你有没有过这种“憋出内伤”的经历?半夜三点,你盯着屏幕上的进度条,心跳随着 K8s 集群升级的指令敲下而加速。虽然官方文档说这是“标准流程”,但你心里清楚:这根本不是在点鼠标,而是在“开盲盒”。运气好,全绿通过;运气不好,证书过期、API 废弃、节点 Drain 不掉……接下来就是长达数小时的排障和业务部门那夺命连环 Call。
K8s 升级,真的只能靠运气吗?
其实,很多人都把 K8s 升级看简单了。他们觉得就是改个版本号的事儿。但现实是,这背后是一场关于基础设施限制与应用现状的深度博弈。今天我们就通过 VMware 官方的一篇案例研究,来拆解在 VMware Kubernetes Service (VKS) 环境中,如何在“原地升级”和“蓝绿升级”之间找到那个微妙的平衡点。
升级不只是变个版本号:理解 VKS 的“四层协同”
咱先说句实在话,很多人第一步就走错了。他们总觉得升级 K8s 就是改几个二进制文件、换个版本号,哪有那么简单?在 VKS(VMware Kubernetes Service) 的体系里,它其实是一个四层架构的协同:
- 管理平面(Supervisor)
- 平台层(VKS 服务)
- 工作负载集群(Workload Cluster K8S)
- 最核心的——你的应用
很多时候,平台层升上去了,集群也变绿了,但应用挂了。为什么?因为应用没准备好,或者应用所依赖的 K8s API、特性在目标版本中已发生变化。这就是为什么我们要深入讨论两种不同的路径:原地升级(Sequential In-Place) 和 并行/蓝绿升级(Parallel / Blue-Green)。
先看“原地升级”:省钱是真省钱,费神也是真费神
这种模式大家最熟悉:在原来的基础设施上直接覆盖升级,层层递进。它遵循一个严格的顺序:先升级 vCenter,再升级 Supervisor,接着是 VKS 服务本身,最后才是各个工作负载集群。
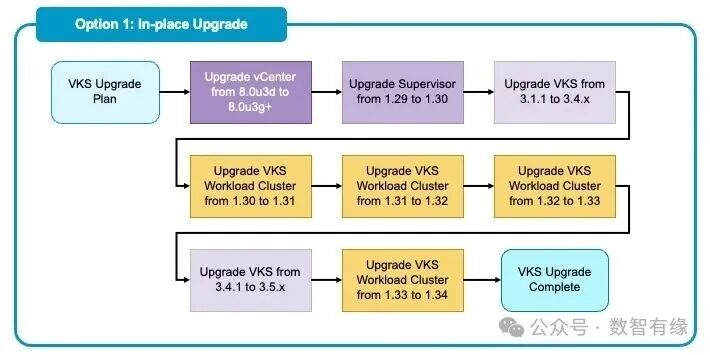
至于为什么还有很多人选它?说白了,核心原因就两个字:资源。原地升级不需要你额外准备一套庞大的备用服务器,它复用了现有的设施。对于很多硬件资源吃紧或预算有限的 IT 部门来说,这往往是唯一现实的选择。
但它的“代价”,往往藏在时间表和管理复杂度里。 我给你举个真实的例子:如果你的公司规定每月只能做一次生产环境变更(这在金融、制造等行业太正常了),而你的集群需要跨 4 个小版本。按原地升级的逻辑,你得一跳一跳来。一跳一个月,四跳就是四个月。这四个月里,每一次升级操作都是一次高风险事件。你要处理节点排空、控制平面重启、证书轮换,甚至还得应对那些启动缓慢、且没有正确配置 Pod Disruption Budgets (PDB) 的老旧应用。
记住这句话:原地升级省的是硬件资源,耗的是时间和运维心力,考验的是应用的生命力。
再聊“蓝绿升级”:爽是真的爽,但门槛也是真的高
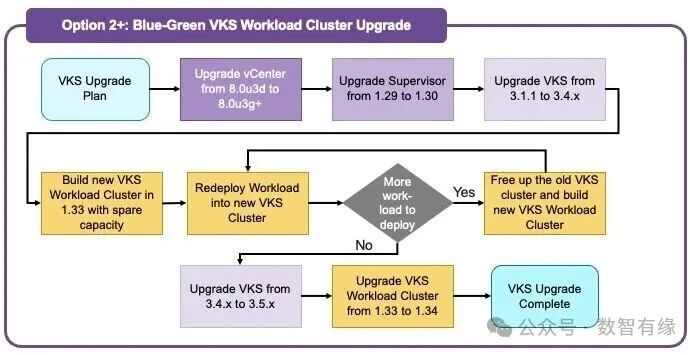
蓝绿升级的思路就比较“优雅”了:直接在旁边构建一套全新的、版本更高的环境(例如直接构建 1.33 集群),经过充分验证后,将工作负载和流量逐步或一次性迁移过去,旧的集群随后退役。

这种方案最吸引人的地方就在于:一步到位,规避中间状态风险。 你不需要操心中间那些过渡版本(如 1.31、1.32)是否存在已知的兼容性 Bug,可以直接从起点飞到终点。回滚也异常简单,流量切回原集群即可,因为“蓝”环境始终保持原状,稳如泰山。
