
2026年初,一小群对智能体开发感兴趣的开发者聚在一起分享经验时,可能没人能预料到,仅仅几周后,一个名为 OpenClaw 的项目会引爆整个社区。从周末的个人脚本起步,在八周内斩获超过18万GitHub星标,它迅速成为了一个现象级的开源项目。这一切是如何发生的?关键或许不在于技术本身有多复杂,而在于其出色的产品化能力——它将智能体能力从一个研究概念,变成了普通人也能轻松部署和使用的实用工具。
那么,OpenClaw究竟是什么?
简单来说,它是一个运行在你自己硬件上的个人AI助手平台。你可以把它装在你的笔记本电脑、家庭服务器或云容器里。然后,它会将AI模型连接到你已经日常使用的各类消息应用,如 WhatsApp、Telegram、Slack,甚至是 iMessage。
它的核心理念很独特:将AI助手视为一个基础设施问题,而不仅仅是提示工程问题。OpenClaw不依赖复杂的提示词让大语言模型去“记住”上下文或“学会”安全操作,而是直接在模型外部构建了一个结构化的执行环境。这个环境具备会话管理、记忆系统、工具沙箱和消息路由等完整功能。可以说,大语言模型提供了“智能”,而 OpenClaw 提供了“操作系统”。

核心架构原理:轮辐式设计
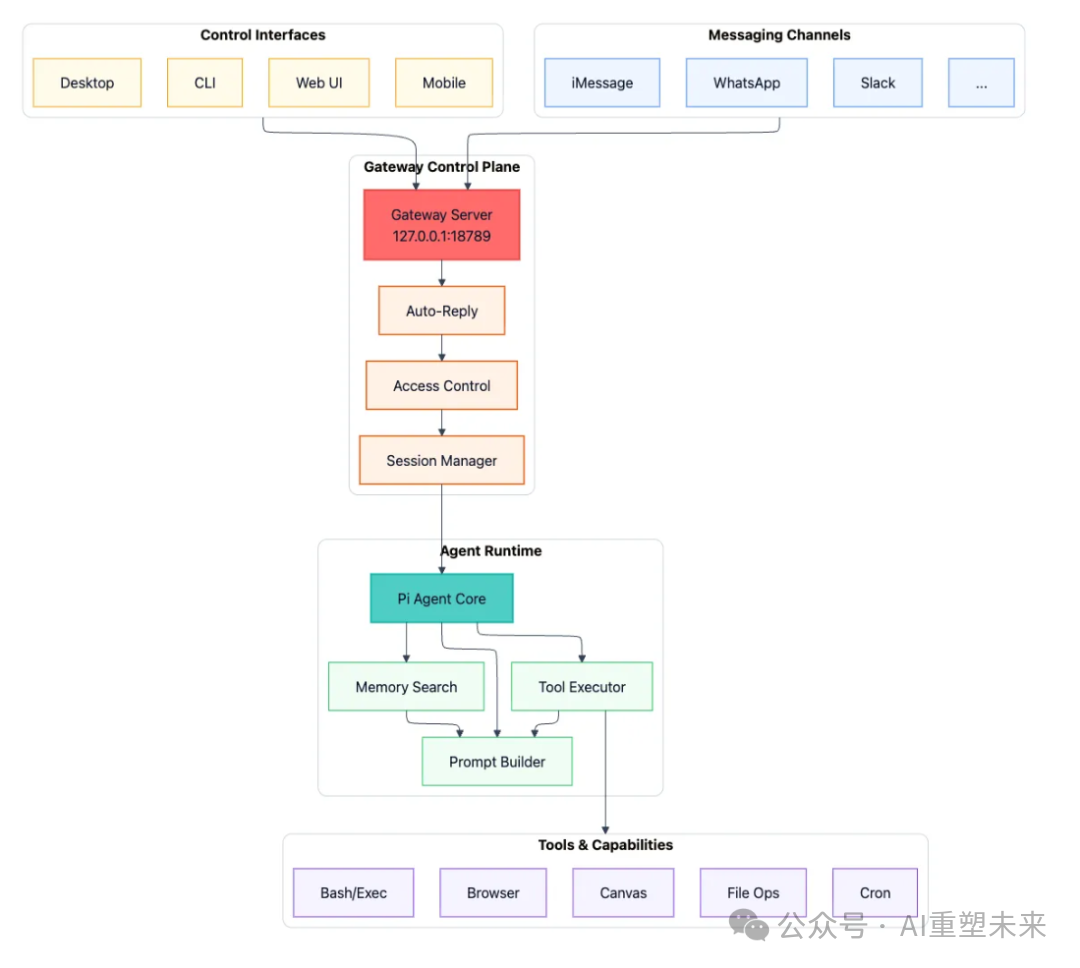
OpenClaw的架构并非围绕某个AI模型API的简单包装。它采用了一种以单一网关为中心的轮辐式设计,这个网关充当了所有用户入口与AI智能体运行时之间的控制平面。
- 网关 (Gateway):一个WebSocket服务器,负责连接各种消息平台和控制界面,并将每条需要路由的消息分发给对应的智能体运行时。
- 智能体运行时 (Agent Runtime):这里是AI循环发生的地方。它负责从会话历史和记忆中组装上下文、调用大模型、执行工具调用(如运行bash命令、操作浏览器),并持久化更新后的状态。
