在微服务架构中,负载均衡是保障系统高可用的基石。作为新一代负载均衡器,SpringCloud LoadBalancer内置了多种开箱即用的负载规则。不过,许多开发者可能只是停留在简单的配置和使用层面,对其背后的运作机制和源码实现并不完全清楚。本文将带你深入SpringCloud LoadBalancer的源码世界,拆解其核心负载规则,并结合实例教你如何扩展自定义规则。
一、SpringCloud LoadBalancer核心组件结构
SpringCloud LoadBalancer的运作核心由LoadBalancerClient、LoadBalancer和IRule三个核心接口构成。LoadBalancerClient作为对外暴露的客户端接口,负责协调负载均衡的整体流程;LoadBalancer则维护着服务实例的列表与状态信息;而IRule才是真正的“大脑”,它定义了从服务实例列表中挑选最佳节点的具体策略。
// LoadBalancerClient核心方法
public interface LoadBalancerClient {
<T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException;
<T> T execute(String serviceId, ServiceInstance serviceInstance, LoadBalancerRequest<T> request) throws IOException;
URI reconstructURI(ServiceInstance instance, URI original);
ServiceInstance choose(String serviceId);
}
其中,choose方法是整个负载均衡流程的入口。它会调用LoadBalancer获取可用的服务实例列表,然后将选择权委托给具体的IRule实现去执行负载规则。
二、RoundRobinRule轮询规则源码解析
轮询规则是最常用的负载策略之一,它按照顺序、均匀地选择服务实例。其核心实现位于RoundRobinRule类中,让我们来看看它的源码。
public class RoundRobinRule extends AbstractLoadBalancerRule {
private AtomicInteger nextServerCyclicCounter;
private static final boolean AVAILABLE_ONLY_SERVERS = true;
private static final boolean ALL_SERVERS = false;
public RoundRobinRule() {
nextServerCyclicCounter = new AtomicInteger(0);
}
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
log.warn("no load balancer");
return null;
}
Server server = null;
int count = 0;
while (server == null && count++ < 10) {
List<Server> reachableServers = lb.getReachableServers();
List<Server> allServers = lb.getAllServers();
int upCount = reachableServers.size();
int serverCount = allServers.size();
if ((upCount == 0) || (serverCount == 0)) {
log.warn("No up servers available from load balancer: " + lb);
return null;
}
int nextServerIndex = incrementAndGetModulo(serverCount);
server = allServers.get(nextServerIndex);
if (server == null) {
Thread.yield();
continue;
}
if (server.isAlive() && (server.isReadyToServe())) {
return (server);
}
server = null;
}
if (count >= 10) {
log.warn("No available alive servers after 10 tries from load balancer: " + lb);
}
return server;
}
private int incrementAndGetModulo(int modulo) {
for (;;) {
int current = nextServerCyclicCounter.get();
int next = (current + 1) % modulo;
if (nextServerCyclicCounter.compareAndSet(current, next))
return next;
}
}
}
关键实现逻辑解读:
- 线程安全的计数器:使用
AtomicInteger类型的nextServerCyclicCounter来记录下一个应选择的服务器索引,确保了在多线程并发场景下的原子性和线程安全。
- 循环递增与取模:
incrementAndGetModulo方法通过CAS(比较并交换)操作实现计数器的原子递增,并利用取模运算保证索引永远不会超出服务器列表的范围,形成循环。
- 健康状态检查:在选择到一个服务器实例后,代码会检查其
isAlive()和isReadyToServe()状态,确保只返回可用的实例。
- 内置重试机制:设计了一个最多10次的循环重试机制。如果选中的服务器不可用,会继续选择下一个,从而避免因单个节点瞬时故障导致请求失败。
三、RandomRule随机规则源码解析
随机规则从服务实例列表中随机挑选一个节点,适用于对请求分布均匀性要求不高、追求实现简单快速的场景。
public class RandomRule extends AbstractLoadBalancerRule {
Random rand;
public RandomRule() {
rand = new Random();
}
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
}
Server server = null;
