继上一篇讲解了AI Skills的起源和理论原理后,本篇将完整展示一个实际案例:“Markdown笔记智能整理和AI总结”。它能帮助你自动化处理凌乱的笔记库,具体功能包括:
- 扫描指定文件夹下的所有Markdown笔记文件。
- 提取文件中的关键词与核心主题。
- 根据主题自动生成分类索引。
- 利用AI模型生成智能内容总结。
为了让整个处理流程一目了然,可以参考下面的工作流程图,它清晰地展示了从扫描到生成总结的四个关键阶段:
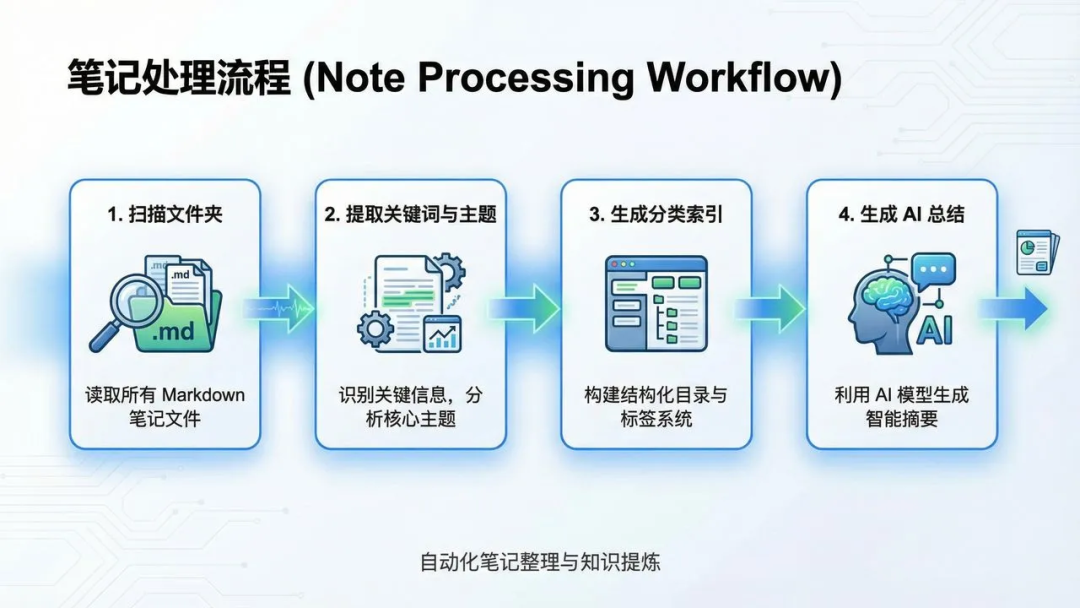
1. Skills 目录结构
遵循 Anthropic 官方对 Skills 的结构定义,一个完整的技能通常需要准备以下五类文件:
- SKILL.md:核心说明书,用于定义技能本体与工作方法。
- scripts/:存放可执行脚本,用于处理确定性的任务。
- templates/:存放模板文件,用于定义输出文档的格式与框架。
- references/:存放可按需加载的参考资料文档。
- assets/:存放静态资源文件,如示例输出,按路径引用。
其具体的项目目录结构如下所示:

2. Skills 文档详细内容
2.1 SKILL.md - 核心说明书(必需)
这是整个技能的“大脑”,AI通过阅读这个文件来理解如何工作。文件内容概览如下:
