当我们正在使用一个智能聊天机器人,输入了一个简短的问题,满怀期待地等待回复。然而,由于服务器正在处理一个长篇文档总结任务,请求被堵在后面,迟迟得不到响应,眼睁睁看着“正在输入”的提示转个不停。这种体验像极了早高峰堵车——一辆大货车慢悠悠地走在前面,后面的小车只能干着急。
在大型语言模型(LLM)的服务系统中,这种现象被称为头阻塞(Head-of-Line blocking,HoL)。它发生在模型推理的预填充阶段(prefill phase),即模型处理用户输入提示(prompt)的阶段。
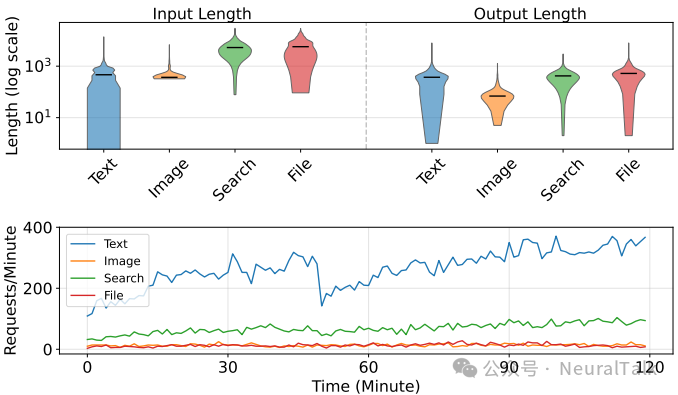
图 1 | QwenTrace 中不同任务类型的请求长度分布与到达模式。本文探索了为具有多样化 SLO 保障的请求进行调度的可行性。该图直观呈现了聊天机器人、图像理解、网页搜索和摘要生成四类任务的请求特征差异,短输入高优先级的聊天任务与长输入宽松 SLO 的摘要任务并存,这种异质性加剧了预填充阶段的队首阻塞问题,凸显了灵活调度机制的必要性。
长提示的预填充计算量大,会长时间占用 GPU 资源,导致后续到达的短请求被阻塞,进而违反首 Token 时间(Time-to-First-Token,TTFT) 的服务水平目标(SLO)。

现有的一些解决方案,比如分块预填充(chunked prefill),将长提示切成小块执行,允许在块间插入其他请求。但这引入了一个根本性的权衡:
- 块越小,响应越快,但计算效率越低(因为内核启动开销和冗余内存访问增加);
- 块越大,吞吐量越高,但阻塞延迟也越长。
这就好比在堵车时,我们不可能把大货车拆成小块通过,但完全不让它走也不行。
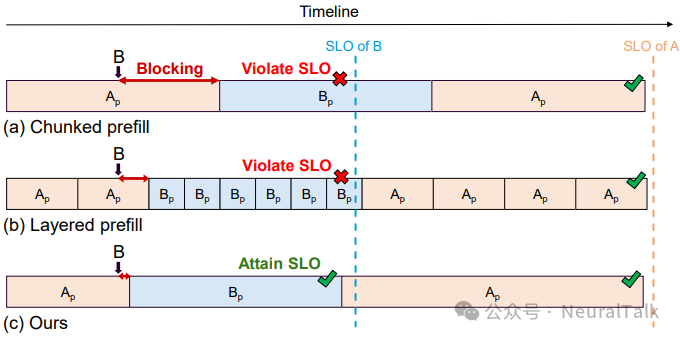
图 2 | 不同预填充粒度对首 token 延迟(TTFT)服务等级目标(SLO)的满足情况。(a) 分块预填充;(b) 分层预填充;(c) 本文方法。对比可见,分块和分层预填充均存在 SLO 违约问题,前者因块边界限制导致高优先级请求阻塞,后者受层执行时长约束,而本文方法通过算子级抢占实现精准响应,成功让高优先级请求 B 满足 SLO,破解了粒度与效率的矛盾。
那么,有没有一种方法既能保持高吞吐,又能实现细粒度抢占,让高优先级请求“插队”而不影响整体效率?
