基于谷歌 Gemini 3 Deep Think 打造的数学智能体 Aletheia,在一项比 IMO 更难的数学挑战赛 FirstProof 中取得了最佳成绩。
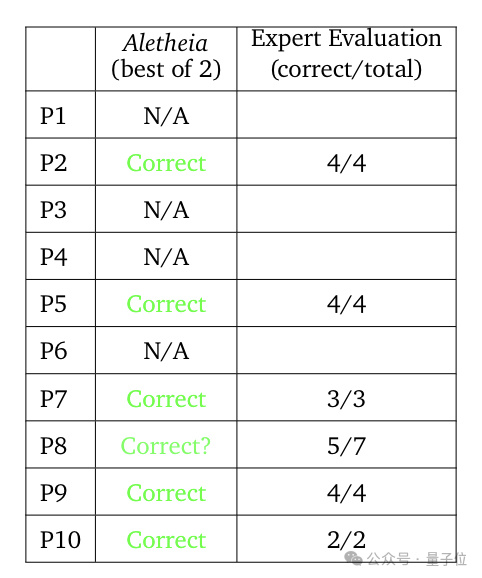
在其公布的完整成绩单中,Aletheia 在 0人工参与 的情况下,成功解出了10道题中的6道。其中5道题获得了专家评审的全票通过,另一道也拿到了5/7的高通过率。
这项 FirstProof 挑战赛由来自哈佛、斯坦福等名校的11位顶尖数学家联合打造,专门用于验证 AI 的独立科研能力。题目全部源于研究者们真实遇到的、此前从未公开发布过的难题,旨在杜绝 AI 通过背诵现有答案来“作弊”的可能。连著名数学家陶哲轩都转发并评论称,这项实验非常有趣,值得关注。

不止谷歌,OpenAI 的内部模型也参加了这项测试,基本答对了5道题。但关键区别在于:谷歌的 Aletheia 全程由 AI 自主完成,而 OpenAI 在解题过程中动用了人工来挑选和优化最佳答案。
谷歌略胜一筹
与 IMO 这类标准化竞赛题不同,FirstProof 的10道题直接取材于真实的数学研究难题,此前没有任何公开记录。更重要的是,标准答案是在所有 AI 提交解答后才公布的,彻底切断了模型“背答案”的可能性。
先看成绩单。OpenAI 冲刺七天后,在以下5个问题上给出了基本正确的答案:
-
- 有限加性卷积与Φₙ的调和平均不等式;
-
- O-适配切片滤过与切片连通性的几何不动点判据;
-
- 大规模ε-轻顶点子集;
-
- 缩放四线性行列式张量之间的代数关系;
-
- 含缺失数据的核化CP–ALS子问题:基于Kronecker预条件的无矩阵PCG方法。
实际上,OpenAI 最初公布的成绩单包含6道题,但其中第2题(非阿基米德局部域上GLₙ的Rankin–Selberg积分非零性判定)被社区反复指出存在逻辑问题,团队最终保守地将其修正为5道。
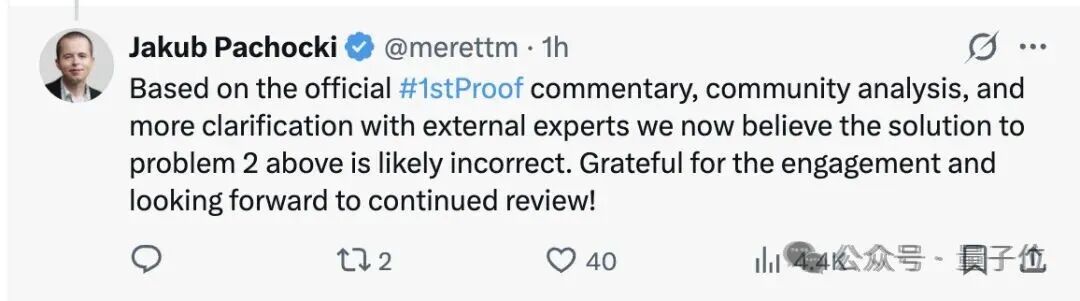
OpenAI 团队也透露,在测试过程中使用了人工来协调模型与 ChatGPT 之间的交流,用于答案验证、格式整理与风格调整。个别问题最终呈现的是经过人工挑选的最佳结果。
相比之下,谷歌的 Aletheia 完全自主地拿下了6道题,其中就包括 OpenAI 被质疑的第2题。在专家评审中,其解答在2、5、7、9、10题上获得了全票通过。
值得一提的是,第7题(含2-挠率的实半单群一致格的紧流形基本群可实现性)被公认为本次挑战集中难度最高的一题,是一个此前未解决的公开问题。直到 FirstProof 挑战赛发布标准答案时,才由 Cappell–Weinberger–Yan 团队首次解决。Aletheia 成功攻克了此题。
第8题虽未全票通过,但也拿到了5/7的高分。Aletheia 自主解答的6道题分别是:
-
- 非阿基米德局部域上GLₙ的Rankin–Selberg积分非零性判定;
-
- O-适配切片滤过与切片连通性的几何不动点判据;
-
- 含2-挠率的实半单群一致格的紧流形基本群可实现性;
-
- 多面体拉格朗日曲面的4-顶点Lagrangian光滑化存在性;
-
- 缩放四线性行列式张量之间的代数关系;
-
- 含缺失数据的核化CP–ALS子问题:基于Kronecker预条件的无矩阵PCG方法。
无论是从解题数量,还是从完全自主的解题模式来看,谷歌 Aletheia 都略胜一筹。这引发了许多对 计算机基础 和自动推理能力边界的思考。

那么,Aletheia 究竟是如何做到的呢?