这种设计的巧妙之处在于,它彻底分离了接口层(消息从哪里来)和助手运行时(智能和执行在哪里发生)。这意味着,你可以通过任何一个你常用的聊天软件访问同一个持久化的、有状态的助手,而所有的对话状态和工具访问权限都在你自己的硬件上集中管理。
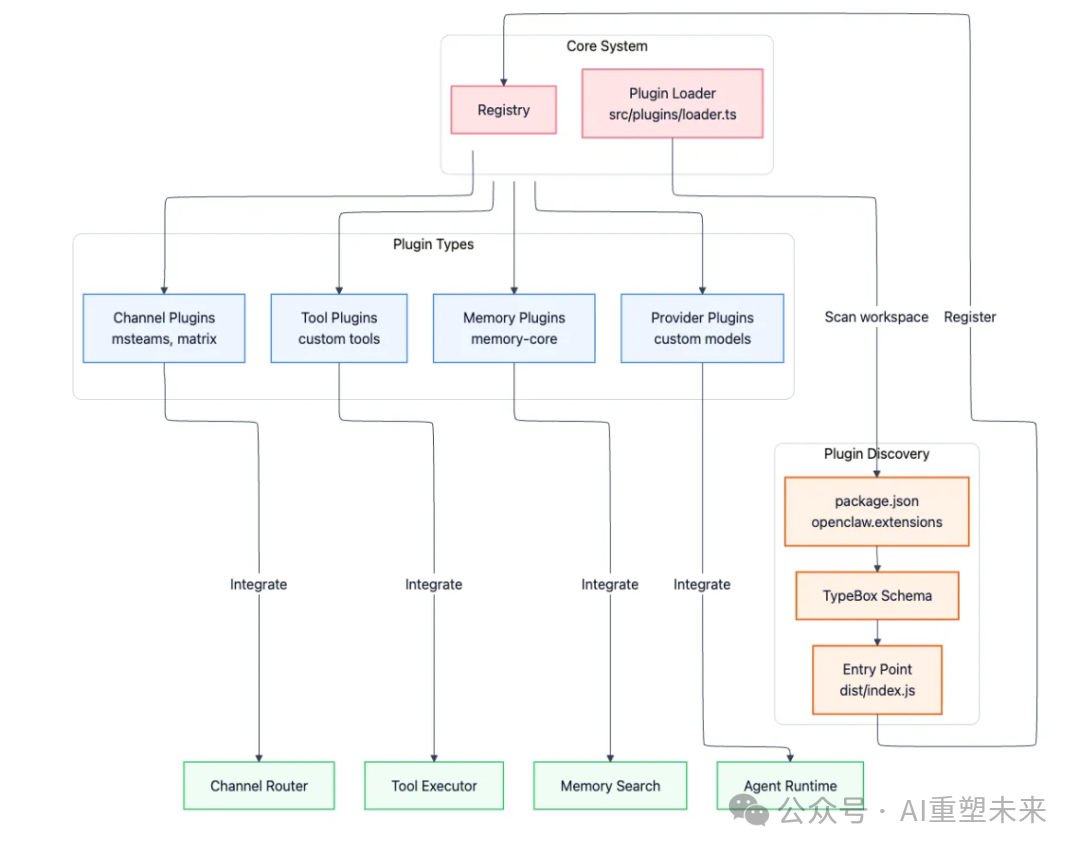
通过插件实现无限扩展
为了让系统无需修改核心代码就能成长,OpenClaw设计了一套灵活的插件系统。插件主要通过四种方式扩展系统能力:
- 频道插件:支持新的消息平台,如 Microsoft Teams、Matrix。
- 内存插件:替换默认的SQLite存储后端,接入向量数据库或知识图谱。
- 工具插件:在內置的bash、浏览器等工具之外,添加自定义功能。
- 提供商插件:接入自定义的LLM服务商或自托管模型。
插件系统基于发现机制工作。位于 src/plugins/loader.ts 的插件加载器会扫描工作区内的 package.json 文件,寻找 openclaw.extensions 字段,验证其模式后自动热加载。
核心组件深入解析
1. 频道适配器 (Channel Adapters)
这是OpenClaw的“耳朵和嘴巴”。每个适配器专门处理一个特定消息平台的协议,负责认证连接、解析平台特有的消息格式、执行访问控制,并将智能体的响应格式化为平台能理解的形式再发送回去。
2. 控制界面
除了通过消息应用交互,OpenClaw还提供了多种管理方式:
- Web UI:用于配置、监控和直接对话的浏览器界面。
- CLI:便于脚本化和自动化管理的命令行工具。
- macOS 应用:提供快速访问的原生菜单栏应用。
3. 智能体运行时的工作流
智能体运行时是真正体现“智能”的引擎,其工作流程可以分解为几个关键步骤:
会话解析:确定一条新消息属于哪个已有的会话,并加载该会话的状态。
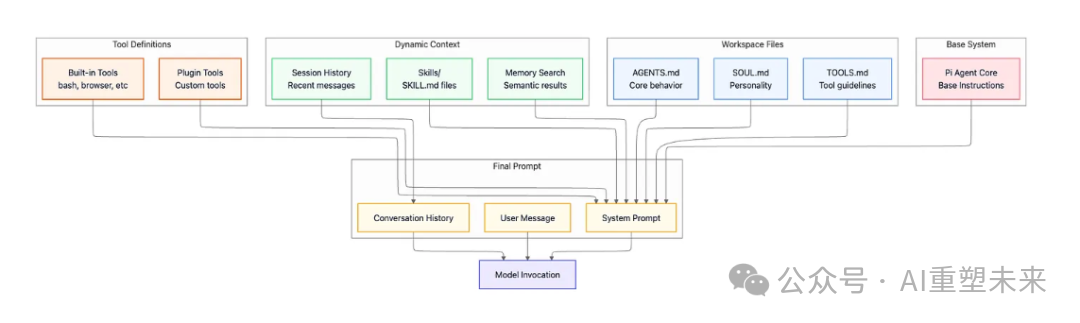
上下文组装:这是构建每次模型调用“系统提示”的关键环节。运行时会:
- 读取工作区中的
AGENTS.md(核心行为)、SOUL.md(个性)和 TOOLS.md(工具使用指南)文件。
- 注入相关的技能(
SKILL.md 文件)。
- 查询记忆搜索系统,寻找语义上相关的过往对话以提供上下文。
执行循环:
- 模型调用:将组装好的丰富上下文打包,流式发送给配置好的大模型。
- 工具执行:模型在思考过程中可能会决定调用工具(比如“打开浏览器搜索天气”)。运行时截获这个工具调用请求,在安全的沙箱环境中执行它(例如运行一个bash命令),并将执行结果流式传回模型,供其纳入后续的思考。
- 响应交付:模型生成的回答块通过网关实时流回,由对应的频道适配器格式化后发送给用户。最后,整个对话状态会被持久化到磁盘。
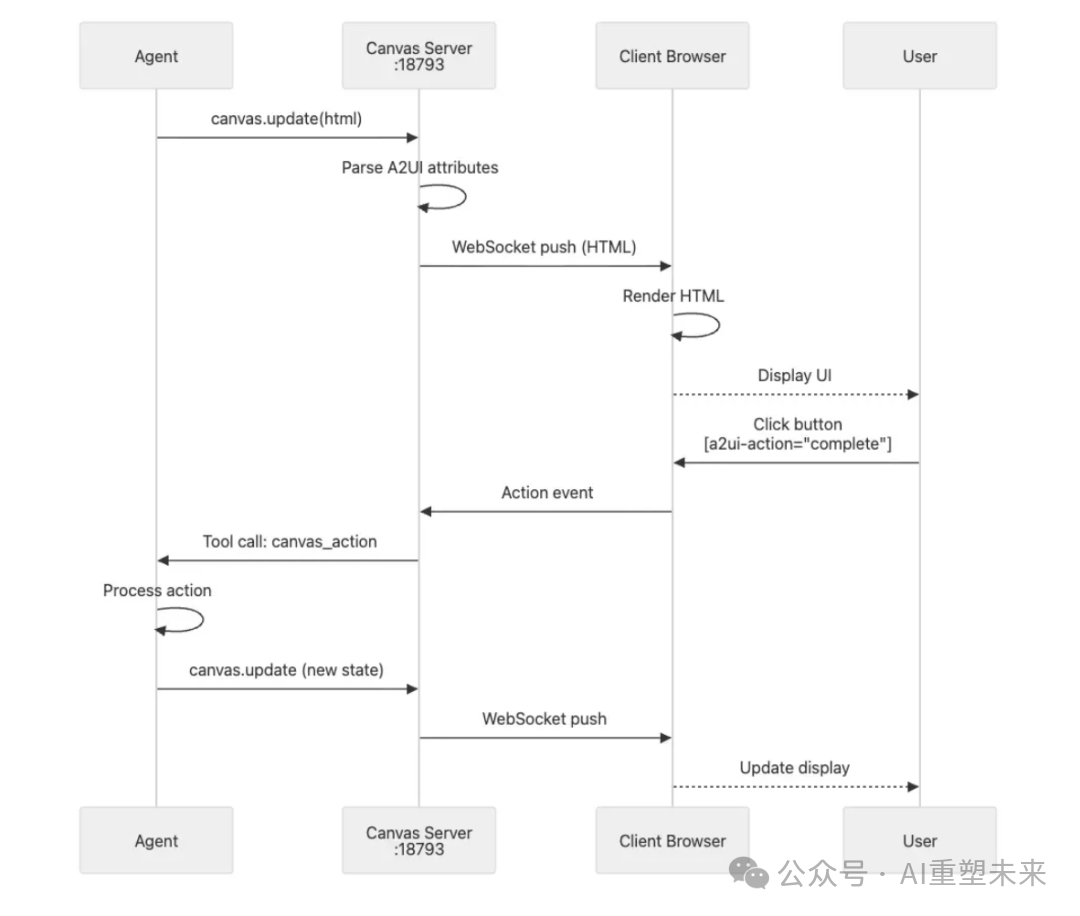
端到端消息流程示例
假设你通过WhatsApp向你的OpenClaw助手发送:“今天天气怎么样?” 整个处理链条如下:
- 摄取:消息经由WhatsApp服务器到达你手机上的OpenClaw WhatsApp适配器。
- 访问控制与路由:网关在毫秒级内验证消息来源并决定路由。
- 上下文组装:运行时从磁盘加载会话、组装包含你个性设置和工具指南的系统提示。
- 模型调用:网络状况良好时,通常在200-500毫秒内收到模型的第一个响应令牌。
- 工具执行:模型可能决定调用“浏览器”工具打开一个天气网站,这个过程可能需要1-3秒。
- 响应交付:格式化的最终答案“今天晴朗,25度”通过WhatsApp服务器发回你的手机。
数据、安全与部署