这正是本文要介绍的 FlowPrefill 系统所解决的核心问题。它通过将抢占粒度与调度频率解耦,实现了近乎无阻塞的预填充调度。
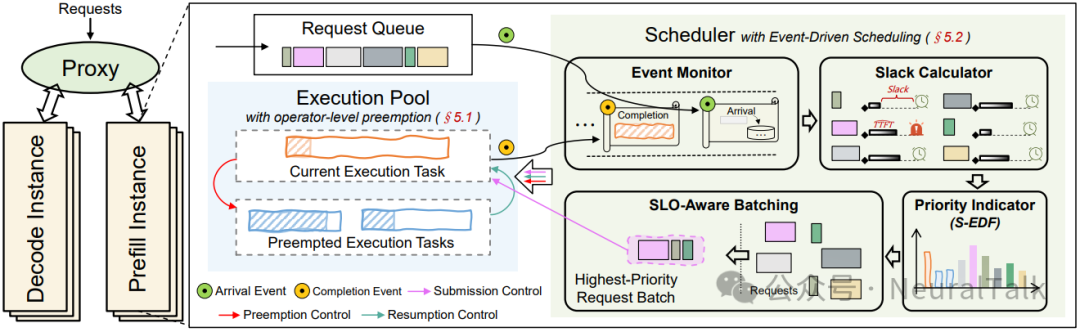
图 3 | FlowPrefill 的整体架构。架构核心包含代理、预填充实例和解码实例,预填充实例内置请求队列、执行池和调度器三大模块,通过事件驱动调度与算子级抢占的协同,实现高优先级请求的及时响应,同时借助 S-EDF 策略和 SLO 感知批处理最大化系统有效吞吐量。
一、背景:LLM 推理的两阶段与 PD 分离
现代 LLM 大多基于 Transformer 架构,推理过程分为两个阶段:
- 预填充阶段:输入整个提示序列(例如用户的问题),并行计算所有 token 的注意力,生成第一个输出 token,并初始化键值缓存(KV cache)。这个阶段主要执行矩阵-矩阵乘法(GEMM),计算密集,属于计算密集型。
- 解码阶段:自回归地逐个生成后续 token。每步只输入一个 token,执行矩阵-向量乘法(GEMV),需要反复从高带宽内存(HBM)加载模型权重,属于内存密集型。
这两个阶段对资源的需求截然不同。预填充需要强大的算力,解码则受限于内存带宽。如果将它们混合在同一 GPU 上执行,预填充的突发计算会干扰解码的延迟敏感任务。
1.2 预填充-解码分离(PD Disaggregation)
为了解决上述干扰,现代系统采用 PD 分离架构,将预填充和解码部署在不同的 GPU 实例上。
这样,解码实例可以稳定地提供低延迟,预填充实例则专注于处理输入。然而,PD 分离并没有消除预填充阶段内部的头阻塞问题——事实上,它把竞争全部集中到了预填充实例上。一个长上下文请求可能独占 GPU 数百毫秒,后续的高优先级短请求只能排队等待,导致 TTFT SLO 违例。
二、动机:现有方法的局限
2.1 抢占粒度 vs. 效率的权衡
为了缓解头阻塞,现有系统通常采用固定粒度的抢占策略:
- 分块预填充:将长输入切分成固定大小的块(如 2K tokens),每块执行完后检查是否可以调度新请求。
- 分层预填充:利用 Transformer 层的自然边界作为抢占点,每层执行完后检查。
然而,作者通过实验揭示了这些方法的内在矛盾。图 4 展示了在 Llama3-8B 模型上处理 32K token 输入时,不同块大小对吞吐量和延迟的影响。
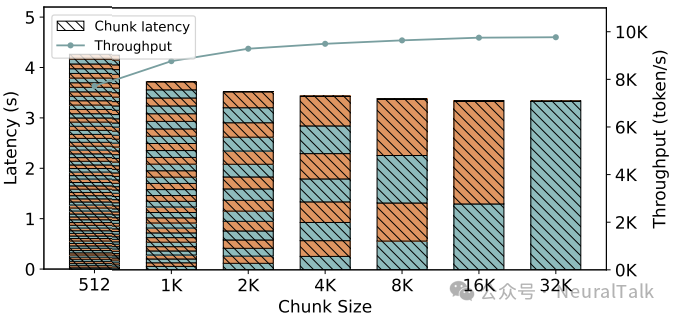
图 4 | 服务 Llama3-8B 模型时,32K token 输入在不同分块大小下的分块预填充吞吐量与延迟。每个条形内的交替颜色代表单个分块。实验结果清晰展现了分块大小的权衡困境:小块虽提升响应性但因内核启动开销和 KV 缓存冗余访问导致吞吐量骤降,大块虽恢复吞吐量却加剧阻塞,这为本文提出算子级抢占提供了现实依据。
观察可知,块越小,延迟越低,但吞吐量急剧下降。这是因为小块导致内核启动次数增加、KV 缓存重复加载,设备利用率下降。而块越大,吞吐越高,但单个块的执行时间过长,阻塞无法避免。这就是所谓的“吞吐-延迟权衡”。