但我得泼盆冷水:蓝绿升级不是你想玩就能玩的。 很多团队看别人演示丝滑流畅,自己一试就翻车。为什么?因为他们可能缺了以下几样“硬装备”:
- 高级流量管理能力:你不能仅仅依赖修改 DNS 记录。你需要一个能进行精细灰度(如 5%、50%、100% 渐进式切换)的智能 流量管理 组件,如现代负载均衡器或服务网格。
- 弹性伸缩基础:流量切换的一瞬间,新集群能扛得住突增的负载吗?你得有健全的 HPA(水平 Pod 自动伸缩)和集群节点自动扩缩容策略,否则新集群可能被直接压垮。
- 强健的 CI/CD 与 GitOps:如果你还在手动执行
kubectl apply,那蓝绿升级就是运维噩梦。你需要像 ArgoCD、Flux 这样的 GitOps 工具,实现应用配置在多个集群间的自动同步与部署。
- 有状态应用的数据迁移策略:无状态应用迁移相对简单,但有状态的应用程序(数据库、消息队列)怎么办?数据如何在线迁移或备份恢复?可接受的停机时间窗口是多少?清晰的回退流程是什么?
说白了,蓝绿升级是“高帅富”的玩法:它需要充足的备用资源、高度自动化的运维流水线,以及相对成熟的云原生架构体系作为支撑。
决策天平:你的场景该选哪一边?
讲到这儿,你可能会问:那到底该选哪种?没有银弹,只有最适合你当前约束的选择。下面是一份可供参考的“决策清单”:
- 如果你的集群规模巨大,或者需要跨越 2 个以上次要版本升级:强烈建议评估蓝绿升级。试想,如果是跨四版本升级,四次独立的变更审批、四次维护窗口,可能耗掉你一个季度,这个时间成本和风险累计谁也吃不消。
- 如果你的应用极度脆弱,无法耐受重启或滚动更新:优先选择蓝绿。你可以在隔离的新环境中慢慢调试应用,待其完全稳定后,再进行流量切换。
- 如果你的硬件资源极其有限,没有任何备用容量:那可能只能选择原地升级。但务必记住:拉长维护窗口,制定详尽的、经过测试的回滚预案,并做好熬夜准备。
- 如果你的变更审批流程冗长复杂:蓝绿升级能帮你把 N 次独立升级审批,整合为“搭建新环境”和“流量切换”等少数几次关键审批,大幅提升效率。
对于小规模、低风险的相邻版本升级,以及应用本身具备高弹性的环境,顺序原地升级仍然是一个成本可控的合理选择。然而,对于多版本迭代、存在严格版本依赖或大型生产集群,并行/蓝绿策略通常能更快、更安全地抵达目标版本,并提供更清晰简单的回滚机制——当然,前提是必要的架构和自动化能力已经就位。
混合策略:现实世界中的平衡之道
其实,在 VMware 的这份真实案例中,专家最终给客户推荐了一个 “折中方案”:Supervisor 管理平面采用原地升级,而工作负载集群则采用蓝绿迁移的方式。 这是一种务实的混合策略,在控制底层基础设施升级复杂度的同时,为上层应用提供了更灵活的迁移和回滚能力。
技术方案从来不是非黑即白的。 升级不是为了盲目追新,更不是为了炫耀技术栈,其根本目的是为了让你的业务应用跑得更稳、更快、更安全。在技术迭代飞快的今天,尤其是在 VCF 9.0 等更自动化平台逐渐普及的背景下,升级过程会变得越来越“一键化”。但无论工具如何进化,作为架构师或运维负责人,你脑海中那杆权衡风险、成本、资源与时间的“平衡秤”,永远都不能丢。在 云栈社区 里,我们也经常探讨类似的基础设施演进话题,因为找到最适合自己当前阶段的路径,才是真正的运维智慧。
 发表于 2026-2-27 07:21:28
|
查看: 217|
回复: 0
发表于 2026-2-27 07:21:28
|
查看: 217|
回复: 0
