在微服务架构中,负载均衡是保障系统高可用性的基石。作为 Ribbon 的继任者,Spring Cloud LoadBalancer 是如何在客户端实现这一核心能力的?其核心拦截器 LoadBalancerInterceptor 扮演了怎样的角色?本文将通过逐行源码分析,带你深入理解其内部机制与执行流程。
一、LoadBalancerInterceptor 的核心定位
LoadBalancerInterceptor 是 Spring Cloud LoadBalancer 的核心拦截器。它实现了 ClientHttpRequestInterceptor 接口,专门负责在 RestTemplate 发起 HTTP 请求之前进行拦截,核心工作是完成服务实例的选择与请求 URL 的重构。
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor {
private LoadBalancerClient loadBalancerClient;
private LoadBalancerRequestFactory requestFactory;
@Override
public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException {
URI originalUri = request.getURI();
String serviceName = originalUri.getHost();
Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);
return this.loadBalancerClient.execute(serviceName, this.requestFactory.createRequest(request, body, execution));
}
}
这段代码揭示了其核心逻辑:
- 请求拦截:作为
ClientHttpRequestInterceptor 的实现,它能拦截所有通过 RestTemplate 发起的请求。
- 服务名提取:从请求的 URI 中提取主机名部分,这个主机名在微服务上下文中就是服务标识(serviceId)。
- 委托执行:将提取出的服务名和包装后的请求,交给
LoadBalancerClient 去执行后续的负载均衡和实际调用。这是 Spring Cloud 负载均衡体系的关键一步。
二、LoadBalancerClient.execute() 深度解析
LoadBalancerClient 是负载均衡客户端的核心接口,其 execute() 方法是协调服务实例选择与请求执行的总调度中心。
public <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {
ServiceInstance serviceInstance = choose(serviceId);
if (serviceInstance == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
return execute(serviceId, serviceInstance, request);
}
public <T> T execute(String serviceId, ServiceInstance serviceInstance, LoadBalancerRequest<T> request) throws IOException {
RequestContextHolder.getRequestContext().setLoadBalancerServiceInstance(serviceInstance);
try {
URI uri = reconstructURI(serviceInstance, request.getUri());
ClientHttpResponse response = request.execute(uri, request.getHeaders(), request.getBody());
return (T) response;
} finally {
RequestContextHolder.resetRequestAttributes();
}
}
关键流程分析:
- 服务实例选择:首先调用
choose(serviceId) 方法,根据负载均衡策略从可用列表中选出一个合适的 ServiceInstance。
- 请求上下文设置:将选中的服务实例存入请求上下文 (
RequestContextHolder),便于在本次请求链路中全局访问。
- 请求 URI 重构:调用
reconstructURI() 方法,将原始请求中的逻辑服务名(如 http://user-service/api/info)替换为具体实例的物理地址(如 http://192.168.1.101:8080/api/info)。
- 请求执行与清理:执行实际 HTTP 请求,并在最后清理请求上下文,防止内存泄漏。
三、服务实例选择策略揭秘
服务实例的选择是负载均衡的核心。Spring Cloud LoadBalancer 提供了多种策略,默认使用 RoundRobinLoadBalancer(轮询策略)。
public class RoundRobinLoadBalancer implements ReactorServiceInstanceLoadBalancer {
private AtomicInteger position;
private String serviceId;
private ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider;
@Override
public Mono<Response<ServiceInstance>> choose(Request request) {
ServiceInstanceListSupplier supplier = serviceInstanceListSupplierProvider.getIfAvailable();
return supplier.get().next()
.map(instances -> processInstanceResponse(supplier, instances));
}
private Response<ServiceInstance> processInstanceResponse(ServiceInstanceListSupplier supplier, List<ServiceInstance> instances) {
if (instances.isEmpty()) {
return new EmptyResponse();
}
int pos = position.incrementAndGet() & Integer.MAX_VALUE;
ServiceInstance instance = instances.get(pos % instances.size());
return new DefaultResponse(instance);
}
}
轮询策略的核心逻辑很简单:
- 原子计数器:使用