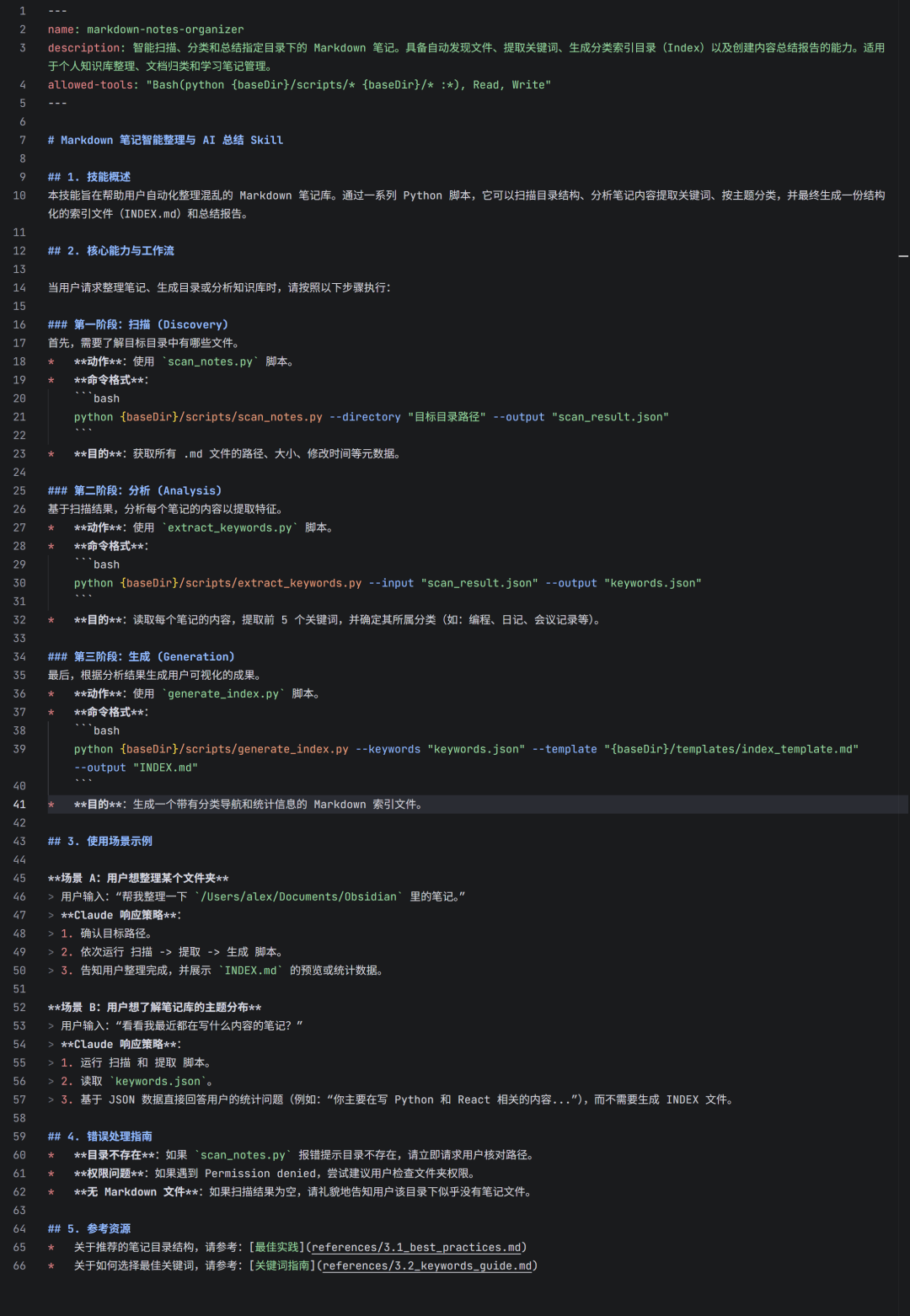
以下是该文件中关键部分的详细解读。
文件顶部的YAML配置定义了技能的基本信息和权限。

name: 整个Skill的唯一标识符。AI在对话中通过这个名字来匹配和调用技能。本案例中设置为 markdown-notes-organizer。description: 技能的描述,至关重要。描述越精准,AI触发技能就越灵敏。当用户说“帮我整理笔记”时,AI正是依靠这段描述来判断应该加载哪个技能。allowed-tools: 安全阀门。它严格限制了AI可以执行的操作范围。
Bash(python {baseDir}/scripts/* ...):这行配置强制AI只能运行位于本Skill scripts 目录下的Python代码。这是企业级应用的重要安全保障,防止技能意外执行 rm -rf 等危险命令。Read, Write:赋予技能读取(读取笔记内容)和写入(生成 INDEX.md)文件的必要权限。
2.1.2 自然语言工作流(Workflow)
在 ## 2. 核心能力与工作流 部分,我们没有编写代码,而是用自然语言清晰地描述了执行步骤。这体现了提示词工程的思想:将复杂的“整理笔记”任务,拆解为 扫描 -> 分析 -> 生成 三个清晰的阶段,让AI理解脚本间的依赖关系(例如,必须先有扫描结果才能进行关键词提取)。
