在这个对系统响应速度要求极其苛刻的时代,用户体验往往在毫秒之间决定。试想一个电商秒杀场景,页面加载延迟0.5秒就可能错失心仪商品。此时,Redis的价值便凸显出来——它如同触手可及的钥匙,而传统的关系型数据库(如MySQL)则像需要翻箱倒柜寻找的备用钥匙,两者在效率上存在量级之差。
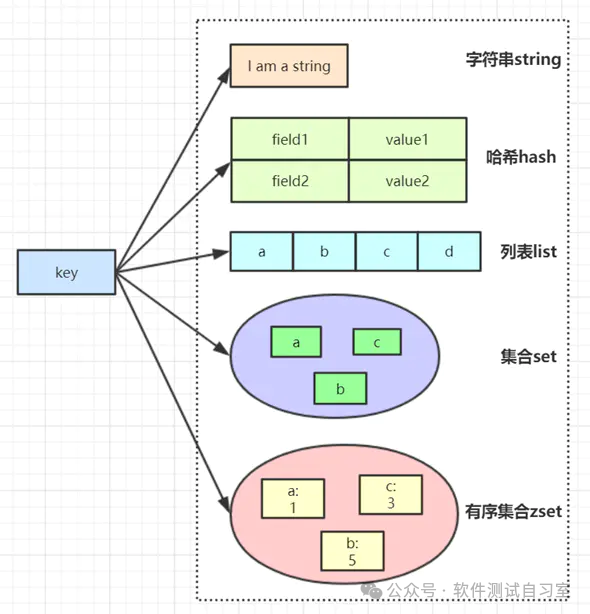
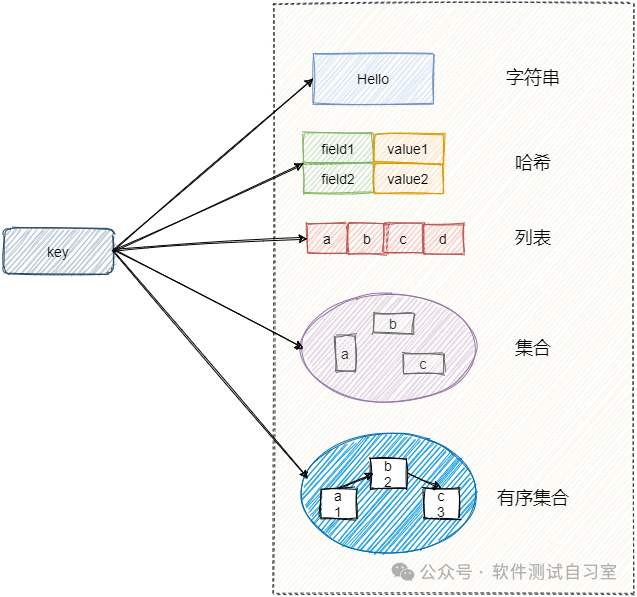
作为一款高性能的内存数据库,Redis凭借其极致的读写速度(单机QPS可达10万以上)、灵活的数据结构(String、List、Hash、Set、Sorted Set等)以及高可靠性,已然成为互联网高并发架构中不可或缺的缓存组件。无论是秒杀系统、社交信息流还是实时排行榜,其身影无处不在。
