阿里巴巴开源的 Zvec 是一个轻量级、高性能的嵌入式向量数据库。它的目标是将复杂的向量检索变得像使用 SQLite 一样简单,让开发者可以轻松地在手机、电脑甚至物联网设备上运行AI检索任务,无需部署复杂的服务器。
官网:https://zvec.org/
GitHub 仓库:https://github.com/alibaba/zvec
核心概念:向量数据库界的 SQLite
Zvec 最核心的设计理念,就是立志成为“向量数据库界的 SQLite”。这意味着它不是一个需要独立部署和运维的数据库服务,而是一个可以直接集成到你的应用程序代码中的库。这种嵌入式架构带来了几个非常关键的优势:
- 零部署,开箱即用:你不需要安装、配置或维护一个独立的数据库服务。对于 Python 或 Node.js 项目,通常只需要一条
pip 或 npm 命令即可完成安装并开始使用。
- 数据本地化与隐私安全:所有的向量数据和元数据都存储在本地文件中,查询计算也在本地完成。这避免了将敏感数据上传到云端的需求,从架构层面保障了用户的数据隐私。
- 低延迟,高性能:由于消除了网络调用的开销,你的应用程序可以直接与数据库引擎交互,查询速度可以达到毫秒级。这对于聊天机器人、实时推荐等对响应时间要求极高的场景来说,是巨大的优势。
主要特点与优势
Zvec 的强大不仅在于其“嵌入式”的理念,更在于它为真实生产环境打磨出的一系列丰富特性。
- 强大的内核引擎:Zvec 并非从零造轮子,其核心基于阿里巴巴内部久经考验的向量检索引擎 Proxima 构建。Proxima 多年来一直为淘宝的商品搜索、支付宝的人脸支付等核心业务提供底层支持,其稳定性和高性能在超大规模的生产环境中得到了充分的验证。这次将其核心能力以 开源 库的形式释放出来,对社区而言是一份宝贵的资产。
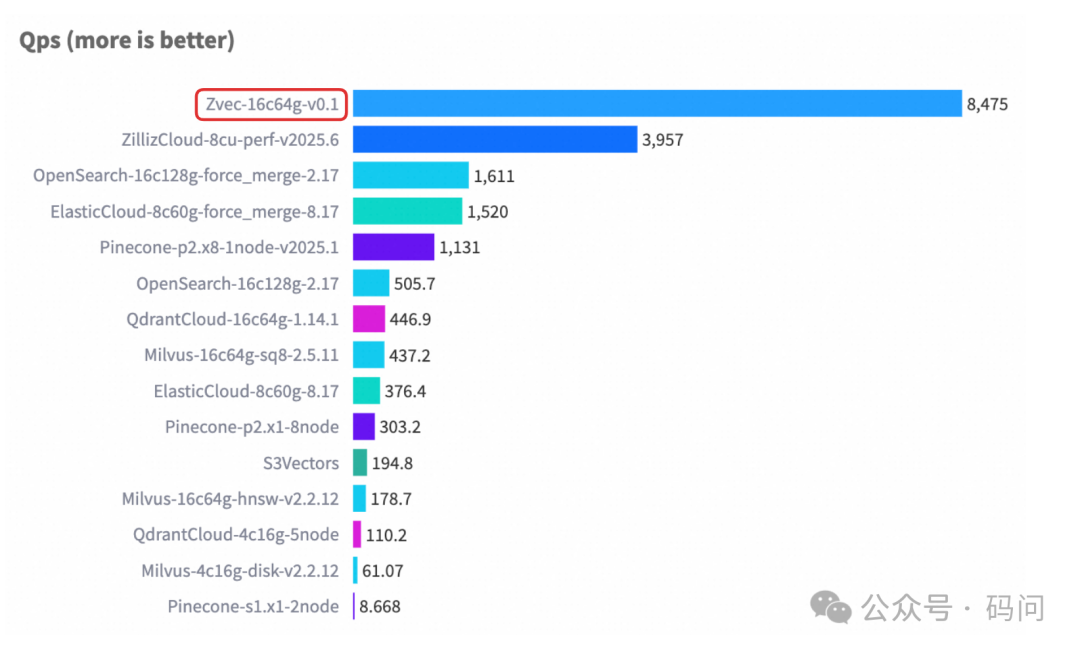
- 令人印象深刻的性能:在权威的 VectorDBBench 基准测试中,面对包含 1000 万条数据的 Cohere 数据集,Zvec 取得了每秒超过 8000 次查询(QPS) 的惊人成绩。根据上方的性能对比图显示,其性能达到了榜单上其他云服务或开源方案的两倍以上,展现了其底层引擎的效率。
- 专为 RAG 优化的功能集:当前,检索增强生成(RAG)是 AI 应用落地的主要范式之一。Zvec 为此提供了近乎完整的支持:
- 完整 CRUD 操作:你可以像操作传统关系型数据库一样,随时对向量数据进行插入、删除、更新和查询,这保证了知识库能够实时更新,适应动态变化的信息。
- 混合搜索:支持同时根据向量相似度和标量字段(如文档创建日期、所属类别、标签等)进行过滤与筛选,让最终的搜索结果更加精准、符合业务逻辑。
- 多向量检索与重排序:支持在一次查询中组合多个向量(例如,同时用问题向量和摘要向量进行检索),并内置了结果重排序(Re-ranking)功能,可以有效提升最终召回结果的相关性和质量。这对于构建复杂的 RAG 应用至关重要。
- 精细的资源控制:为了能在手机等资源高度受限的设备上稳定运行,Zvec 提供了细粒度的内存和并发控制机制。例如,它支持通过内存映射文件(mmap)来处理远超物理内存容量的大型数据集;同时,可以限制查询和索引构建时使用的线程数,防止后台任务抢占过多资源导致前台应用卡顿。
总的来说,Zvec 的出现为需要在边缘侧、终端设备或轻量级服务中集成向量检索能力的开发者提供了一个强有力的新选择。它将阿里巴巴内部的大规模实践经验封装成一个简单易用的库,降低了 人工智能 应用落地的门槛。如果你正在寻找一个无需复杂运维、注重数据隐私且性能卓越的向量检索方案,Zvec 值得你深入研究和尝试。想了解更多类似的尖端开源技术和实践,欢迎来 云栈社区 与更多开发者交流探讨。 |  发表于 2026-2-26 05:26:13
|
查看: 326|
回复: 0
发表于 2026-2-26 05:26:13
|
查看: 326|
回复: 0
