今天凌晨,人工智能领域爆出一则重磅消息,瞬间在技术圈引发热议。事件的起因是Claude的母公司Anthropic在其官网和社交平台发布了一则措辞严厉的声明,直接点名中国三家知名AI公司——DeepSeek、Kimi(Moonshot AI)和MiniMax,指控它们对自家模型Claude发起了“工业规模级的蒸馏攻击”。
据声明所述,这三家公司动用了超过24,000个虚假账户,与Claude进行了超过1600万次交互,以此提取其能力用于训练和优化自身模型。

声明用词激烈,场面堪比商战大片。在深入讨论之前,我们有必要先搞清楚什么是蒸馏(Distillation)。
简单来说,“蒸馏”就像让初学者通过模仿顶级学霸的解题思路来快速提分。在正常的人工智能研发中,这是一种合法且常见的模型训练技术。实验室通常会将庞大而昂贵的“教师模型”的知识压缩到更小、更高效的“学生模型”中,以便部署。
然而,Anthropic此次声讨的“蒸馏攻击”,性质截然不同。它指控竞争对手并非进行内部技术优化,而是通过庞大的代理网络(Anthropic称之为“九头蛇集群”)和海量虚假账号,向Claude发起精心设计的高难度查询。这相当于别人重金培养出的状元,被你雇人成规模地套取其核心解题方法和试卷答案,直接用来喂养自己的模型。
根据Anthropic披露的细节,各家“攻击”的侧重点和规模有所不同:
- DeepSeek进行了超过15万次对话,主要目标是套取跨任务推理能力。

- MiniMax的交互规模惊人,达到了超过1300万次,专注于智能体编码和工具使用编排。

- Moonshot AI(Kimi)进行了超过340万次交互,目标包括智能体推理、代码分析乃至计算机视觉。

更令Anthropic不满的是,据称在Claude发布新模型后不到24小时,相关活动就迅速转向了新版本。
按理说,作为“受害者”发声,Anthropic本应获得同情和支持。但戏剧性的是,声明发布后,评论区画风彻底跑偏。 大量网友并未声援,反而纷纷嘲讽Anthropic这是“贼喊捉贼”。毕竟,在训练顶级大模型的过程中,几乎所有公司都曾在互联网上大规模抓取(Scraping)未经明确授权的数据。
科技巨头埃隆·马斯克也亲自下场评论,他转发了相关消息并直言不讳地指出,Anthropic自身就面临因使用盗版数据训练模型而支付数十亿美元和解金的诉讼。
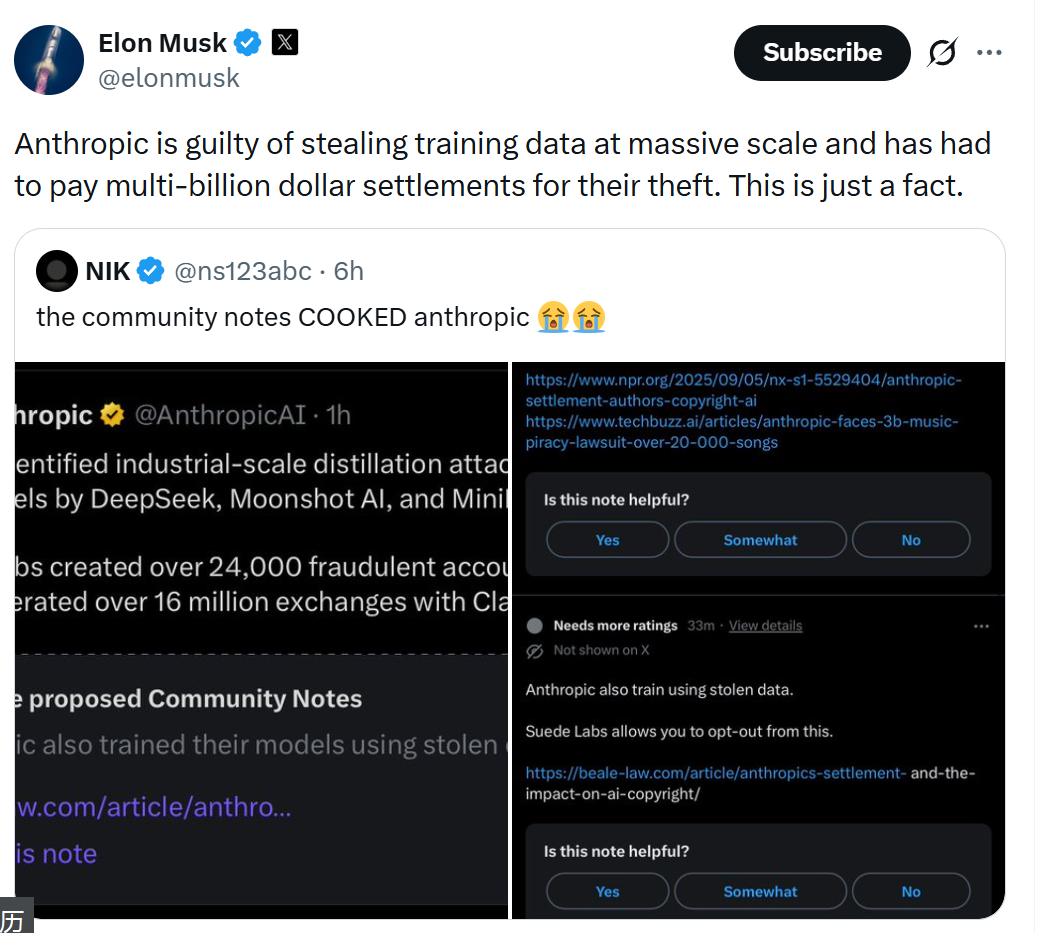
有网友在马斯克的推文下调侃道:“说得好像你们的训练数据是自己写的一样。”
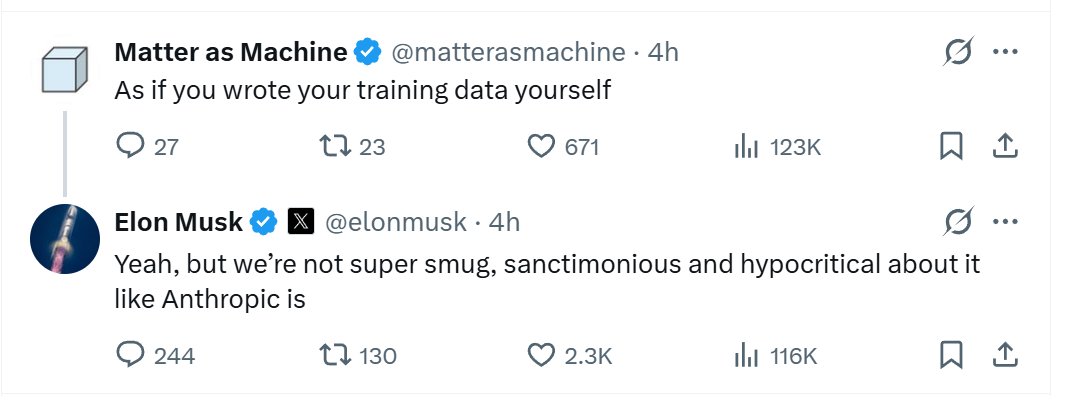
马斯克的回复则更加直白:大家或多或少都使用公开网络数据,存在争议,但Anthropic摆出一副道貌岸然的样子指责别人,实属伪君子。
这场风波也引发了网友们的集体吐槽,各种梗图纷纷出炉:
- 网友A:这个“互相指责”的蜘蛛侠梗图,是不是完美诠释了当前AI行业的现状?