while (server == null) {
if (Thread.interrupted()) {
return null;
}
List<Server> upList = lb.getReachableServers();
List<Server> allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
int index = rand.nextInt(serverCount);
server = allList.get(index);
if (server == null) {
Thread.yield();
continue;
}
if (server.isAlive()) {
return (server);
}
server = null;
Thread.yield();
}
return server;
}
}
关键实现逻辑解读:
- 随机数生成器:内部持有一个
Random实例,通过rand.nextInt(serverCount)生成一个随机的列表索引。
- 可用性检查:同样,在选择到实例后会验证其
isAlive()状态,保证返回的实例是可用的。
- 自旋重试逻辑:如果随机选到的实例为空或不可用,会通过
while循环和Thread.yield()进行自旋,直到选中一个可用的实例或线程被中断。
四、负载规则执行流程UML分析
为了更好地理解上述规则在整体流程中的位置,我们可以通过下面这张时序图来梳理整个调用链路:
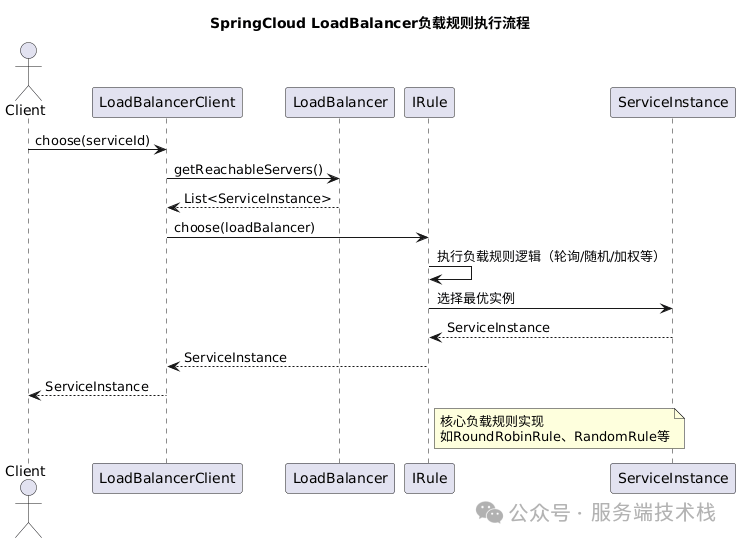
从图中可以清晰地看到负载规则执行的五个关键步骤:
- 客户端通过
LoadBalancerClient.choose(serviceId)方法发起请求。
LoadBalancerClient从关联的LoadBalancer中获取可访问的服务实例列表(getReachableServers)。- 将选择逻辑委托给具体的
IRule实现(如RoundRobinRule)。
IRule根据自身算法(轮询、随机等)从列表中选出最优的服务实例(ServiceInstance)。- 最终将这个选中的实例返回给客户端,用于后续的实际请求。
五、自定义负载规则实战
内置规则虽好,但有时无法满足特定的业务场景。这时,自定义负载规则就派上了用场。例如,我们需要一个根据服务器权重进行选择的加权随机规则。
public class WeightedRandomRule extends AbstractLoadBalancerRule {
@Override
public Server choose(Object key) {
ILoadBalancer lb = getLoadBalancer();
if (lb == null) {
return null;
}
List<Server> allServers = lb.getAllServers();
int totalWeight = allServers.stream()
.mapToInt(server -> getServerWeight(server))
.sum();
int randomWeight = new Random().nextInt(totalWeight);
int currentWeight = 0;
for (Server server : allServers) {
currentWeight += getServerWeight(server);
if (currentWeight > randomWeight) {
return server;
}
}
return allServers.get(new Random().nextInt(allServers.size()));
}
private int getServerWeight(Server server) {
// 从服务元数据中获取权重,默认1
Map<String, String> metadata = ((DiscoveryEnabledServer) server).getInstanceInfo().getMetadata();
return Integer.parseInt(metadata.getOrDefault("weight", "1"));
}
}
实现思路剖析:
- 权重配置:权重信息可以配置在服务实例的元数据(Metadata)中,例如在Nacos或Eureka的注册信息里添加一个
weight字段。
- 加权随机算法:
- 首先计算所有实例的权重总和 (
totalWeight)。
- 在
[0, totalWeight)区间内生成一个随机数 (randomWeight)。
- 遍历服务实例列表,并累加它们的权重 (
currentWeight)。当累加值第一次超过randomWeight时,当前遍历到的实例就是被选中的那一个。权重越大的实例,其权重区间所占范围越广,被选中的概率也就越高。
- 降级策略:作为一个健壮的实现,我们在最后添加了一个降级逻辑:如果遍历完所有实例仍未命中(理论上概率极低),则退化到普通的随机选择,保证总有返回值。
六、负载规则的选择与优化建议
了解原理后,如何在实际项目中做选择呢?
- 轮询规则 (
RoundRobinRule):适用于集群中各个服务实例性能和配置相近的场景,能最简单地保证请求量的绝对均匀分布。
- 随机规则 (
RandomRule):实现简单,开销小,在实例性能差异不大且对分布均匀性要求不苛刻的场景下是一个轻量级的选择。
- 加权规则:当服务实例的硬件配置、处理能力存在显著差异时,加权策略(如上面的加权随机)能更合理地分配负载,让性能强的机器承担更多请求。
- 自定义规则:面对复杂的业务场景,自定义规则提供了最大的灵活性。例如,你可以实现基于实时响应时间动态调整权重的规则,或者根据请求的特定参数(如用户ID)进行哈希选择,实现会话粘滞。
总结
通过对RoundRobinRule和RandomRule的源码解读,我们不仅理解了其算法实现,更看到了SpringCloud LoadBalancer在健壮性上的考量,如健康检查、线程安全、重试机制等。而自定义WeightedRandomRule的实践,则展示了如何基于标准接口扩展出适应业务需求的能力。
理解这些底层逻辑,能帮助我们在实际开发中更好地排查问题、进行调优,而不仅仅是做一个“配置工程师”。希望本文的源码级剖析能为你带来启发。如果你在微服务负载均衡实践中有其他独特的见解或遇到的挑战,欢迎在云栈社区与大家一起交流探讨。
 发表于 2026-2-22 04:09:03
|
查看: 190|
回复: 0
发表于 2026-2-22 04:09:03
|
查看: 190|
回复: 0
