年前的那篇文章,聊到了 Spark on k8s 环境搭建时遇到的一系列问题,从解决的过程来看,主要精力都花费在了「制作符合要求的镜像」上。
当然,如果你不想跟我一样费劲,docker hub 官方也确实提供了很多现成可用的 Spark 镜像,只不过这些镜像,都会绑定对应的 Spark、Scala 或者 Java 版本。
如果你只是简单做个测试,证明 Spark on k8s 这套玩法可行,那你随便挑个现成的,确实就可以很快跑起来。
但如果你跟我一样,是要实打实根据当前项目情况跑生产,那对应的 Spark、Scala、Java 的版本,就必须得跟现有的保持一致——总不能去改已经开发完的代码吧,我可没那么彪。
既然上次已经把运行环境给折腾出来了,并顺利跑通了个 demo,那么这次我们再来看看,上几个真刀真枪的生产级 Spark 任务,看是不是依旧跑的利索?
0. 依赖 jar 包位置问题
要求很简单,就是要能正常把我之前在 yarn 上跑起来的 Spark 任务,也同样能提交到 k8s。
这里,我先测试一个 Spark 的批处理任务——把一个亿级规模的数据,经过 ETL 后,写到 CK 表里。
那这里的第 1 步,就是要知道把我的这个,本地开发环境打包好的「任务依赖 jar 包」给搁哪?
如果是用 Spark on yarn,这个根本就不是问题,你把 jar 包上传到Spark 的客户端服务器,然后直接在任务提交命令行指定就好了。
比如像这样:
spark-submit \
--master yarn \
--deploy-mode cluster \
--name SparkTaskName \
--jars /home/spark/sparktask-1.0-SNAPSHOT-with-dependencies.jar \
--class com.anryg.SparkTaskName \
/home/spark/sparktask-1.0-SNAPSHOT.jar
这种玩法,不仅支持直接从本地读取源码 jar 包,还支持直接本地读取依赖的 jar 包,非常方便。
但如果换成 Spark on k8s,那抱一丝,这招貌似玩不转了——没法直接读取本地依赖。
1. jar 包往哪放
还记得上次跑通的那个 demo,它的依赖 jar 放在哪的吗?

这里 local 后面的路径,其实指的是运行 Spark 任务时,依赖的 docker image 启动后,里面 container 的操作系统路径。
我 C,那是不是就意味着,每次我要跑新的 Spark 任务,都得重新制作一次新的 docker 镜像?
其实也不至于。
但我替你试了,如果想直接从本地读取这个依赖 jar,貌似是行不通了。
比如你直接这样:
./bin/spark-submit \
--master k8s://https://192.168.xxxx.xx:6443 \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=apache/spark:3.2-scala_2.12-jre8 \
--conf spark.kubernetes.namespace=spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-account \
/home/spark/sparktask-1.0-SNAPSHOT-with-dependencies.jar
人家就会这样:
Exception in thread "main" org.apache.spark.SparkException: Please specify spark.kubernetes.file.upload.path property.
对于 Spark on k8s 来说,最次,也要把这个 jar,上传到分布式文件系统里,比如 HDFS,或者 S3(也支持其他方式,但发现就这个最好用)。
幸亏我还有 HDFS,要不然还真就玩不转了,就是这么有腔调。
所以,对于这个 jar 包路径,你得改成这样:

人家才能正常提交。
2. 运行中的问题
可以提交到 k8s 了,但没一会,就这样了:

日志一翻:
Exception in thread "main" java.sql.SQLException: No suitable driver
这个小场面,之前在 on yarn 的时候也有过。
只需要在代码里,显示添加一个 CK 数据的驱动类,就好了:

解决这个问题不是重点。
这里其实暴露出另外一个问题:对于 Spark on k8s 来说,每次更新 jar 包,是一件很麻烦的事情,至少,比之前的 on yarn 麻烦不少。
首先:它好像不能像 Spark on yarn 一样,在任务提交命令里,同时指定「源码 jar」跟「源码依赖 jar」,这样一来,我每次源码如果有更新,就不得不上传整个 fat jar 到服务器,因为比较大,所以这个过程,是很耗时的(相比 on yarn 只用上传源码 jar 要慢的多)。
其次:把依赖的 fat jar 上传到 k8s 客户端机器后,这还只是第 1 步,后面还需要再次上传到 HDFS,关键,在上传到 HDFS 之前,你还得把之前已经存在的那个老 jar 包,给删除了才能上传,这又需要一些时间。
就,很麻烦。
3. 优点
说完槽点,咱再来说说好的地方。
首先,任务提交的速度,体感上,那确实要比 on yarn 快不少。
印象中,之前提交到 yarn 的 Spark 任务,甭管资源是不是富裕,那任务从 pending 到 Running 的状态,至少得等个 10 秒左右,很多时候甚至半分钟之久。
但 on k8s 后,经过我很多次的测试,这个状态的转变,最多不超过 3 秒:
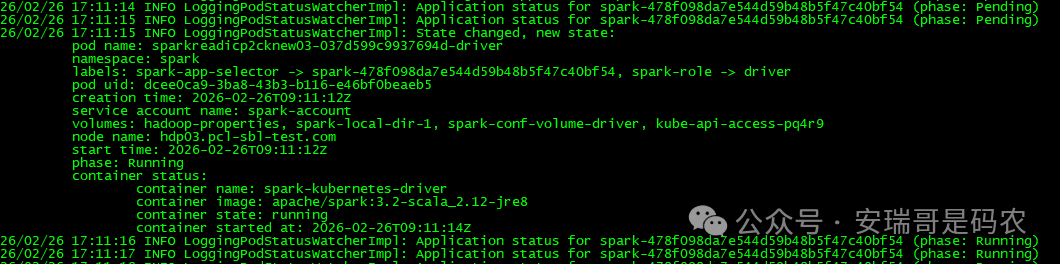
这种不磨磨唧唧的态度,让我很是喜欢。
再来看这次测试的批处理任务,经过多次测试,运行过程也非常稳定,至于任务运行效率,虽然没有直接跟 on yarn 的比,但体感也是挺高的。
说好的亿级数据,也能稳稳当当的入库:
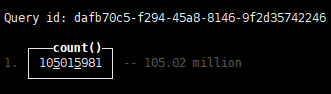
当然,后续我还提交了一个 Spark 的 streaming 任务,也是一如既往的稳,没出现任何幺儿子。
你别说,我开始有点喜欢它了。
最后
从这次的实测表现来看,只要你把 Spark on k8s 的运行环境调通了,那么无论是用它来跑过家家的 demo ,还是跑生产上正儿八经的 ETL 任务,都不在话下。
而且,相比于 Flink on k8s,Spark on k8s 对 hadoop 的亲和力明显要更高,压根就不会出现之前 Flink on k8s 的那些,对 hadoop 的排异反应。
既然这样,那以后我的 Spark 任务,就多让它在 k8s 上跑得了。如果你也在进行类似的架构迁移或者对云原生大数据感兴趣,欢迎到 云栈社区 分享和探讨你的实践经验。
 发表于 2026-2-27 16:11:10
|
查看: 225|
回复: 0
发表于 2026-2-27 16:11:10
|
查看: 225|
回复: 0