更进一步,分层预填充虽然避免了内存开销,但将调度频率与层数耦合。
- 如果每层都做调度检查,开销巨大;
- 而如果间隔多层才检查,又可能错过及时的抢占机会。图 5 显示,分层抢占的平均阻塞时间可达十几毫秒,而算子级抢占能将其降至 4.5ms 以下。
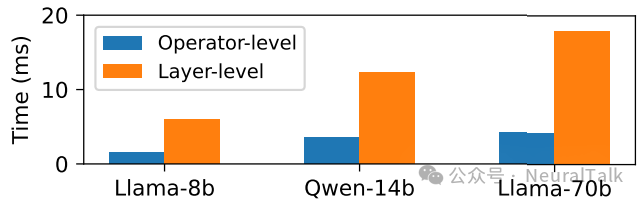
图 5 | 算子级与分层级抢占边界下的平均抢占阻塞时间。不同抢占粒度通过在不同执行边界设置抢占检查实现。数据显示,算子级抢占将平均阻塞时间降低 3.5-4.2 倍,所有模型下均控制在 4.5 毫秒内,这种近无阻塞的性能表现,使得高优先级请求能快速获得资源,大幅缓解了预填充阶段的队首阻塞问题。
Takeaway 1: 固定粒度的执行单元在效率和响应性之间无法两全,需要一种自适应的、不依赖固定切分的抢占机制。
2.2 批处理中的请求不对称性
除了单请求执行,批处理(batching)也影响着不同长度请求的表现。图 6 展示了在预填充阶段,不同输入长度下吞吐量和 TTFT 随批大小的变化。
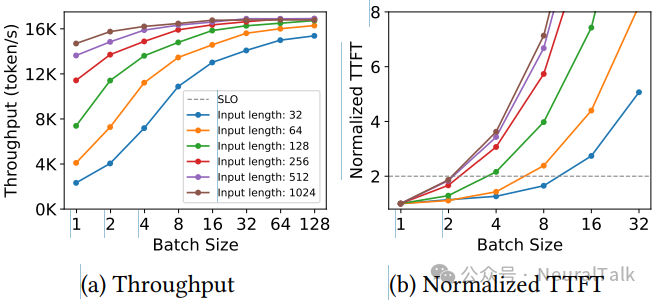
图 6 | 服务 Llama3-8B 模型时,不同输入长度在预填充阶段的吞吐量与归一化首 token 延迟(TTFT)。(a) 吞吐量;(b) 归一化 TTFT。
上图揭示了批处理对不同长度请求的异质影响:
- 对于短请求(32-256 token),单个请求无法充分利用 GPU 并行性,批处理能显著提高吞吐,且延迟增长平缓。
- 对于长请求(如 2K 以上),单个请求已接近饱和 GPU,批处理带来的吞吐增益微乎其微,但延迟却线性增加,极易导致 SLO 违例。
Takeaway 2: 短请求需要批处理来提高效率,而长请求应避免过度批处理,以免无谓地增加延迟。
三、FlowPrefill 核心设计
FlowPrefill 是一个以有效吞吐(goodput)为优化目标的 LLM 服务系统,它通过两个关键创新来解决上述问题:算子级抢占(Operator-Level Preemption) 和事件驱动调度(Event-Driven Scheduling)。图 3 展示了系统的整体架构。
系统主要由三部分组成:
- Proxy:接收前端请求,以轮询方式分发到预填充实例。
- Prefill Instance:核心优化模块,包括请求队列、执行池和调度器。
- Decode Instance:沿用默认的解码逻辑,采用 FCFS 调度。
下面我们深入两个创新点。
3.1 算子级抢占
3.1.1 原理
算子级抢占的核心思想是:在模型执行过程中,将抢占检查点设置在算子(operator)的边界,而不是在固定大小的块或层边界。
算子是模型的最小执行单元,例如 qkv_proj、attn、o_proj、gate_up_proj、down_proj 等。每个算子执行完成后,插入一个轻量级的抢占检查,判断是否有更高优先级的请求到达。如果有,则暂停当前任务,保存状态,让出执行权。
图 7 对比了不同层次的抢占粒度。