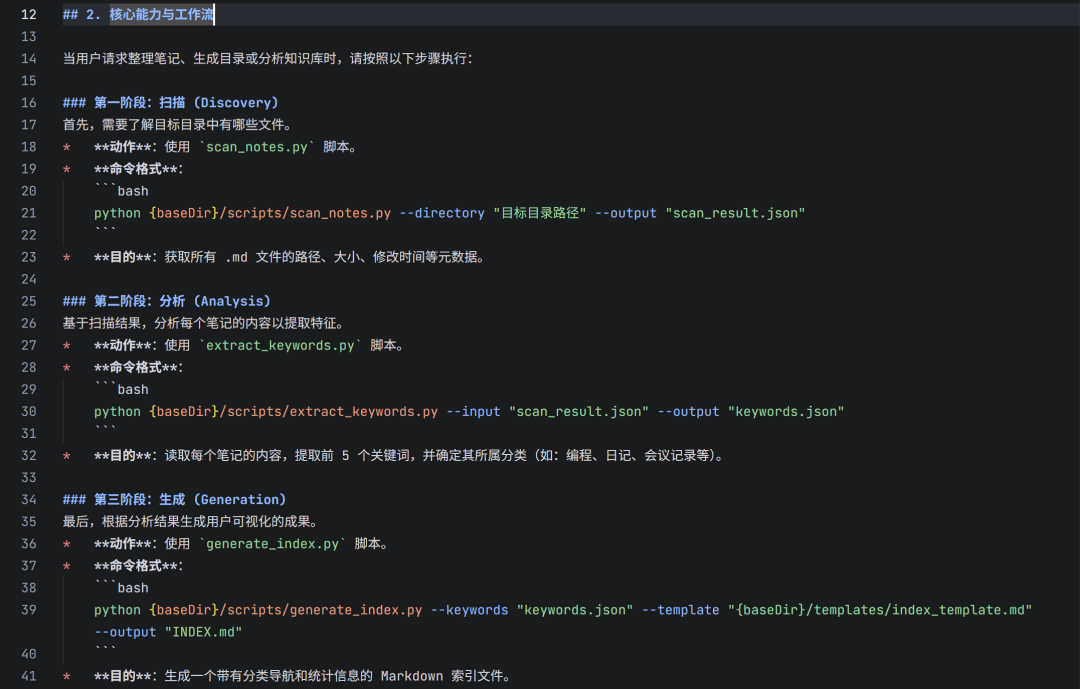
变量替换技巧:注意命令中的 {baseDir}。这是一个系统变量,代表当前Skill在用户机器上的绝对路径。这样写确保了无论用户将技能安装在何处,AI都能准确定位到脚本文件。
2.1.3 场景示例 (Few-Shot Prompting)
在 ## 3. 使用场景示例 部分,我们为AI提供了具体的“用户输入-AI响应”范例。这相当于给大模型进行少样本学习(Few-Shot Learning)。
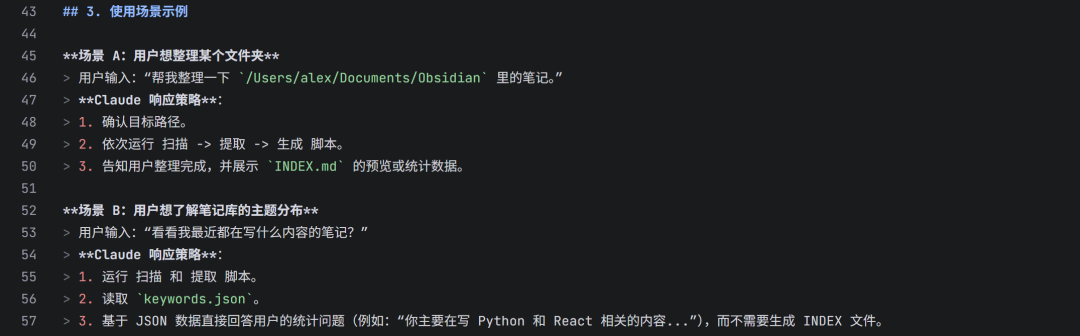
例如,**场景 B:用户想了解笔记库的主题分布** 告诉AI:用户有时只需要一个快速的统计分析,而不必生成完整的索引文件。这使得技能变得更加灵活和智能,不会死板地每次都必须运行全部三个脚本。
2.1.4 错误处理
## 4. 错误处理指南 部分预先告知AI,当底层脚本运行出错时应该如何与用户沟通。这能显著提升用户体验,避免AI在遇到代码错误时输出混乱或无关的信息。

2.2 scripts - 执行脚本
这三个Python脚本是技能的执行核心,它们将工作流中的每个阶段具体实现。
