
近日,人工智能公司 Anthropic 针对中国大模型发起指控,称后者使用其模型输出进行训练,这一行为究竟是为了打击竞争对手,还是为了服务其在美国政府的商业布局?这场围绕 模型蒸馏 与数据版权的争议,正在引发行业内外的广泛讨论。
2月24日,Anthropic 在其官网发布声明,矛头直指 DeepSeek、Moonshot AI 和 MiniMax 三家人工智能企业。Anthropic 声称,这些公司试图通过 蒸馏攻击 窃取其 Claude 模型的能力,用于改进自身模型。声明特别强调,上述企业通过约24000个账户与 Claude 进行了超过1600万次交互,违反了其服务条款和区域访问限制。
所谓区域访问限制,可以追溯到2024年5月,当时 Anthropic 旗下的 Claude 系列模型停止对中国大陆提供服务。到了2025年9月,限制进一步升级,扩展至所有“中资关联方”。更早之前,Anthropic 的 CEO Dario Amodei 甚至呼吁通过禁止美国芯片出口来限制中国的 AI 发展。有学者将这种态度概括为“人工智能民族主义”,认为这是一种技术竞争中的对抗姿态。
在这场争议中,模型蒸馏 是核心的技术焦点。简单来说,蒸馏 就是利用一个大模型(教师模型)的输出结果,来指导训练另一个小模型(学生模型)。这项技术由深度学习先驱 Geoffrey Hinton 在2015年提出,本身是一种合法且广泛应用的模型压缩与知识迁移方法。
然而,Anthropic 认为,当竞争对手以工业规模系统性调用其 API 并收集输出用于训练时,这种蒸馏就成了一种“攻击”。它允许对手以极低的成本和极短的时间,获得其他实验室耗费巨大资源开发出的能力。
对此,一位学术界的研究员表达了不同看法:“蒸馏本身没什么,大家相互借鉴。既然你敢开放使用,就不要怕别人拿你的回答当数据。”他强调,对于闭源的“黑盒”模型,使用其公开输出进行指令微调(Instruction Tuning)来学习经验,在业界是常见的做法。另一位研究员也表示,目前行业内确实存在相互学习的情况,并且没有特别有效的方法能明确界定和检测蒸馏行为。
需要指出的是,Anthropic 强调的“超过1600万次交互”本身,并不能直接证明这些交互数据被用于了 DeepSeek 等公司的大模型训练。事实上,DeepSeek 此前在回应 OpenAI 的类似指控时曾解释,其模型的训练数据主要来源于公开网页和电子书,但也承认互联网上已存在大量由其他强大模型生成的内容,这可能导致其模型间接受益。
换句话说,数据污染(Data Contamination)问题在当前的互联网环境下几乎无法完全避免。当模型的训练数据来自整个互联网时,很难完全剔除其中可能包含的其他模型的“智慧结晶”。
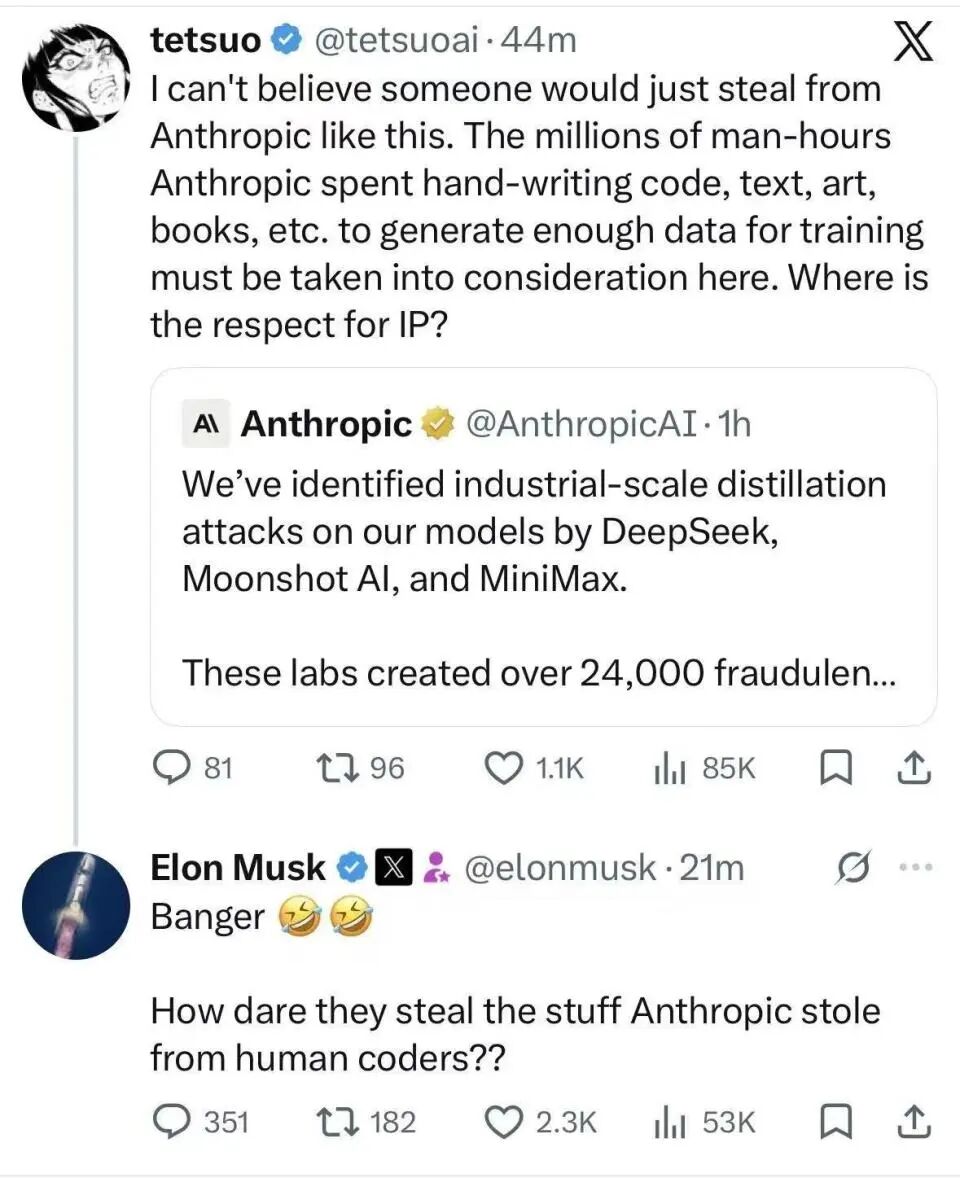
有趣的是,对于 Anthropic 给中国大模型贴上“抄袭”标签的行为,社交网络上出现了不少调侃的声音。特斯拉与 SpaceX CEO 埃隆·马斯克(Elon Musk)在转发相关讨论时反问:“他们竟敢‘偷窃’Anthropic从人类程序员那里偷走的东西?” 这句讽刺直指一个更根本的行业性问题:几乎所有大模型的训练数据,其原始版权都归属于在互联网上创作内容的人类。