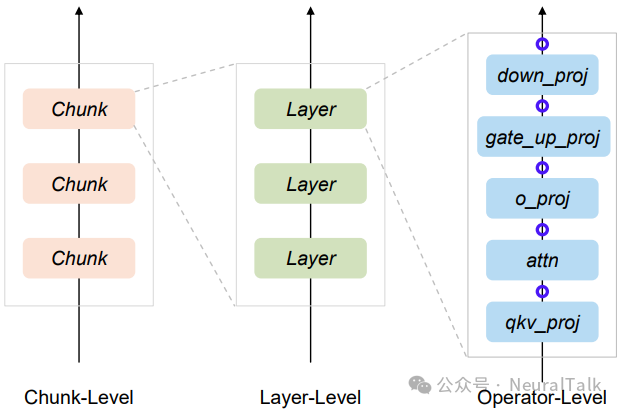
图 7 | 执行逻辑具有层级性,抢占检查可置于不同执行边界。分块或分层级别的抢占检查导致较粗的抢占粒度,而 FlowPrefill 将其置于核心算子边界以实现最细粒度抢占(蓝色圆圈表示抢占检查点)。该图清晰展示了 LLM 执行的三级层级结构,算子级作为最细执行单元,其边界抢占无需拆分请求即可实现高效中断,既避免了分块的冗余开销,又突破了分层的粒度限制,为低延迟抢占提供了硬件友好的实现路径。
这种方法的好处是:
- 细粒度:算子执行时间通常很短(例如几毫秒),因此抢占延迟被限定在单个算子时间内。
- 无额外切分开销:不需要将请求拆分成小块,避免了内存重复加载和内核启动开销。
- 通用性:可适用于各种模型,只需在核心算子间插入检查点。
3.1.2 协同抢占过程
FlowPrefill 采用协同抢占(cooperative preemption),而不是强制中断。这是因为强制中断正在执行的 GPU 内核可能导致资源泄漏或死锁。协同抢占的过程如图 8 所示。
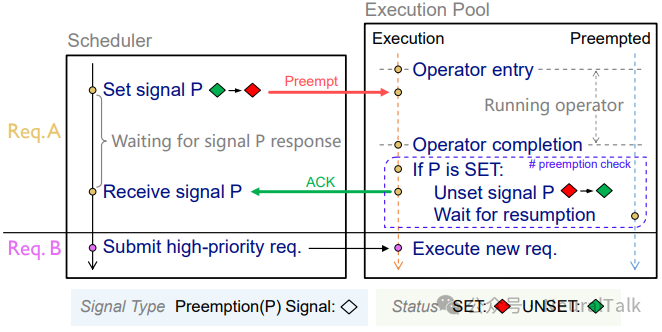
图 8 | 协作式抢占流程。该流程体现了调度器与执行池的协同机制,调度器通过设置抢占信号触发中断,执行池在算子执行完毕后检查信号并安全挂起当前任务,整个过程仅涉及简单并发原语操作,开销可忽略,确保了抢占的高效性与安全性。
协作式抢占流程如下:
- 高优先级请求到达:调度器设置抢占信号,并等待确认(ACK)。
- 算子完成检查:执行池在算子边界检查信号,若发现被置位,则清除信号,暂停当前任务,并将其移入“被抢占队列”,然后发送 ACK 给调度器。
- 调度新任务:调度器收到 ACK 后,提交高优先级请求执行。
- 恢复被抢占任务:当高优先级任务完成且无更高优先级请求时,调度器发送 resume 命令,恢复被暂停的任务。
对于使用张量并行(tensor parallelism)的大型模型,FlowPrefill 通过同步迭代计数器确保所有并行进程在相同算子边界暂停,避免通信死锁。
3.2 事件驱动调度
算子级抢占提供了机制,但还需要一个智能的调度策略来决定何时抢占、选择哪个请求。FlowPrefill 采用事件驱动调度,即仅在请求到达或完成时触发调度决策,避免了周期性检查的开销。
3.2.1 优先级定义:Slack-aware EDF(S-EDF)
每个请求被赋予一个优先级,公式如下:
priority(r) = sgn(slack(r)) * (1 / (deadline(r) - arrival(r)))
其中:
slack(r) = deadline(r) - current_time - predicted_TTFT(r),表示剩余可用时间(若为正,则有可能按时完成;若为负,则已注定超时)。sgn() 是符号函数:正 slack 返回 1,负 slack 返回 -1。deadline(r) 是请求到达时间加上其 TTFT SLO。