2.2.1 scan_notes.py(阶段一:扫描)
此脚本对应工作流的“扫描”阶段,负责对目标目录进行摸底,收集所有Markdown文件的元数据,而不关心具体内容。
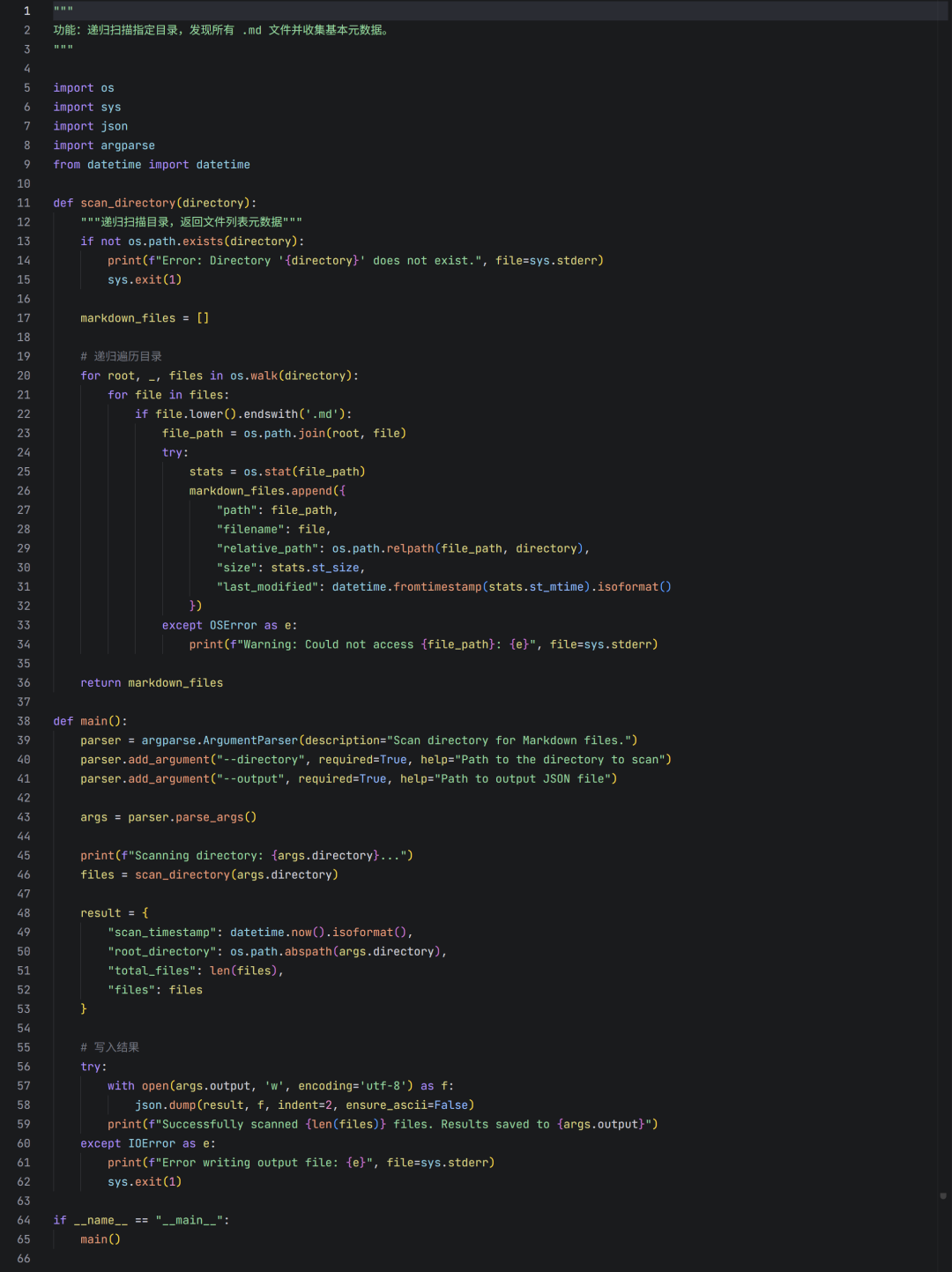
关键设计解析:
- 标准化输出:结果以JSON格式输出,便于下一个脚本读取。其中包含
scan_timestamp,方便后续判断数据的时效性。
- 路径处理:同时保留
path(供机器读取的绝对路径)和 relative_path(相对路径,用于最终在INDEX.md中生成可点击的链接)。
此脚本负责“理解”内容。它会打开每个文件,提取特征并进行分类。为了保持轻量化和零依赖,这里采用了基于规则的关键词匹配法,而非重型NLP库。
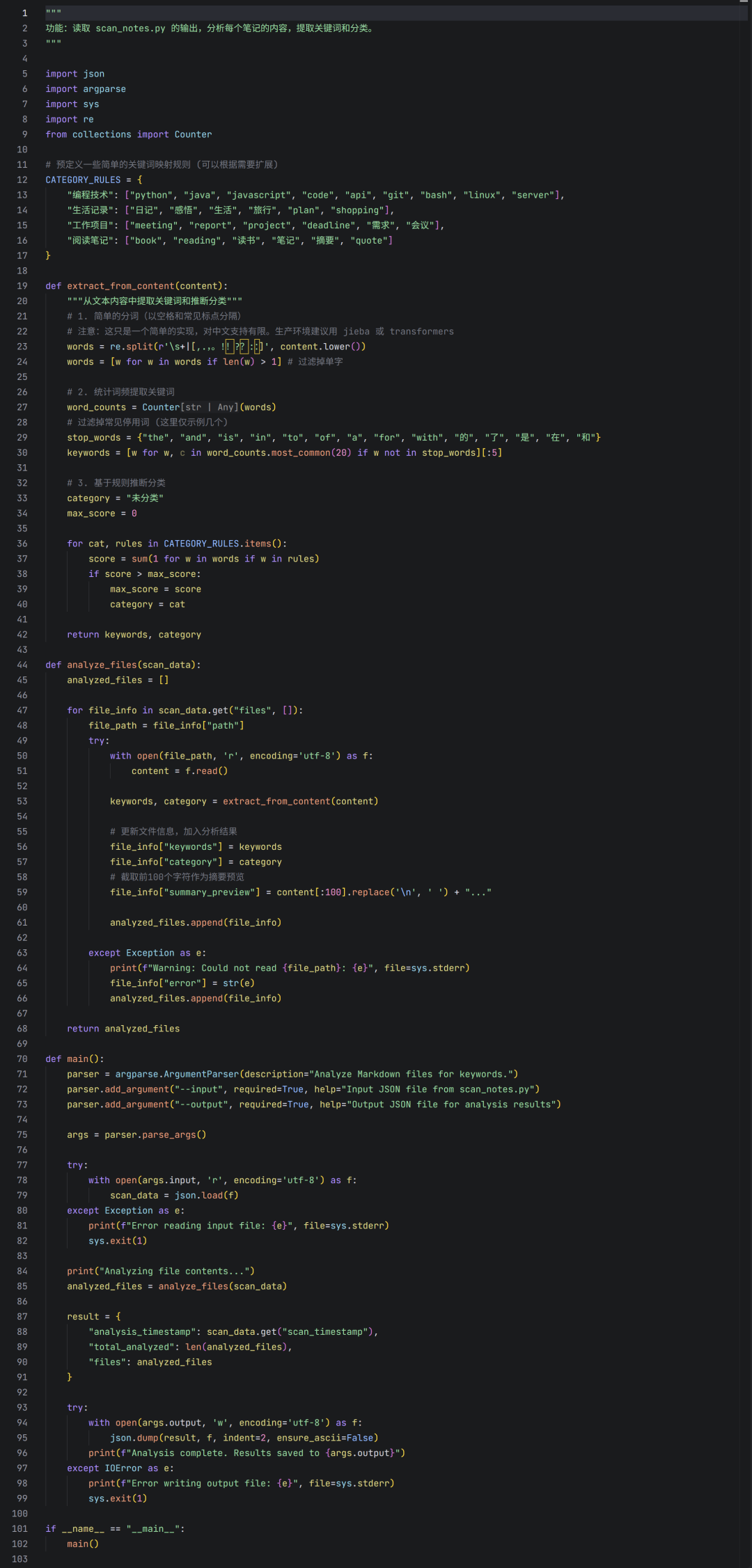
关键设计解析:
- 轻量化:刻意避免导入
jieba 或 nltk 等库,确保技能在任意安装了标准Python的环境中都能直接运行。
- 规则引擎:
CATEGORY_RULES 字典是一个简单的分类器。例如,如果笔记内容中出现“python”,就会被归类为“技术类”。这种方式对于整理个人笔记这种特定场景,往往比通用AI模型更精准、可控。
2.2.3 generate_index.py(阶段三:生成)