本文将系统性地解析Redis,涵盖其核心原理、数据结构实战、集群化部署、性能调优以及应对经典缓存问题的策略。
第一章:Redis核心概念解析
1.1 Redis是什么?
Redis远不止一个简单的缓存工具。它是一款开源的内存数据结构存储系统,可用作数据库、缓存和消息中间件。你可以将其理解为一个功能强大的“内存键值存储”,支持多种复杂数据类型。
- 特点一:极致性能:数据存储在内存中,读写延迟可低至亚毫秒级别,远超基于磁盘的数据库。
- 特点二:丰富的数据结构:除基本类型外,还支持位图、HyperLogLog等,以应对多样化的业务场景。
- 特点三:完善的分布式支持:提供主从复制、哨兵模式及Redis Cluster集群方案,保障高可用与可扩展性。
1.2 快速安装与启动
在Linux系统上安装Redis非常简便,只需几个步骤:
# 1. 下载源码
wget https://download.redis.io/redis-stable.tar.gz
# 2. 解压并编译
tar -xzvf redis-stable.tar.gz
cd redis-stable
make
# 3. 安装并启动
sudo make install
redis-server redis.conf # 指定配置文件启动
启动后,使用redis-cli进行连接测试:
redis-cli -h localhost -p 6379
127.0.0.1:6379> PING # 返回PONG则表示连接成功
PONG
安全提示:生产环境务必修改默认配置,例如设置访问密码(requirepass)、绑定内网IP(bind),以避免安全风险。
第二章:核心数据结构与应用场景
Redis的强大源于其多样的数据结构,每种结构都针对特定场景进行了优化。
2.1 String(字符串)
底层实现:简单动态字符串(SDS),支持动态扩容,比C语言原生字符串更安全高效。
常用命令:SET, GET, INCR, APPEND。
应用场景:
- 计数器:
INCR article:1001:views
- 缓存对象:
SET user:1001 '{"name":"张三"}'
- 分布式锁:
SET lock:order_id NX EX 10(NX表示仅当键不存在时设置,EX设置过期时间)
2.2 Hash(哈希)
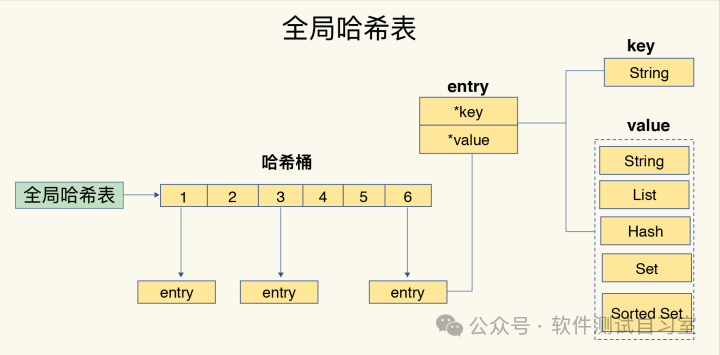
底层实现:哈希表,数据量小时采用压缩列表(ZipList)以节省内存。
常用命令:HSET, HGET, HGETALL, HINCRBY。
应用场景:
- 存储对象属性:
HSET user:1001 name "张三" age 20
- 购物车:
HSET cart:1001 product:100 2
2.3 List(列表)
底层实现:双向链表,数据量小时采用压缩列表。
常用命令:LPUSH/RPUSH, LPOP/RPOP, LRANGE。
应用场景:
- 消息队列:
LPUSH生产消息,RPOP消费消息。
- 社交Feed流:
LPUSH user:1001:feeds "post_id",使用LRANGE获取最新动态。
2.4 Set(集合)