- 网友B:你们(Anthropic)难道不也是从OpenAI那里“蒸馏”出来的吗?
- 网友C:用一张经典迷因图表达了对数据来源问题的灵魂拷问。

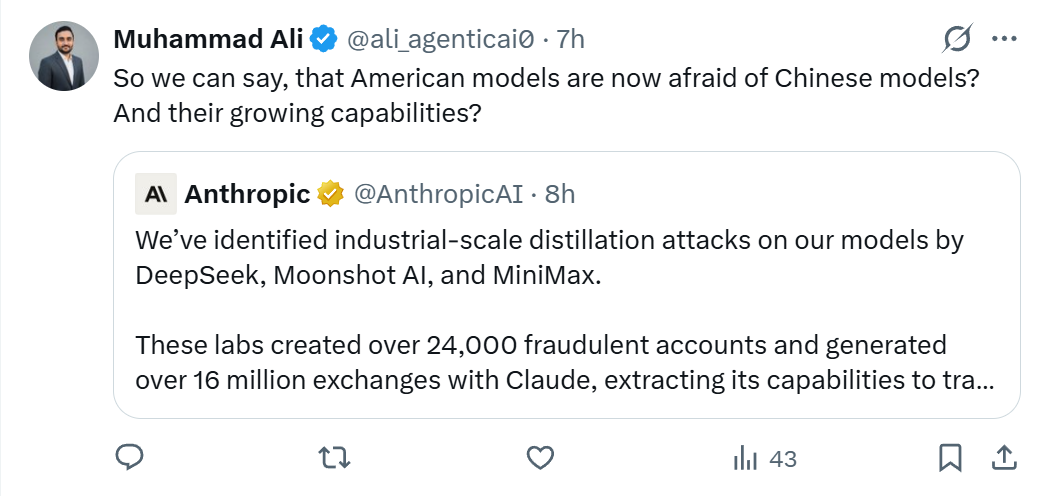
- 网友D:所以这是不是意味着美国模型开始害怕中国模型日益增长的能力了?
- 网友E:直接批评Anthropic是一家制造恐惧、游说反对开源AI的公司。
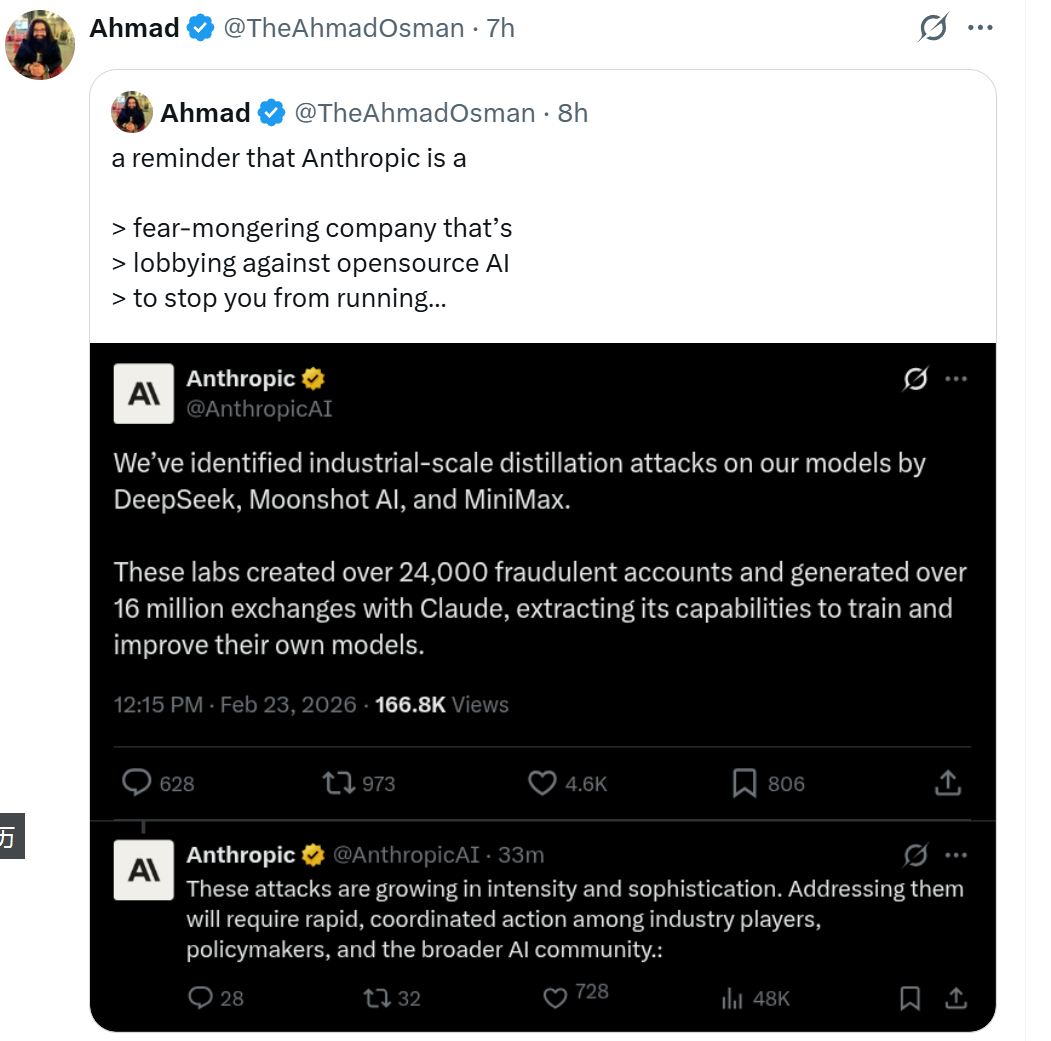
这些评论尖锐地揭示了当前AI行业的一个荒诞现实:许多巨头本身是依靠大规模、未经授权的数据抓取起家,甚至因此卷入法律纠纷,如今却高举“安全”与“道德”大旗指责后来者的类似行为,这无疑是一场深刻的信誉危机。
一点思考
1. 如何面对巨头的指责与谩骂?
当先发巨头对追赶者发出激烈指责时,我们首先要洞察其背后的真实动机。很多时候,“合规”与“道德”大旗是先发者用于遏制竞争、维护市场地位的舆论工具。陷入无休止的自证清白只是内耗,保持战略定力至关重要。巨头们如此强烈的反应,恰恰印证了新兴力量的发展速度已经触及了它们的核心利益。最有力的回应,是加速摆脱对单一模型或技术的依赖,沉下心来在底层算法和原始创新上寻求突破。
2. 数据到底还是不是坚固的护城河?
高质量数据无疑是现阶段AI模型能力的核心基石,但Anthropic此次事件暴露出,这种基于静态数据集的护城河正变得异常脆弱。其愤怒根源在于,耗费海量算力炼就的智能体推理、思维链等关键“智慧成果”,被对手以较低成本快速复制。
蒸馏攻击的可行性表明,一旦大模型通过API对外开放服务,其核心能力便暴露在可被提取的风险之下。未来的竞争壁垒,可能必须从“圈占历史数据”转向构建“动态数据生成”能力——即能否持续、低成本地创造高质量的合成数据,以及能否拥有更快的算法迭代与自我进化速度。
这场风波不仅是企业间的纠纷,更引发了整个开发者社区对AI伦理、数据产权与行业竞争形态的广泛讨论。对于此类前沿技术与商业博弈的深度解析,欢迎持续关注云栈社区的相关技术动态。
 发表于 2026-2-25 02:11:21
|
查看: 234|
回复: 0
发表于 2026-2-25 02:11:21
|
查看: 234|
回复: 0