此脚本负责“展示”,将分析得到的结构化JSON数据,转换成人眼可读、结构清晰的Markdown索引报告。一份清晰的技术文档对于理解这类数据转换逻辑非常有帮助。
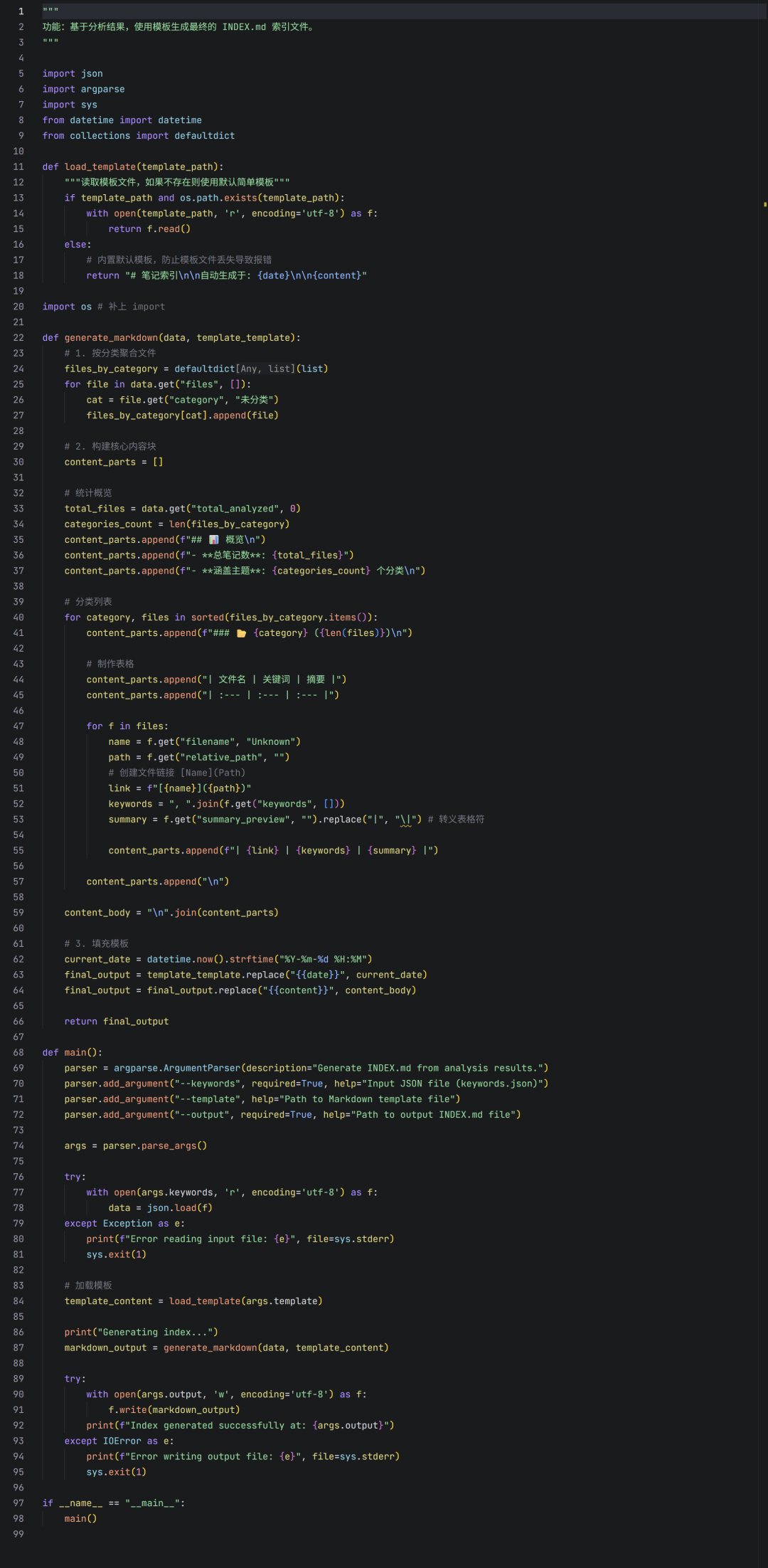
关键设计解析:
- 模板引擎思想:虽然没有使用Jinja2等模板引擎(以减少依赖),但通过
replace(“{{content}}”, …) 实现了基础的模板替换。用户可以自由修改模板文件来改变 INDEX.md 的样式,而无需触碰Python代码。
- 相对链接:生成的索引文件中,文件名被格式化为
[文件名](相对路径) 的Markdown链接。这样在VS Code、Obsidian等工具中,用户可以点击链接直接跳转到对应的原始笔记文件,极大提升了实用性。
2.3 templates - 模板文件
模板文件定义了最终输出物的结构和样式,将数据处理与呈现逻辑分离。
2.3.1 index_template.md(索引页模板)
这个模板会被 generate_index.py 脚本用于生成最终的 INDEX.md 文件。脚本会动态地将当前时间和生成的内容填充到模板的占位符中。
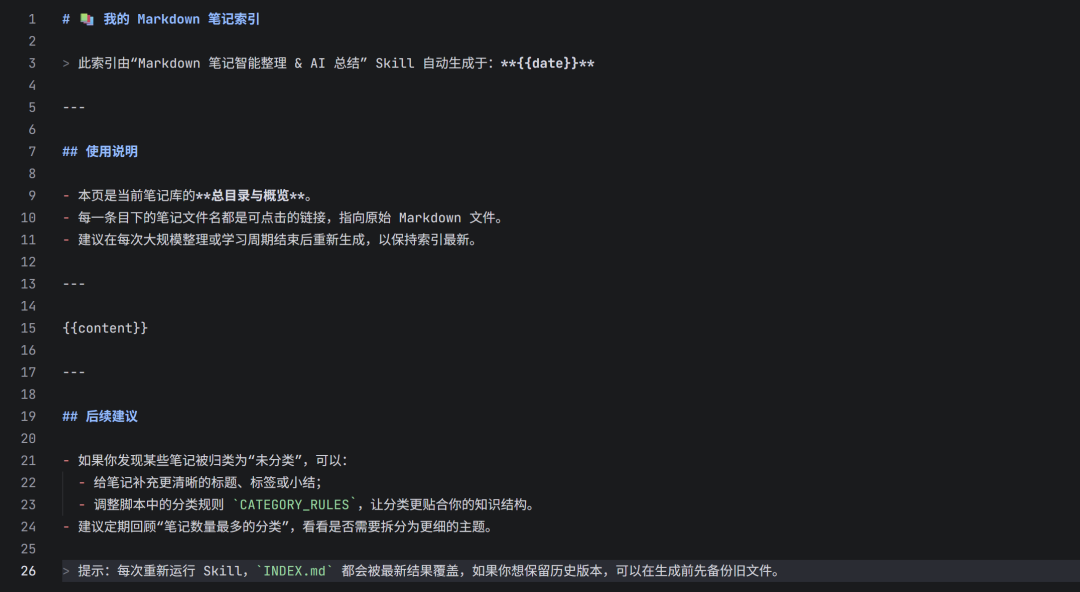
模板设计与用法说明:
{{date}} 占位符:在脚本中会被替换为当前时间字符串(如 final_output = template.replace(“{{date}}”, current_date))。目的是让用户一目了然地知道索引的生成时间。{{content}} 占位符:脚本会将拼接好的“统计信息 + 各分类文件列表”整段Markdown内容填充至此。这个模板主要负责定义页头、页尾和使用说明,中间的业务内容完全动态生成。- 可自定义部分:用户可以安全地修改顶部标题、使用说明和后续建议的文字,只要不删除或错误拼写
{{date}} 和 {{content}} 这两个占位符,脚本就能正常工作。
2.3.2 summary_template.md(总结页模板)
这个模板并非由Python脚本直接填充,而是为AI生成自然语言总结时提供的结构化写作框架。
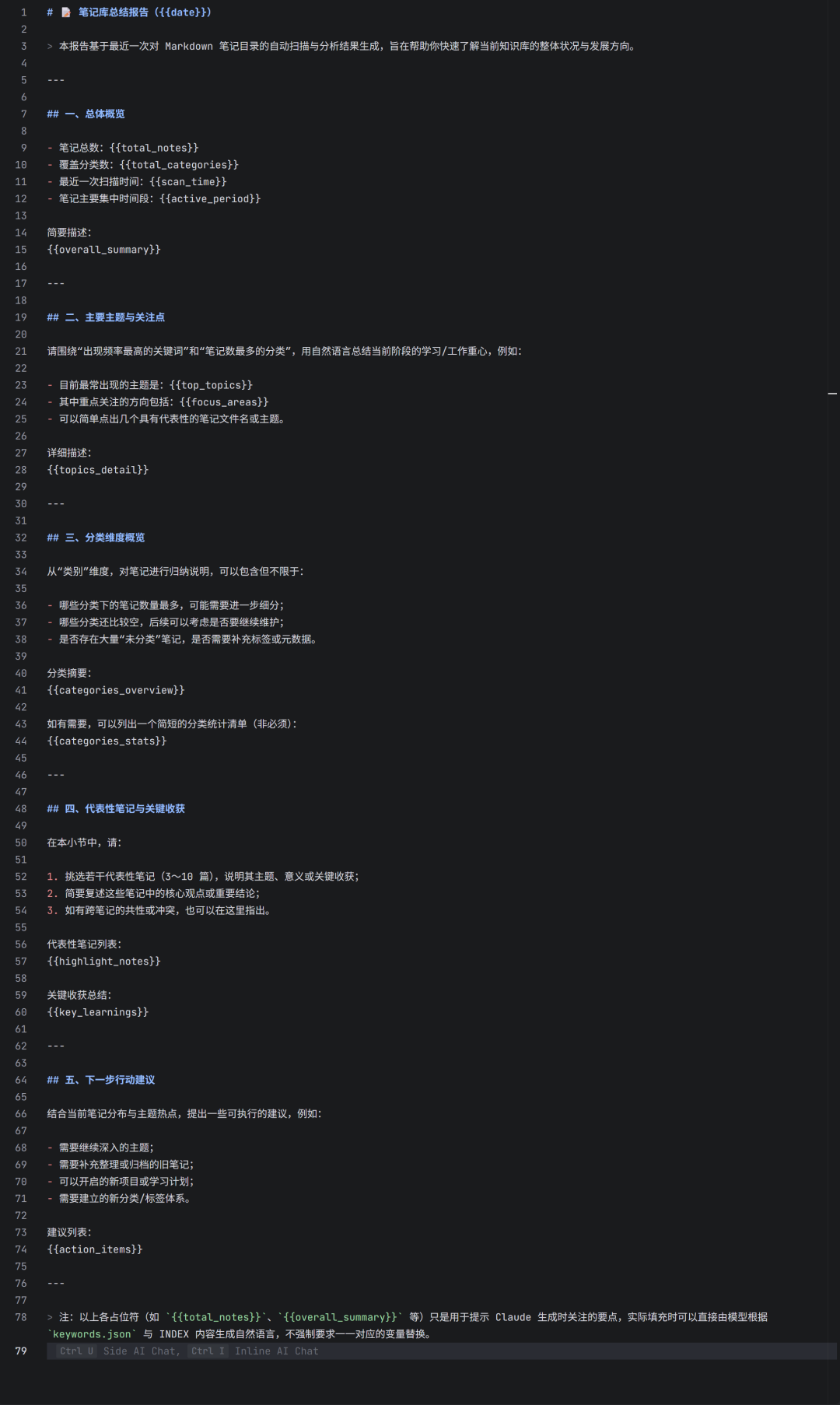
用户可以在对话中指示AI:“基于刚才生成的 keywords.json,请参照 summary_template.md 的结构,写一份本周的笔记库总结报告。”
模板设计与用法说明:
- 指导AI写作:模板中的章节结构(如“总体概览”、“主要主题”、“行动建议”)为AI提供了清晰的写作提纲,确保输出的总结报告结构完整、重点突出。
