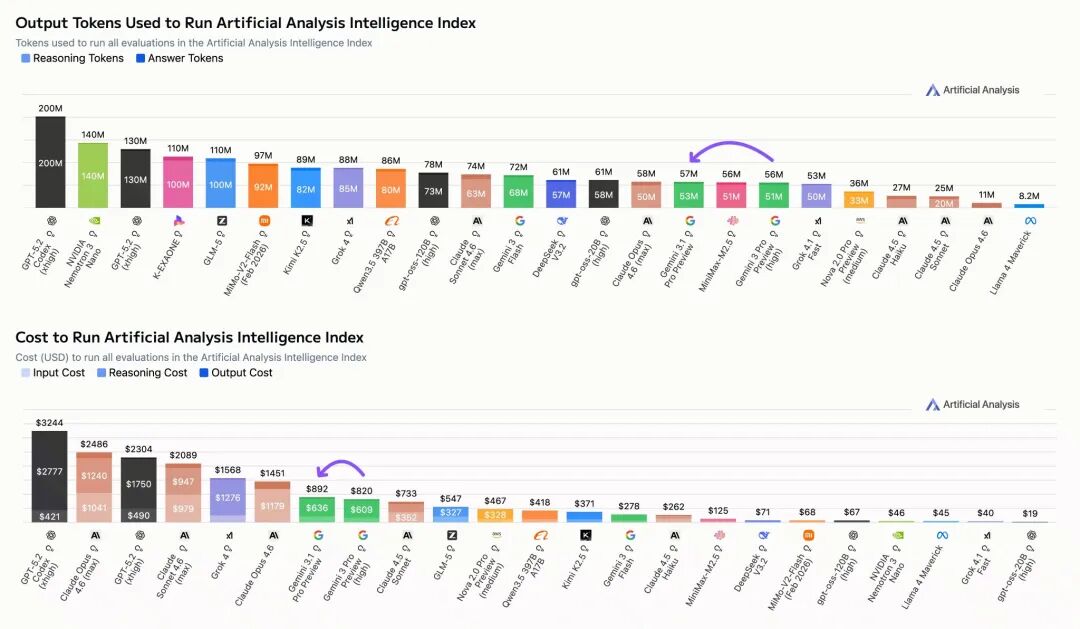
更令人印象深刻的是,模型在性能大幅提升的同时,保持了极高的令牌效率。运行整套智能指数测试仅比前代多消耗100万个令牌(从5600万增至5700万),成本仅增加72美元。
其定价策略维持不变:每百万输入令牌2美元,输出令牌12美元。模型支持100万令牌上下文与64k输出,知识截止时间为2025年1月。
超越基准:实际应用案例展示
基准测试分数只是理论表现,谷歌通过一系列实际案例展示了3.1 Pro的落地能力。
实时国际空间站追踪仪表盘
模型需要同时处理多个逻辑流:从公共API获取实时遥测数据、构建响应式用户界面、并应用物理原理来渲染精确的昼夜循环视觉效果。
代码动画生成
模型能够直接从文本提示生成网站就绪的动画SVG。由于是纯代码(矢量图形)而非像素图像,它在任何缩放比例下都能保持绝对清晰,且文件体积比传统视频小得多。

有用户使用相同的提示词“Create a svg in html of a red Ferrari supercar”测试了两个主流模型。左侧为Gemini 3.1 Pro生成的结果,线条流畅,设计更接近现代超跑;右侧来自Claude Opus 4.6,风格更显圆润卡通。据谷歌工程师透露,模型的SVG生成能力经过了专门的后训练优化。
交互式3D模拟
模型构建了一个模拟椋鸟群(murmuration)飞行的3D模拟。它需要理解鸟群飞行的物理原理,让模拟环境能够对手部追踪做出实时反应,并同步生成随鸟群运动而动态变化的配乐。
创意编码
基于经典小说《呼啸山庄》,模型构建了一个个人作品集网站。它不仅仅是总结文本,而是通过推理小说的氛围与基调来设计现代化的UI,并生成能够捕捉角色精髓的交互式代码。
技术社区反应
技术社区对这些数据印象深刻。有评论指出,82%的工具使用能力提升和2.5倍的抽象推理改进,这并非一次渐进式的版本迭代,而更像是根本性的能力解锁。甚至有人认为,如此巨大的提升幅度暗示前代模型可能存在某些基础性的设计局限。
从开发者社区的反馈来看,有人注意到谷歌在不到一年的时间里,从追赶者转变为在16个主要基准测试中领先13个的领跑者。但更关键的问题是:这种基准测试的优势,能否稳定地转化为实际生产应用中的优越表现?
价格策略同样引发了广泛讨论。不少用户认为谷歌的定价具有颠覆性,让竞争对手的高价策略在AI服务日益商品化的背景下显得有些不合时宜。
Gemini 3.1 Pro已于发布当日开始逐步推出,开发者可以通过Google AI Studio、Antigravity、Gemini CLI以及Android Studio的预览版进行访问。消费者版本则在Gemini应用和NotebookLM中提供,但更高的使用配额仅限于Google AI Pro和Ultra订阅用户。
有业内人士评论,这次发布标志着AI竞赛的重点正在从单纯的参数规模竞赛,转向对实际复杂任务推理能力的深耕。当模型能够理解系统内在逻辑,而不仅仅是生成“看似合理”的回答时,真正的实用价值才开始显现。对于持续关注大模型进展的技术爱好者而言,可以前往云栈社区的对应板块,获取更多深度分析和实践讨论。
 发表于 2026-2-21 03:35:48
|
查看: 188|
回复: 0
发表于 2026-2-21 03:35:48
|
查看: 188|
回复: 0