数据存储:OpenClaw将配置(~/.openclaw/openclaw.json)、会话状态(~/.openclaw/sessions/)和记忆分开存储。会话以仅追加的事件日志形式保存,支持状态恢复和历史回溯,并会自动压缩旧对话以保持在模型的上下文限制内。
安全架构:安全模型是多层次的:
- 网络安全:网关默认绑定到
localhost,通过SSH隧道等方式安全暴露。
- 访问控制:控制界面需要认证,消息来源需要验证。
- 工具沙箱:非受信会话的工具执行在受限环境(如Docker)中进行。
- 提示注入防御:系统层面设有防护机制。
部署模式:非常灵活,支持本地macOS/Linux开发、作为macOS菜单栏应用运行、在Linux虚拟机通过SSH隧道远程访问,以及通过Docker容器在Fly.io等平台上进行云端部署。

总结
OpenClaw代表了一种现代的个人AI基础设施思路:本地优先、自托管、完全可控。它的架构在单进程网关的简洁性与多智能体路由、工具沙箱、插件扩展的强功能性之间取得了良好平衡。这使得它既对初学者友好,又能满足生产环境的需求。
无论你是在自己的电脑上运行一个私人助手,还是在云服务器上部署一个24小时在线的智能体,你都能获得一个可以通过任何聊天软件访问的、真正能“做事”的AI伙伴。在AI能力日益被封装进黑盒API的时代,OpenClaw提供了另一种可能性:一个透明、可控、可按自己意愿扩展的AI智能体操作系统。对于关注系统架构和前沿AI应用的开发者而言,深入研究OpenClaw的设计无疑是一次宝贵的学习体验。如果你想与更多开发者交流这类技术实践,可以到 云栈社区 的相关板块参与讨论。
 发表于 2026-3-2 02:31:12
|
查看: 212|
回复: 0
发表于 2026-3-2 02:31:12
|
查看: 212|
回复: 0