- 占位符是语义提示:模板中的
{{total_notes}}、{{overall_summary}} 等花括号内容是对AI的写作要点提示,而非需要字面替换的技术占位符。AI会理解其含义并填充相应内容。
- 高度可定制:用户可以根据公司规范或个人喜好定制此模板。例如,在公司内部可改为“团队知识库周报”,在个人使用时可调整为“本周学习复盘”。
2.4 references - 说明文档
references/ 目录下的文档主要供AI在技能内部阅读,用于回答用户关于笔记整理方法、关键词选择等咨询类问题。
2.4.1 best_practices.md(最佳实践指南)
这份文档提供了如何高效组织Markdown笔记的指导原则,例如文件命名规范和目录结构设计。
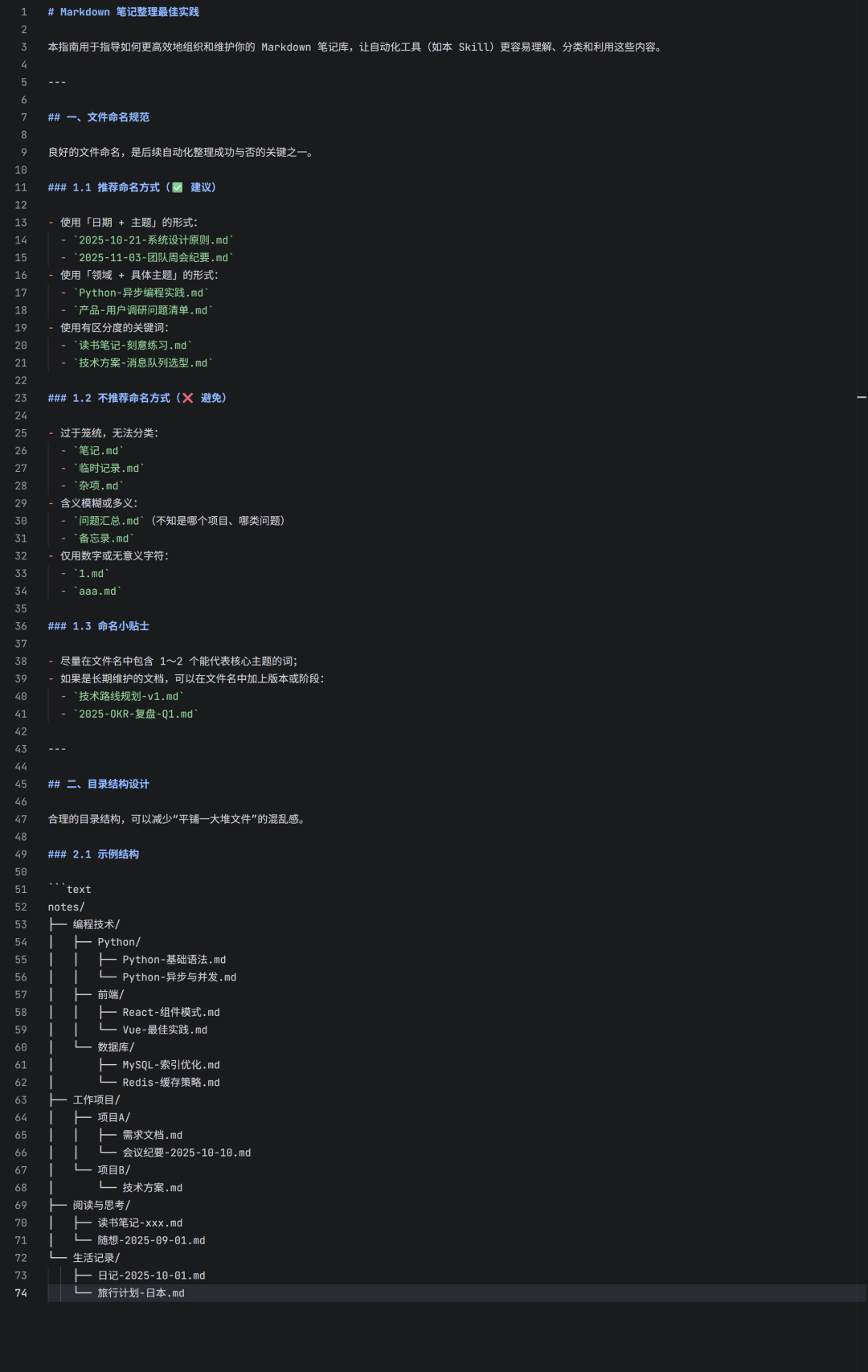
结构设计原则包括:
- 按“领域”或“用途”分层,避免所有文件堆积在根目录。
- 为长期项目建立独立目录,如
工作项目/项目A/。
- 使用“集合”目录归类零散但相关的内容,如
阅读与思考/。
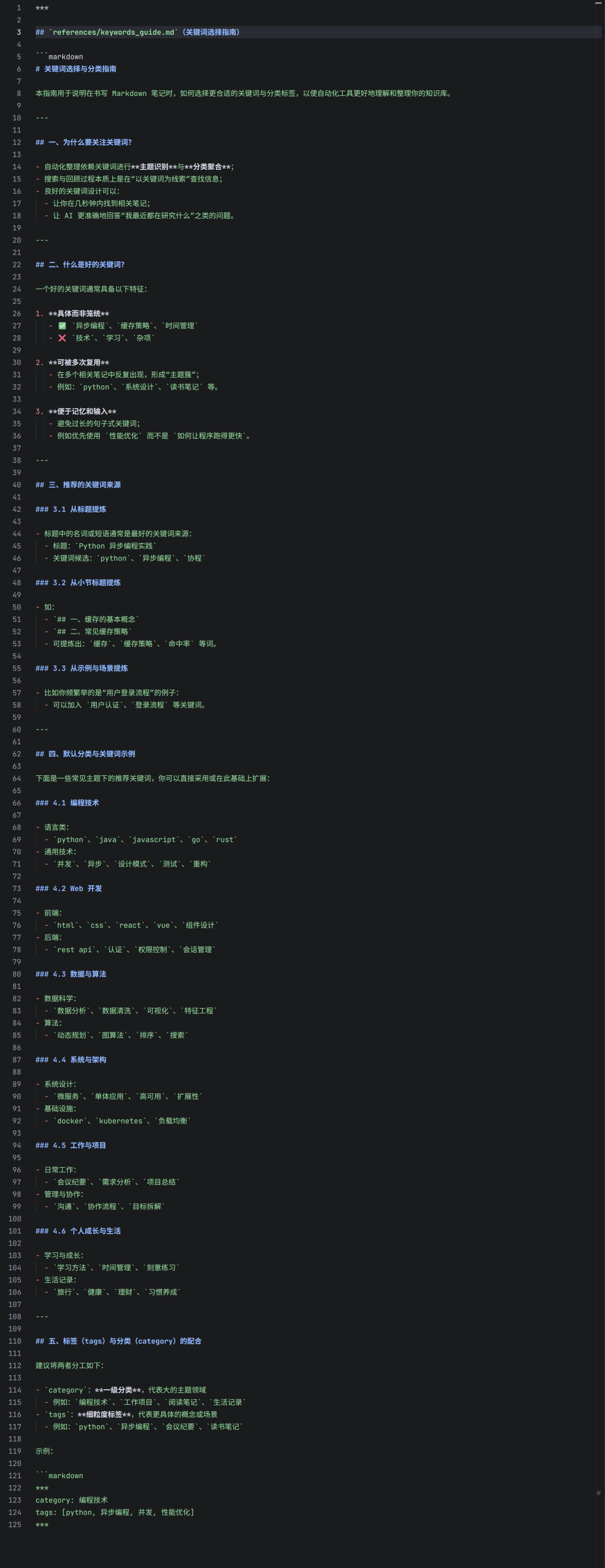
2.4.2 keywords_guide.md(关键词指南)
这份文档更深入地探讨了内容分析与关键词提取的相关概念,可以作为AI回答更深入问题的知识储备。构建这类知识库本身就是一种有效的开源实战过程。