底层实现:哈希表,元素为整数且量少时使用整数集合(IntSet)。
特点:元素唯一、无序,支持集合运算。
常用命令:SADD, SMEMBERS, SINTER(交集), SUNION(并集)。
应用场景:
- 标签系统:
SADD user:1001:tags "科技" "阅读"
- 共同好友:
SINTER user:A:friends user:B:friends
2.5 Sorted Set(有序集合)
底层实现:跳表(SkipList)结合哈希表,元素按分数排序。
常用命令:ZADD, ZRANGE, ZREVRANGE, ZINCRBY。
应用场景:
- 排行榜:
ZADD leaderboard 95 "player1",ZREVRANGE获取TOP N。
- 延迟队列:以执行时间戳为分数,定时获取分数小于当前时间的任务。
第三章:持久化机制保障数据安全
Redis提供两种持久化方式,将内存数据保存到磁盘,防止重启后数据丢失。
3.1 RDB(快照)
原理:在指定时间点,将内存数据生成快照文件(.rdb)保存到磁盘。
触发方式:配置save规则自动触发,或手动执行SAVE/BGSAVE命令。
优点:文件紧凑,恢复速度快。
缺点:可能丢失最后一次快照之后的数据。
3.2 AOF(追加日志文件)
原理:记录所有写操作命令,重启时重新执行以恢复数据。
刷盘策略:appendfsync everysec(推荐,平衡性能与安全)。
优点:数据安全性高,最多丢失一秒数据。
缺点:文件体积通常比RDB大,恢复速度较慢。
3.3 混合持久化(Redis 4.0+)
结合两者优点,AOF文件由RDB格式的前半部分和AOF格式的后半部分组成。恢复时先加载RDB快照,再重放AOF日志,实现快速且安全的数据恢复。
第四章:高可用与可扩展集群架构
单机Redis存在性能与容量瓶颈,需借助集群方案应对大规模应用。
4.1 主从复制
架构:一主多从,主节点负责写,从节点负责读和数据备份。
原理:从节点连接主节点,同步RDB快照及后续增量命令。
作用:读写分离,提升读吞吐量;数据冗余,提高可用性。
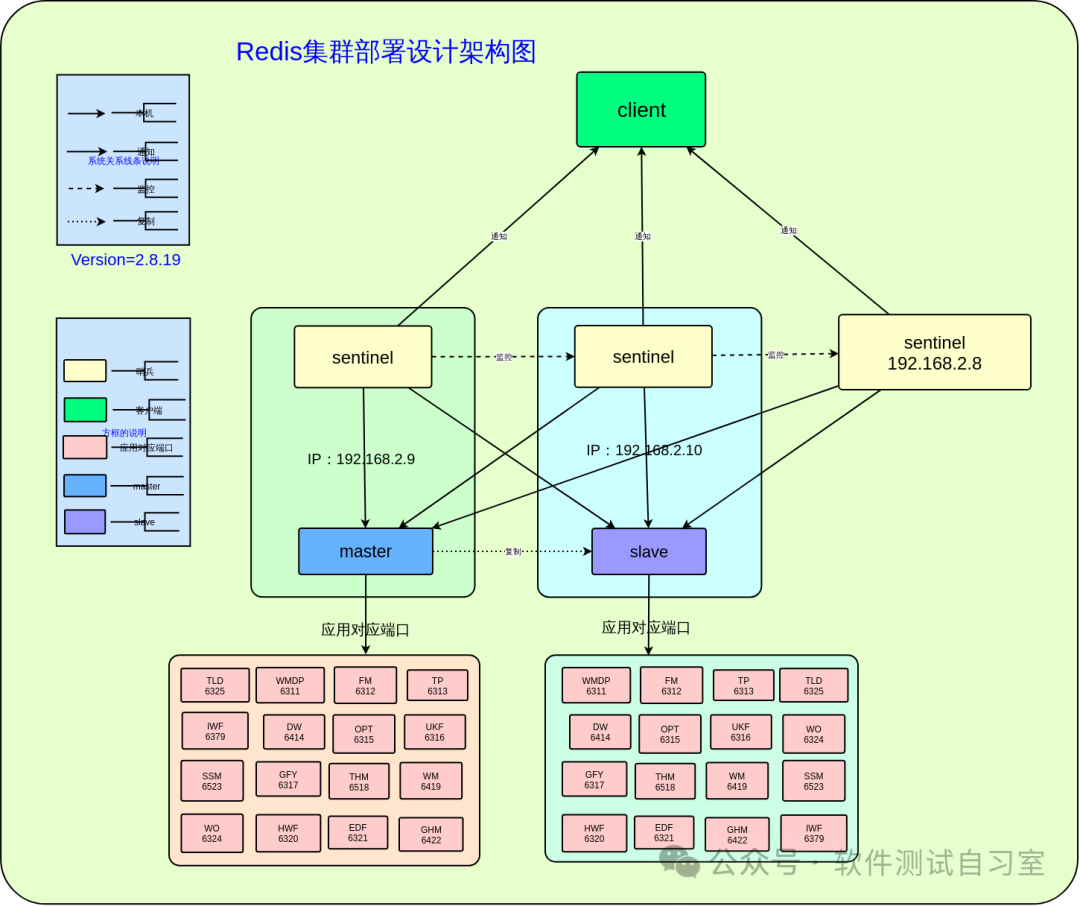
4.2 哨兵模式(Sentinel)
功能:监控主从节点,在主节点故障时自动进行故障转移与主从切换。
部署:建议至少部署3个哨兵实例,形成奇数个决策群体,避免脑裂。
优点:实现了高可用自动化,无需人工干预。
4.3 Redis Cluster
核心:官方提供的分布式解决方案,支持数据分片和自动故障转移。
数据分片:采用哈希槽(Hash Slot)机制,将整个数据集划分为16384个槽,分配给集群中的多个主节点。这类似于在Kubernetes中调度和管理分布式工作负载的理念。
客户端路由:客户端可直接连接任意节点,若键所在槽不在该节点,节点会返回重定向指令。
优点:支持海量数据与高并发,具备线性扩展能力。
第五章:性能调优实战
5.1 内存管理与淘汰策略
设置最大内存并配置合理的淘汰策略,防止内存溢出(OOM):
maxmemory 4GB
maxmemory-policy allkeys-lru # 内存不足时,淘汰最近最少使用的键
5.2 避免大Key与慢查询
- 大Key危害:操作耗时长,可能阻塞服务,网络传输压力大。