AI自主解题:生成、验证、修订循环
Aletheia 的底层模型是此前已在 IMO 中摘金的 Gemini 3 Deep Think。系统同时搭载了 A(2026年2月最新版)和 B(2026年1月版本)两个版本的该模型,采用“最优二选一”的策略生成初始解答。
其核心在于一套真正的零人工干预解题流程:
- 自主读题与推理:Aletheia 能直接读取未经人类格式化的原始问题,进行自主推理。
- 自动验证与提取:通过内置的验证提示词,系统会自动校验答案的逻辑严谨性,并整理格式,最终直接输出 LaTeX 形式的答案。
- 智能拒答机制:对于剩余4道未解答的题目,Aletheia 并非给出了错误答案,而是选择了“拒答”。当系统判断无法生成可靠证明时,不会胡编乱造,而是直接输出“无解决方案”。
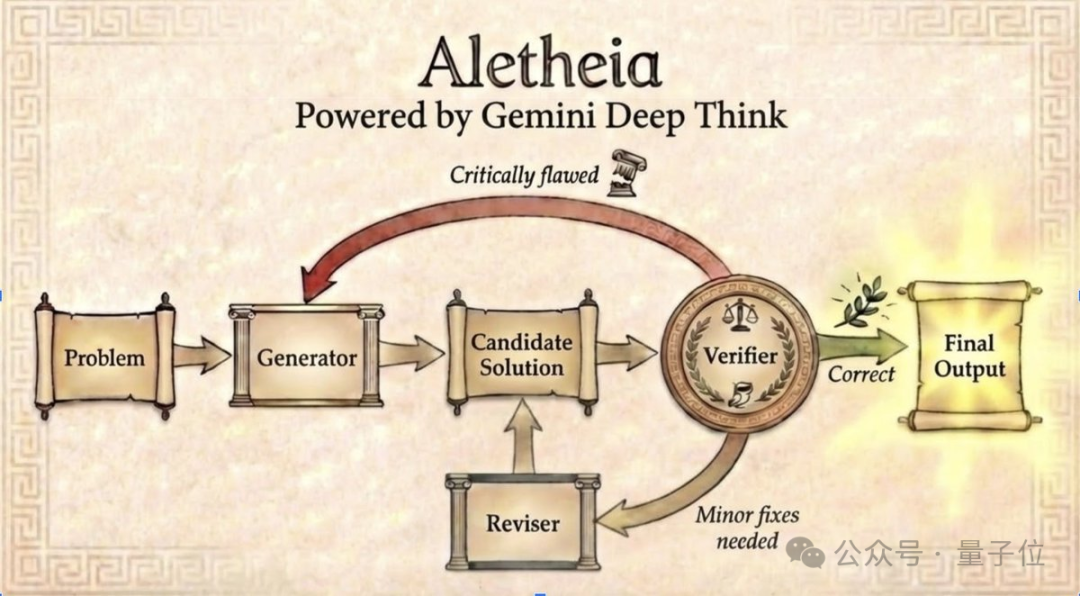
Aletheia 还能动态调整推理资源的分配。例如,在面对超高难度的第7题时,它能自动投入远超常规题的算力,通过 Generator 子智能体进行多轮生成,并由 Verifier 子智能体严格校验,形成“生成-验证-修订”的循环,直至攻克难关。而对于相对简单的题目,则会合理控制算力,避免资源浪费。
在处理如第10题这类涉及张量分解的数值型问题时,Aletheia 展示出了对 算法 效率的优化能力。它没有直接生成超大维度的 Khatri-Rao 乘积矩阵 Z,而是通过动态生成所需矩阵行的方法,将每轮迭代的复杂度压缩到 O(qr+n²r),比传统线性求解器的 O(n³r³) 快了几个数量级。
这轮竞赛,谷歌凭借其全自主的智能体略占上风。据悉,下一轮难度更高的问题集将于3月中旬发布,这场 AI 在尖端 数学 领域的较量,值得持续关注。关于此类技术进展的深入讨论,欢迎前往 云栈社区 与更多开发者交流。
参考链接:
[1]https://x.com/lmthang/status/2021644542852968952
[2]https://mathstodon.xyz/@tao/116022211452443707
[3]https://x.com/polynoamial/status/2022527227049742779
 发表于 2026-2-27 03:43:17
|
查看: 219|
回复: 0
发表于 2026-2-27 03:43:17
|
查看: 219|
回复: 0