这个公式的含义是:优先级最高的请求是那些 deadline 最早且 slack 非负的请求。负 slack 的请求被赋予负优先级,即实际上被降级,避免它们浪费资源。
TTFT 预测通过一个离线拟合的多项式模型实现,输入为 token 数,输出预测时间。由于 PD 分离下预填充与解码互不干扰,预填充时间与 token 数近似线性,因此多项式拟合效果良好,见图 9。
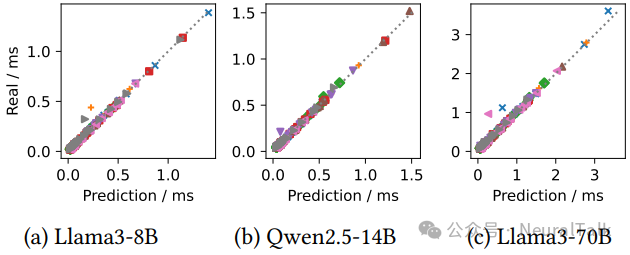
图 9 | 三种模型在 QwenTrace 的一个轨迹片段上服务时,首 token 延迟(TTFT)的实际值与预测值对比(固定请求速率)。(a) Llama3-8B;(b) Qwen2.5-14B;(c) Llama3-70B。预测值与实际值高度吻合,少量异常值不影响整体效果,这得益于 PD 解耦架构下预填充计算与令牌数的近似线性关系,使得基于离线拟合的多项式模型能精准预测 TTFT,为松弛度计算和 SLO 感知批处理提供了可靠支撑。
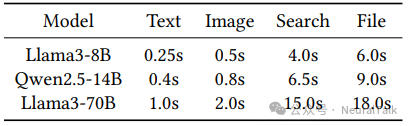
表 1 | 本文中使用的关键符号及其描述。
3.2.2 SLO-aware batching
为了在满足 SLO 的前提下最大化吞吐,FlowPrefill 采用 SLO 感知的批处理算法(Algorithm 1)。其核心思想是:以当前最高优先级请求 H 为基础,尝试加入其他候选请求,但必须保证加入后整个批次的预测延迟不超过 H 的剩余时间 T_remain,且总 token 数不超过预算 G。
算法步骤:
- 初始化批次 B = {H},剩余时间 T_remain = H.deadline – current_time,当前 token 数 N = H.num_tokens。
- 遍历候选请求 C(按优先级排序):
- 计算加入 r 后的总 token 数 n = N + r.num_tokens。
- 预测批次延迟 L = predict_latency(n)。
- 如果 T_remain > L 且 n < G,则将 r 加入批次,更新 N = n。
- 返回最终批次。
该算法确保批次不会导致 H 超时,同时通过预算 G 限制批大小,避免长请求过度批处理。

算法 1 | SLO 感知批处理算法。
3.2.3 完整调度流程
算法 2 给出了事件驱动调度的完整流程。

算法 2 | 事件驱动调度算法。
结合上面的算法描述,这里给出关键步骤:
- 等待事件发生(请求到达或完成)。
- 将所有请求按优先级排序,选出最高优先级请求 H。
- 如果 H 在等待队列中,则尝试 SLO-aware batching。
- 检查当前运行的任务 E 是否应被抢占(即 H 的优先级高于 E),如果是,则抢占 E,然后提交或恢复 H。
图 10 用一个简单示例展示了整个流程。
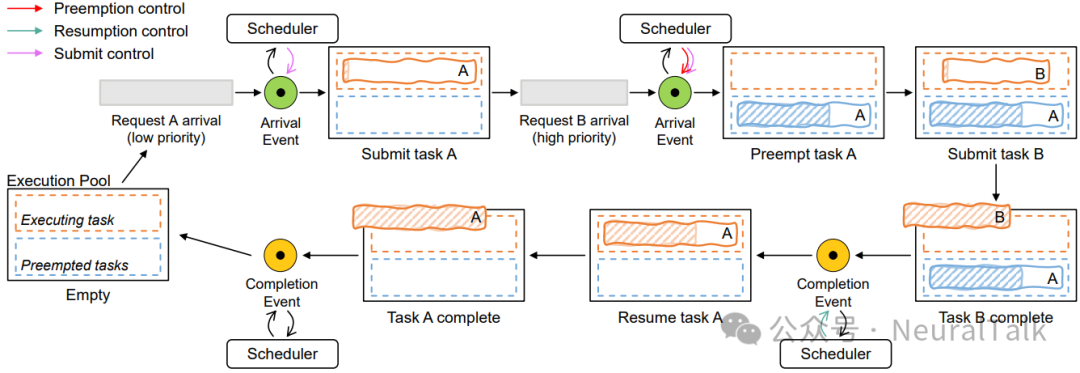
图 10 | FlowPrefill 中处理两个不同优先级请求的示例。示例完整呈现了事件驱动调度的核心逻辑,低优先级请求 A 执行中被高优先级请求 B 的到达事件触发抢占,B 完成后通过完成事件唤醒 A 继续执行,整个过程无多余调度检查,既保证了高优先级请求的时效性,又避免了资源浪费。