AtomicInteger position 保证在多线程环境下计数的线程安全。
- 取模轮询:通过
pos % instances.size() 这个经典计算,实现对所有实例的依次选择。
- 响应式编程:整个选择过程基于 Reactor 框架,是异步非阻塞的,契合 微服务架构 对高并发的要求。
四、请求 URI 重构机制
reconstructURI() 方法是将逻辑服务名映射到物理地址的关键转换器。
public URI reconstructURI(ServiceInstance instance, URI original) {
Assert.notNull(instance, "instance can not be null");
String serviceId = instance.getServiceId();
URI uri = instance.getUri();
if (uri == null) {
String host = instance.getHost();
int port = instance.getPort();
uri = URI.create((host.startsWith("http") ? "" : "http://") + host + ":" + port);
}
if (StringUtils.hasText(original.getRawQuery())) {
uri = URI.create(uri + "?" + original.getRawQuery());
}
return uri;
}
它的工作清晰明确:
- 获取实例地址:从
ServiceInstance 对象中获取其定义好的 URI,或通过主机和端口组合构造。
- 协议补全:如果实例地址没有明确协议(如
http 或 https),默认补全为 http://。
- 保留原始参数:将原始请求 URI 中的查询参数(Query String)完整地追加到新构造的 URI 之后,确保请求语义不变。
五、LoadBalancerInterceptor 执行流程全景图
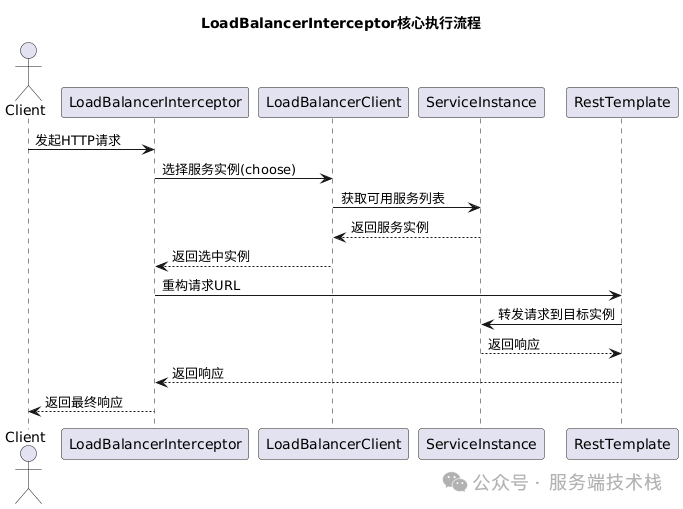
上图清晰地展示了从客户端发起请求到获得响应的完整过程,我们可以将其分为六个阶段:
- 请求拦截:
RestTemplate 发出的请求首先被 LoadBalancerInterceptor 拦截。
- 服务名提取:拦截器从请求 URL 中解析出目标服务名。
- 实例选择:调用
LoadBalancerClient.choose(),由负载均衡器依据策略选定一个具体实例。
- 请求重构:
LoadBalancerClient 将原请求的 URL 主机部分替换为选中实例的 IP 和端口。
- 请求执行:
RestTemplate 将重构后的请求发送到目标服务实例。
- 响应返回:将服务实例的响应原路返回,最终抵达客户端。
六、负载均衡策略扩展机制
Spring Cloud LoadBalancer 的设计具有良好的扩展性。你可以通过实现 ReactorServiceInstanceLoadBalancer 接口,轻松注入自定义的负载均衡逻辑。
public interface ReactorServiceInstanceLoadBalancer {
Mono<Response<ServiceInstance>> choose(Request request);
}
自定义策略示例(比如实现一个简单的随机选择器):
public class CustomLoadBalancer implements ReactorServiceInstanceLoadBalancer {
private ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider;
private String serviceId;
@Override
public Mono<Response<ServiceInstance>> choose(Request request) {
ServiceInstanceListSupplier supplier = serviceInstanceListSupplierProvider.getIfAvailable();
return supplier.get().next()
.map(instances -> selectInstance(instances));
}
private Response<ServiceInstance> selectInstance(List<ServiceInstance> instances) {
// 自定义负载均衡逻辑
if (instances.isEmpty()) {
return new EmptyResponse();
}
// 这里实现自定义选择逻辑,比如权重负载均衡
return new DefaultResponse(instances.get(0));
}
}
通过配置类启用自定义策略:
@Configuration
public class CustomLoadBalancerConfiguration {
@Bean
public ReactorServiceInstanceLoadBalancer customLoadBalancer(
Environment environment,
ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider) {
String serviceId = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new CustomLoadBalancer(serviceInstanceListSupplierProvider, serviceId);
}
}
七、性能优化与最佳实践
在理解了核心原理后,在实际应用中还可以关注以下几点来优化性能和可靠性:
- 响应式优势:充分利用其基于 Reactor 的异步非阻塞特性,提升系统吞吐量。
- 实例缓存:合理配置服务实例列表的缓存策略,减少对服务注册中心的频繁查询。
- 超时与重试:结合
@LoadBalanced 与 RestTemplate 或 WebClient 的配置,合理设置连接、读取超时及重试机制。
- 熔断降级:集成熔断器(如 Resilience4j),在实例选择失败或请求超时时快速失败,避免雪崩。
- 监控告警:监控关键指标,如实例选择耗时、成功率、各实例的请求分布等,便于及时发现问题。
总结
LoadBalancerInterceptor 作为 Spring Cloud LoadBalancer 的交通枢纽,通过清晰的职责划分——拦截、解析、选择、重构——优雅地实现了客户端负载均衡。其源码设计体现了单一职责和开闭原则,为我们提供了深入理解 微服务通信底层 的绝佳范例。希望这篇逐行解析能帮助你在下次遇到负载均衡相关问题时,不仅知道如何配置,更能洞悉其所以然。如果你想深入探讨更多 Spring Cloud 或微服务相关的技术细节,欢迎在 云栈社区 与更多开发者交流分享你的实践经验。
 发表于 2026-2-25 07:48:34
|
查看: 202|
回复: 0
发表于 2026-2-25 07:48:34
|
查看: 202|
回复: 0