另一位网友则贴出了一张梗图,将“问女性年龄”、“问男性薪资”和“问AI公司的训练数据从哪里来”并列,暗示探究大模型的训练数据来源是一件相当“不礼貌”且难以得到清晰答案的事情。

这恰恰触及了 人工智能 发展的一个核心悖论:模型需要海量数据训练,而优质数据的来源始终是模糊且充满争议的。马斯克本人也曾公开批评 Anthropic,称其大规模窃取训练数据并为此支付了数十亿美元的赔偿金。

从法律角度看,关于模型蒸馏的争议同样复杂。法律专家指出,即使服务条款禁止蒸馏,也存在因提示义务不足而导致条款无效的可能性。更重要的是,在著作权法层面,大模型生成的内容通常被认为缺乏足够的人类独创性智力贡献,很难受到版权保护。即便构成作品,平台往往已将输出内容的权利让渡给用户,使得模型提供商难以主张侵权。
至于不正当竞争,关键在于是否使用了欺诈、窃取商业秘密等非法手段。仅通过公开API获取输出数据,通常难以被认定为不正当竞争行为。相反,如果市场主导者滥用其地位,全面禁止合法的技术借鉴,反而可能构成阻碍技术创新的垄断行为。
那么,Anthropic 大张旗鼓地发起指控,其根本目的究竟是什么?许多观察者认为,打击竞争对手只是表象,更深层的目的是为其商业战略披上“国家安全”的外衣,以稳固其在美国政府供应商中的地位。
Anthropic 在声明中明确将“非法蒸馏”与国家安全风险挂钩,称这会破坏美国的 出口管制 措施。这一论调与美国政府近年来的对华技术竞争策略高度同步。此前,“中国大模型第一股”智谱AI就曾被纳入实体清单。
有分析指出,Anthropic 积极靠拢美国政府的“国家安全”叙事,既有价值观因素,更是明确的利益驱动。站队美国政府,有助于其获得宝贵的订单和政策支持。事实也确实如此:2025年,Anthropic 与美国政府达成多项重点合作,成为了官方认证的大模型服务承包商。它不仅获得了为国防、情报等敏感场景开发定制模型的资格,还签署了白宫的《AI安全承诺》,进入政府采购白名单。
2025年6月,Anthropic 推出专为政府敏感场景设计的模型,获得合规优先认定。同年7月,与美国国防部签约,订单金额最高达2亿美元。尽管近期有消息称其与国防部的合作出现分歧,可能波及部分订单,但对于年化收入据称已达140亿美元的 Anthropic 而言,2亿美元订单的财务影响或许有限,但“高优先级美国政府承包商”的身份对其未来的市场竞争和持续融资至关重要。
就在今年2月中旬,Anthropic 刚刚完成了总额300亿美元的G轮融资,投后估值达到3800亿美元。在这场与 OpenAI(正寻求8500亿美元估值融资)等巨头的激烈竞争中,任何能强化自身“可信”、“安全”形象的举措,都显得至关重要。
因此,此次针对中国大模型的指控,更像是一场精心策划的舆论与法律行动,旨在技术竞争之外,开辟地缘政治与合规安全的新战场。这场争议不仅关乎几家公司的技术路线,更折射出全球 人工智能 竞争格局中日益复杂的法律、伦理与政治交织的现状。对于行业开发者而言,理解这些技术之外的游戏规则,或许与钻研算法模型本身同样重要。关于大模型技术演进与行业动态的更多深度讨论,欢迎到 云栈社区 的开发者广场板块交流探讨。
 发表于 2026-2-25 06:44:49
|
查看: 284|
回复: 0
发表于 2026-2-25 06:44:49
|
查看: 284|
回复: 0