上图展示了两个请求的调度示例:
- 请求 A(低优先级)先到达并开始执行;
- 请求 B(高优先级)到达后触发抢占,A 被暂停,B 执行;
- B 完成后,A 恢复执行。
四、评估
FlowPrefill 在真实生产轨迹 QwenTrace 上进行了全面评估,与 DistServe 和 vLLM 等基线对比。我们摘取关键结果解读。
4.1 实验设置
- 硬件:8×NVIDIA A800 80GB GPU,NVLink 互联。
- 模型:Llama3-8B、Qwen2.5-14B、Llama3-70B(稠密模型),以及 Qwen3-30B-A3B(MoE 模型)。
- 工作负载:QwenTrace 包含四种任务类型(聊天、图像理解、网页搜索、文件总结),其提示长度分布见表 2。
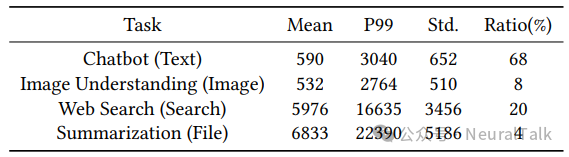
表 2 | 实验中使用的任务类型及其 SLO 配置。
每个任务被分配不同的 TTFT SLO,聊天最严格(0.25s),文件最宽松(6.0s)。
4.2 端到端性能
图 11 展示了在不同请求率和 SLO 要求下,各系统的 SLO 达标率。
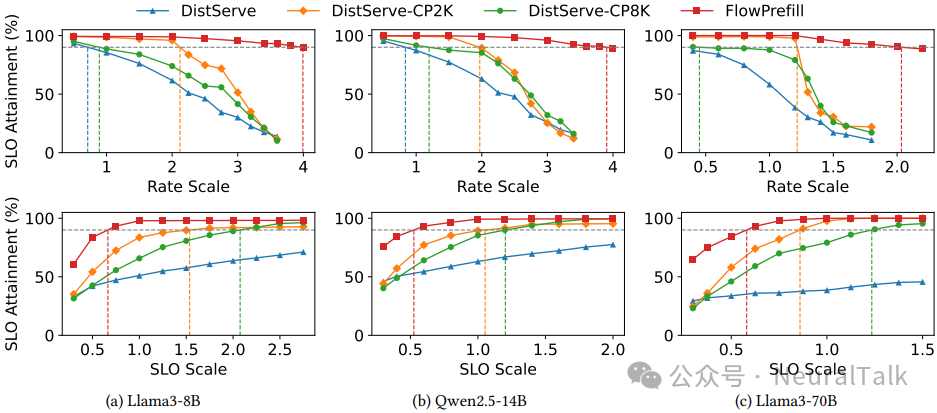
图 11 | 三种模型在 QwenTrace 上不同请求速率和 SLO 要求下的端到端性能。(a) Llama3-8B;(b) Qwen2.5-14B;(c) Llama3-70B。结果显示,FlowPrefill 在各模型上均表现优异,在相同 SLO 达标率下,其支持的请求速率较 DistServe 提升 4.7-5.6 倍,较分块预填充变体提升 2.0-4.5 倍,且能支持 1.5-3.1 倍更严格的 SLO,验证了其在不同模型规模下的泛化性与高效性。
- 与 DistServe 对比:FlowPrefill 的最大有效吞吐比 DistServe(默认 FCFS)高 4.7 倍~ 5.6 倍;比 DistServe-CP2K(块大小 2K)高 2.0 倍;比 DistServe-CP8K 高 4.5 倍。这是因为 FlowPrefill 能及时抢占低优先级请求,让高优先级短请求几乎无阻塞地执行。
- SLO 收紧容忍度:FlowPrefill 能支持比 DistServe-CP2K 更紧 1.5 倍~ 2.3 倍的 SLO,比 CP8K 更紧 2.1 倍~ 3.1 倍。这得益于 S-EDF 和 SLO-aware batching,在负载高时主动放弃注定超时的请求,避免系统崩溃。
4.3 消融实验
4.3.1 调度策略
图 12 比较了 S-EDF 与普通 EDF、deadline-aware EDF(D-EDF)。S-EDF 显著优于二者,因为它利用 slack 提前排除不可行的请求,防止资源浪费。
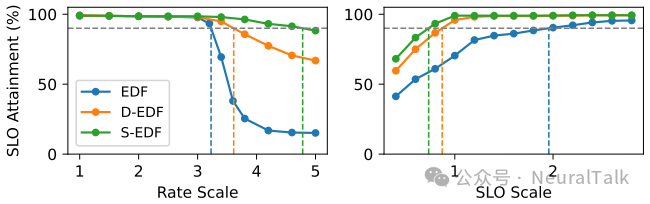