2.5 assets/example_output.md(示例输出)
这个文件展示了一次典型运行后生成的 INDEX.md 最终效果。它有两个主要作用:一是让用户在运行前就能直观了解产出物的样子;二是让AI在需要时可以参考此示例,向用户解释技能的效果。
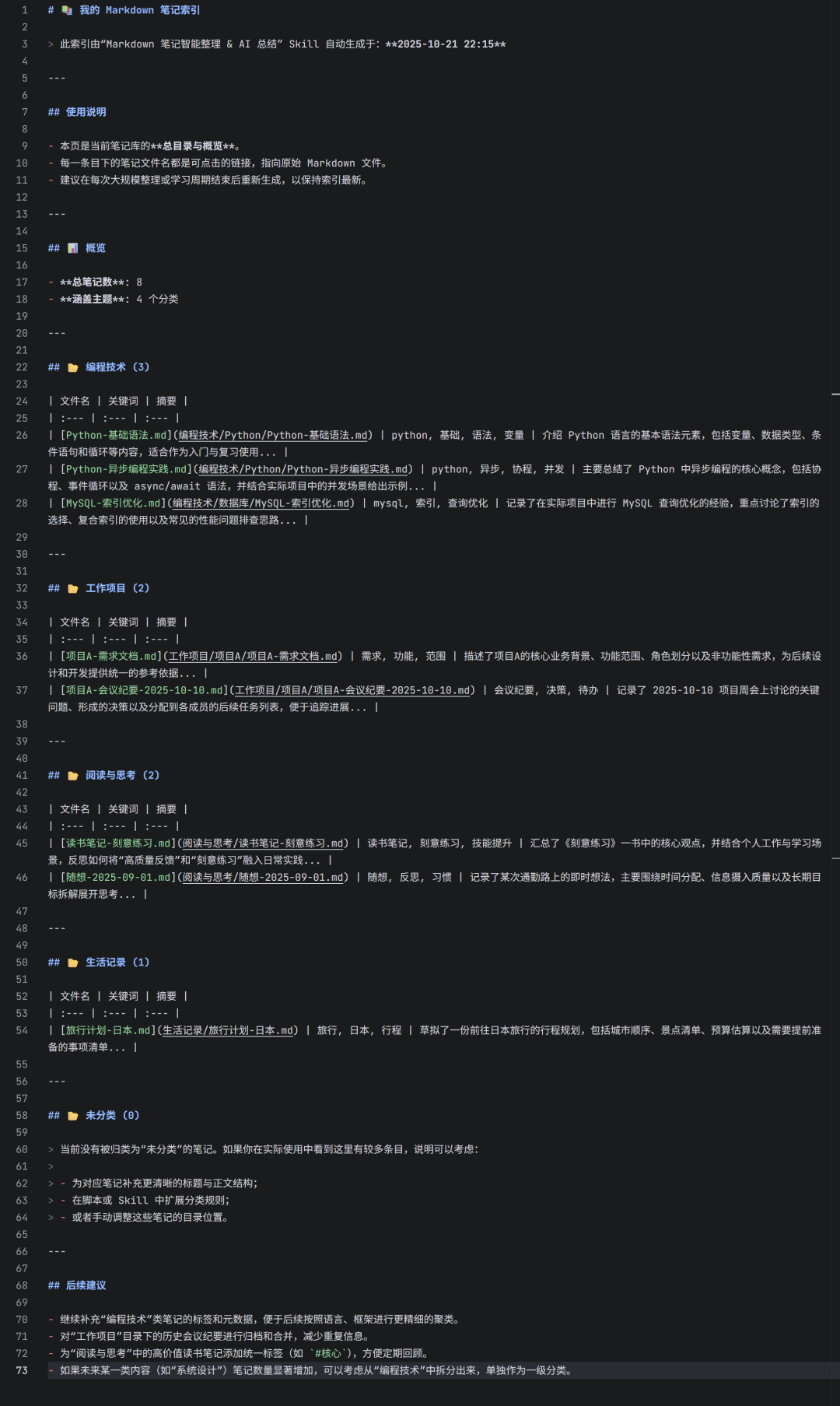
示例输出严格遵循了前面设计的逻辑,展示了:
- 顶层的统计信息块(文件总数、分类数量)。
- 按分类分组的文件列表,每条目都包含可点击的Markdown链接和内容摘要。
- “未分类”提示区,引导用户思考是否需完善分类规则。
用户完全可以基于这个示例文件,调整标题、图标或建议文案,定制成自己喜欢的风格,这不会影响底层 Python 脚本和技能的正常运行。通过这个完整的案例,我们可以看到,将复杂任务拆解为清晰的Python脚本,并结合AI的灵活调度与自然语言生成能力,可以构建出强大且易用的自动化工具。希望这个实践能为你构建自己的AI技能带来启发。更多技术讨论与资源分享,欢迎访问云栈社区。
 发表于 2026-2-24 09:52:22
|
查看: 193|
回复: 0
发表于 2026-2-24 09:52:22
|
查看: 193|
回复: 0