- 优化方案:拆分大Key(如将大Hash拆分为多个小Hash);使用
UNLINK异步删除替代DEL。
- 使用Pipeline:将多个命令打包发送,减少网络往返延迟。
5.3 启用多线程IO(Redis 6.0+)
针对网络IO瓶颈,Redis 6.0引入了多线程IO,处理读写网络数据,命令执行仍为单线程。
io-threads-do-reads yes
io-threads 4 # 建议设置为CPU核心数-1
第六章:应对经典缓存问题
6.1 缓存穿透
问题:请求查询数据库中根本不存在的数据,导致请求穿透缓存直达数据库。
解决方案:
- 布隆过滤器:在缓存之前加一层拦截,快速判断数据是否存在。
- 缓存空值:对查询不到的数据也进行缓存(设置较短过期时间)。
6.2 缓存击穿
问题:某个热点Key在过期瞬间,大量请求同时涌向数据库。
解决方案:
- 互斥锁:只让一个请求去加载数据,其他请求等待或重试。
- 热点Key永不过期:后台异步更新缓存数据。
6.3 缓存雪崩
问题:大量Key在同一时间点过期或缓存服务宕机,导致所有请求涌向数据库。
解决方案:
- 过期时间随机化:给Key的过期时间加上一个随机值,避免同时失效。
- 构建多级缓存:本地缓存(如Caffeine)+ Redis缓存。
- 服务熔断与降级:当数据库压力过大时,暂时屏蔽部分请求或返回默认值。
第七章:高级特性拓展
7.1 Lua脚本
用于原子性地执行多个Redis命令,解决复杂场景下的竞态条件。
-- 原子扣减库存示例
local stock = redis.call('GET', KEYS[1])
if tonumber(stock) > 0 then
redis.call('DECR', KEYS[1])
return 1
end
return 0
7.2 Stream(Redis 5.0+)
专为消息队列设计的数据结构,支持消费者组、消息回溯等高级功能,比使用List实现的消息队列更强大。
7.3 功能模块
通过加载模块可扩展Redis能力,例如:
- RedisJSON:原生支持JSON数据类型及操作。
- RediSearch:提供全文搜索功能。
第八章:行业应用案例
8.1 电商秒杀系统
利用Redis预减库存,通过Lua脚本保证原子性扣减,并结合消息队列进行异步下单,从而扛住瞬时超高并发。
8.2 社交Feed流
用户发布动态后,使用List的LPUSH将动态ID写入粉丝的Feed流列表,拉取时使用LRANGE快速获取最新内容。
8.3 游戏实时排行榜
使用Sorted Set存储玩家积分,ZINCRBY实时更新分数,ZREVRANGE快速获取Top N榜单,实现毫秒级响应的排名展示。
总结
从核心数据结构到分布式集群架构,从性能调优到经典问题规避,Redis为现代高性能应用提供了坚实的基础设施支持。随着其功能的不断迭代(如多线程IO、Stream、模块化扩展),Redis的应用边界仍在持续拓宽。深入理解并合理运用Redis,是构建稳定、高效、可扩展系统的关键技能之一。
 发表于 2025-12-6 23:42:46
|
查看: 185|
回复: 0
发表于 2025-12-6 23:42:46
|
查看: 185|
回复: 0