图 12 | 三种调度策略的性能对比。D-EDF:截止时间感知 EDF;S-EDF:松弛感知 EDF;EDF:原生 EDF。对比表明,S-EDF 策略通过引入松弛度估计,能主动降级无法满足 SLO 的请求,避免队列拥堵导致的整体性能崩塌,在最大有效吞吐量和最小可支持 SLO 两方面均显著优于仅关注截止时间的 D-EDF 和原生 EDF,凸显了调度策略的合理性。
4.3.2 SLO-aware batching
图 13 展示了不同批处理 token 预算的影响。预算为 4K 时,SLO 达标率与吞吐达到较好平衡;无批处理时吞吐最低;预算过大(8K)虽吞吐略增但 SLO 达标率下降。
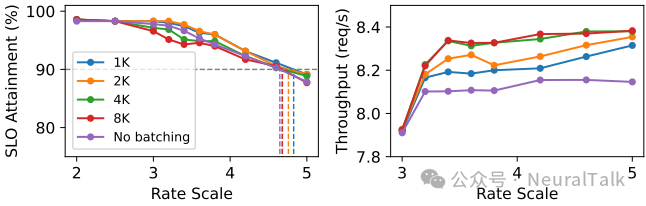
图 13 | 不同批处理令牌预算与无批处理情况下的性能对比。实验验证了 SLO 感知批处理的有效性,无批处理吞吐量最低,过大预算虽提升吞吐量但增加 SLO 违约风险,而中等预算(4K 左右)能在捕获短请求批处理收益的同时控制延迟,实现吞吐量与 SLO 达标率的平衡。
4.4 运行时分析
4.4.1 抢占阻塞时间
图 5 对比了算子级与层级的抢占阻塞时间。算子级平均阻塞时间仅 2.6ms(最大<4.5ms),层级则达 9.5ms 以上,前者降低 3.5 倍~ 4.2 倍。
4.4.2 TTFT 预测准确性
图 9 显示真实 TTFT 与预测值的散点图,大部分点靠近对角线,说明多项式预测模型足够准确。
4.5 扩展性评估
4.5.1 单 SLO 场景
在 ShareGPT 数据集上,所有请求共享相同 SLO(聊天)。图 14 显示 FlowPrefill 的吞吐与 DistServe-CP2K 相当,但 SLO 达标率更高,证明算子级抢占几乎没有额外开销。
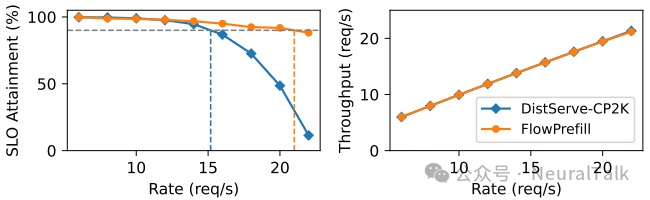
图 14 | 单一 SLO 工作负载下的性能对比。FlowPrefill 的吞吐量与基线相当,表明算子级抢占的开销可忽略不计,但在请求速率提升时能提供更优的 SLO 达标率。
4.5.2 结合分块预填充
对于极长输入(如>32K),单个算子也可能耗时较长。图 15 显示,将 FlowPrefill 与分块预填充结合(选择合适的块大小,如 8K)可进一步提升性能。
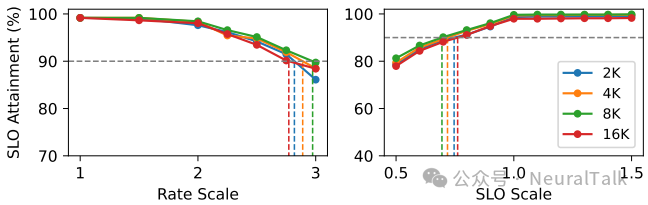
图 15 | FlowPrefill 结合分块预填充在不同分块大小下的性能。结果显示分块大小需合理配置,小块(2K)因频繁拆分引入额外开销,大块(16K)缺乏足够抢占粒度,中等分块能平衡算子执行时间与吞吐量,说明 FlowPrefill 可与分块预填充结合,进一步优化超长输入场景的性能。
4.5.3 PD-共存场景
FlowPrefill 也适用于预填充和解码共存于同一设备组的情况。图 16 显示,在 PD-共存下,FlowPrefill 不仅改善了 TTFT SLO,还因减少了预填充干扰而间接提升了 TBT(token 间时间)SLO。
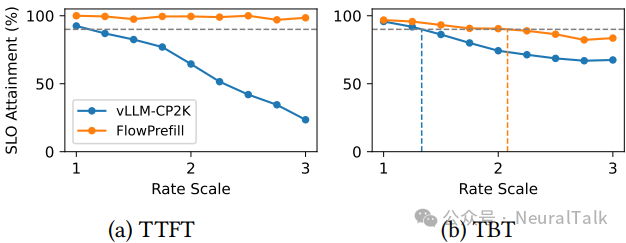
图 16 | PD 共置架构下不同请求速率的性能对比,报告首 token 延迟(TTFT)和令牌间延迟(TBT)的 SLO 达标率。(a) TTFT;(b) TBT。尽管 FlowPrefill 主打 PD 解耦架构,但在共置场景下仍表现出色,TTFT 达标率显著高于 vLLM-CP2K,且因自适应抢占缩短了预填充对解码的干扰时间,TBT 达标率提升 1.6 倍,验证了其跨部署范式的鲁棒性。
4.5.4 MoE 模型
在 Qwen3-30B-A3B(混合专家模型)上,FlowPrefill 同样有效如图 17,说明其算子级抢占可扩展到专家路由等新算子。
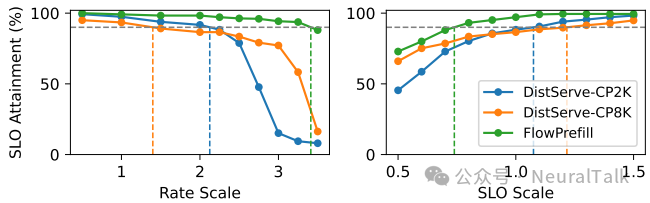
图 17 | 服务 Qwen3-30B-A3B 模型的性能对比。针对混合专家(MoE)模型,FlowPrefill 通过在新增算子边界设置抢占检查实现快速适配,其有效吞吐量较 DistServe-CP2K 提升 1.6 倍,支持的 SLO 严格度提升 2.4 倍,证明其设计对复杂模型架构具有良好的兼容性与扩展性。
五、相关工作
FlowPrefill 并非孤立存在,它建立在前人研究的基础上,并针对性地解决了它们的不足。我们将其与以下几类工作对比:
| 类别 |
相关研究/系统 |
核心特点与局限性 |
| 聚合式LLM服务系统 |
Orca、vLLM、SARATHI |
单GPU处理预填充+解码;vLLM优化KV缓存,SARATHI分块预填充交错解码;无法消除阶段干扰,异构SLO下服务质量难以保障 |
| 分离式LLM服务系统 |
DistServe、Splitwise、Mooncake |
PD分离架构,两阶段部署在不同实例;DistServe优化资源分配,Splitwise关注成本效率;预填充阶段用FCFS/固定分块,无法解决长请求阻塞问题 |
| LLM调度策略 |
多级队列、EDF、Medha、Prism |
基于请求特征优化,近似SJF或采用EDF;Medha、Prism结合分块预填充与EDF;抢占粒度固定,调度与执行粒度耦合,灵活性和效率不足 |
结论
FlowPrefill 通过算子级抢占和事件驱动调度,成功解耦了抢占粒度与调度频率,解决了 LLM 服务中预填充阶段的头阻塞问题。它能在保持高吞吐的同时,实现近乎无阻塞的响应,显著提升了有效吞吐(goodput)和对异构 SLO 的容忍度。
实验表明,FlowPrefill 相比现有系统,有效吞吐提升高达 5.6 倍,支持更紧的 SLO 达 3.1 倍。
这一设计为 LLM 服务提供了一种新的思路:不依赖固定切分,而是利用模型自身的算子边界,结合智能调度,实现高效、灵活的抢占。未来,随着模型规模不断增长和多模态模型的普及,类似 FlowPrefill 的细粒度、自适应调度技术将变得越发重要。
如果您对高性能计算与调度优化感兴趣,欢迎在云栈社区交流更多技术实践。
 发表于 2026-2-22 07:49:27
|
查看: 240|
回复: 0
发表于 2026-2-22 07:49:27
|
查看: 240|
回复: 0
